How to make content recommendations
When dealing with the media, we at Relap.io often come across a mass of misconceptions that everyone believes in, because this has happened historically. The site has blocks like “Read also” or “Hottest”, etc. In short, all that constitutes the binding of the article and seeks to complement the dear reader's UX. We will tell you what misconceptions the media have that make content recommendations and dispel them in numbers.
Recommend by tags
The biggest and most popular misconception. Most often, the media make recommendations at the end of an article by tags. So does Look At Me and RBC, for example. There is material with tags: tractor, Putin, cheese. Texts about a tractor, about Putin and cheese are displayed to him. At first glance, it is logical:

Such a mechanic of recommendations in real life would have looked like this. You go to the grocery store. And put in the basket of butter. A consultant with sweaty palms palms comes up to you and says: “Oh, I see you have taken butter and that means you need butter. Take five more types of creamy rustic and sunflower and goat butter. ” The maximum that can happen out of the ordinary is that you will be offered a transmission if you have read something about cars. And this will already be considered rocket science.
')
But there are situations where you can recommend for tags: for example, a website with reviews of products - here you can assume that a person will want to read several reviews of similar pressure cookers or phones. But you shouldn’t trust the editor who puts down the tags: different people perceive texts differently, and if the editors have more than one, the variety of tags describing more or less the same thing is amazing.
It is better to rely on the machine and isolate keywords from the text automatically. In this case, we get only those words (and even better are stable phrases, collocations, but this is a slightly different story) that are important for a specific text, and not a list of names / trademarks, which are likely to be found in a million articles on completely different topics. .
The simplest (and, in many cases, very effective) way to isolate keywords from text is to use tf-idf and its many variants.
tf-idf - term frequency-inverse document frequency . We see which words and how often are used in the document and give more weight to those words that are rarely found in the corpus. In other words, even if the word "cash" is found only once in the text, it is much more likely to be a significant tag than, for example, the word "Carnival" (except when we index the site for trading sebulcaria).
For those who do not remember, the reverse frequency of the body ( idf ) is calculated as
Where
The frequency of the term is even simpler:
Where
To rank words by importance, we simply multiply these two numbers:
It is easy to see that the inverse frequency is calculated over the whole body, and the frequency of the term depends on the document that we want to analyze. In the case of the Russian language, it would be nice (actually necessary) to bring all the words in the text to dictionary forms or at least lemmatize, but this is not the case at this point (those interested can begin acquaintance with the process with Porter’s algorithm ).
If you calculate a corpus and rank the words in each document by descending value
Shocking truth
The world is a little more complicated. In fact, everything works like this: the user comes to the site, watches the dollar rate, a review of the new iPhone and photos of pandas. So, another person who has already watched the dollar and the iPhone will most likely want to look at the pandas, however strange that may sound. This is called collaborative filtering. There are clusters of users and patterns that can be used to maximize the reader’s involvement in your content.
Test results
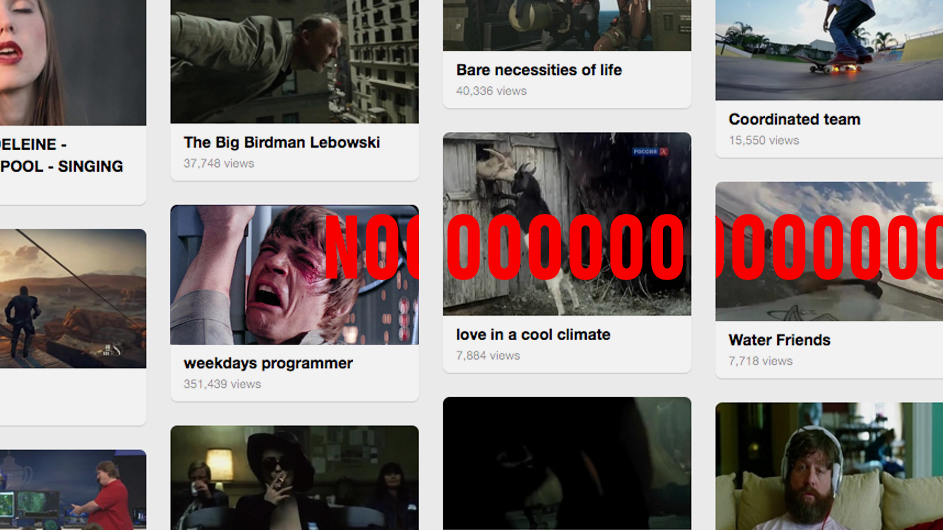
According to the results of A / V tests, collaborative filtering, with no additional settings, gives 20-30% more clicks than selection by tags. And this means that no one should make “Read also” blocks based on tags.
