Microservices. How to do and when to apply?

The author: Vyacheslav Mikhailov
Monolithic applications and their problems
')
Everyone knows what a monolithic application is: we all did such two- or three-layer applications with a classical architecture:
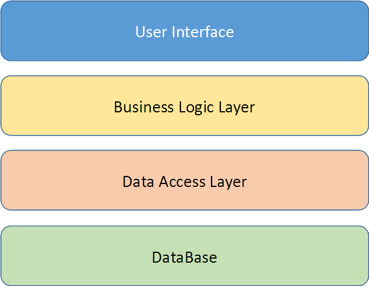
For small and simple applications, this architecture works fine, but, let's say, you want to improve the application by adding new services and logic to it. Perhaps you even have another application that works with the same data (for example, a mobile client), then the architecture of the application will change a bit:
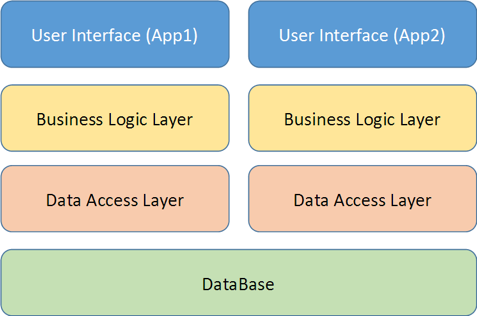
Anyway, as your application grows and grows, you encounter problems with monolithic architectures:
- the complexity of the system is constantly growing;
- support it more and more difficult;
- It is difficult to understand it - especially if the system passed from generation to generation, the logic was forgotten, people left and came, but there were no comments and tests);
- many errors;
- few tests - the monolith cannot be disassembled or tested, so usually there are only UI tests whose support usually takes a lot of time;
- expensive to make changes;
- getting stuck on technologies (for example, I worked in a company where, since 2003, technologies have not changed yet).
Sooner or later you realize that you can no longer do anything with your monolithic system. The customer, of course, is disappointed: he does not understand why adding the simplest function requires several weeks of development, and then stabilization, testing, etc. Surely, many are familiar with these problems.
System development
Suppose that you somehow managed to avoid the above problems and still cope with your system, but you probably need to develop and scale it, especially if it brings serious money to the company. How to do it?
Three scaling dimensions
In the book “The Art of Scalability” there is a concept “scale cube” - from the book “The Art of Scalability”. For this cube, we see that there are three orthogonal ways to increase application performance: sharding, mirrorring, and microservices.

- Sharding ("sharding", "splitting") - the location of the same type, but different data on different nodes. Those who have worked with NoSQL databases know what it is. You have a sharding key, by which you determine that, for example, the data on A and B is stored on one node, on C and D on another node, etc. Thus, using an intelligent load balancer, you can distribute it across your system and achieve better performance.
- Mirroring - horizontal duplication or cloning of all data when you put absolutely identical hosts nearby. So you completely copy the data. It is necessary, first of all, for the system to respond to requests with any expected response time.
- Microservices (microservices) - you break down functionality by business task. Each service will perform specific tasks. This is the microservice approach, which we will analyze here.
CAP theorem
Generally speaking, if we want to develop the system, we will have to solve the following questions:
- How to make the system accessible from different regions?
- Assuming the system is distributed, how to ensure data consistency?
- And how can this also speed up the system N times?
These questions lead us to the CAP theorem formulated by Brewer in 2000.

