Sorting tables in Caché DBMS
 But what sorting!
But what sorting! (A. S. Pushkin)
If it were a Twitter post, it would be: “ Caché ObjectScript programmers! Use Cyrillic4 instead of Cyrillic3! ". But here Habr, therefore it is necessary to develop a thought - welcome under cat.
Everything in Caché is stored in globals. Data, metadata, classes, programs. Global nodes are sorted by index values (subscript) and stored on the disk not in the order in which they were inserted, but in the sorted one - for a quick search:
')
USER>set ^a(10)="" USER>set ^a("")="" USER>set ^a("")="" USER>set ^a(2)="" USER>zwrite ^a ^a(2)="" ^a(10)="" ^a("")="" ^a("")="" When sorting, Caché distinguishes between numbers and strings - 2 is treated as a number and sorted before 10. The zwrite command and the $ Order and $ Query functions output global indexes in the order in which they are stored on disk: first, an empty string, then negative numbers, zero, positive numbers, then strings in the order specified by the collation table.
In the simplest case, the sorting table matches each character with a certain sequence number. Further, the sorting table I will call sorting.
Standard sorting in Caché is called Caché standard. It matches each character with its Unicode code.
The sorting with which local arrays are created in the current process is determined by the locale (Management Portal> System Administration> Configuration> Configuring National Language Support). For rusw - the Russian locale of Unicode installations Caché - the default sorting table is Cyrillic3. Other possible sorts in rusw are Caché standard, Cyrillic1, Cyrillic3, Cyrillic4, Ukrainian1.
The ## class (% Collate) .SetLocalName () method changes the sorting for the local arrays of the current process:
USER>write ##class(%Collate).GetLocalName() Cyrillic3 USER>write ##class(%Collate).SetLocalName("Cache standard") 1 USER>write ##class(%Collate).GetLocalName() Cache standard USER>write ##class(%Collate).SetLocalName("Cyrillic3") 1 USER>write ##class(%Collate).GetLocalName() Cyrillic3 Each sort has a steam room in which the numbers are sorted as strings. The name of such a pair sort is obtained by appending "string" to the name of the original sort:
USER>write ##class(%Collate).SetLocalName("Cache standard string") 1 USER>kill test USER>set test(10) = "", test(2) = "", test("") = "", test("") = "" USER>zwrite test test(10)="" test(2)="" test("")="" test("")="" USER>write ##class(%Collate).SetLocalName("Cache standard") 1 USER>kill test USER>set test(10) = "", test(2) = "", test("") = "", test("") = "" USER>zwrite test test(2)="" test(10)="" test("")="" test("")="" Caché standard and Cyrillic3
In Caché standard, characters are sorted in the order of their Unicode codes:
write ##class(%Library.Collate).SetLocalName("Cache standard"),! write ##class(%Library.Collate).GetLocalName(),! set letters = "" set letters = letters _ $zconvert(letters,"U") kill test // test for i=1:1:$Length(letters) { set test($Extract(letters,i)) = "" } // test set l = "", cnt = 0 for { set l = $Order(test(l)) quit:l="" write l, " ", $Ascii(l),"," set cnt = cnt + 1 write:cnt#8=0 ! } USER>do ^testcol 1 Cache standard 1025, 1040, 1041, 1042, 1043, 1044, 1045, 1046, 1047, 1048, 1049, 1050, 1051, 1052, 1053, 1054, 1055, 1056, 1057, 1058, 1059, 1060, 1061, 1062, 1063, 1065, 1066, 1067, 1068, 1069, 1070, 1071, 1072, 1073, 1074, 1075, 1076, 1077, 1078, 1079, 1080, 1081, 1082, 1083, 1084, 1085, 1086, 1087, 1088, 1089, 1090, 1091, 1092, 1093, 1094, 1095, 1097, 1098, 1099, 1100, 1101, 1102, 1103, 1105, All the letters in its place, except for the letters "e" and "E". Their Unicode codes are knocked out of general order. Therefore, the Russian locale needed its own sorting table - Cyrillic3, in which the letters go in the same order as in the Russian alphabet:
USER>do ^testcol 1 Cyrillic3 1040, 1041, 1042, 1043, 1044, 1045, 1025, 1046, 1047, 1048, 1049, 1050, 1051, 1052, 1053, 1054, 1055, 1056, 1057, 1058, 1059, 1060, 1061, 1062, 1063, 1065, 1066, 1067, 1068, 1069, 1070, 1071, 1072, 1073, 1074, 1075, 1076, 1077, 1105, 1078, 1079, 1080, 1081, 1082, 1083, 1084, 1085, 1086, 1087, 1088, 1089, 1090, 1091, 1092, 1093, 1094, 1095, 1097, 1098, 1099, 1100, 1101, 1102, 1103, Caché ObjectScript has a special binary operator]] - “sorted after”. It returns 1 if the left argument in the array index is placed after the right argument, otherwise 0:
USER>write ##class(%Library.Collate).SetLocalName("Cache standard"),! 1 USER>write "" ]] "" 1 USER>write ##class(%Library.Collate).SetLocalName("Cyrillic3"),! 1 USER>write "" ]] "" 0 Globals and sorting tables
Different globals in the same database may have different sorting. Each database has a setting - sorting for new globals. Immediately after installation, all bases except USER have the default sorting for new globals - Caché standard. For USER , depending on the installation locale. For rusw - Cyrillic3.
