Oracle Database 12.1.0.2 New Features
In the process of developing a new version of Oracle Database of Oracle, it was important to consider the two main trends of the modern IT industry. Firstly, the trend of price and available RAM that is characteristic of recent years. After all, the cost of RAM every year drops by 30%, and a typical corporate server today comes with 128 GB of memory, and many servers have 1 TB of memory. This means that if you learn to place databases directly in RAM, requests for them will be executed tens or hundreds of times faster, which opens up the possibility of real-time business intelligence.

Secondly, it is important to remember that in the face of reduced IT costs, developers need new tools that allow them to more quickly innovate and simplify application support. For example, in order to integrate new developments with existing corporate infrastructures, developers are moving away from monolithic applications, complex and difficult to develop, towards the microservice architecture, that is, applications that are sets of independently deployable services. And to work with the new architecture, it is necessary for the database to support new tools and new programming methods.
')
Oracle has taken all this into account when developing the Oracle Database 12.1.0.2 database. This article is an overview of the major innovations of this version.
Let's start with the fact that in 2013, Oracle released Oracle Database 12c (version 12.1.0.1), the main advantages of which were reduced storage costs, high availability of data, ease of consolidating databases and protecting access to data.
In more detail, this version introduces the Oracle Multitenant architecture, which greatly simplifies database consolidation, speeds up database deployment and allows you to manage many databases as one — instead of administering hundreds of databases individually, the administrator works with one database, managing many databases. data as one. All this made the version of Oracle Database 12c at the time of its release the most suitable database management system for cloud computing, especially for SaaS applications, where high-speed creation of new databases on demand of users is especially important, which, with the support of Snapshot Cloning technology, takes A couple of minutes.
In addition, in Oracle Database 12.1.0.1, automatic data optimization has appeared, combining the technology of “smart compression”, which automatically detects data blocks that are rarely accessed (“cold” data) and compresses them, and multi-level data storage automation technology, which automatically transfers “cold” data to a cheaper storage level.
Another new Oracle Database 12c technology, called Data Guard Far Sync, provides zero data loss over long distances and allows you to keep backup copies of databases far away from the main database. An additional special database instance that does not have data files accepts changes from the main database in synchronous mode and asynchronously transmits these changes to remote database instances, which ensures both the synchronous mode reliability and the asynchronous mode performance.
Technology Application Continuity allows you to repeat aborted transactions - thereby solving one of the main problems of web applications with databases. The technology makes the failure of the database instance transparent to the web application and allows you to determine the status of the last transaction. If the transaction fails, it will be executed, and if it is already completed, the Application Continuity technology does not allow it to be executed again.
The technology of dynamic data masking Data Redaction is transparent to applications and allows you to set data access policies within the database. The data remains unchanged, but, depending on the rights of the end user, his role, he will see only the data for which he is authorized to access. This allows applications to work transparently with the database, the policy will be executed for all applications.
Finally, in Oracle Database 12.1.0.1, a powerful system for analyzing the relationship of the Pattern Matching lines was implemented, which allows analyzing trends and finding statistical patterns in them using SQL language constructs. And this is not counting more than five hundred other modifications.
Already in 2014, Oracle released Oracle Database 12.1.0.2, where these capabilities were improved and a new option, Oracle In-Memory, was added, the most important.
When developing In-Memory, Oracle sought to create technology that would make real-time analytics possible for operational business decisions. It is extremely important that if Oracle's competitors use a different database and other technologies to use their In-Memory options, then the Oracle Database In-Memory option is built into the database, is included in just one parameter, is completely transparent to applications and is compatible with all database capabilities. The experience of using this option by customers shows that transaction processing is accelerated twice, inserting rows is three to four times faster than usual, requests for analytics are actually executed in real time, almost instantly.
