AlphaGo on the fingers
So, while our new masters are resting, let me try to tell you how AlphaGo works. The post implies some familiarity of the reader with the subject - you need to know the difference between Fan Hui and Lee Sedol, and to superficially understand how neural networks work.
Disclaimer: the post is written on the basis of fairly edited chat logs closedcircles.com , hence the style of presentation, and the availability of clarifying questions
As everyone knows, computers played badly in Go because there are so many possible moves and the search space is so large that direct bust helps a little.
The best programs use the so-called Monte Carlo Tree Search - a search on the tree with the evaluation of the nodes through the so-called rollouts, that is, quick simulations of the result of the game from the position in the node.
AlphaGo complements this search for tree-based deep-learning evaluation functions to optimize the search space. The article originally appeared in Nature (and it is there for paywall), but you can find it on the Internet. For example here - https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
')
We take 160K of fairly high-level online games available and train the neural network that predicts the next move of a person in position.
The network architecture is just 12 convolution layers with non-linearity and softmax per cell at the end. Such depth is generally comparable to the networks for processing images of the past generation (Google Inception-v1, VGG, all these things)
The important point is that the neural network is given for input:
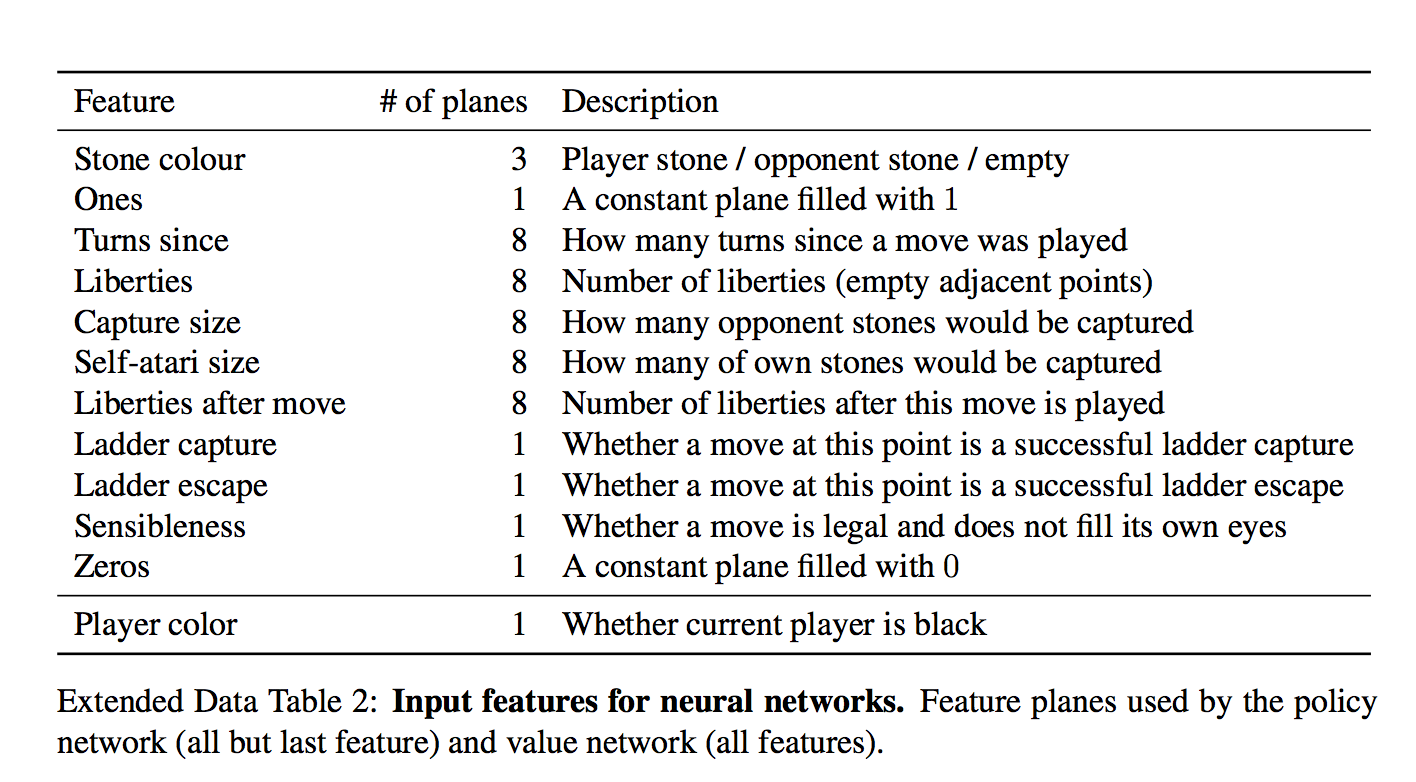
For each cell, 48 features are given for input, they are all in the table (each dimension is a binary feature)
The set is interesting. At first glance, it seems that the network needs to be given only if there is a stone in the cell and if so, which one. But figs there!