The theorem is that, theoretically, you cannot provide the system with both consistency (availability), and availability (partitioning). Therefore, one has to sacrifice one of the three properties in favor of the other two. Just as when choosing from “fast, cheap and high quality” you have to choose only two options. Now consider the various options that we have according to the CAP theorem.
CA - consistency + availability
In this situation, the data in all nodes we have agreed and available. Availability here means that you guarantee a response for a predictable time. This time is not necessarily short (it may be a minute or more), but we guarantee it. Alas, while we sacrifice the division into sections - we can not deploy 300 such hosts and distribute all users to these hosts. So the system will not work, because there will be no transaction consistency.
A striking example of CA is ACID transactions that are present in classic monoliths.
CP - consistency + partitioning
The next option is when data in all nodes are matched and distributed into independent sections. At the same time, we are ready to sacrifice the time required to coordinate all transactions - the response will be very long. This means that if two users consistently request the same data, it is not known how long the data for the second user will be consistent.
This behavior is typical for those monoliths that had to scale, despite the antiquity.
AP - availability + partitioning
The last option is when the system is available with a predictable response time and is distributed. At the same time, we will have to abandon the integrity of the result - our data is no longer consistent at any given time, and outdated ones (from microseconds to days) appear among them. But, in fact, we always operate on old data. Even if you have a three-tier monolithic architecture with a web application, when the web server gave you a packet with the data that you displayed to the user, they are already out of date. After all, you in no way know if someone else came at that moment and did not change this data. So that the data we have agreed upon (ultimately consistent) is normal. “Agreed in the long run” means that if an external influence ceases to influence the system, it will come to an agreed state.
A vivid example is classic DNS systems that are synchronized with a delay of up to days (at least, earlier).
Now, having familiarized with the theory of CAP, we understand how we can develop the system so that it is fast, accessible and distributed. No way! You have to choose only two of the three properties.
Microservice architecture
What to choose? To make the right choice, you need, first of all, to think about why all this is needed - you need to clearly understand the business objectives. After all, the decision in favor of microservices is a very crucial step. The fact is that in microservices everything is much more complicated than usual, that is, we can face the following situation:
You can't just take and cut everything into some pieces and say that these are now microservices. Otherwise, you will have a very hard time.
Microservices & SOA
And now let's talk a little more about theory. You all know perfectly well what SOA is - a service-oriented architecture. And then you probably have a question, how does SOA relate to microservice architecture? After all, it would seem, SOA is the same, but it is not quite so. In fact, microservice architecture is a special case of SOA:

In other words, microservice architecture is just a set of more stringent rules and agreements on how to write all the same SOA services.
What are microservices?
This is an architectural template in which services:
- small
- focused
- loosely coupled
- highly coordinated (highly cohesive).
Now we will analyze these concepts separately.
What does “ small ” service mean? This means that a service in the microservice architecture cannot be developed by more than one team. Usually one team develops about 5 - 6 services. In this case, each service solves one business problem, and one person is able to understand it. If not able, the time to cut the service. Because if one person is able to support the entire business logic of one service, he will build a really effective solution. After all, it happens that often, when making decisions in the process of writing code, people simply do not understand what they are doing - they do not know how the system behaves in general. And if the service is small, everything is much easier. By the way, we can use this approach separately, even without following the microservice architecture as a whole.
What does “ focused ” service mean? This means that the service solves only one business problem, and solves it well. Such a service makes sense apart from other services. In other words, you can put it on the Internet by adding a security wrapper, and it will be useful for people.
What is a “ loosely coupled ” service? This is when changing one service does not require changes in another. You are connected via interfaces, you have a solution through DI and IoC - this is now a standard practice, which must be applied. Usually, developers know why :)
What is a “ highly consistent ” service? This means that a class or component contains all the necessary methods for solving the problem. However, the question often arises here, how does high cohesion differ from SRP? Suppose we have a class in charge of kitchen management. In the case of SRP, this class only works with the kitchen and nothing else, but it may not contain all the methods for managing the kitchen. In the case of high consistency, all methods for kitchen management are contained only in this class, and nowhere else. This is an important distinction.
Characteristics of microservices
- Division into components (services).
- Grouping by business tasks.
- Services have business meaning.
- Smart services and simple communications.
- Decentralized management.
- Decentralized data management.
- Automate deployment and monitoring.
- Design for failure (Chaos Monkey).
Division into components (services)
Components are of two kinds: libraries and services that interact over a network. Martin Fowler defines components as independently replaceable and independently deployable. That is, if you can take something and calmly replace it with a new version, this is a component. And if something is connected with another and cannot be independently replaced (contracts, assemblies, versions ... must be taken into account) - together they form one component. If something cannot be deployed independently, and logic is needed from somewhere else, this is also not a component.
Grouping by business tasks (services have business meaning)
Here is the standard monolith layout:

To increase the efficiency of development, you also often have to divide the teams and teams: there is a team that deals with the UI, there is a team that deals with the core, and there is a team that understands the database.
If you go to the microservice architecture, services and teams are divided by business objectives:

For example, there may be a group that deals with order management - it can process transactions, make reports on them, etc. Such a group will deal with the corresponding databases and the corresponding logic, and maybe even the UI. However, in my experience, UI could not be sawn yet - it had to be left monolithic. Maybe we can do this in the future, then be sure to tell the others how you achieved it. Be that as it may, even if the UI remains monolithic, it is still much better when the rest is broken down into components. Nevertheless, I repeat, it is very important to understand WHY you do it - otherwise one day you will have to redo everything back.
Smart services and simple communications
There are different options for the interaction of services. It happens that they take a very smart bus that knows about routing, and about business rules (for example, some BizTalk), and ready-made objects arrive at the services. Then it turns out a very smart middleware and stupid endpoints. This is, in fact, anti-pattern. As time has shown (by the example of the same Internet), we have a very simple and unpretentious data transmission environment - she absolutely does not care what you transmit, she does not know anything about your business. All the brains are sitting in the services. It is important to understand. If you put everything in the transmission medium, you will have a smart monolith and stupid database wrapper services.
Decentralized storage
From the point of view of service-oriented architectures and, in particular, microservices, decentralized storage is a very important point. Decentralized storage means that each service has its own and only its own database. The only case where different services can use the same repository is if these services are exact copies of each other. Databases do not interact with each other:

The only interaction option is networking between services:

Middleware here may be different - we'll talk more about this. The discovery of services and the interaction between them can occur simply directly, through an RPC call, and maybe through some ESB.
Automate deployment and monitoring
Automation of deployment and monitoring is something without which the microservice architecture is better not even fit. T. h. You must be willing to invest in this and hire a DevOps engineer. You will definitely need automatic deployment, continuous integration and delivery. Also, you will need continuous monitoring, otherwise you just can not keep track of all the numerous services, and everything will turn into some kind of hell. It is useful to use all sorts of useful things that help centralize logging - you can not write them, because there are good ready-made solutions like ELK or Amazon CloudWatch.
Design for Failure (Chaos Monkey)
From the very first stage, starting to build a microservice architecture, you should proceed from the assumption that your services do not work. In other words, your service should understand that it can never be answered if it expects some data. Thus, you should immediately start from the situation that something may not work for you.
For example, for this, Netflix developed Chaos Monkey, a tool that breaks services, randomly turns them off and tears up connections. This one needs to evaluate the reliability of the system.
How will services interact with each other?
Take the example of a simple application. The pictures below, I took from Chris Richardson 's blog on NGINX - it tells in detail what microservices are.
So, let's say we have some kind of client (not necessarily even a UI th), which, in order to provide someone with the necessary data, interacts with a set of other services.

