What makes software quality?

KDPV
Someone creates open source software, and I spend a lot of time thinking about how to make software better. An endless stream of requests for help on the Stack Overflow, GitHub, Slack forums, emails and private messages is inevitable. Fortunately, in the end, you know many people who have achieved some success and did fantastic things, and knowing that you took part in this thanks to you and your help is a good motivation for new achievements.
You have a question: what qualities of software lead a developer to success or to failure? How can I improve my software and help more people become successful? Can I articulate some basic principles or rely on intuition on a case-by-case basis? (The birth and embodiment of one thought are two completely different actions).
')
Perhaps this is something like Dieter Rams principles promoting quality software design?
- Good design is innovative.
- A good design makes the product useful.
- A good design is aesthetic.
- A good design makes the product understandable.
- Good design is unobtrusive.
- Good design is honest.
- Good design is long lasting.
- A good project is thought out to the smallest detail.
- Good design is environmentally friendly.
- In a good design project as little as possible.
The overall picture is probably more important than what I’m writing today, but I know that its “advice” is sometimes impractical or not applicable at all, or, worse, truisms . It's like saying: "Make it as simple as possible, but not too simple." ("Make it as simple as possible, but no simpler". Original note.) . It is clear that we all want things to be simpler. But sometimes we do not know what needs to be done to achieve this goal.
And even if you have the right "general idea" of what you are doing, there is no guarantee that your project will be successful. Methods for translating ideas into life are just as important as the idea itself. The devil is in the details.
I cannot give effective universal advice, but perhaps there is less another way. I was inspired by Thomas Green and Marian Petre , whose “cognitive dimensions” define a set of “discussion tools” to “increase the level of discourse” about the suitability of such “informational artifacts” like code.
- Abstract gradient;
- The proximity of the display;
- Sequence;
- Blurry;
- Propensity to mistakes;
- Complex mental operations;
- Hidden dependencies;
- Premature commitment;
- Progressive assessment;
- Role expressiveness;
- Secondary designation;
- Viscosity;
- Visibility.
No platform is perfect. It (some kind of abstract platform) was created to study the visual programming environment, and in some cases for specific applications. (Consider a situation that simulates the observation of the entire code at the same time. Is any software today small enough to be fully visible on one screen? Perhaps a modular principle would be better?). I believe that it is difficult to assign some problems of usability of one or another dimension. (Both hidden dependencies and role expressiveness imply that with the help of this code something different will be done that is different from what was done before). However, it is good food for thinking about the “cognitive effects” of software design.
I will not define a "general framework." But I do have some observations that I would like to share, and this is just as suitable a time as any other to accomplish the a posteriori rationalization of the past year: I spent approximately as much on D3 4.0 .
I am not returning to the “large-scale” project D3 . I am quite satisfied with such concepts as data connection, scale and markup, separate from the visual presentation. There is also an interesting study here and this is not my last focus. I break D3 into modules to make it suitable for use in more applications, to make it easier to expand for other applications, and easier to develop - but in the process of working with it. I also identify and fix a large number of defects and flaws in the API. These things can easily be overlooked, but at the same time, they largely limit the actions of people.
Sometimes I worry that these changes are trivial, especially if we consider them individually. I hope I can convince you otherwise. I'm worried because I think that we (ie, people who write software) tend to underestimate the usability of programming interfaces, instead considering more objective qualities that are easier to measure: functionality, performance, accuracy.
Such qualities matter, but poor usability has its own, real value. Just ask anyone who struggled to figure out the tangled block of code or tore his hair out while fighting the debugger. Rather, we should better assess usability and create high-quality software that we use first.
You cannot just take a piece of code and feel its weight or texture in your hands. The code is an “information object”, but not a physical or graphic one. You interact with the API by manipulating text in the editor or on the command line.
And yet it is - the interaction according to a given standard with the presence of the human factor. Thus, we can evaluate the code, like any tool, simply by the criterion of the feasibility of its intended task, but is it really that easy to become an experienced programmer and use it effectively? We must consider the possibilities and aesthetics of the code. Is everything pretty clear? Or, on the contrary, sad? Or maybe beautiful?