There are trivially computed features like "the number of degrees of freedom of a stone", or "the number of stones that will be taken by this move"
There are also formally unimportant features like "how long has it been a move"
And even a special feature for the frequent appearance of "ladder capture / ladder escape" - a potentially long sequence of forced moves.
and what is "always 1" and "always 0"?
They simply to finish quantity of features to multiple 4th, it seems to me.
And on this all the grid learns to predict human moves. Predicts with an accuracy of 57% and this must be treated with caution - the purpose of the prediction, the human move, is still ambiguous.
The authors show, however, that even small improvements in accuracy strongly affect the strength in the game (comparing grids of different capacities)
Separate from SL-policy, they train fast rollout policy - a very fast strategy, which is simply a linear classifier.
They give her more advanced features at the entrance.

That is, it is given features in the form of pre-prepared patterns.
It is much worse than a model with a deep network, but it is super-fast. How it is used - it will be clear further
We choose an adversary from a pool of past versions of the network by chance (so as not to overfit herself), play the game with him to the end by simply choosing the most likely move from network prediction, again without any sorting.
The only reward is the actual result of the game, won or lost.
After the reward is known, we calculate how to move the weights - we lose the game again and at each turn we move the weights that affect the choice of the selected position, along the gradient in + or in - depending on the result. In other words, we apply this reward as the direction of the gradient to each turn.
(for the curious, there is a little more subtle and the gradient is multiplied by the difference between the result and the position estimate via the value network)
And here we repeat and repeat this process - after that the RL-policy is much stronger than the SL-policy from the first step.
The prediction of this trained RL-policy is already tearing up most of the past programs that play Go, without any trees and overrules.
Including DarkForest Facebook?
It was not compared with it, it is not clear.
An interesting detail! In the original article it is written that this process lasted only 1 day (the rest of the workouts - weeks).
Those. predicts just one value from -1 to 1.
It has exactly the same architecture as the policy network (there is one extra convolution layer, it seems) + a naturally fully connected layer at the end.
That is, she has the same features?
value network give another feature - whether the player plays with black or not (the policy network transmits a “friend or foe” stone, not a color). As I understand it, this is so that she can take into account the Komi - extra points for white, because they go second
It turns out that it cannot be trained in all positions from the games of people — since many positions belong to the game with the same result, such a network starts to overfit — that is, remember which party it is, instead of evaluating the position.
Therefore, she is trained on synthetic data — N moves are made through the SL network, then a random legal move is made, then she is played through the RL-network to find out the result, and she is trained on N + 2 (!) During only one position per generated game.
TL; DR: Policy network predicts probable moves to reduce the search width (less than possible moves in the node), value network predicts how advantageous the position is to reduce the required search depth
Attention, picture!
