Pandasql vs Pandas for solving data analysis tasks
What is it about?
In this article I would like to talk about the use of the python library Pandasql .
Many people confronted with data analysis tasks are likely to be familiar with the Pandas library. Pandas allows you to quickly and conveniently work with tabular data: filter, group, join on the data; build pivot tables and even draw charts (for simple visualizations, the plot () function is sufficient, and if you want something more interesting, the matplotlib library will help). On Habré more than once told about the use of this library to work with data: one , two , three .
But in my experience, not everyone knows about the Pandasql library, which allows you to work with Pandas DataFrames as tables and access them using the SQL language. In some tasks it is easier to express what you want with the help of the declarative SQL language, so I think that it is useful for people working with data to know about the presence of such functionality. If we talk about real problems, then I used this library to solve the join problem of tables by fuzzy conditions (it was necessary to combine records of events from different systems at approximately the same time, a gap of about 5 seconds).
')
Consider the use of this library with specific examples.
Data for analysis
For illustration, I took data on the involvement of students of the Data Analyst Nanodegree specialization at Udacity. This data is published in the Intro to Data Analysis course (I can recommend this course to anyone who wants to get acquainted with the use of the Pandas and Numpy libraries for data analysis, although the Pandasql library has not been reviewed at all).
In the examples I will use 2 tables (for more information about the data, you can read here ):
- enrollments : data on the entry to the "Data Analyst Nanodegree" specialization of a random subset of students;
- account key : student ID;
- join date : the day the student enrolled in the specialization;
- status : student status at the time of data collection: "current" if the student is active, and "canceled" if he left the course;
- cancel date : the day the student left the course, None for active students;
- is udacity : takes True for test accounts in Udacity, for live users - False;
- daily engagements : data on the activity of students from the table of enrollments for each day when they were recorded for specialization;
- acct : student ID;
- utc date : date of activity;
- total minutes visited : the total number of minutes the student spent on the Data Analyst Nanodegree courses.
Examples
Now we can proceed to the consideration of examples. It seems to me that it will be most vivid to show how to solve each of the tasks using the standard functionality of Pandas and Pandasql.
First we need to do all the necessary imports and load the data from the csv files into DataFrames. The full code of examples and source data can be found in the repository .
import pandas as pd import pandasql as ps from datetime import datetime import seaborn daily_engagements = pd.read_csv('./data/daily_engagement.csv') enrollments = pd.read_csv('./data/enrollments.csv') Import of the seaborn library is used only to make the graphics more beautiful, no special library functionality will be used.
Simple request
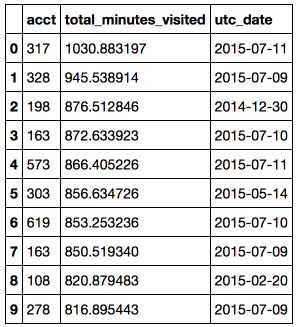
Task : to find the top 10 maximum student activities on a particular day.
This example describes how to use filtering, sorting, and getting the first N objects. To execute the SQL query, the
sqldf function of the sqldf module is used, and the dictionary of local names locals() must also be passed to this function (for more information on using the functions of locals() and globals() in Pandasql, you can read on Stackoverflow ). # pandas code top10_engagements_pandas = daily_engagements[['acct', 'total_minutes_visited', 'utc_date']] .sort('total_minutes_visited', ascending = False)[:10] # pandasql code simple_query = ''' SELECT acct, total_minutes_visited, utc_date FROM daily_engagements ORDER BY total_minutes_visited desc LIMIT 10 ''' top10_engagements_pandas = ps.sqldf(simple_query, locals()) Conclusion: The most diligent student spent more than 17 hours studying in one day.
Using aggregate functions
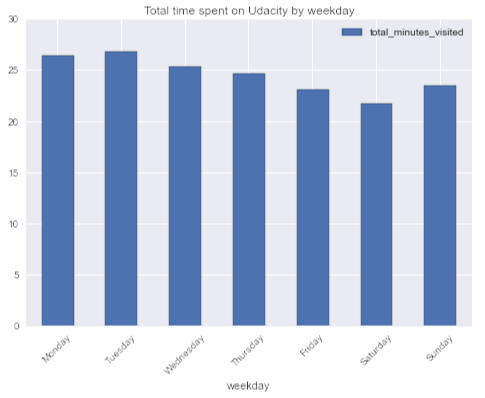
Task : I wonder if there is a weekly seasonality in students' activity (if judged by oneself, then usually there is not enough time for online courses on weekdays, but you can spend more time on weekends).