Programming interfaces are user interfaces. Or, to put it another way: Programmers are people too. On the subject of underestimating the human aspect in developing the design, we will again hear Rams:
“Indifference towards people and the reality in which they live is in fact the one and only mortal sin in design.”
It follows, for example, that good documentation does not justify a bad design. You can advise people to "go smoking mana," but it's silly to assume that they read everything and remember every detail. Clarity of examples, the ability to decrypt and edit software in the real world, is probably much more important. The form must pass the function.
Here are some changes that I make to the eye in D3 for ease of use. But first, an intensive course in data processing in D3.
Case 1. Remove enter.append magic.
“D3” stands for data-driven documents. The data refers to the things you want to visualize, and the document refers to its visual presentation. This is called a “document” because D3 is based on the standard model for web pages: in the document object model .
A simple page might look like this:
<!DOCTYPE html> <svg width="960" height="540"> <g transform="translate(32,270)"> <text x="0">b</text> <text x="32">c</text> <text x="64">d</text> <text x="96">k</text> <text x="128">n</text> <text x="160">r</text> <text x="192">t</text> </g> </svg> This becomes an HTML document containing an SVG element, but you do not need to know the semantics of each element and attribute in order to understand the concept. Just know that each element, for example, ... for a particular piece of text is a discrete graphic character. Elements are grouped in a hierarchical order (hereinafter contains, which contains, and so on) in such a way that you can position and style element groups.
The corresponding sample data set might look like this:
var data = [ "b", "c", "d", "k", "n", "r", "t" ]; This data set is an array of strings. (A string is a sequence of characters, individual letters are located through the lines.) But the data can have any structure you want if you can represent them in JavaScript.
For each record (each line) in the data array, we need the corresponding element in the document. This is the purpose of data-join: a quick method of transforming a document is adding, deleting, or modifying elements so that it matches the data.
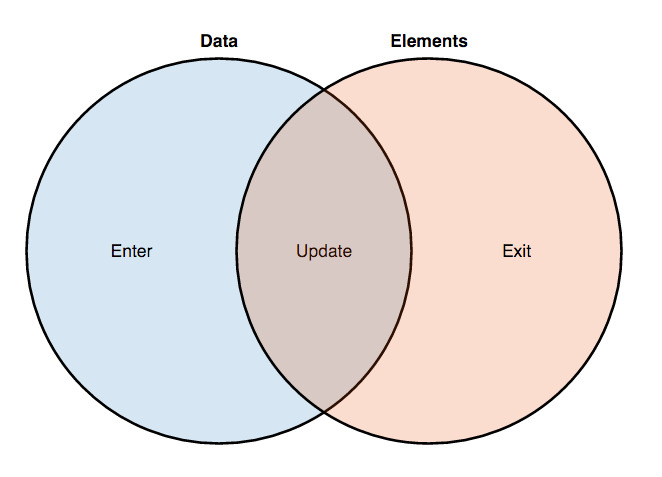
The data-join as the source takes an array of data and an array of document elements, and returns three options to choose from.
Input selection is the "missing" elements (input data) that may be needed to create and add to the document.
Selecting an update represents existing items (data storage) that may need to be modified (for example, repositioning). The selection of the type of output represents the "remaining" elements (outgoing data) that may need to be removed from the document.
Combining data does not change the document itself. It calculates, enters, updates and displays the result, and then you perform all the necessary operations. This provides visibility: for example, to animate input and output elements.

As you might expect, data merging is something you often use both during the first visualization and during each change. The usability of this functional is extremely important for the overall "utility" of D3. It looks like this:
var text = g .selectAll("text") .data(data, key); // JOIN text.exit() // EXIT .remove(); text // UPDATE .attr("x", function(d, i) { return i * 32; }); text.enter() // ENTER .append("text") .attr("x", function(d, i) { return i * 32; }) // .text(function(d) { return d; }); I did not mention some details (for example, a key function that assigns data to elements), but I hope that the essence of the topic is disclosed. After merging with the data, the above code deletes existing elements, rearranges the update adds the incoming elements.