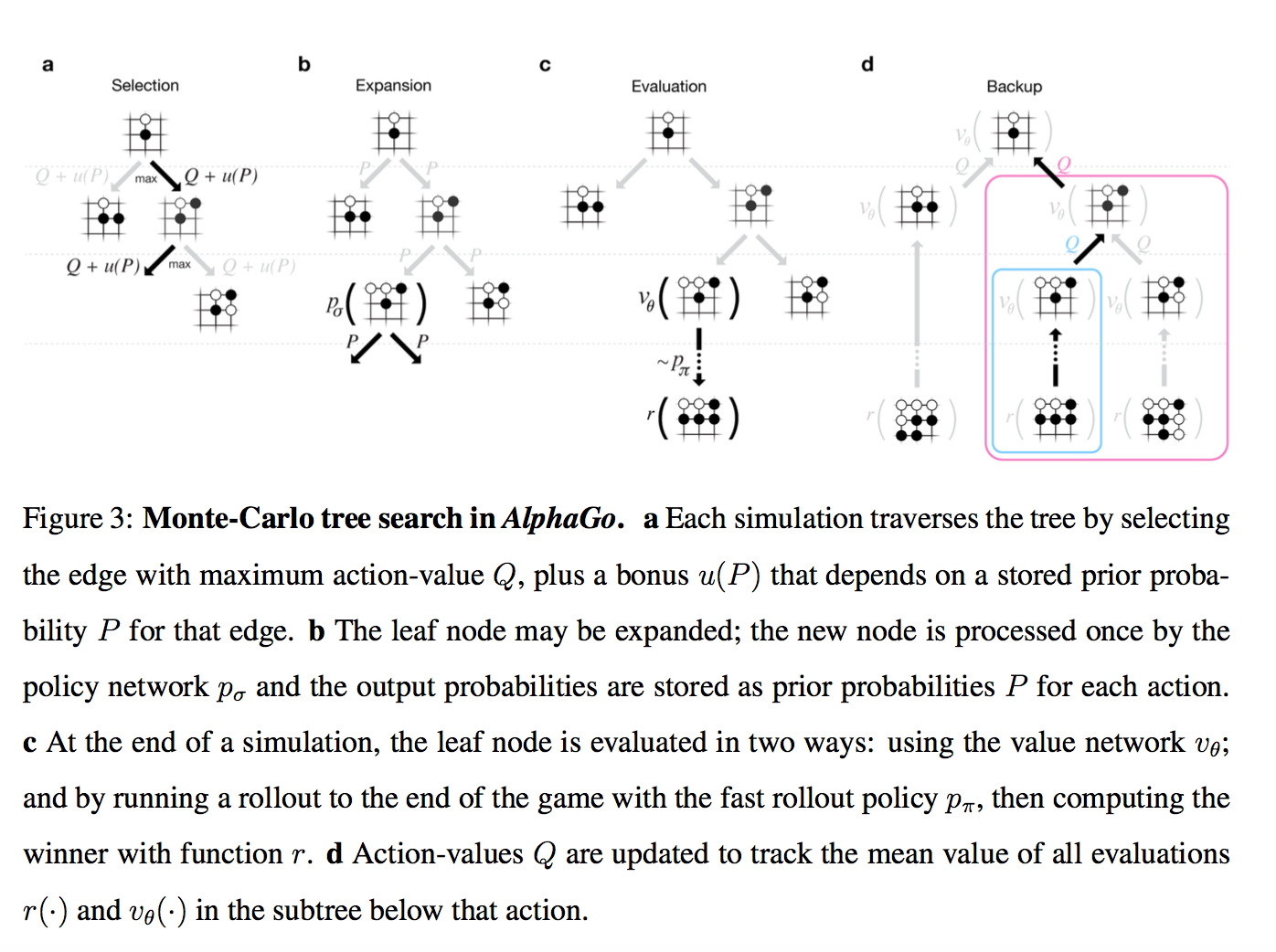
So, we have a tree of positions, in the root - the current one. For each position there is a certain value of Q, which means how much it leads to victory.
We are simultaneously running a large number of simulations on this tree.
Each simulation goes through the tree to where there is more Q + m (P). m (P) is a special additive that stimulates exploration. It is more if the policy network considers that this move has a high probability and less if it has already been followed a lot along this path.