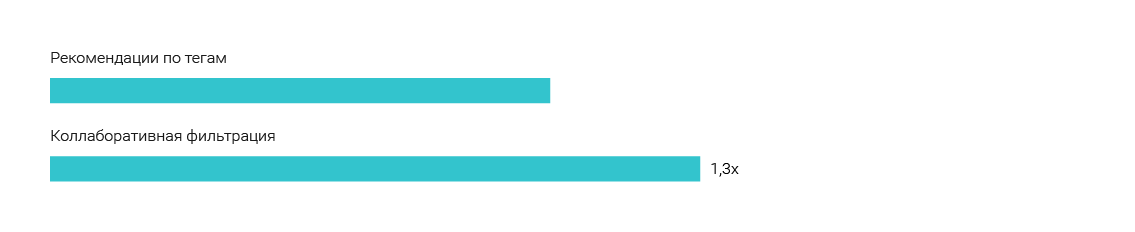
Collaborative filtering is to some extent a continuation of the idea of using tf-idf to isolate meaningful information, but instead of the frequency of words, we use differently weighted “voices” of readers. By voice, we understand some actions: viewing the page, scraping it to the end, something else - a set of events depends solely on the imagination of mathematicians and the programmer’s free time (who writes the code, all this magnificence takes into account).
Just counting the number of events is wrong, so we again calculate the weight of votes. Since readers do not rate (moreover, they do not even know or do not think that by reading an article about the mushroom that grew on the edge near the village council, they help to collect statistics on the reader's preferences of the Bulletin Bulletin Bulletin of readers), we need to determine the "importance" votes using only anonymous and fairly limited information.
The importance of the reader’s voice depends on how active it is, however, with a negative sign: the more articles a user reads over a period of time (for example, 12 hours), the cheaper his voice is. The weight of the vote is a decreasing function of the number of articles read on the resource. Moreover, it makes sense to put a cut-off on top: a person who has read more than 100 articles on the same site for one day is either the editor of this site, or a maniac or bot, and most likely we do not need his recommendations.
Weights can be calculated like this:
Where
Recommend content from the same section.
The second incarnation of the previous fallacy is to segment recommendations by sections.
Imagine that the consultant of the butter department takes you hostage with the words: “Today you will buy only butter, oh yeah, you will buy a lot of butter!” You shout out the doors with a cry and never return to this store.
Test results
We showed segmented recommendations to one group of users: a person reads news from the “Society” section - we recommend him articles only from the “Society” section. Another group received recommendations from the entire site (cross-segment recommendations). The CTR of the widget with recommendations without sections is 2 times higher, the failure rate is 16% lower and the time spent on the site was 23% higher. There is no point in restricting the reader to a single section. Be diverse in your recommendations.
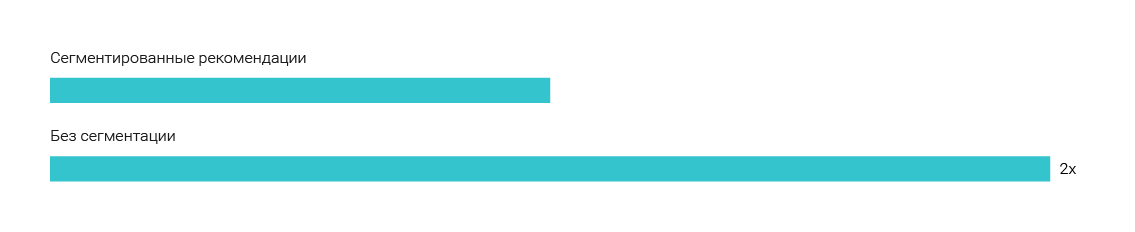
It is easy to see that both collaborative filtering and automatic calculation of tags within one segment will work worse - after all, by breaking the site content into segments and calculating recommendations within each segment, we simply apply the same approach on a smaller sample. Moreover, we get a distorted picture of user activity.
In the end, when ranking users, we are interested in how active a person is online, and not how many articles about the weather he / she reads per day. Well, about the correlation of interests in this case, you can forget: we are not interested in conditional transition probabilities from one section to another (or rather, we are interested, but do not collect statistics for their calculation), so do not lock your recommendations in the section cells, they do not like.
Recommend popular
To recommend popular news means to recommend unnecessary news that everyone has already seen. Popular are materials that many people have watched. That is how popular is becoming popular. Every time you want to make such a block on your site, remember this sentence, because this is how it works. This is the news that everyone saw.