In the above code, there is a
.attr("x", function(d, i) { return i * 32; }) // usability problem (the string .attr("x", function(d, i) { return i * 32; }) // ). This is a duplicate code: sets the attribute "x" to enter and update.Usually these operations are used both for input and for updating elements. If an item is updated (that is, you are not creating it from scratch), you may need to change it. Such modifications are often used to enter items, as they must reflect new data.
D3 2.0 made certain changes to solve the duplication problem: adding an input to the selection will now copy the input of items into the update selection. Thus, any operations applied to the list of updates after adding to the input selection will be used both for input and for modification of elements, thus duplicating code will be eliminated:
var text = g .selectAll("text") .data(data, key); // JOIN text.exit() // EXIT .remove(); text.enter() // ENTER .append("text") // .text(function(d) { return d; }); text // ENTER + UPDATE .attr("x", function(d, i) { return i * 32; }); Alas, it worsened usability.
First, there are no indicators of what is going on inside (poor expressiveness of roles, or perhaps hidden dependencies). Most of the time,
selection.append creates, adds, and selects new items; and by default changes the selection of updates. Surprise!Secondly, the code now depends on the order of operations: if the operations for selecting updates are applied before
enter.append , they only affect the update of nodes; if they are applied later, then, in this case, they affect both the input and the updates. The goal of data aggregation is to eliminate such complex logic, as well as to apply a more declarative specification of document conversions without complex branching and iteration. The code may look much simpler.D3 4.0 removes the
enter.append . (In fact, D3 4.0 completely eliminates the distinction between input and selection: now there is only one class to choose from). In its place is the new selection.merge method, which can combine input selection and updating: var text = g .selectAll("text") .data(data, key); // JOIN text.exit() // EXIT .remove(); text.enter() // ENTER .append("text") .text(function(d) { return d; }) .merge(text) // ENTER + UPDATE .attr("x", function(d, i) { return i * 32; }); This method eliminates duplicate code without distorting the behavior of the generally accepted method (selection.append) and without introducing a dependency ordering. In addition, the selection.merge method is an unfamiliar pointer for readers, which they can find in the documentation.
Principle 1. Avoid semantic overload.
What conclusion can we draw from this failure? D3 3.x violated the Rams principle: good design makes the product understandable. Regarding the dimension, it was not consistent because
selection.append behaved differently on the input selection. This method had poor expressiveness of roles, because its behavior in the past was not obvious. There is also a hidden relationship: text selection operations should be run after adding input, although nothing in the code makes this requirement obvious.D3 4.0 avoids overloading the value. Instead of adding functionality to
enter.append by default - even if it is useful in the general case - selection.append always adds only elements. If you want to combine samples, you need a new method! Therefore, this is selection.merge .Case 2. Elimination of magic transition.each
The transition is similar to choosing an interface for animating changes to a document. Instead of changing the document instantly, transitions smoothly interpolate the document from its current state to the desired target state for a certain time.
Transitions can be non-uniform: sometimes you need to synchronize the transition through multiple selections. For example, to go on an axis, you should tick off the location of lines and tags at the same time:
Or as one of the options:
bl.ocks.org/1166403 One way of specifying such a transition: d3.selectAll("line").transition() .duration(750) .attr("x1", x) .attr("x2", x); d3.selectAll("text").transition() // .duration(750) // .attr("x", x); (Here, x is a function, the same as the linear scale, which serves to calculate the horizontal position of each tick from its corresponding data value).
With these two lines (
d3.selectAll("text").transition() // and .duration(750) // ) you need to be careful. Duplicate code appears again: transitions for the string and text elements are created independently, so we need to duplicate synchronization parameters such as delay and duration.The problem is the absence of any guarantee that these two transitions are synchronized! The second transition is created after the first, so it starts a little later. The difference of one or two milliseconds can be invisible here, unlike other applications.