(this is a variation of the standard multi-armed bandit)
When the simulation has reached the tree to the leaf, and wants to go on, where there is nothing yet ...
That newly created tree node is evaluated in two ways.
The results of these two estimates are mixed with a certain weight (in the release it is naturally 0.5), and the resulting score is recorded for all the tree nodes through which the simulation passed, and Q in each node is updated as the average of all scores for passes through this node.
(there is quite a bit more complicated, but it can be neglected)
Those. each simulation runs through the tree to the most promising area (taking exploration into account), finds a new position, evaluates it, writes the result upwards through all the moves that led to it. And then Q in each node is calculated as averaging over all simulations that ran through it.
Actually, everything. The best move is declared the node through which they ran the most (it turns out that it is a bit more stable than this Q-score). AlphaGo is dealt if all Q-scores are <-0.8, i.e. probability of winning is less than 10%.
An interesting detail! In the paper for the initial probabilities of moves P, the weaker SL-policy was used, not the RL-policy.
It turned out empirically that it was a little better this way (perhaps, the match with Lee Sedol was no longer there, but they played it with Fan Hui), i.e. reinforcement learning was needed only to train value network
Finally, what can be said about what the version of AlphaGo, which played with Fan Hui (and was described in the article), differed from the version that plays with Lee Sedol:
Perhaps all. Looking forward to 5: 0!
Bonus : Attempt to open-source implementation. There, of course, another saw and saw.
Disclaimer: the post is written on the basis of fairly edited chat logs closedcircles.com , hence the style of presentation, and the availability of clarifying questions
As everyone knows, computers played badly in Go because there are so many possible moves and the search space is so large that direct bust helps a little.
The best programs use the so-called Monte Carlo Tree Search - a search on the tree with the evaluation of the nodes through the so-called rollouts, that is, quick simulations of the result of the game from the position in the node.
AlphaGo complements this search for tree-based deep-learning evaluation functions to optimize the search space. The article originally appeared in Nature (and it is there for paywall), but you can find it on the Internet. For example here - https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
')
First, let's talk about the composite pieces, and then how they are combined.
Step 1: we train the neural network that learns to predict the moves of people - SL-policy network
We take 160K of fairly high-level online games available and train the neural network that predicts the next move of a person in position.
The network architecture is just 12 convolution layers with non-linearity and softmax per cell at the end. Such depth is generally comparable to the networks for processing images of the past generation (Google Inception-v1, VGG, all these things)
The important point is that the neural network is given for input:
For each cell, 48 features are given for input, they are all in the table (each dimension is a binary feature)
The set is interesting. At first glance, it seems that the network needs to be given only if there is a stone in the cell and if so, which one. But figs there!
There are trivially computed features like "the number of degrees of freedom of a stone", or "the number of stones that will be taken by this move"
There are also formally unimportant features like "how long has it been a move"
And even a special feature for the frequent appearance of "ladder capture / ladder escape" - a potentially long sequence of forced moves.
and what is "always 1" and "always 0"?
They simply to finish quantity of features to multiple 4th, it seems to me.
And on this all the grid learns to predict human moves. Predicts with an accuracy of 57% and this must be treated with caution - the purpose of the prediction, the human move, is still ambiguous.
The authors show, however, that even small improvements in accuracy strongly affect the strength in the game (comparing grids of different capacities)
Separate from SL-policy, they train fast rollout policy - a very fast strategy, which is simply a linear classifier.
They give her more advanced features at the entrance.
That is, it is given features in the form of pre-prepared patterns.
It is much worse than a model with a deep network, but it is super-fast. How it is used - it will be clear further
Step 2: we train policy even better through playing with ourselves (reinforcement learning) - RL-policy network
We choose an adversary from a pool of past versions of the network by chance (so as not to overfit herself), play the game with him to the end by simply choosing the most likely move from network prediction, again without any sorting.
The only reward is the actual result of the game, won or lost.