The meaning of the technology is that next to the usual buffer cache that stores the rows of tables and blocks of indexes, a new shared area is created for the data in the RAM, in which they are stored in a column format (Fig. 1). Thus, the technology uses both inline and column storage formats for the same table data, with the data being simultaneously active and transactionally consistent. All changes are first made in the traditional buffer cache, and then reflected in the column cache.
In this case, only tables are reflected in the column cache, indexes are not cached. In addition, if the data is read, but does not change, then there is no need to store it in the buffer cache, but if the data is changed, then they are stored in both caches, the buffer and the column. Therefore, In-Memory accelerates the work of analytics, because column-based data storage is more efficient for analytics.
In addition, the In-Memory option allows you to get rid of analytical indexes without sacrificing performance, while flexibility will appear: disk space is saved, you can build a query on any column that is placed in In-Memory, and you do not need to build additional indexes for fast query work .

An important element of Oracle Database In-Memory is hardware support. In particular, the technology supports SIMD (Single Instruction Multiple Data Values) instruction set, designed for graphics processing, In-Memory uses these instructions, if they are embedded in the processor, to compare several column values with a predicate at once, greatly accelerating the column scanning speed - up to 1 billion lines per second.
But that's not all. Oracle SPARC M7 and T7 servers, released in late 2015, contain hardware support for In-Memory. To this end, the M7 and T7 processors have added a database vector scanning module, an in-memory data decompression module and a memory hardware protection module that implements real-time access to in-memory data to protect data from malicious intruders and program code errors. .
In order to use Oracle In-Memory, it is enough to set the size of the memory buffer of the In-Memory Column Store, specify which tables, sections, columns will be located in this memory, re-start the database and delete analytical indexes if they are no longer required for performance. applications. In-Memory is easy to manage from the Oracle Enterprise Manager, where there is a separate In-Memory Central page that displays the memory allocation between objects and allows you to configure the In-Memory Column Store. The latest version of Enterprise Manager 13c has the In-Memory Advisor tool, supported for database versions 11.2.0.3 and higher, which analyzes the existing database load and provides a list of objects that will load the maximum in the In-Memory Column Store.
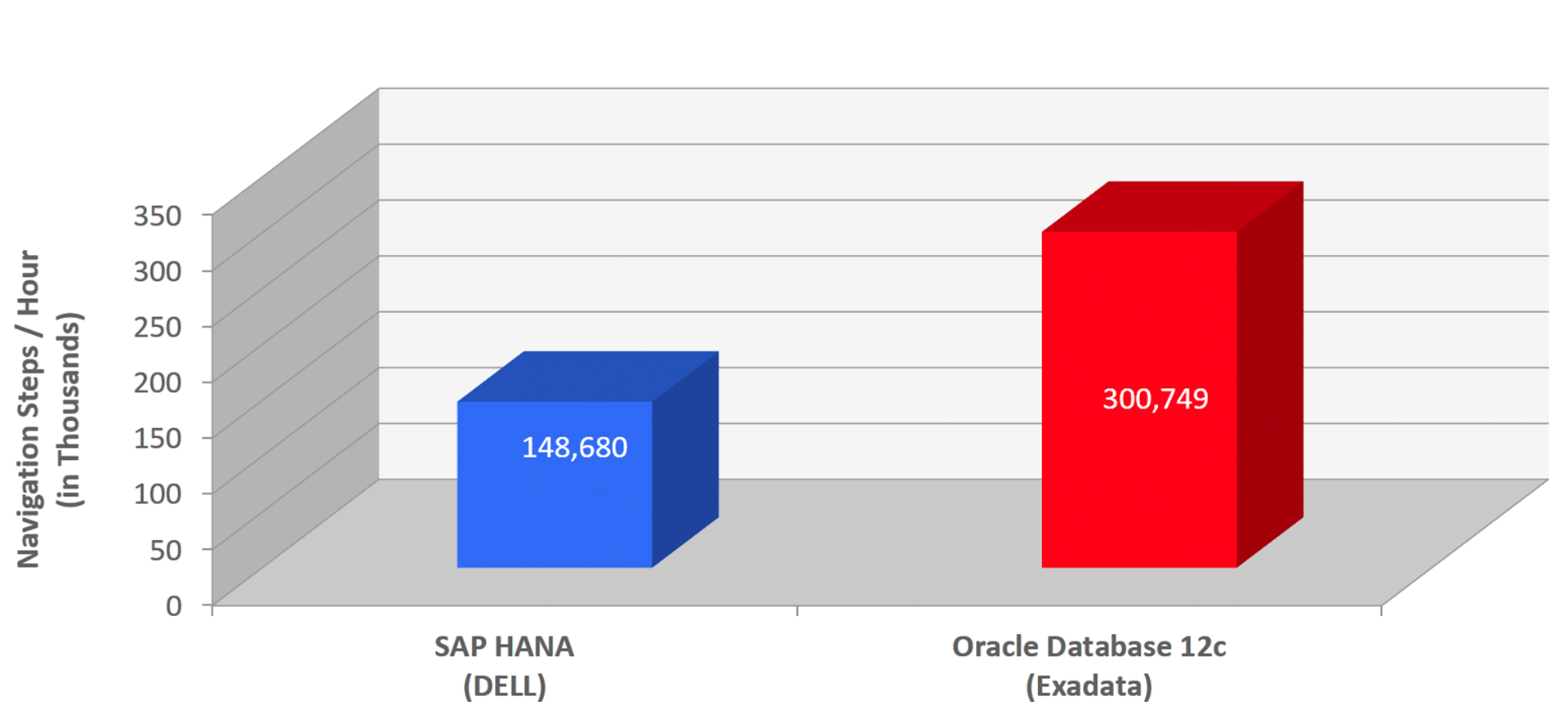
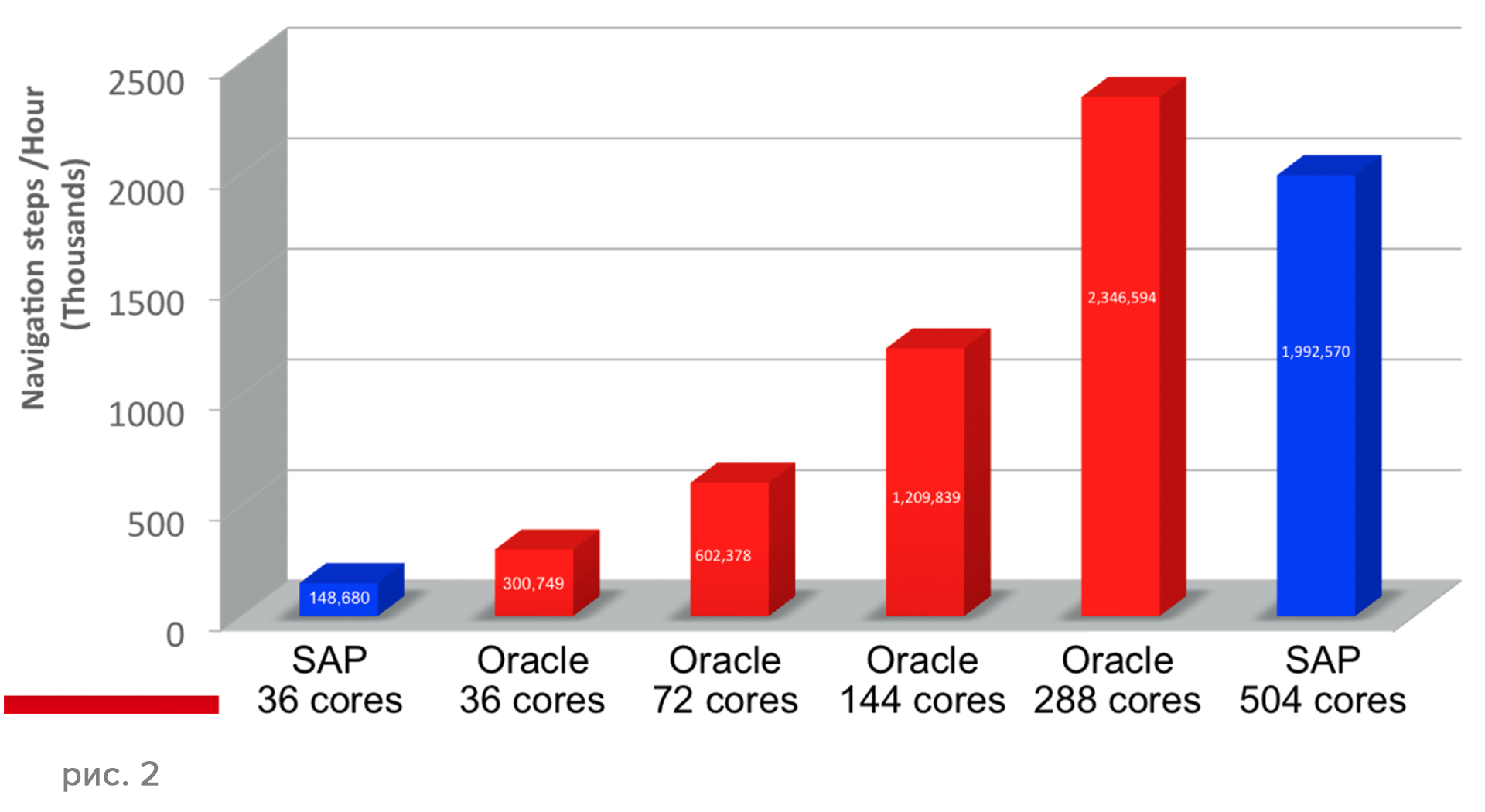
Comparative testing of Oracle Database 12c In-Memory and SAP HANA on the same number of cores Intel demonstrated twice the performance of Oracle Database 12 than SAP HANA (Figure 2, above). Comparative testing of the scalability of Oracle Database 12c In-Memory and SAP HANA showed that Oracle Database 12c In-Memory scales much better than SAP HANA — almost linearly (Figure 2, below).