It would seem that everything is simple - the client can apply to all these services. But in reality, this translates into the fact that the client configuration becomes very large. Therefore, there is a very simple Gateway API template:
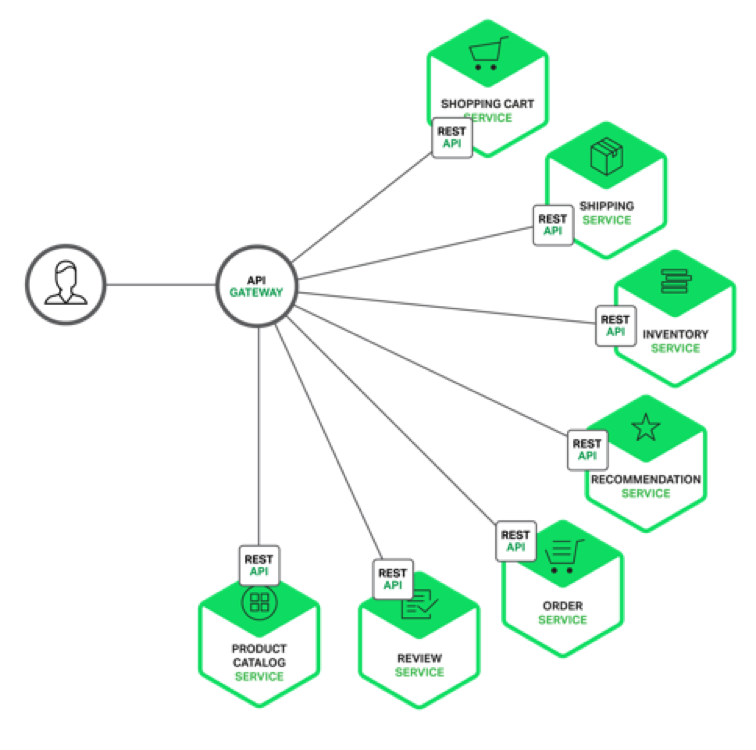
API Gateway is the first thing to consider when you are doing a microservice architecture. If you have a number of services in the backend, set a simple service for them, whose task is to collect business calls to the target services. Then you will be able to implement a mapping of transport (transport will not necessarily be a REST API, as in the picture, but in any way). API Gateway provides data in the form in which it is needed specifically for this type of users. For example, if there is a web and mobile application, you will have two API Gateway, which will collect data from the services and provide them a little differently. In no case should API Gateway contain any serious business logic, otherwise this logic would be duplicated everywhere, and it would be difficult to maintain. API Gateway only transfers data, that's all.
Different types of microservice architecture
So, let's say we have a UI, API Gateway and a dozen services behind it, but this is not enough - you can't build a normal application. After all, usually services are somehow interconnected. I see three ways to link services:
- Service Discovery (RPC Style) - services know about each other and communicate directly.
- Message Bus (Event-driven) - if you use the “publisher-subscriber” template and neither the “subscriber” knows those who subscribe to it, nor the “publisher” does not know where the content comes from. They are only interested in content of a certain type - they subscribe to messages. This is called a message-driven or event-driven architecture.
- Hybrid - a mixed version, when for some cases we use RPC, and for others - the message bus.
Service Discovery
Service Discovery (RPC Style)
Here is the simplest version of Service Discovery:
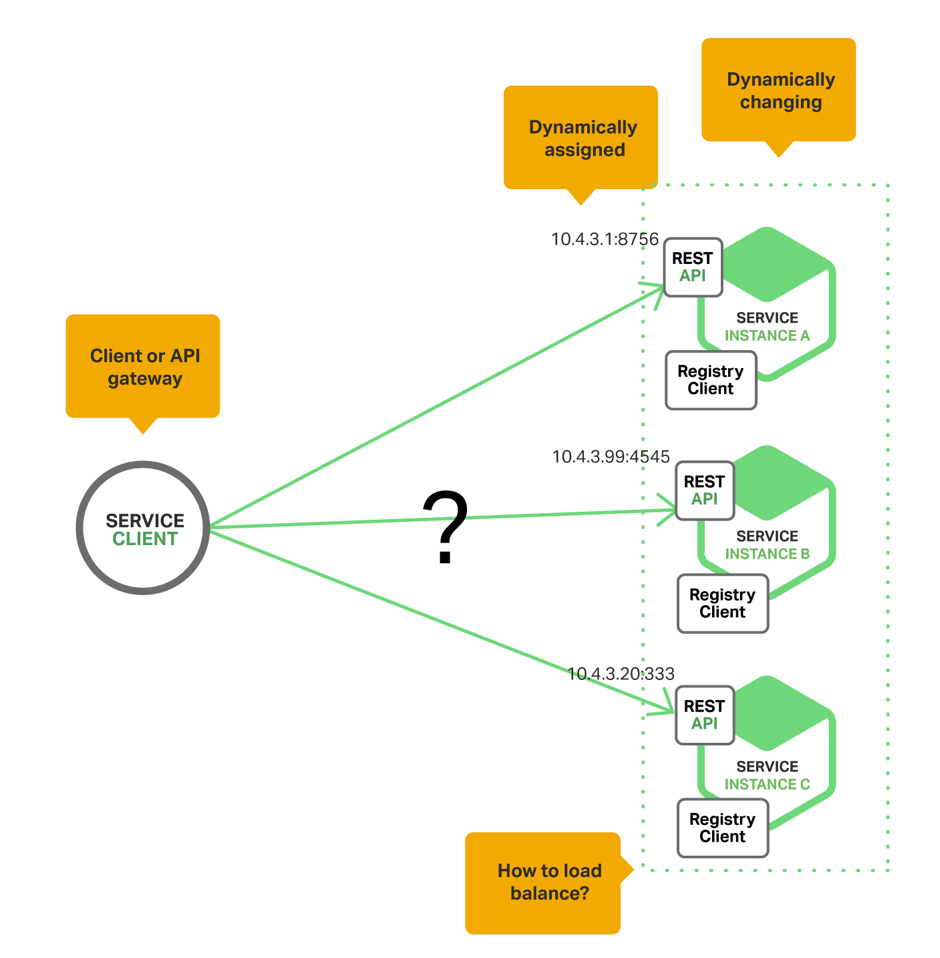
Here we have a customer who accesses various services. However, if the address of a particular service is sewn up in the client's configuration, we will be tied hand and foot, because we may want to redefine everything, or there may be another instance of the service. And here Server-Side Service Discovery will help us.
Server-Side Service Discovery
With Server-Side Service Discovery, your client does not interact directly with a specific service, but with a load balancer (load balancer):

