Track updates from MongoDB Oplog to Sharded Cluster using Scala and Akka Streams
Introduction
This article is a continuation of the previous published article Tailing the MongoDB Replica Set Oplog with Scala and Akka Streams .
As we discussed before, tracking updates in MongoDB Sharded Cluster Oplog has its pitfalls compared to Replica Set. This article will try to reveal some aspects of the topic.
The MongoDB team blog has some very good articles covering the whole topic of tracking updates from MongoDB Oplog to Sharded Clusters. You can find them at the following links:
- Tailing the MongoDB Oplog on Sharded Clusters
- Pitfalls and Workarounds for Tailing the Oplog on a MongoDB Sharded Cluster
You can also find information about MongoDB Sharded Cluster in the documentation .
The examples given in this article should not be considered and used in production environment. The project with examples is available on github .
MongoDB Sharded Cluster
From the MongoDB documentation:
Sharding , or horizontal scaling, separation and distribution of data across multiple servers or segments (shards). Each segment is an independent database, and collectively, all segments constitute a single local database.
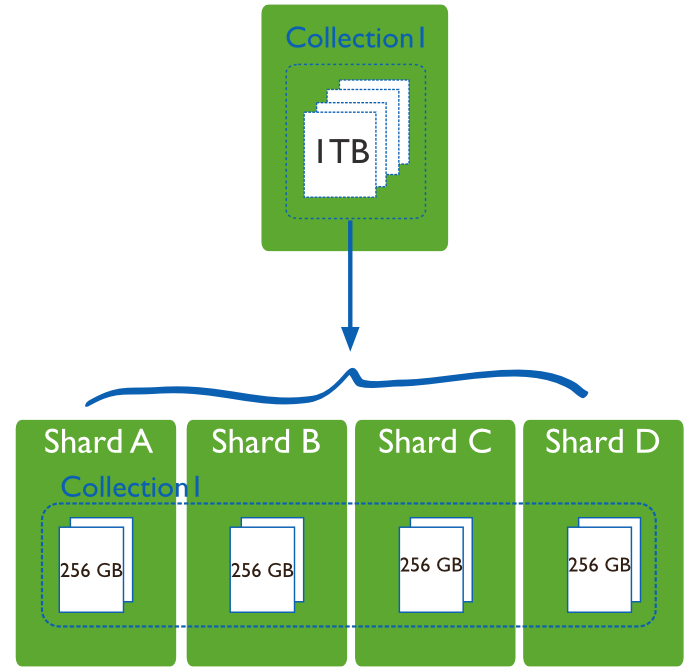
In the production environment, each node is a Replica Set:
')
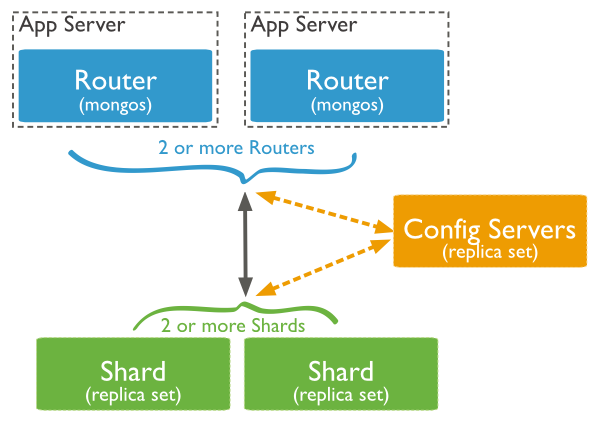
MongoDB internal operations
Because of the distribution of data into several segments, MongoDB has intra-cluster operations that are reflected in the
oplog . These documents have an additional fromMigrate field, since we are not interested in these operations, we will update our oplog request to exclude them from the result. client.getDatabase("local") .getCollection("oplog.rs") .find(and( in(MongoConstants.OPLOG_OPERATION, "i", "d", "u"), exists("fromMigrate", false))) .cursorType(CursorType.TailableAwait) .noCursorTimeout(true) Getting information about nodes
As you may have already guessed, in order to track updates from the
oplog to the Sharded Cluster, we will need to monitor the oplog each node (Replica Set).For this, we can query from the
config database for a list of all available segments. Documents in the collection look like: { "_id" : "shard01", "host" : "shard01/localhost:27018,localhost:27019,localhost:27020" } I prefer to use
case classes instead of Document objects, so I will declare a class: case class Shard(name: String, uri: String) and the function to translate the
Document to Shard : def parseShardInformation(item: Document): Shard = { val document = item.toBsonDocument val shardId = document.getString("_id").getValue val serversDefinition = document.getString("host").getValue val servers = if (serversDefinition.contains("/")) serversDefinition.substring(serversDefinition.indexOf('/') + 1) else serversDefinition Shard(shardId, "mongodb://" + servers) } Now we can make a request:
val shards = client.getDatabase("config") .getCollection("shards") .find() .map(parseShardInformation) In the end, we will have a list of all segments from our MongoDB Sharded Cluster.