We have already said that from heavy monolithic applications the IT industry is moving to web services. As web services increasingly access each other through a REST interface, Oracle provides the Oracle REST Data Services (ORDS) Java application, which provides a single REST interface for working with Oracle DBMS (relational data and JSON Document Store) and Oracle NoSQL Database. ORDS can be used both offline and deployed on WebLogic Server, Oracle Glassfish Server, Apache Tomcat application servers. SQL Developer provides a convenient platform for installing and configuring ORDS, in particular, it contains a setup wizard that automatically creates REST services for accessing database tables. The VirtualBox virtual machine with configured Big Data Lite Virtual Machine and configured REST services is available for free at Oracle Technology Network. Since the same REST call can be applied to different databases, this increases the flexibility and speed of programming, because the developer does not require knowledge of SQL and database specifics. Oracle Database 12.1.0.2 has built-in support for JSON databases. REST services can work either with JSON Document Store in a database version 12c, or with relational database tables, which are represented as REST Data Services, or with NoSQL databases.
Oracle Big Data Appliance are clusters designed to run Hadoop and NoSQL databases. Unlike other software and hardware complexes of Oracle, these systems were developed in collaboration with Cloudera, one of the leading suppliers of the Hadoop distribution. Contrary to common misconception, such systems are needed not only by companies from the Internet business, because today the need to process huge volumes of data is faced by any companies that need to do in-depth analysis of customer behavior, plan high-precision advertising, combine and analyze data from many sources, including including unstructured ones, fighting fraud, etc.
