Parsers to all! Analyzing and testing existing HTML parsers

Hello!
After the publication of the previous article, not a few letters arrived to the post with a request to show and prove how one solution is better than another.
I enthusiastically began to compare, but everything, as usual, is a little more complicated than it seems at first glance.
')
Yes, in this article I propose to put all the parsers on the table and measure!
Let's get started!
Before comparing something, we need to understand: what do we really want to compare ?! And we want to compare html parsers, but what is html parser?
Html parser is:
- Tokenizer (Tokenizer) - breakdown of text into tokens
- Building a Tree (Tree Builder) - placing tokens "in the right position" in the tree
- Further work with wood
A person "from the cold" can say: - "It is not necessary to build a tree for parsing html, it is enough to get tokens". And unfortunately, will be wrong.
The fact is that for proper tokenization of html we need to have a tree at hand. Point 1 and 2 are inseparable.
I will give two examples:
The first:
<svg><desc><math><style><a> The result of the correct processing:
<html> <head> <body> <svg:svg> <desc:svg> <math:math> <style:math> <a:math> Second:
<svg><desc><style><a> The result of the correct processing:
<html> <head> <body> <svg:svg> <desc:svg> <style> <-text>: <a> After the ":" is the namespace, if not specified then html.
From the two examples it is clear that the STYLE element behaves differently depending on where it is located. In the first variant, there is an element A, and in the second, this is already a text element.
Here you can give an example with frameset, script, title ... and their different behavior, but I think the general meaning is clear.
Now, we can definitely conclude that the token splitting cannot be correctly implemented without building the html tree. Consequently, HTML parsing cannot be done without at least two stages: tokenization and tree building.
As for the terms: "strict", "does not meet the specifications", "light", "html 4" and the like ... I am sure that all these terms can be safely replaced with one: "does not handle correctly." All this is absurd.
How and what will we compare?
And here is the most interesting. Far from everyone can bear the proud title of html parser; moreover, even those who call themselves html identifiers are, in fact, not so.
Having put all the parsers on the table, I immediately had a question - who should I compare with whom?
And we will compare the correct parsers: myhtml, html5lib, html5ever, gumbo.
They correspond to the latest specification, and their result will coincide with what we can see in modern browsers.
Wrong parsers (do not meet the specifications) can vary greatly in speed / memory, but more than that, they simply handle the document incorrectly.
No excuses, like "parser for html 4", will not be taken into account. The world is constantly changing, and you have to keep up with it.
It is worth noting that html5ever is not quite the right parser. The authors write that he does not pass all html5lin-test-tree-builder tests, that is, tests for the correctness of tree construction. He got into the correct parsers for trying to be correct.
Also, at the time of writing this article, html5lib does not correctly build a tree for some HTML format. But these are all the bugs that I hope the authors will fix.
Let's measure time / memory for 466 html files - TOP500 alexa. 466, not 500 because not all sites work and not all give away their content.
For each page, a fork with stages will be created:
- Full parser initialization
- Single page parsing
- Resource Release
Tech will also be a test "from life" - to drive away all the pages, if possible, one object. It will all happen consistently.
To the tests!
We have reached the tests: myhtml, html5ever, gumbo.
Unfortunately, html5lib took off from testing. The preliminary run showed that it was noticeably slower than the others. It makes no sense to compare it, it is written in python and it is slow, very slow.
MyHTML and Gumbo are written in C. html5ever - this is Rust. Growing up I am not strong, not yet strong, and therefore I asked Alexey Voznyuk to help me. Alexey agreed (respect and respect) and made a wrapper for testing the parser.