Test results
In the A / B tests, we compared popular and collaborative filtering. CTR widget with collaborative filtering is 7 times higher. This does not mean that our algorithms are so cool. This means that the block is popular on the site - sucks and does not need anyone at all. We understand that the “Popular” block on the site is a must have for most media, but it's time to say goodbye to this delusion.

Popular news needs some time to turn into a button accordion and recommend something that many people are interested in right now is not a bad idea. You just need to clearly understand - when the reader's interest begins to fade, otherwise we would still see only "Labutyens" and the like when trying to find fresh jokes on YouTube - but what? This video scored a billion views, so it is good!
As it is easy to guess, the decreasing function of the age of the event will help us just as the decreasing function of the number of actions performed by the user helped weed out bots and maniacs. However, in the case of the age of views, the weight of each voice should decrease much faster: there are many users and a thousand views in the morning does not mean that someone wants to read about the morning traffic jams for lunch. An inverse relationship to the logarithm of views works well when weighting the votes of one user, to determine the popularity of the negative degree of age works better:
If you look at the last formula for more than three seconds, it is easy to come to the conclusion that the actual amount of weights is not so important, the speed with which it grows is important. Therefore, it is even better not to rank the news according to the “totality of merit,” but according to the speed of the collection of these same merits. Actually, if we take this speed carefully, then we can learn how to predict the virality of the post and do other cosmic things (with the proviso, however, that in this case virality is still not predicted, but detected at an early stage).
Do not set a time limit
Why news publications recommend the news six months ago, it is difficult to understand. Such an approach generates wild examples of the type of this:
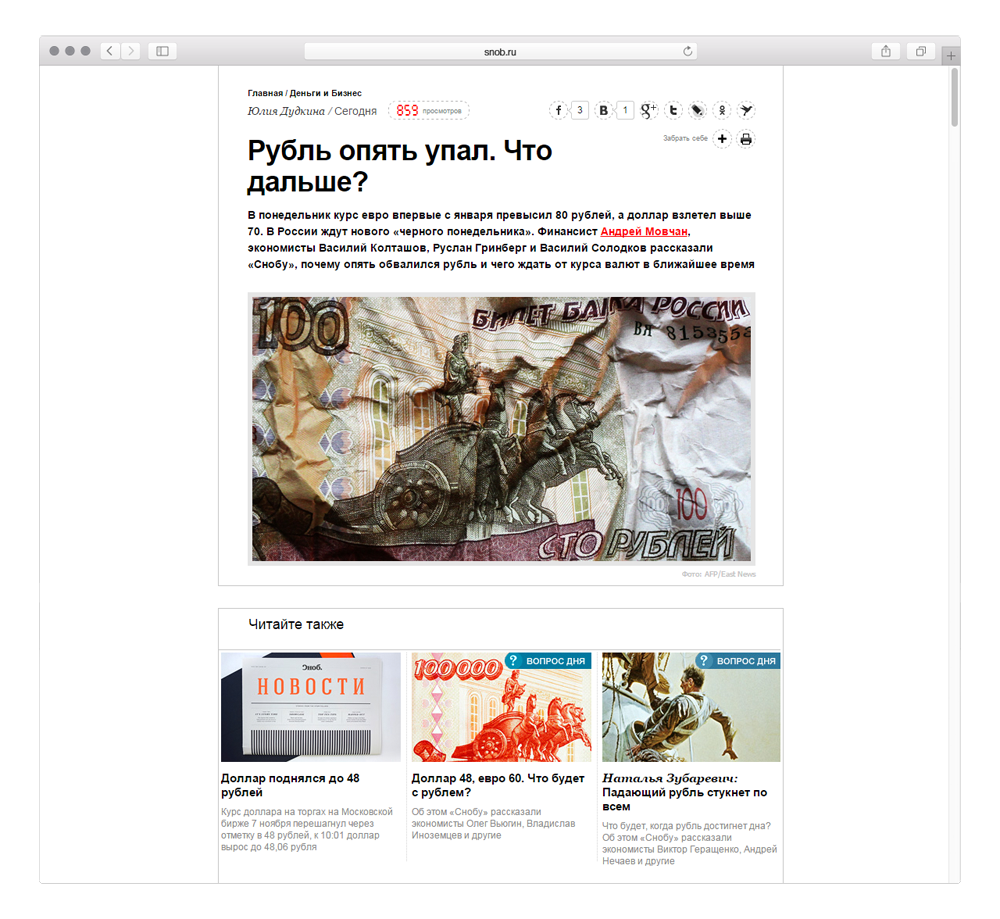
Media thinks the user wants to know what was on the subject before. No, he does not want! He is not interested, and no one is interested.