Source declaration for each node
To designate the
Source , we can simply go through our list of segments and use the method from the previous article. def source(client: MongoClient): Source[Document, NotUsed] = { val observable = client.getDatabase("local") .getCollection("oplog.rs") .find(and( in("op", "i", "d", "u"), exists("fromMigrate", false))) .cursorType(CursorType.TailableAwait) .noCursorTimeout(true) Source.fromPublisher(observable) } val sources = shards.map({ shard => val client = MongoClient(shard.uri) source(client) }) One Source to control them all
We could process each
Source separately, but of course, it’s much easier and more convenient to work with them as one Source . To do this, we must combine them.Akka Streams has several
Fan-in operations :
- Merge [In] - (N incoming flows, 1 output stream) selects the elements in a random order from the incoming streams and sends them one by one to the output stream.
- MergePreferred [In] - similar to Merge, but if elements are available on the preferred stream, then select elements from it, otherwise choose according to the same principle as ** Merge
- ZipWith [A, B, ..., Out] - (N input streams, 1 output stream) receives a function from N input streams which returns 1 item to the output stream per item from each incoming stream.
- Zip [A, B] - (2 input streams, 1 output stream) is the same as ZipWith designed to connect elements from streams A and B into a stream of pairwise values (A, B)
- Concat [A] - (2 incoming streams, 1 outgoing stream) connects 2 streams (sends items from the first stream, and then from the second)
We use the simplified API for Merge and then output all the elements of the stream to
STDOUT : val allShards: Source[Document, NotUsed] = sources.foldLeft(Source.empty[Document]) { (prev, current) => Source.combine(prev, current)(Merge(_)) } allShards.runForeach(println) Error Handling - Switching and Emergency Rollbacks
Akka Streams uses Supervision Strategies to handle errors. In general, there are 3 different ways to handle errors:
- Stop - The thread ends with an error.
- Resume - The erroneous item is skipped and the thread processing continues.
- Restart - The erroneous item is skipped and stream processing will continue after the current stage is reloaded. Rebooting a stage means that all accumulated data is cleared. This is usually achieved by creating a new stage pattern.
The default is always Stop .
But unfortunately, all of the above does not apply to the
ActorPublisher and ActorSubscriber , so that in the event of any error in our Source we will not be able to correctly recover the stream processing.This issue has already been described on Github # 16916 , and I hope that this will be fixed soon.
Alternatively, you can consider the option suggested in the Pitfalls and Workarounds article for Tailing the Oplog on a MongoDB Sharded Cluster :
Finally, a completely different approach would be if we follow the updates of most or even all the nodes in the replica set. Since a pair ofts & hfield values uniquely identifies each transaction, you can easily combine the results from eachoplogon the application side, so the result of the flow will be the events that were returned by most MongoDB nodes. With this approach, you do not need to worry about whether the node is primary or secondary, you simply follow theoplogall the nodes, and all events that are returned by most of theoplogare considered valid. If you receive events that do not exist in mostoplog, such events are skipped and discarded.
I will try to use this option in one of the following articles.
Conclusion
We did not cover the topic of updates of
orphan documents in MongoDB Sharded Cluster, since in my case, I am interested in all operations from oplog and consider them idempotent across the _id field, so this does not interfere.As you can see, there are many aspects that are quite easily solved with the help of Akka Streams, but there are also difficult ones to solve. In general, I have a double impression about this library. The library is full of good ideas that bring Akka Actors ideas to a new level, but it still feels unfinished. Personally, I will stick with Akka Actors for now.
Source: https://habr.com/ru/post/279675/
All Articles