Oracle Big Data SQL as part of the Oracle Big Data Appliance allows you to make one quick SQL-query from Oracle Database 12 with all data stored in Hadoop, relational and NoSQL databases. Oracle Big Data SQL is a new architecture that offers powerful, high-performance SQL on Hadoop, with the full range of Oracle SQL features on Hadoop and local SQL query processing on Hadoop nodes. The architecture offers simple integration of Hadoop, Oracle Database and Oracle NoSQL data, a single SQL entry point for access to all data, scalable connections between Hadoop data and RDBMS.
Oracle NoSQL Database is a scalable, high-performance, high-availability database with transparent load balancing, the entire amount of data in which is stored as key-value pairs.
New features of Multitenant-databases version 12.1.0.2 relate primarily to the cloning of PDB (pluggable db, plug-in) databases. Part of the tablespaces can now be excluded from cloning. It is possible to clone only metadata, which is sometimes required for development. Remote cloning allows you to clone a PDB database between two container databases via a database link. Finally, a subtle cloning appeared, based on the Direct NFS technology embedded in the database and independent of the file system.
Other improvements include a new SQL statement, which allows you to make aggregated queries on tables that are located in several pluggable databases. The new phrase “standbys” allows you to explicitly specify or cancel the creation of a backup database when creating a plug-in database.
Secondly, it is important to remember that in the face of reduced IT costs, developers need new tools that allow them to more quickly innovate and simplify application support. For example, in order to integrate new developments with existing corporate infrastructures, developers are moving away from monolithic applications, complex and difficult to develop, towards the microservice architecture, that is, applications that are sets of independently deployable services. And to work with the new architecture, it is necessary for the database to support new tools and new programming methods.
')
Oracle has taken all this into account when developing the Oracle Database 12.1.0.2 database. This article is an overview of the major innovations of this version.
Oracle database 12c
Let's start with the fact that in 2013, Oracle released Oracle Database 12c (version 12.1.0.1), the main advantages of which were reduced storage costs, high availability of data, ease of consolidating databases and protecting access to data.
In more detail, this version introduces the Oracle Multitenant architecture, which greatly simplifies database consolidation, speeds up database deployment and allows you to manage many databases as one — instead of administering hundreds of databases individually, the administrator works with one database, managing many databases. data as one. All this made the version of Oracle Database 12c at the time of its release the most suitable database management system for cloud computing, especially for SaaS applications, where high-speed creation of new databases on demand of users is especially important, which, with the support of Snapshot Cloning technology, takes A couple of minutes.
In addition, in Oracle Database 12.1.0.1, automatic data optimization has appeared, combining the technology of “smart compression”, which automatically detects data blocks that are rarely accessed (“cold” data) and compresses them, and multi-level data storage automation technology, which automatically transfers “cold” data to a cheaper storage level.
Another new Oracle Database 12c technology, called Data Guard Far Sync, provides zero data loss over long distances and allows you to keep backup copies of databases far away from the main database. An additional special database instance that does not have data files accepts changes from the main database in synchronous mode and asynchronously transmits these changes to remote database instances, which ensures both the synchronous mode reliability and the asynchronous mode performance.
Technology Application Continuity allows you to repeat aborted transactions - thereby solving one of the main problems of web applications with databases. The technology makes the failure of the database instance transparent to the web application and allows you to determine the status of the last transaction. If the transaction fails, it will be executed, and if it is already completed, the Application Continuity technology does not allow it to be executed again.
The technology of dynamic data masking Data Redaction is transparent to applications and allows you to set data access policies within the database. The data remains unchanged, but, depending on the rights of the end user, his role, he will see only the data for which he is authorized to access. This allows applications to work transparently with the database, the policy will be executed for all applications.
Finally, in Oracle Database 12.1.0.1, a powerful system for analyzing the relationship of the Pattern Matching lines was implemented, which allows analyzing trends and finding statistical patterns in them using SQL language constructs. And this is not counting more than five hundred other modifications.
Already in 2014, Oracle released Oracle Database 12.1.0.2, where these capabilities were improved and a new option, Oracle In-Memory, was added, the most important.