D3 2.8 introduced a new function to synchronize this kind of heterogeneous transitions: it added the magic of
transition.each - a method for iterating over each selected element - in such a way that any new transition created within the callback will inherit synchronization from the surrounding transition. Now we can say that: var t = d3.transition() .duration(750); t.each(function() { d3.selectAll("line").transition() // .attr("x1", x) .attr("x2", x); d3.selectAll("text").transition() // .attr("x", x); }); Just like
enter.append , it has poor usability: it changes the behavior of existing methods (selection.each and selection.transition) without notifying it. If you create a second transition at a given choice, it does not replace the old one; you simply re-select the old transition. Oops!This example, unfortunately, was invented for pedagogy. There is another clearer way (even in D3 3.x) to synchronize transitions by sampling, using transition.select and transition.selectAll:
var t = d3.transition() .duration(750); t.selectAll("line") .attr("x1", x) .attr("x2", x); t.selectAll("text") .attr("x", x); In this case, the transition t to the root directory of the document is applied to the string and text elements by selecting them. This transition is a limited solution to this problem: the transition can only be applied to a new choice. Repeated selection is always possible, but it is unnecessary work and extra code (especially for temporary input, updating, and exit choices returned by the data fusion).
D3 4.0 removes the ambiguity of the transition.each transition logic; it now provides an implementation of the selection.each command. Instead, the selection.transition command can be transferred via conversion tools, with the result that the new transition will inherit the time from the specified transition. Now we can achieve the desired synchronization when creating new choices:
var t = d3.transition() .duration(750); d3.selectAll("line").transition(t) .attr("x1", x) .attr("x2", x); d3.selectAll("text").transition(t) .attr("x", x); Or when using existing selections: var t = d3.transition() .duration(750); line.transition(t) .attr("x1", x) .attr("x2", x); text.transition(t) .attr("x", x); New design distorts selection.transition behavior. But the new signature method (method with the same name, but with different parameters) is a fairly common design pattern, the difference in behavior is located in a single call.
Principle 2. Avoid behavior patterns.
This principle is a continuation of the previous one, in order to avoid overloading the value for a more egregious violation. Here D3 2.8 introduced an inconsistency with selection.transition, but the behavioral trigger was not another class; he was just inside the transition.each call. A remarkable consequence of this construction is that you can change the behavior of code that you did not write by wrapping it with transition.each!
If you see code that sets a global variable to trigger a global change in behavior, this is most likely a bad idea.
Looking back, I conclude that this time it is particularly striking. What was I just thinking about? Maybe I'm a failed designer? There is some consolation in understanding why bad ideas are attractive: it is easier to recognize and avoid in the future. Here I recall trying to minimize the imaginary complexity, avoiding the use of new methods. However, this is a clear example of where the introduction of new methods (or signatures) is easier than overloading existing ones.
Case 3. Remove the magic d3.transition (selection)
A powerful concept in most modern programming languages is the ability to define reusable blocks of code as a function. Turning code into a function, you can call it wherever you want, without resorting to copying and pasting. While some software libraries define their own abstractions for code reuse (say, extending the diagram type), D3 is an indicator of how to encapsulate code, I recommend doing it only with a function.
Since selection queries and transitions share many methods such as selection.style and transition.style for setting style properties, you can write a function that will affect both selection queries and transitions. For example:
function makeitred(context) { context.style("color", "red"); } You can set the makeitred selection to instantly repaint the text to red:
d3.select ("body") .call (makeitred);But you can also pass makeitred a transition, in which case the text color will turn red for a short period of time:
d3.select("body").transition().call(makeitred);This approach is applied with embedded D3 components, such as axes and brushes, as well as modes such as zooming.
The glitch of this approach is that transitions and selections do not have identical APIs, so not all code can be agnostic. Operations such as counting data aggregation in order to update axis check marks require sampling queries.
