Error in Linux kernel sends damaged TCP / IP packets to Mesos, Kubernetes and Docker containers

And it was discovered on Twitter servers
The Linux kernel has an error caused by containers. In order not to check TCP checksums, for network routing containers use veth devices (such as Docker on IPv6, Kubernetes, Google Container Engine and Mesos). This leads to the fact that in some cases, applications mistakenly receive damaged data, as is the case with faulty network equipment. We checked that this error appeared at least three years ago and is still “sitting” in the nuclei. Our patch has been tested and introduced into the kernel, and currently provides retro-support for stable release 3.14 on various distributions (such as Suse and Canonical). If you use containers in your system, I recommend that you use this patch or install the kernel with it when it becomes available.
Note: this does not apply to networks with NAT, the default used for Docker, since the Google Container Engine is practically protected from "iron" errors by its virtualized network. Jake Bower also believes that this error is very similar to the Pager Duty error found earlier.
')
How it all began
One weekend in November, a group of support engineers on Twitter looked through the logs. Each non-working application produced "incredible" errors in the form of lines of strange characters or omissions of mandatory fields. The interrelationship of these errors was not obvious due to the nature of the distributed Twitter architecture. The whole situation was complicated by the fact that in any distributed system, the data, once corrupted, can cause errors for quite a long time (they are stored in caches, recorded on disks, in logs, etc.).
After a day of continuous troubleshooting work at the application level, the team managed to localize the problem to individual rack racks. The engineers determined that a significant increase in the number of detected TCP checksum errors occurred just before they reached the addressee. It seemed that this result was “free from guilt” software: the application could cause network overload, and not packet damage!
Note:
the mention of the ephemeral "team" can hide from the reader how many people worked on this problem. A lot of engineers from the entire company worked on diagnosing these strange faults. It is difficult to list all, but the main contributions were made by: Brian Martin (Brian Martin), David Robinson, Ken Koemoto (Ken Kawamoto), Mahak Patidar, Manuel Cabalquinto, Sandy Strong , Zach Kiehl, Will Campbell, Ramin Khatibi, Yao Yue, Berk Demir, David Barr, Gopal Raiprourohit (Gopal Rajpurohit), Joseph Smith (Joseph Smith), Rohis Menon (Rohith Menon), Alex Lambert (Alex Lambert) and Ian Downes (Ian Downes), Cong Wang (Cong Wang).)
As soon as these racks were turned off, the application errors disappeared. Of course, data corruption at the network level can occur for many reasons: switches can fail in the most bizarre way, wires can be damaged, power can often fail, and so on. Checksums in TCP and IP are designed to protect against such faults. Indeed, the statistics collected by the equipment showed that errors were present. So, why did a set of various applications start to falter?
After isolating certain switches, attempts were made to reproduce these errors (mainly due to the tremendous work of senior reliability engineer Brian Martin). It turned out that it is relatively easy to reproduce corrupted data by sending a number of data packets to these racks. On some switches, up to 10% of the sent packets were damaged. However, damage was always detected by the kernel using TCP checksums (messages like TcpInCsumErrors netstat-a), and never reached applications. (In Linux, using the undocumented SO_NO_CHECK option, you can send IPv4 UDP packets with checksums disabled — in which case we will be able to see that the packet is damaged.)
Evan Jones suggested that the corrupted data has the correct TCP checksum. If in the same 16-bit word two bits are flip-flipped (for example, 0 → 1 and 1 → 0), their effects on the TCP checksum will balance each other (the TCP checksum is simple addition of bits). Although the data corruption in the message (32 bytes by module) always consisted in changing the same bit position, the fact that there was a “sticky bit” (0 → 1) precluded this possibility. On the other hand, since the checksum itself is inverted before being stored, the "flip" of the bit in the checksum, along with the "flip" of the bit in the data, can balance each other. However, the bit position that we observed changed could not affect the TCP checksum, and therefore this was not possible.
Soon, the team realized that our tests were conducted on a standard Linux system, and most of the services on Twitter work on Mesos, which uses Linux containers to isolate various applications. In particular, virtual Ethernet devices (veth devices) are created in the Twitter configuration and all packets for applications are transmitted through them. Of course, after launching our test application, corrupted data immediately appeared in the Mesos container, coming in via a TCP connection, despite the fact that the TCP checksums were wrong (and were identified as incorrect: the number of TcpInCsumErrors increased). Someone suggested changing the “checksum offloading” setting on the virtual Ethernet device, which solved the problem, leading to a corresponding removal of the corrupted data.
Now we have a serious task. The Mesos Twitter team quickly conveyed information to the open source Mesos project and changed the settings on all of the Twitter work containers.
Dig further
When Evan and I discussed this error, we decided that, since the TCP / IP protocol was broken by the OS, it was possible that it was not the result of mis-configuration of Mesos, but, most likely, the result of a previously undetected error in the network kernel stack.
To continue this investigation, we have created a test system as simple as possible:
- a simple client that opens a socket and sends a very simple, long message every second.
- a simple server (we actually used a network computer in listening mode) that listens on the socket and, when it receives information, displays it on the screen.
- a network device, a transmission controller that allows the user to arbitrarily damage packets before they are sent over the wire.
- Once we connected the client and the server, we used a network device to damage all packets sent in 10 seconds.