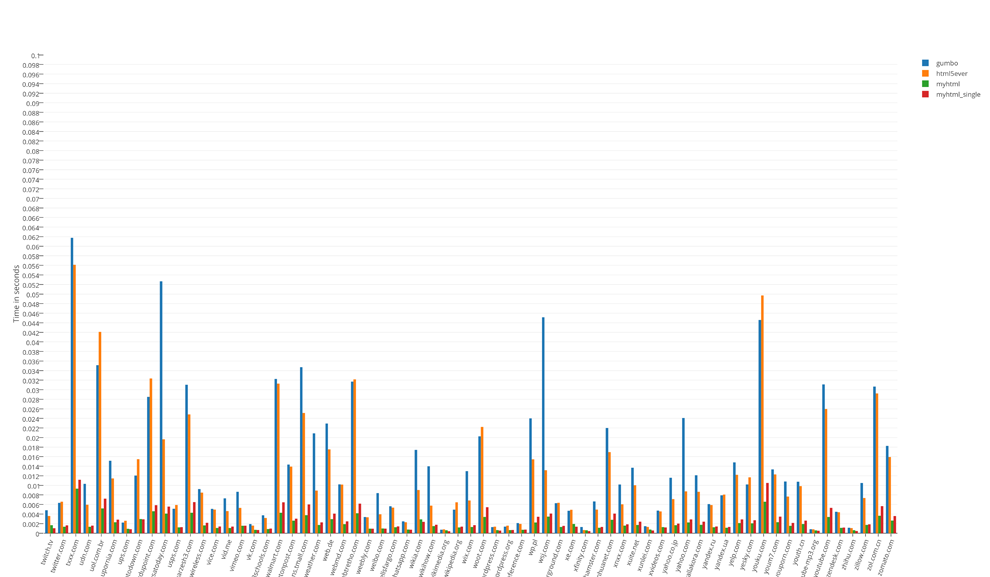
The overall result of the runtime tests:
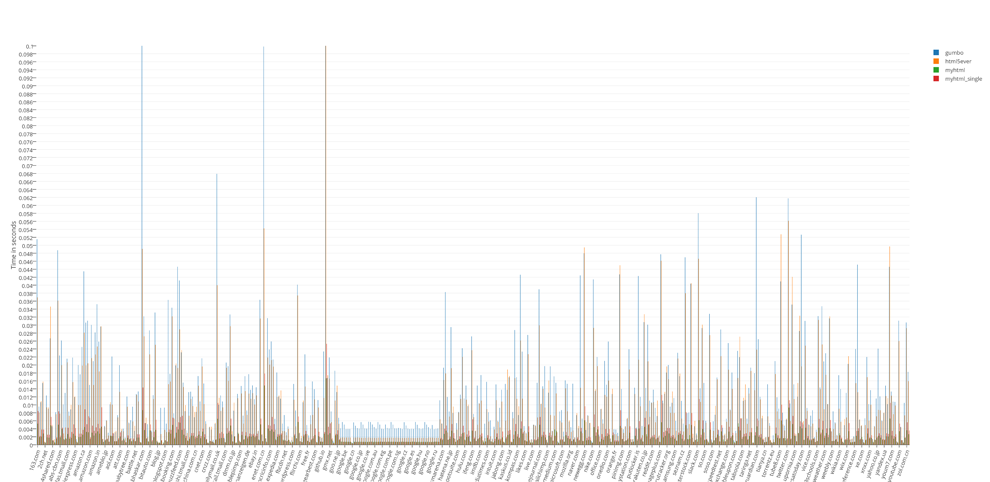
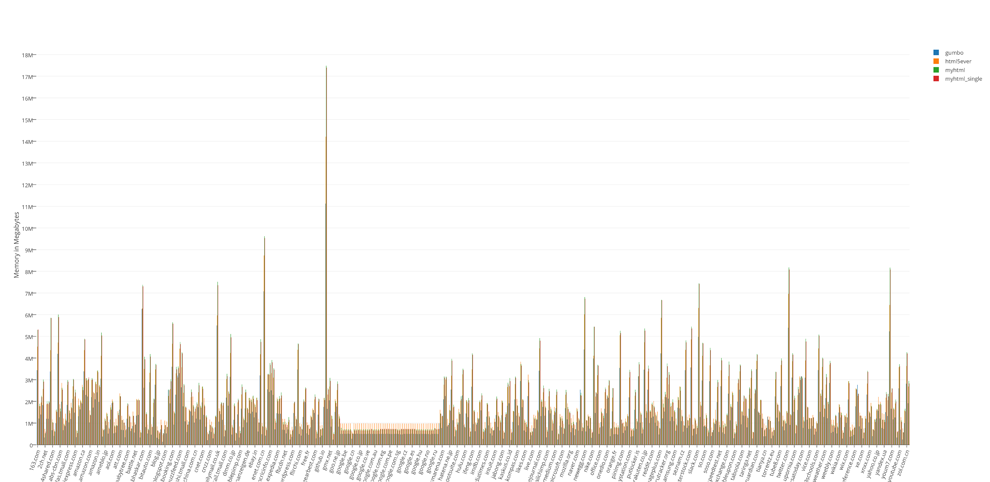
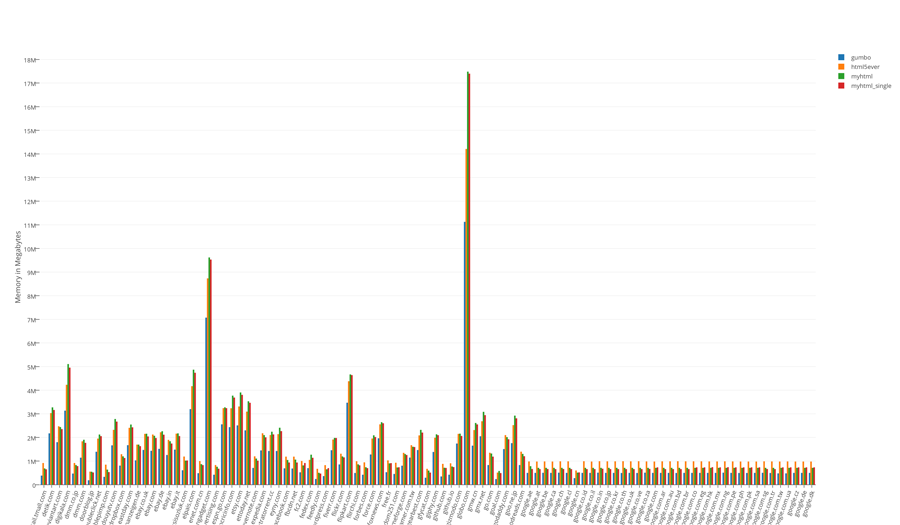
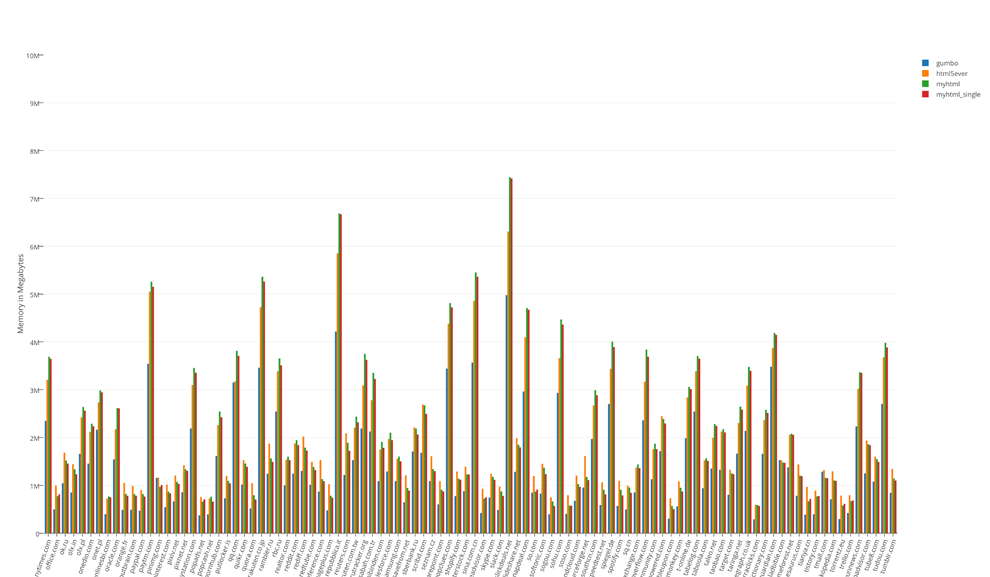
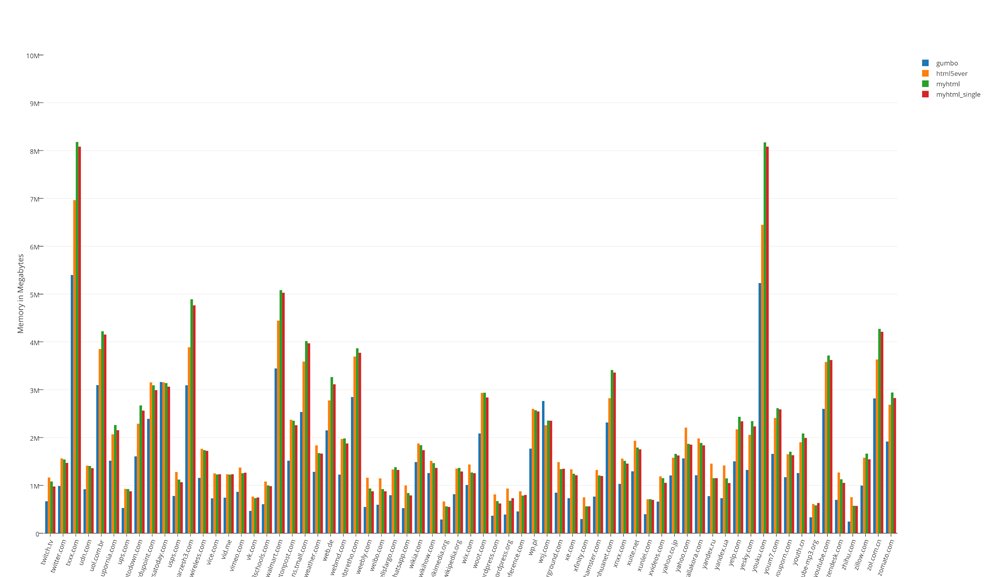
The total result of tests of occupied resources:
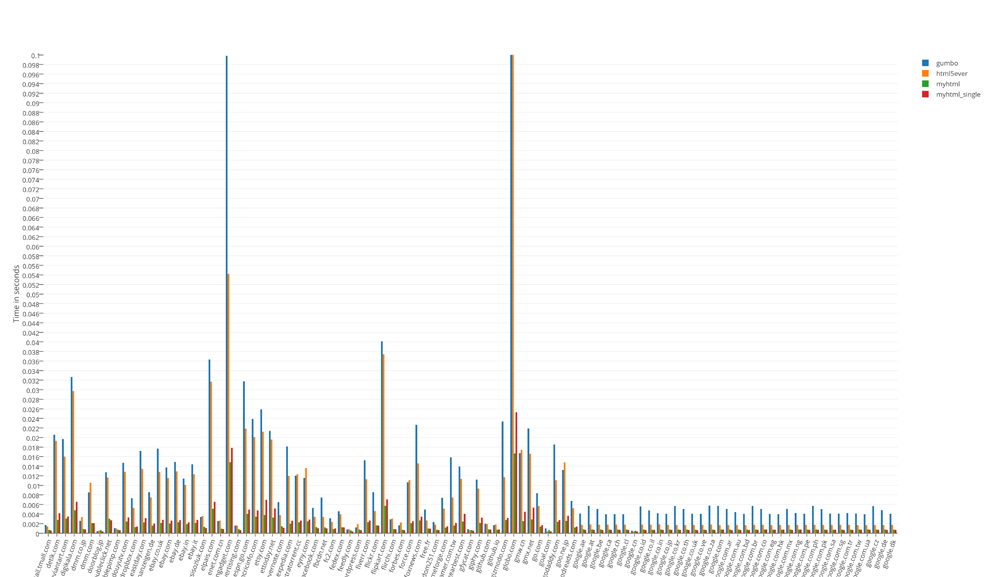
Runtime test results broken down by 100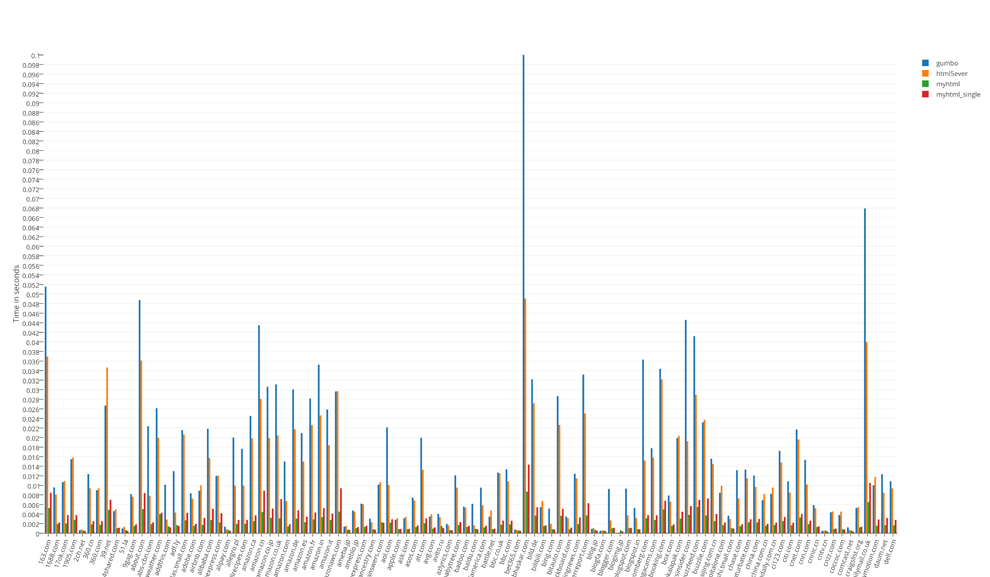