After the reward is known, we calculate how to move the weights - we lose the game again and at each turn we move the weights that affect the choice of the selected position, along the gradient in + or in - depending on the result. In other words, we apply this reward as the direction of the gradient to each turn.
(for the curious, there is a little more subtle and the gradient is multiplied by the difference between the result and the position estimate via the value network)
And here we repeat and repeat this process - after that the RL-policy is much stronger than the SL-policy from the first step.
The prediction of this trained RL-policy is already tearing up most of the past programs that play Go, without any trees and overrules.
Including DarkForest Facebook?
It was not compared with it, it is not clear.
An interesting detail! In the original article it is written that this process lasted only 1 day (the rest of the workouts - weeks).
Step 3: we will train the network, which tells us at a glance to the alignment, what are our chances to win! - Value network
Those. predicts just one value from -1 to 1.
It has exactly the same architecture as the policy network (there is one extra convolution layer, it seems) + a naturally fully connected layer at the end.
That is, she has the same features?
value network give another feature - whether the player plays with black or not (the policy network transmits a “friend or foe” stone, not a color). As I understand it, this is so that she can take into account the Komi - extra points for white, because they go second
It turns out that it cannot be trained in all positions from the games of people — since many positions belong to the game with the same result, such a network starts to overfit — that is, remember which party it is, instead of evaluating the position.
Therefore, she is trained on synthetic data — N moves are made through the SL network, then a random legal move is made, then she is played through the RL-network to find out the result, and she is trained on N + 2 (!) During only one position per generated game.
So, here we have these trained bricks. How do we play with them?
TL; DR: Policy network predicts probable moves to reduce the search width (less than possible moves in the node), value network predicts how advantageous the position is to reduce the required search depth
Attention, picture!
So, we have a tree of positions, in the root - the current one. For each position there is a certain value of Q, which means how much it leads to victory.
We are simultaneously running a large number of simulations on this tree.
Each simulation goes through the tree to where there is more Q + m (P). m (P) is a special additive that stimulates exploration. It is more if the policy network considers that this move has a high probability and less if it has already been followed a lot along this path.
(this is a variation of the standard multi-armed bandit)
When the simulation has reached the tree to the leaf, and wants to go on, where there is nothing yet ...
That newly created tree node is evaluated in two ways.
- First, through the value network described above
- secondly, it is played to the end with the help of the super-fast model from Step 1 (this is called rollout)
The results of these two estimates are mixed with a certain weight (in the release it is naturally 0.5), and the resulting score is recorded for all the tree nodes through which the simulation passed, and Q in each node is updated as the average of all scores for passes through this node.
(there is quite a bit more complicated, but it can be neglected)
Those. each simulation runs through the tree to the most promising area (taking exploration into account), finds a new position, evaluates it, writes the result upwards through all the moves that led to it. And then Q in each node is calculated as averaging over all simulations that ran through it.
Actually, everything. The best move is declared the node through which they ran the most (it turns out that it is a bit more stable than this Q-score). AlphaGo is dealt if all Q-scores are <-0.8, i.e. probability of winning is less than 10%.
An interesting detail! In the paper for the initial probabilities of moves P, the weaker SL-policy was used, not the RL-policy.
It turned out empirically that it was a little better this way (perhaps, the match with Lee Sedol was no longer there, but they played it with Fan Hui), i.e. reinforcement learning was needed only to train value network
Finally, what can be said about what the version of AlphaGo, which played with Fan Hui (and was described in the article), differed from the version that plays with Lee Sedol:
- Cluster could be bigger. The maximum version of the cluster in the article is 280 GPUs, but Fan Hui played with the version with 176 GPUs.
- It seems that it has become more time to spend on the move (in the article all the estimates are given for 2 seconds per move) + added some ML on the topic of time management
- There was more time to train the nets before the match. My personal suspicion is fundamentally that more time is spent on reinforcement learning. 1 day in the original article is somehow not even funny.
Perhaps all. Looking forward to 5: 0!
Bonus : Attempt to open-source implementation. There, of course, another saw and saw.
Source: https://habr.com/ru/post/279071/
All Articles