There is a lot of load balancer: Amazon, Azure, etc. have it. Based on its own rules, Load balancer decides who to give the call to if there are more than one service and it is not clear where the service is located.
There is another additional service, the service registry, which also comes in different types, depending on who registers, how and where. You can make the service registry register all types of services. Load balancer takes all the data from the service registry. Thus, the load balancer task is simply to take the location of services from the service registry and scatter requests to them. And the task of the service registry is to store the registration data of the services, and he does it differently: he can interrogate services himself, take data from an external config, etc. The space for maneuvers here seems very broad.
Client-Side Service Discovery
Client-Side Service Discovery is another, radically different way to interact.

There is no load balancer, and the service refers directly to the service registry, from where the service address is taken. What is better? The fact that one request less - so everything works faster. This approach is better than the previous one - but provided that you have a trust system in which the client is internal and will not use the information that it takes from services, to the detriment (for example, for DDoS).
In general, in Service Discovery, everything is quite simple - quite known technologies are used. However, here comes the difficulty - how to implement a more or less serious business process? Still, services with this approach are too closely connected, although we solve the problem from the point of view of deployment and scaling. Service instance A knows that you need to go to the service instance B for data, and if tomorrow you change half of the application and the service instance B function is performed by another service, you will have to rewrite a lot.
In addition, when a transactional situation arises and you need to coordinate the actions of several services, you will need a broker (additional service), which should coordinate everything.
Message bus
Message Bus needs to be able to cook and really need to know what it is. Message Bus is used for well-defined tasks, for example, do not need to make request – reply requests by Message Bus or transfer large amounts of data. The Message Bus (and, in principle, the Publish / Subscribe pattern) breaks suppliers and consumers of information: suppliers do not know who needs information, and consumers do not know where it comes from - one information could theoretically have different suppliers and consumers.
And, no matter how hard you try, in such a system you should have an additional network call - to the broker who collects messages, and another call when these messages need to be delivered. In my experience, transferring large amounts of data (for example, megabytes) via the Message Bus is not worth it. Message Bus - command pattern; it is needed so that one service can inform the other that something has changed in it so that other services can react to it.
In such a situation, a hybrid architecture would help us a lot. Then you take and throw a message on the Message Bus that some data has changed. After that, the subscribers respond to this data, go to the registry, pick up the sender's place where they need to go for the data, and go directly. So you save a lot and unload your tire.
Message Bus: Pros and Cons