The results of tests of occupied resources divided by 100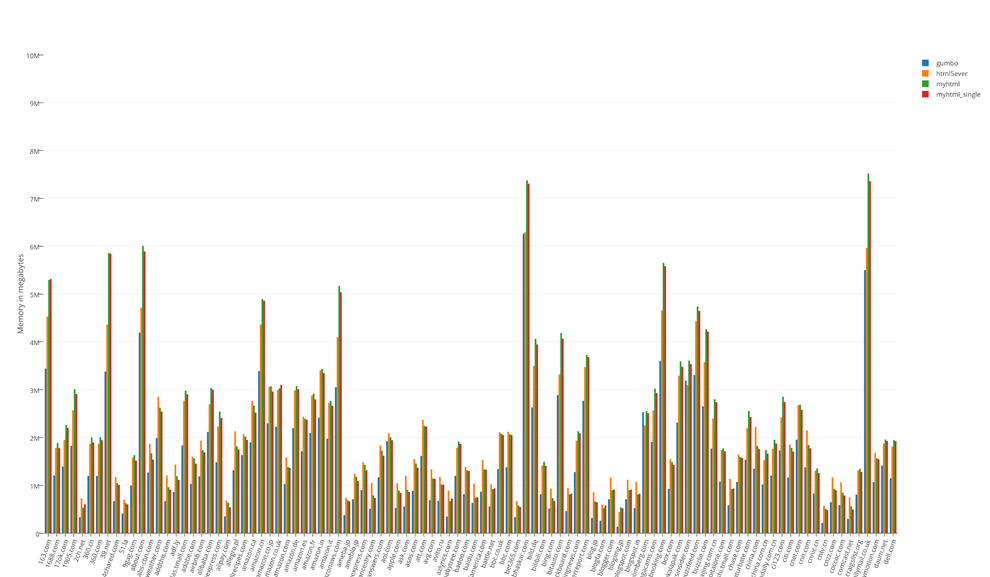

The result of tests "from life." Run all (466) pages in one process:
myhtml :
: 0.50890; : 1052672; : 32120832 gumbo :
: 6.12951; : 1052672; : 29319168 html5ever :
: 4.50536; : 1052672; : 30715904 Results
The undisputed leader in speed is myhtml. gumbo is the memory leader, which is not surprising. html5ever showed itself, to put it mildly, no way. It is not fast and didn’t express itself in memory, and it can only be used from Rust.
The “life” test showed that the differences in the memory are not significant, but in terms of speed, I would not hesitate to say that it is colossal.
What was used
Equipment:
Intel® Core (TM) i7-3615QM CPU @ 2.30GHz
8 GB 1600 MHz DDR3
Software:
Darwin MBP-Alexander 15.3.0 Darwin Kernel Version 15.3.0: Thu Dec 10 18:40:58 PST 2015; root: xnu-3248.30.4 ~ 1 / RELEASE_X86_64 x86_64
Apple LLVM version 7.0.2 (clang-700.1.81)
Target: x86_64-apple-darwin15.3.0
Thread model: posix
Links
Benchmark code
Pictures and CSV
myhtml , gumbo , html5ever
Strapping for html5event from Alexey
Thanks for attention!
PS by myhtml
Being the author of myhtml, it was morally difficult for me to do such testing. But I tried to approach this matter with the utmost responsibility, and to work with each parser as with my own.
Source: https://habr.com/ru/post/279409/
All Articles