Oracle Database 12.1.0.2: In-Memory
When developing In-Memory, Oracle sought to create technology that would make real-time analytics possible for operational business decisions. It is extremely important that if Oracle's competitors use a different database and other technologies to use their In-Memory options, then the Oracle Database In-Memory option is built into the database, is included in just one parameter, is completely transparent to applications and is compatible with all database capabilities. The experience of using this option by customers shows that transaction processing is accelerated twice, inserting rows is three to four times faster than usual, requests for analytics are actually executed in real time, almost instantly.
The meaning of the technology is that next to the usual buffer cache that stores the rows of tables and blocks of indexes, a new shared area is created for the data in the RAM, in which they are stored in a column format (Fig. 1). Thus, the technology uses both inline and column storage formats for the same table data, with the data being simultaneously active and transactionally consistent. All changes are first made in the traditional buffer cache, and then reflected in the column cache.
In this case, only tables are reflected in the column cache, indexes are not cached. In addition, if the data is read, but does not change, then there is no need to store it in the buffer cache, but if the data is changed, then they are stored in both caches, the buffer and the column. Therefore, In-Memory accelerates the work of analytics, because column-based data storage is more efficient for analytics.
In addition, the In-Memory option allows you to get rid of analytical indexes without sacrificing performance, while flexibility will appear: disk space is saved, you can build a query on any column that is placed in In-Memory, and you do not need to build additional indexes for fast query work .
An important element of Oracle Database In-Memory is hardware support. In particular, the technology supports SIMD (Single Instruction Multiple Data Values) instruction set, designed for graphics processing, In-Memory uses these instructions, if they are embedded in the processor, to compare several column values with a predicate at once, greatly accelerating the column scanning speed - up to 1 billion lines per second.
But that's not all. Oracle SPARC M7 and T7 servers, released in late 2015, contain hardware support for In-Memory. To this end, the M7 and T7 processors have added a database vector scanning module, an in-memory data decompression module and a memory hardware protection module that implements real-time access to in-memory data to protect data from malicious intruders and program code errors. .
In order to use Oracle In-Memory, it is enough to set the size of the memory buffer of the In-Memory Column Store, specify which tables, sections, columns will be located in this memory, re-start the database and delete analytical indexes if they are no longer required for performance. applications. In-Memory is easy to manage from the Oracle Enterprise Manager, where there is a separate In-Memory Central page that displays the memory allocation between objects and allows you to configure the In-Memory Column Store. The latest version of Enterprise Manager 13c has the In-Memory Advisor tool, supported for database versions 11.2.0.3 and higher, which analyzes the existing database load and provides a list of objects that will load the maximum in the In-Memory Column Store.
Comparative testing of Oracle Database 12c In-Memory and SAP HANA on the same number of cores Intel demonstrated twice the performance of Oracle Database 12 than SAP HANA (Figure 2, above). Comparative testing of the scalability of Oracle Database 12c In-Memory and SAP HANA showed that Oracle Database 12c In-Memory scales much better than SAP HANA — almost linearly (Figure 2, below).
New features for developers
We have already said that from heavy monolithic applications the IT industry is moving to web services. As web services increasingly access each other through a REST interface, Oracle provides the Oracle REST Data Services (ORDS) Java application, which provides a single REST interface for working with Oracle DBMS (relational data and JSON Document Store) and Oracle NoSQL Database. ORDS can be used both offline and deployed on WebLogic Server, Oracle Glassfish Server, Apache Tomcat application servers. SQL Developer provides a convenient platform for installing and configuring ORDS, in particular, it contains a setup wizard that automatically creates REST services for accessing database tables. The VirtualBox virtual machine with configured Big Data Lite Virtual Machine and configured REST services is available for free at Oracle Technology Network. Since the same REST call can be applied to different databases, this increases the flexibility and speed of programming, because the developer does not require knowledge of SQL and database specifics. Oracle Database 12.1.0.2 has built-in support for JSON databases. REST services can work either with JSON Document Store in a database version 12c, or with relational database tables, which are represented as REST Data Services, or with NoSQL databases.