Advantages of Message Bus:
- Message Bus determines what your architecture will be.
- It allows you to easily add services, because some services do not know about others.
- Message Bus was originally designed so that all systems can be mapped.
- When you come to the client and say that you will have an ESB, it just sounds cool.
- There are ready-made solutions that were not written by you — such code should not be maintained, and it works well.
Disadvantages of Message Bus:
- Since the Message Bus dictates the architecture, it also dictates the contracts: you must describe the message contracts that you will use. Therefore, contracts are difficult to change, they need to be versioned. You can use various extensible contract mechanisms like ProtoBuf, which allows you to do this conveniently — extended messages are read by previous versions at the expense of a convenient format.
- Usually asynchronous interactions. To work with them correctly,
- need to have good qualifications.
- You add another element to the deployment infrastructure — another risk zone appears. Here you need special knowledge from DevOps-engineer.
Event Driven Architecture - Event Driven Architecture
When our services interact in the RPC style, everything is clear: we have a service that connects all business logic, collects data from other services and returns them, but what about the event-driven architecture? We do not know where to go - we only have messages.
Due to the fact that services work only with their own repositories, we often have a situation when changes in one service require changes in another. For example, we have an order, and we need to check the limits stored in another service (customer service):

This problem has two solutions.
Solution 1
When you initiate the order creation process, send an entity creation message to the bus:

A service that is interested in these events subscribes to them and gets an identification:

Then he performs some kind of internal action and returns the answer, which then arrives in the service of orders, to the bus:

All this is called eventual consistency. This is not happening atomically, but due to the technology of guaranteed delivery of the Message Bus. At the same time, the interaction of services with the bus is transactional, and the bus ensures the delivery of all messages. Therefore, we can be sure that in the end everything will fly to our services (unless, of course, we decide to clear the broker’s messages via the administration console).
If the standard model is called ACID, such a transactional model is called BASE - Basically Available, Soft state, Eventual consistency, which can be interpreted like this: the state you end up with is called “soft state” because you are not completely sure that condition is really relevant.
Solution 2
There is a second way. It may turn out that you do not want to make decisions in this system (or you cannot, due to some requirements) send a message to another service each time, because the response time here will be great. In such a situation, a service that owns certain information — on a credit limit, as in our example — at the time of changing the credit limit notifies all concerned that the information on this client has changed. The service that needs to check the credit limit is checked and retained by itself the projection of the necessary data, that is, only those fields that it needs. Of course, this will be a duplicate of data, but will allow the service not to go anywhere when the order is received.
Here final consistency works again: you can get an order, check its credit limit and consider it as completed. But since at this moment the credit limit could have changed, it may turn out that it does not correspond to the order, and you will have to build compensation blocks - write additional code that will react to such abnormal situations. This is the whole complexity of service architectures - you need to understand in advance that the data with which you operate may be outdated, which can lead to incorrect actions.
There is also a third, very serious approach - Event Sourcing . This is a big topic that requires a separate discussion. In Event Sourcing, you do not store the state of objects - you build them in real time, but only store changes of objects (in fact, users' intentions to change something). Suppose something is happening in the UI, for example, a user wants to place an order. Then you save not a change in the order, not a new state, but separately save external requests: from the user, from other services and from anywhere. Why do you need it? This is necessary for the situation of compensation - then you can roll back the state of the system and act differently.
In general, the Message Bus is a very big topic, within which a lot can be said about the coordination of events. For example, we can mention Saga - a small workflow, which is now being implemented, at least, by NServiceBus and MassTransit. Saga is essentially a state machine that responds to external changes, thanks to which you know what is happening with the system. In this case, from any state you can make a compensation block. T. h. Saga is a good tool for implementing ultimate consistency.
Transition from monolith to microservices
Now I want to talk about how to move from a monolith to microservices, if you decide that this is really what you need. So, you have a big monolith. How now to divide it into parts?
You take out something limited by business logic (what is called a limited context in DDD). Of course, this will have to understand the monolith. For example, a good candidate for a separate service is a part of a monolith, which requires frequent changes. Thanks to this, you get an immediate benefit from the service allocation - you don't have to test the monolith often. It is also good to single out in a separate service what delivers the most problems and does not work well.
When you divide a monolith into services, pay attention to how your teams are structured. After all, there is the Conway's law of empirical law, which says that the structure of your application repeats the structure of your organization. If your organization is built on technological hierarchies, it will be very difficult to build a microservice architecture. Therefore, you need to select feature-teams that will have all the necessary skills to write the necessary logic from beginning to end.
In fact, it rarely happens that we have a clean microservice architecture. Most often we have a cross between a monolith and microservices. Usually there is some big historical code, and we gradually try to untangle it and separate parts from it.
If we are doing a project from scratch, you need to choose - a monolith or microservices?
Monolith is better to choose in the following cases:
- If you have a new domain and / or no knowledge in this domain ..
- If you make a prototype or a quick solution.
- If the team is not very qualified (all beginners, for example).
- If you just need to write code and forget about it.
- If there is not enough money for the project, microservices will be expensive.
It is better to choose microservices if:
- Accurately need linear scaling.
- You understand the business domain, you can highlight a limited context, and you can ensure consistency at the business level.
- The team is highly qualified, there is experience and a pair of ruined projects with microservices in the past (all the same, microservices do not work out the first time).
- Long-term cooperation with the customer.
- Enough funds to invest in infrastructure.
Microservices: “for” and “against”
Benefits:
The microservice approach can be applied even if you do not use the Message Bus, and microservices will be logical. Indeed, from the point of view of deployment, diversity is possible here. .NET, . , . , .
- . — , , . .
- . — .
- , . , , , . - , , . . .
- - : , .
Disadvantages:
- .
- — . . — , . - , — .
- — DevOps-, . .
, , , ZooKeeper, . Logstash, Kibana, Elastic, Serilog, Amazon Cloud Watch. .
? . , - -. — -. , — , , . — . — , , . , . — , , . Swagger, .
(Amazon CEO)
— Amazon.
, 2000 . , Amazon, :
- All teams will henceforth expose their data and functionality through service interfaces.
- Teams must communicate with each other through these interfaces.
- no direct linking
- no direct reads of another team's data store
- no shared-memory model
- no back-doors whatsoever.
- The only communication allowed is via service interface calls over the network.
- It doesn't matter what technology they use.
- All service interfaces, without exception, must be designed from the ground up to be externalizable.
- No exceptions.
, : « . ( — ) : , . . — .
, , . , . . , — Amazon AWS.
Sources
- https://www.nginx.com/blog/
- https://www.nginx.com/blog/introduction-to-microservices/
- https://www.nginx.com/blog/building-microservices-inter-process-communication/
- http://plainoldobjects.com/presentations/decomposing-applications-for-deployability-and-scalability/
- http://highscalability.com/blog/2016/2/10/how-to-build-your-property-management-system-integration-usi.html
- https://lostechies.com/gabrielschenker/2016/01/27/service-discovery/
- http://microservices.io/
- http://martinfowler.com/articles/microservices.html
Source: https://habr.com/ru/post/280083/
All Articles