D3 2.8 provided another erroneous function for this use case: it overloaded d3.transition, which usually returns a new transition to the root directory of documents. If you entered the d3.transition command, and were inside the transition.each callback, then the d3.transition command would return a new transition to the specified choice; otherwise, it would simply return the specified selection. (This function was added to the same commit as the transition.each defect mentioned above. There is no trouble alone!)
From my cumbersome description, you must conclude that creating this function was a bad idea. But let's look at it in more detail, for science. Here is a similar way of writing the above-mentioned
makeitred function, which limits the code (using s) in choosing an API with another code (using t), instead applied to the API transition, if the context is a transition: unction makeitred(context) { context.each(function() { // var s = d3.select(this), t = d3.transition(s); // t.style("color", "red"); }); } The confusion of the
transition.each function is as follows: d3.transition calls the selection.transition and is inside the transition.each callback, so the new transition inherits synchronization from the surrounding transition. The problem is that d3.transition does not do what it should. And there is also confusion in the fact that both the context and t are unknown types — either of choice or of transition — although this may be justified by the convenience of calling the makeitred function both for selection and for transition.D3 4.0 removes
d3.transition (choice); d3.transition can now be used only to create a transition to the root directory of the document, in the same way as d3.selection . To share the choice and the transition, use your usual JavaScript command to check the types: instanceof or duck typing , depending on your preferences: function makeitred(context) { var s = context.selection ? context.selection() : context, t = context; t.style("color", "red"); } Notice that in addition to removing the magic of
transition.each and d3.transition functions, the new makeitred function avoids transition.each completely, still allowing you to write code that is specific to choosing D3 4.0's and using the new transition.selection method. This is a contrived example of when the choice of s is not used, and t has the same meaning as the context, and thus it can be trivially reduced to the original definition: function makeitred(context) { context.style("color", "red"); } But this is my personal opinion. The need to select a particular code should not require complete correspondence using the
transition.each ! Green and Petra called it a premature commitment.Principle 3. Neat use
The
d3.transition method d3.transition to merge the two operations. The first is checking your presence within the transition.each callback command. If you are still there, the second operation retrieves the new transition from the sample. However, the latter can use selection.transition, so d3.transition trying to do too much and, as a result, it also hides too much.Case 4. Repetition of transitions from d3.active
D3 transitions are finite sequences. Most often, the transition is the stage of transition from the current state of the document to the desired one. However, sometimes you need more thoughtful sequences that go through several stages:
(Be careful when preparing your animation! Read the information about animation transitions in Statistical Data Graphics by Heer & Robertson.)
You may want to repeat the sequence that is described in this example:
D3 does not have a special method for infinite transition sequences, but you can create a new transition when the old one is already finished. This led to the most confusing example of code I've ever written:
svg.selectAll("circle") .transition() .duration(2500) .delay(function(d) { return d * 40; }) .each(slide); // function slide() { var circle = d3.select(this); (function repeat() { circle = circle.transition() // .attr("cx", width) .transition() .attr("cx", 0) .each("end", repeat); })(); // } I do not even dare to try to explain something after the "cognitive consequences", from which we previously abstained. But you are very far from this, so I will do my best. First,
transition.each runs a callback that iterates through the loop. Callback specifies the closing of a repeated call that fixes a circular variable. Initially, a cycle is a selection of a single cycle element; The first stage of the transition is thus created using selection.transition , inheriting time from the surrounding transition! The second stage is created using transition.transition so that it begins only after the end of the first. The second stage is assigned to the cycle. Finally, each time a two-step transition sequence ends, a repeat command is executed, which repeats and revises the transition cycle.In addition, you probably noticed that
transition.each with one parameter does something completely different from transition.each with two parameters?Wow!
Now let's compare with D3 4.0:
svg.selectAll("circle") .transition() .duration(2500) .delay(function(d) { return d * 40; }) .on("start", slide); function slide() { d3.active(this) .attr("cx", width) .transition() .attr("cx", 0) .transition() .on("start", slide); } D3 4.0 provides
d3.active , which returns the active transition on the specified element. This eliminates the need to obtain a local variable for each loop (cyclic variable), and increases the need to close the call (repeated function), as well as the need for an incomprehensible command transition.each !Principle 4. Incomprehensible solutions are not solutions.