Oracle Database 12c and Big Data
Oracle Big Data Appliance are clusters designed to run Hadoop and NoSQL databases. Unlike other software and hardware complexes of Oracle, these systems were developed in collaboration with Cloudera, one of the leading suppliers of the Hadoop distribution. Contrary to common misconception, such systems are needed not only by companies from the Internet business, because today the need to process huge volumes of data is faced by any companies that need to do in-depth analysis of customer behavior, plan high-precision advertising, combine and analyze data from many sources, including including unstructured ones, fighting fraud, etc.
Oracle Big Data SQL as part of the Oracle Big Data Appliance allows you to make one quick SQL-query from Oracle Database 12 with all data stored in Hadoop, relational and NoSQL databases. Oracle Big Data SQL is a new architecture that offers powerful, high-performance SQL on Hadoop, with the full range of Oracle SQL features on Hadoop and local SQL query processing on Hadoop nodes. The architecture offers simple integration of Hadoop, Oracle Database and Oracle NoSQL data, a single SQL entry point for access to all data, scalable connections between Hadoop data and RDBMS.
Oracle NoSQL Database is a scalable, high-performance, high-availability database with transparent load balancing, the entire amount of data in which is stored as key-value pairs.
Oracle Multitenant Improvements
New features of Multitenant-databases version 12.1.0.2 relate primarily to the cloning of PDB (pluggable db, plug-in) databases. Part of the tablespaces can now be excluded from cloning. It is possible to clone only metadata, which is sometimes required for development. Remote cloning allows you to clone a PDB database between two container databases via a database link. Finally, a subtle cloning appeared, based on the Direct NFS technology embedded in the database and independent of the file system.
Other improvements include a new SQL statement, which allows you to make aggregated queries on tables that are located in several pluggable databases. The new phrase “standbys” allows you to explicitly specify or cancel the creation of a backup database when creating a plug-in database.
Other improvements
- Advanced Index Compression technology compresses indexes to reduce disk space (in some databases, the index takes up half the disk space) and more efficient use of the cache.
- Full database caching. It turns on automatically to get a return on all available memory and potentially improve performance if the database is stored in memory. It is possible to force the inclusion of full caching, including tables with NOCACHE LOB objects, with the ALTER DATABASE FORCE FULL DATABASE CACHING command.
- Automatic caching of large tables. Can be used if the database does not fit in memory entirely, but some large objects fit. The DB_BIG_TABLE_CACHE_PERCENT_TARGET parameter allows to allocate a separate area for large tables in the buffer cache. If, in a regular buffer cache, data is cached at the block level, large tables are cached and removed from this cache area entirely based on the frequency of access to them.
- The Attribute Clustering directive, given for a table, orders data by column values, with rows with identical column values lying together on disk. This directive works during direct data load operations, such as bulk inserting records or moving a table. Attribute Clustering can be useful for data compression, since ordered data is better compressed when using the Advanced Compression option. But Attribute Clustering provides the greatest benefit when used together with another new feature in Oracle Database 12.1.0.2, Zone Maps. Zone maps, available on Oracle Exadata or Supercluster, contain minimum and maximum values of specified columns for row ranges and allow you to quickly filter out unnecessary data when executing a query. These technologies are completely transparent to applications, they improve query performance, reduce the number of physical reads, significantly reduce the number of I / O operations for queries with high selectivity and optimize disk usage.
- Approximate Count Distinct is a function of approximate counting of various column values (after all, not every request requires an exact result — for example, the question “How many different visitors were on our site last week?” It is quite possible to give an approximate answer), which works significantly (up to 50 times) faster than accurate counting, and gives accuracy of more than 97% with a 95% confidence factor.
Source: https://habr.com/ru/post/279333/
All Articles