Creating a global with sorting other than the default sorting for this database:
USER>kill ^a USER>write ##class(%GlobalEdit).Create(,"a",##class(%Collate).DisplayToLogical("Cache standard")) In the list of globals in the Management Portal (System Browser> Globals) for each global, its sorting is shown (fourth column).
You cannot change the sorting of an existing global. You need to create a global with a new sort and copy the data from the old global with the merge command. Mass conversion of globals from one sort to another can be done using the ## class (SYS.Database) .Copy () method
Cyrillic4, Cyrillic3 and umlauts
During the operation of Cyrillic3, it turned out that the conversion of the text index to the internal format takes longer than in the Caché standard sorting, so inserting and navigating the global (or local array) with Cyrillic3 sorting is slower. A new Cyrillic4 sorting has been created, available from version 2014.1. The order of Cyrillic letters in it is the same as in Cyrillic3, but Cyrillic4 is much faster.
for collation="Cyrillic3","Cyrillic4","Cache standard","Cyrillic1" { write ##class(%Library.Collate).SetLocalName(collation),! write ##class(%Library.Collate).GetLocalName(),! do test(100000) } quit test(C) set letters = "" set letters = letters _ $zconvert(letters,"U") kill test write "test insert: " // test set z1=$zh for c=1:1:C { for i=1:1:$Length(letters) { set test($Extract(letters,i)_" " _ $Extract(letters,i)) = "" } } write $zh-z1,! // test write "test $Order: " set z1=$zh for c=1:1:C { set l = "" for { set l = $Order(test(l)) quit:l="" } } write $zh-z1,! USER>do ^testcol 1 Cache standard test insert: 1.520673 test $Order: 2.062228 1 Cyrillic3 test insert: 3.541697 test $Order: 5.938042 1 Cyrillic4 test insert: 1.925205 test $Order: 2.834399 Cyrillic4 is not yet the default sorting in the rusw locale, but by creating your own locus based on rusw, you can specify Cyrillic4 as the default sorting for local arrays. Or specify Cyrillic4 as the default sorting for new globals in the database settings.
Cyrillic3 is slower than Caché standard and Cyrillic4, because it is based on a more general algorithm than sorting two lines depending on the codes of the corresponding characters of these lines.
In German, when sorting, the letter ß should be interpreted as ss . This is how Caché works:
USER>write ##class(%Collate).GetLocalName() German3 USER>set test("Straßer")=1 USER>set test("Strasser")=1 USER>set test("Straster")=1 USER>zwrite test test("Strasser")=1 test("Straßer")=1 test("Straster")=1 Pay attention to the order of the lines. Namely, that the first four letters of the first line are “Stras”, then “Straß”, then again “Stras”. This order can not be achieved if each letter compare some code.
You and I were lucky with the Russian language - there are no umlauts or letters that can be sorted in the same way, like, for example, v and w in Finnish . In Russian, it is enough to give each letter a number, and compare the lines by the number of letters in the corresponding positions. Due to this, it turned out to win in speed in Cyrillic4.
Sort and SQL tables
Do not confuse the sorting table in globals and sorting (also collation) for a column in SQL. The second sort is the transformation applied to the value before putting it into the index global or comparing it with another value. In Caché SQL, the default sorting for strings is SQLUPPER . This conversion converts all letters to upper case, removes whitespace at the end and adds one space to the beginning of the line. Three other SQL collations ( EXACT , SQLSTRING , TRUNCATE ) are described in the documentation .
With some skill it is not difficult to create confusion, when different globals in the database have different sorting, and local arrays are third. SQL for internal use uses the CACHETEMP database, the global sorting of which may also differ from the default sorting of the current locale.
The basic rule is that for ORDER BY in SQL queries to return rows in the expected order, the sorting of globals that store data and indexes of tables participating in the query must be the same as the default sorting for the CACHETEMP database and the sorting of local arrays. For details, see the paragraph in the SQL and NLS Collations documentation.
Create a test class:
Class Habr.test Extends %Persistent { Property Name As %String; Property Surname As %String; Index SurInd On Surname; ClassMethod populate() { do ..%KillExtent() set t = ..%New() set t.Name = "", t.Surname = "" write t.%Save() set t = ..%New() set t.Name = "", t.Surname = "" write t.%Save() set t = ..%New() set t.Name = "", t.Surname = "" write t.%Save() } } Fill in the data (you can then change the names on the lines from the German example):
USER>do ##class(Habr.test).populate() Run the query:

The result is unexpected. The main question is why not the alphabetical order of names (Pavel, Peter, Prokhor)? We look at the request plan:

Key words in this plan are “populates temp-file”. To execute the query, the SQL optimizer decided to use a temporary structure — temp-file — global (in some cases, a local array) visible only to the current process (process-private global). In the indexes of the global values are placed and then displayed in sorted order. Temporary globals are stored in the CACHETEMP database, the sorting for the new globals in which is the Caché standard. But why "e" at the beginning and not at the end? In the indexes of the temporary global, the value of the name field is reduced to uppercase ( SQLUPPER is the default for strings ), respectively, the letter E will be at the very beginning.
By canceling the automatic conversion ( % Exact function), we still get the wrong, but at least the expected order - “” is sorted after all the letters

We will not fix the sorting table in CACHETEMP for the time being - check queries with surname. After all, this column has an index in the global ^ Habr.TestI . Sorting this global is Cyrillic3, so the order of the rows should be alphabetic:

Again, not that. See the plan:

To display the last names in their original form (before the SQLUPPER conversion, which is applied by default to the SurInd index elements), only the index data is small and you need to refer to the table, so the SQL optimizer decided to take the data directly from the table and sort them in a temporary variable - as in the case of name.
If you specify in the request that the upper case suits us, then the order will be correct - the data will be taken directly from the index global ^ Habr.testI :

Request Plan Expected:

Now let's do what had to be done long ago - change the default sorting for new globals in the CACHETEMP database to Cyrillic3 (or Cyrillic4).
Requests that used temporary structures now output the lines in the correct order:
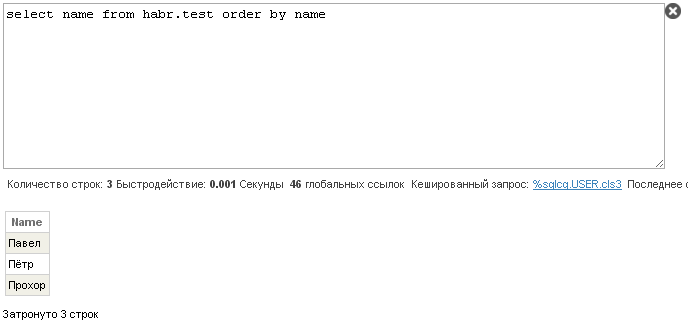

findings
- If you do not care about the order in which the data is displayed with the letter E, use the Caché standard sorting table.
- If you are using Cyrillic3, test your application with the Cyrillic4 sorting table. The app will get faster.
- Check that the same sorting table is in the CACHETEMP database, working database and locale settings.
Source: https://habr.com/ru/post/280081/
All Articles