This is the case when there is a way to solve the problem, but it is so complex and wobbly that you can hardly find it, and hardly remember it at all. Although I wrote the library, I still constantly appeal to Google.
In addition, it is ugly.
Case 5: Hanging in the background
D3 3.x , . , "" . :
, , , , . , , , "" !
, : , . , .
D3 4.0 . ; . D3 4.0 , , . , .
5.
. , , .
6. selection.interrupt
Transitions are often triggered by events, such as the arrival of new data through wire or user interaction. Since the transitions are not instantaneous - there may be several of them and they can compete with each other for the right to control the elements. To avoid this, the transitions must be monopoly, which will allow the new transition to exceed (interrupt) the old one.
However, such exclusivity should not be global. Multiple simultaneous transitions must be allowed, provided they work with different elements. If you quickly switch between the grouped panels below, you can send waves that slightly oscillate through the diagram:

Transitions D3 are exclusive for each element by default. If you need exclusivity, there is
selection.interruptwhich interrupts the active transition on the selected items.The problem with
selection.interruptD3 3.x is that it does not cancel the unfinished transitions that are scheduled for the selected items. There is no control - the reason may be in another design flaw in D3 3.x's timers, which cannot be stopped by external factors, the abolition of transitions is inappropriate in this case. (Instead, the ousted transition independently ends at the start).The solution to this problem in D3 3.x can be the creation of a blank command, a transition with zero delay after an interruption:
selection .interrupt() // interrupt the active transition .transition(); // pre-empt any scheduled transitions That mostly works. But you can cheat it by scheduling another transition: selection .transition() .each("start", alert); // selection .interrupt() .transition(); Since the first transition is not yet active, it is not interrupted. And since the second transition is scheduled after the first transition, the first transition may start before it is subsequently interrupted.
In D3 4.0,
selection.interruptinterrupts the active transition, if any, and cancels all scheduled transitions. Cancellation is stronger than crowding out: scheduled transitions are immediately destroyed, freeing resources and ensuring that they cannot be launched.Principle 6. Consider all possible uses.
, , , . , API-, , "". " ."
7.
. D3 4.0 , -. , D3 3.x:
selection.transition() .duration(750) .ease("elastic-out", 1, 0.3); , :
- 1?
- 0,3?
- , “elastic-out” ?
- ?
D3 4.0:
selection.transition() .duration(750) .ease(d3.easeElasticOut .amplitude(1) .period(0.3)); 1 0,3 , , , API , :

, ,
transition.ease ; . D3 4.0 .7.
Functions that use many parameters obviously have a poor design. People should not try to remember such complex definitions. (I can't even tell you how many times I had to look for parameters
context.arcin working with 2D canvas.)Since its inception, D3 has approved these properties using the chain method and the single parameter method. But there is still room for improvement. If the code cannot be absolutely obvious, at least it can point to the right place in the documentation.
What is the purpose of good software?
It is not only about quick and correct calculation of the result. And not even just a brief or elegant notation.
People have powerful but limited cognitive abilities. Many actors compete for this ability like little children. The most important thing is that people learn. I hope that my examples have shown how strongly the design of programming interfaces influences the ability of people to understand the code and become experienced programmers.
But learning is beyond the scope of ownership of this tool. If you can apply your knowledge about one domain to other domains, such knowledge is very valuable. That is why, for example, D3 uses the standard document object model, rather than a specific view. It may be more effective in the future when the tools change, but the time you have spent studying a narrow field of knowledge may be wasted!
I do not want you to learn D3 for D3. I want you to learn how to examine data and interact effectively.
Good software is affordable. This can be understood by the example of simple things. You do not need to know everything before you can understand anything.
Good software compatible. , . . .
. . .
. , .
. , . , . .
Source: https://habr.com/ru/post/279459/
All Articles