How to use parquet and not slip
There is not a lot of information on Habré in storing data in the Parquet files , so we hope the story about the experience of Wrike in its implementation in conjunction with Spark comes in handy.
In particular, in this article you will learn:
- why do we need “parquet”;
- how it works;
- when to use it;
- in which cases it is not very convenient.
')
Perhaps we should start with the question: why did we even begin to look for a new way of storing data instead of preliminary aggregation and saving the result in the database, and what criteria were we guided by when deciding?
In the analytics department of Wrike, we use Apache Spark , a scalable and increasingly popular tool for working with big data (we have various logs and other incoming data streams and events). We described earlier more about how Spark works with us.
Initially, we wanted to deploy the system quickly and without special infrastructural refinements, so we decided to limit ourselves to Standalone by the cluster manager Spark and the text files that Json was recorded to. At that time, we did not have a large input data stream, so we had to deploy hadoop , etc. there was no point.
About what picture we had at the initial stage:
- We tried to get by with the minimal technology stack and make the system as simple as possible, so we immediately discarded Spark over hadoop, Cassandra , MongoDB, and other storage methods that require special management. Our disks are quite smart and coped well with the data flow. In addition, the machines in the cluster are located close to each other and are connected by a powerful network interface.
- Our input data were poorly structured, so it was difficult to isolate a universal scheme.
- The scheme quickly evolved due to the fact that we constantly added new events and improved tracking of user activity, so we chose json as the data format and put them into ordinary text files.
- We aimed to approach event-based analytics. And in this case, each event should be maximally enriched with information in order to keep the number of join operations to a minimum. In practice, data enrichment spawned more and more columns in the schema (this is an important point, we will come back to it). In addition, due to the large number of events of completely different kinds, but interconnected and characterized by different parameters, the scheme also acquired a large number of columns and the information was rather sparse.
- We worked with immutable data: we recorded, and then we only read.
After several weeks of work, we realized that it was inconvenient and time-consuming to work with json data: slow reading, moreover, with numerous test requests each time Spark had to first read the file, determine the schema, and only then pick up directly on the execution of the request itself. Of course, the way Spark can be shortened by specifying the scheme in advance, but we did not want to do this additional work each time.
Having rummaged in Spark, we found that he himself actively uses parquet-format inside.
What is parquet
Parquet is a binary, column-oriented data storage format, originally created for the hadoop ecosystem. The developers claim that this storage format is ideal for big data (immutable).
The first impression was hurray, with Spark it finally became comfortable to work, it just came to life, but, oddly enough, threw us some unexpected problems. The fact is that parquet behaves like an immutable table or database. This means that the type is defined for the columns, and if you suddenly combine a complex data type (say, nested json) with a simple (normal string value), then the whole system will collapse. For example, take two events and write them in Json format:
{
“event_name”: “event 1”,
“value”: “this is first value”,
}
{
“event_name”: “event 2”,
“value”: {“reason”: “Ok”}
}
You cannot write them in the parquet-file, since in the first case you have a string, and in the second a complex type. Worse, if the system writes the input data stream to a file, say, every hour. Events with string values can come in the first hour, and in the second hour - in the form of a complex type. As a result, of course, it will turn out to write parquet files, but with the merge schema operation, you will come across an error of type incompatibility.
To solve this problem, we had to make a small compromise. We defined the exact scheme known by the data supplier for a part of the information, but for the rest, we took only the high-level keys. At the same time, the data itself was recorded as text (often it was json), which we stored in a cell (later using simple map-reduce operations, this turned into a convenient DataFrame) in the case of the example above, ““ value ”: {“ reason ”:“ Ok ”} 'turns into“ “value”: “{\” reason \ ”: \” Ok \ ”}”'. We also encountered some features of splitting data into Spark.
How does the parquet file structure look like?
Parquet is a rather complicated format compared to the same text file with json inside.
It is noteworthy that this format has even taken root in Google’s development, namely in their project called Dremel - this was already mentioned on Habré , but we will not go deeper into the wilds of Dremel, those who wish can read about it here: research.google.com /pubs/pub36632.html .
In short, Parquet uses an architecture based on “definition levels” (definition levels) and “repetition levels” (repetition levels), which makes it possible to code data rather efficiently, and information about the scheme is put into separate metadata.
At the same time, null values are optimally stored.