Test results
During the tests on the news media, we found out the most optimal age of news that should be recommended to visitors. Three options were tested: 72, 48 and 24 hours from the moment of publication. The test sample was 2.7 million readers, the test was carried out a month. Most of our colleagues bet for 24 hours, because it seemed to them that the news very quickly became obsolete, and no one would read yesterday's news. Slightly less people believed in 48 hours. Apparently, because not everyone has time to read the actual for the day and, most likely, they missed something for yesterday and want to catch up. Nobody believed in 72 hours ... Yes, they won 72 hours. In this range, users find the most interesting materials and blocks, collected from such news, clickable by 4.2% more than 48 hours and 10.9% more than 24 hours. This is probably due to the fact that people do not have time (or simply do not want) to consume the entire amount of information generated by the media. Therefore, the news released the day before yesterday, they are still relevant. The exceptions are breaking news.
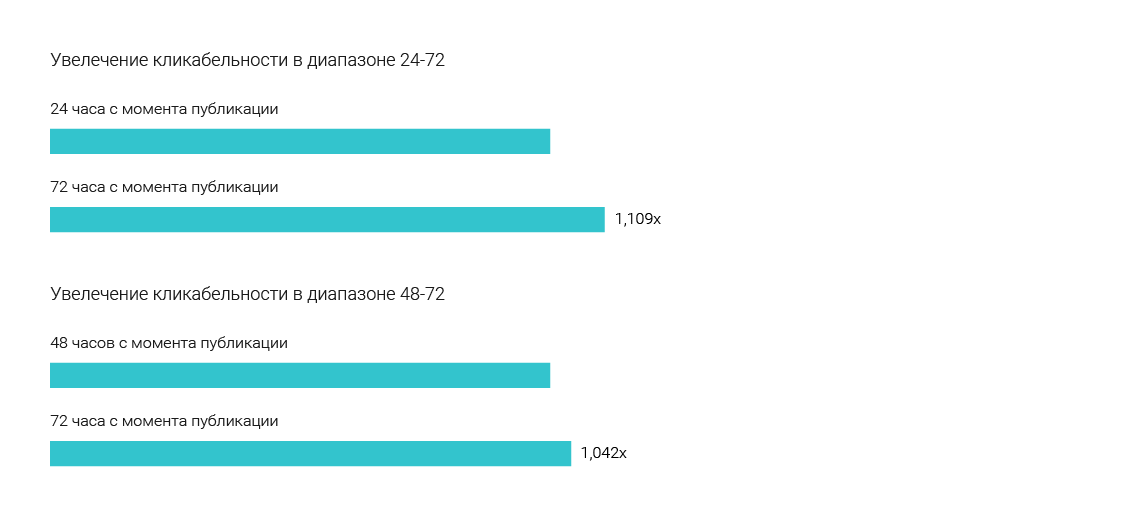
Not to be unsubstantiated, let's look at the statistics of page visits on a relatively large sample (but smaller than that described in the previous paragraph), for example, one million events (page transitions) and look at the age of the articles being read.
At first, let's just see how many different pages are in our sample (all events are collected on one big news site. The following is obtained:
| Age (hours) | Number of pages |
|---|---|
| 0-24 | 719 |
| 24-48 | 841 |
| 48-72 | 581 |
| 72-96 | 368 |
| 96-120 | 238 |
| 120-144 | 73 |
| 144-168 | 85 |
| 168-192 | 147 |
| 192-216 | 141 |
| 216-240 | 110 |
| > 240 | 8152 |
| Total | 11455 |
It is quite obvious that there are many old URLs, but it is also obvious that it is necessary to consider not just the visited URLs, but the distribution of traffic. Look at the number of visits:
| Article age (hours) | Number of events |
|---|---|
| 0-24 | 771 435 |
| 24-48 | 130,431 |
| 48-72 | 26,233 |
| 72-96 | 21,536 |
| 96-120 | 5,214 |
| 120-144 | 673 |
| 144-168 | 287 |
| 168-192 | 965 |
| 192-216 | 1 001 |
| 216-240 | 1,642 |
| > 240 | 40 583 |
| Total | 1000 000 |
As expected, more than 90% of traffic comes from articles published in the last 72 hours.
These are 5 universal rules for all media. In addition, each site has its own behavioral patterns. Depending on them, algorithms are configured. The same set of laws and prohibitions could be formulated for any of our sites.
We are very pleased if this article has helped in the work of your editorial staff and interface design. If you have questions, crazy hypotheses and ideas that you want to implement with us - write to lab@relap.io
If you want to use our technologies, engage readers and generally automate content recommendations on the site, we will be happy to help. Write to support@relap.io
Ask questions. We will answer them in the comments.
Source: https://habr.com/ru/post/279909/
All Articles