First, add the "weekday" column to the original DataFrame, converting the date to the day of the week.
daily_engagements['weekday'] = map(lambda x: datetime.strptime(x, '%Y-%m-%d').strftime('%A'), daily_engagements.utc_date) daily_engagements.head() 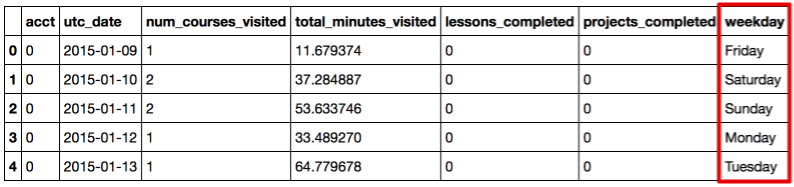
# pandas code weekday_engagement_pandas = pd.DataFrame(daily_engagements.groupby('weekday').total_minutes_visited.mean()) # pandasql code aggr_query = ''' SELECT avg(total_minutes_visited) as total_minutes_visited, weekday FROM daily_engagements GROUP BY weekday ''' weekday_engagement_pandasql = ps.sqldf(aggr_query, locals()).set_index('weekday') week_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'] weekday_engagement_pandasql.loc[week_order].plot(kind = 'bar', rot = 45, title = 'Total time spent on Udacity by weekday') Conclusion: It is curious, but on average, students spend most of their time on courses on Tuesday, and least of all on Saturday. On average, students spend more time on MOOC on weekdays than on weekends. Another proof that I am unrepresentative.
JOIN tables
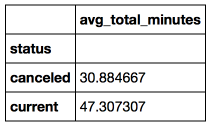
Objective : consider students who have not passed the specialization (with the canceled status) and those who successfully study / studied and compare their average activity per day for the first week after they enrolled in the specialization. There is a hypothesis that those who remained and study successfully spent more time on training.
To answer this question, we need data from both the enrollments and daily engagements tables, so we will use join by student ID.
Also in this problem there are several pitfalls that need to be considered:
- not all users are living people, there are also Udacity test accounts, they need to be filtered
is_udacity = 0; - A student can register for a specialization several times, including at intervals of less than one week, so you need to check that the activity date of the utc date is between join date and cancel date (only for students with the canceled status).
# pandas code join_df = pd.merge(daily_engagements, enrollments[enrollments.is_udacity == 0], how = 'inner', right_on ='account_key', left_on = 'acct') join_df = join_df[['account_key', 'status', 'total_minutes_visited', 'utc_date', 'join_date', 'cancel_date']] join_df['days_since_joining'] = map(lambda x: x.days, pd.to_datetime(join_df.utc_date) - pd.to_datetime(join_df.join_date)) join_df['before_cancel'] = (pd.to_datetime(join_df.utc_date) <= pd.to_datetime(join_df.cancel_date)) join_df = join_df[join_df.before_cancel | (join_df.status == 'current')] join_df = join_df[(join_df.days_since_joining < 7) & (join_df.days_since_joining >= 0)] avg_account_total_minutes = pd.DataFrame(join_df.groupby(['account_key', 'status'], as_index = False) .total_minutes_visited.mean()) avg_engagement_pandas = pd.DataFrame(avg_account_total_minutes.groupby('status').total_minutes_visited.mean()) avg_engagement_pandas.columns = [] # pandasql code join_query = ''' SELECT avg(avg_acct_total_minutes) as avg_total_minutes, status FROM (SELECT avg(total_minutes_visited) as avg_acct_total_minutes, status, account_key FROM (SELECT e.account_key, e.status, de.total_minutes_visited, (cast(strftime('%s',de.utc_date) as interger) - cast(strftime('%s',e.join_date) as interger))/(24*60*60) as days_since_joining, (cast(strftime('%s',e.cancel_date) as interger) - cast(strftime('%s', de.utc_date) as interger))/(24*60*60) as days_before_cancel FROM enrollments as e JOIN daily_engagements as de ON (e.account_key = de.acct) WHERE (is_udacity = 0) AND (days_since_joining < 7) AND (days_since_joining >= 0) AND ((days_before_cancel >= 0) OR (status = 'current')) ) GROUP BY status, account_key) GROUP BY status ''' avg_engagement_pandasql = ps.sqldf(join_query, locals()).set_index('status') It is worth noting that in the SQL query, the
cast and strftime functions were used to bring the dates from the rows into the timestamp (the number of seconds since the beginning of the epoch), and then calculate the difference between these dates in days.Conclusion: On average, students who did not abandon their specialization spent the first week on Udacity 53% more time than those who decided to stop studying.
Summarizing
In this article, we looked at examples of using the Pandasql library for data analysis and compared it using Pandas functionality. We applied filtering, sorting, aggregate functions and joines to work with DataFrames in Pandasql.
Pandas is a very convenient library that allows you to quickly and easily convert data, but it seems to me that in some tasks it is easier to express your thoughts using a declarative language and then Pandasql comes to the rescue. In addition, Pandasql can be useful for those who are just starting to get to know Pandas, but already have good knowledge of SQL.
The full code of examples and source data are also given in the repository on github .
For those interested, there is also a good tutorial by Pandasql on The Yhat Blog .
Source: https://habr.com/ru/post/279213/
All Articles