The structure of the parquet file is well illustrated in the documentation :
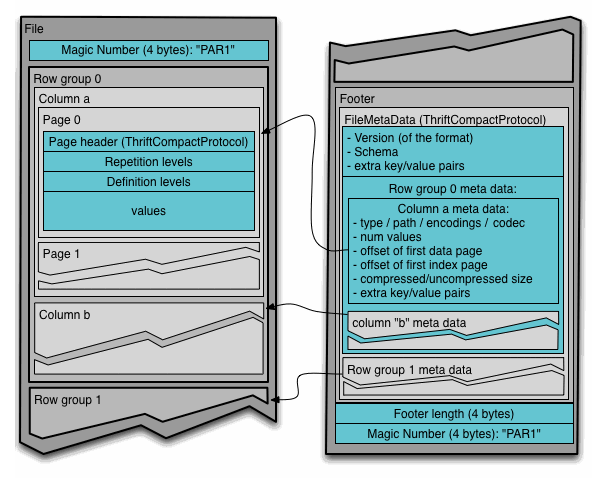
Files have several levels of splitting into parts, due to which a rather effective parallel execution of operations on top of them is possible:
Row-group is a partition that allows you to work in parallel with data at the Map-Reduce level.
Column chunk - split at the column level, allowing you to distribute IO operations
Page - Split columns into pages, allowing you to distribute the work of coding and compression
If you save the data in the parquet file to disk using the file system we are used to, you will find that instead of a file, a directory is created that contains a whole collection of files. Some of them are meta-information, in it is a diagram, as well as various service information, including a partial index, which allows reading only the necessary data blocks upon request. The remaining parts, or partitions, are our Row group.
For an intuitive understanding, we will consider Row groups as a set of files united by common information. By the way, this partitioning is used by HDFS to implement data locality, when each node in the cluster can read the data that is directly located on the disk. Moreover, the row group is a Map Reduce unit, and each map-reduce task in Spark works with its own row-group. Therefore, a worker must place a group of lines in memory, and when setting the size of a group, you must take into account the minimum amount of memory allocated to the task on the weakest node, otherwise you might stumble upon OOM.
In our case, we were faced with the fact that in certain conditions Spark, reading a text file, formed only one partition, and because of this, data conversion was performed on only one core, although much more resources were available. With the help of the repartition operation in rdd, we split the input data, in the end we got several row groups, and the problem was gone.
Column chunk (split at the column level) - optimizes the work with the disk (s). If we present the data as a table, they are not written line by line, but by columns.
Imagine a table:
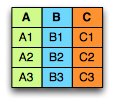
Then in a text file, say, csv, we would store data on a disk like this:

In the case of Parquet:

Thanks to this we can read only the columns we need.
Of all the variety of columns, in fact, the analyst at a particular moment needs only a few, and most of the columns remain empty. Parquet speeds up the process of working with data, moreover - such information structuring simplifies data compression and coding due to their homogeneity and similarity.
Each column is divided into pages ( Pages ), which, in turn, contain meta-information and data encoded according to the principle of architecture from the Dremel project. Due to this, quite effective and fast coding is achieved. In addition, compression is performed at this level (if configured). Currently available codecs snappy, gzip, lzo .
Are there any pitfalls?
Due to the “parquet” organization of data, it is difficult to configure their streaming - if you transfer data, then the entire group is complete. Also, if you have lost the meta information or changed the checksum for the Data Page, then the whole page will be lost (if for the Column chank, then the chank is lost, similarly for the row group). At each of the splitting levels, checksums are built, so you can turn off their calculations at the file system level to improve performance.
Findings:
Advantages of data storage in Parquet:
- Despite the fact that they are created for hdfs, data can be stored in other file systems, such as GlusterFs or over NFS.
- In essence, these are just files, which means that it is easy to work with them, move, backup and replicate.
- The columnar view allows you to significantly speed up the work of the analyst, if he does not need all the columns at once.
- Native support in Spark out of the box provides the ability to simply take and save the file to your favorite repository.
- Efficient storage in terms of space occupied.
- Practice shows that it is this method that provides the fastest reading performance compared to using other file formats.
Disadvantages:
- Column view makes you think about the schema and data types.
- Except in Spark, Parquet does not always have native support in other products.
- Does not support data modification and schematic evolution. Of course, Spark knows how to merge the scheme, if you change it over time (you need to specify a special option when reading), but to change something in an already existing file, you cannot do without overwriting, except that you can add a new column.
- Transactions are not supported, as these are regular files and not DB.
In Wrike, we have been using parquet files for quite a long time as storing enriched event data, our analysts drive quite a lot of requests to them every day, we have developed a special technique for working with this technology, so we’ll be happy to share our experience with those who want to try parquet in business, and answer all questions in the comments.
PS Of course, later we repeatedly revised our views on the form of data storage, for example, we were advised by the more popular Avro format, but so far there is no urgent need to change something.
For those who still do not understand the difference between string-oriented data and column-oriented data, there is an excellent video from Cloudera ,
as well as a rather entertaining presentation about data storage formats for analytics.
Source: https://habr.com/ru/post/279797/
All Articles