We ran a client from one machine, and a server from another. Computers connected through the switch. When we ran the test system without containers, it behaved exactly as expected. No bad packet alerts have been reported. In fact, for those ten seconds that corrupted data was transmitted, we did not receive any messages at all. After the client stopped damaging the packets, all 10 messages (which were not delivered) came immediately. This confirmed that TCP on Linux without containers works as expected: bad TCP packets are delayed and are constantly retransmitted until they can be received without errors.
So this should work in theory: corrupted data is not delivered; TCP retransmits them.
Linux and containers
At this point, it is useful (as we did when diagnosing a problem) to go back and briefly describe how the network stack works in a Linux container environment. The containers were designed to allow serving users to work together on computers and thus provide many advantages of a virtualized environment (to reduce or completely eliminate the possibility of application influence on each other, to enable several applications to work in different environments or with different libraries) at lower costs. virtualization Ideally, all objects that conflict with each other, are isolated. Examples include disk queuing queues, caches, and network performance.
In Linux, veth devices are used to isolate some containers running on a computer from others. The Linux network stack is quite complex, but essentially a veth device is an interface that, from the user's point of view, should look exactly like a “regular” Ethernet device.
To create a container with a virtual Ethernet device, you need to (first) create a container, (second) create a veth, (third) bind one end of the veth to the container, (fourth) assign an IP address to the veth and (fifth) configure routing, as a rule , using Linux Traffic Control, so that the container can receive and send packets.
Why all this virtual economy "falls"
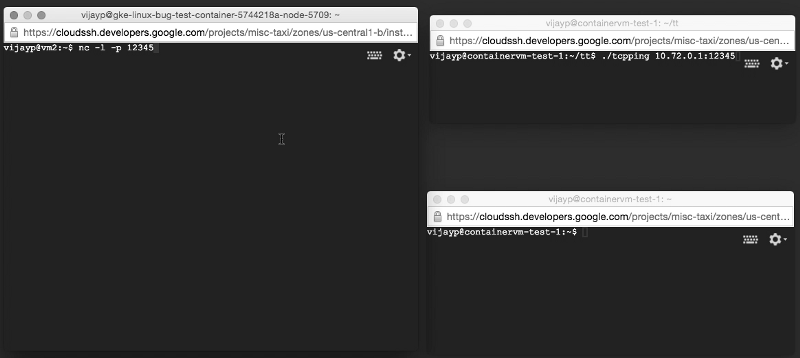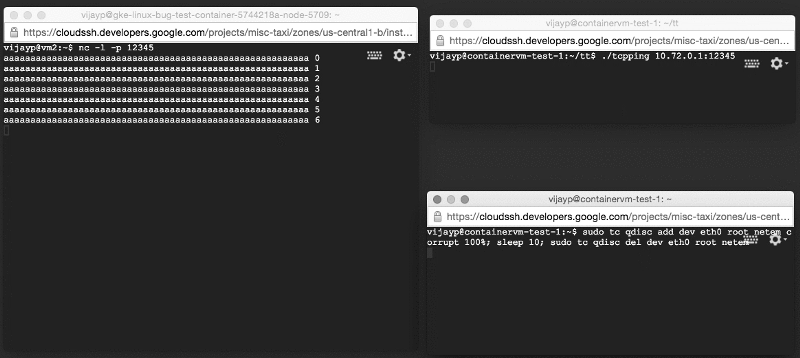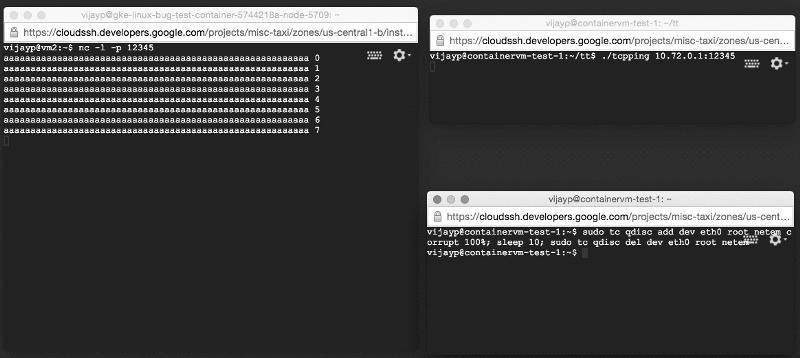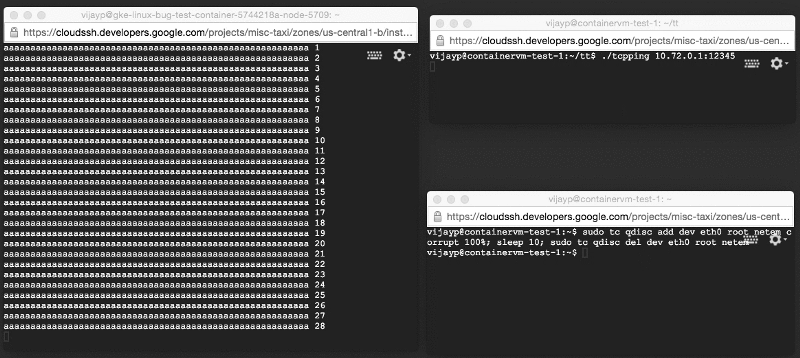
We re-created the test system described above, except that the server was now working inside the container. However, when we launched it, we saw a completely opposite picture: corrupted data did not linger, but were delivered to applications! We reproduced the error on a very simple test system (two machines on the table and two very simple programs).
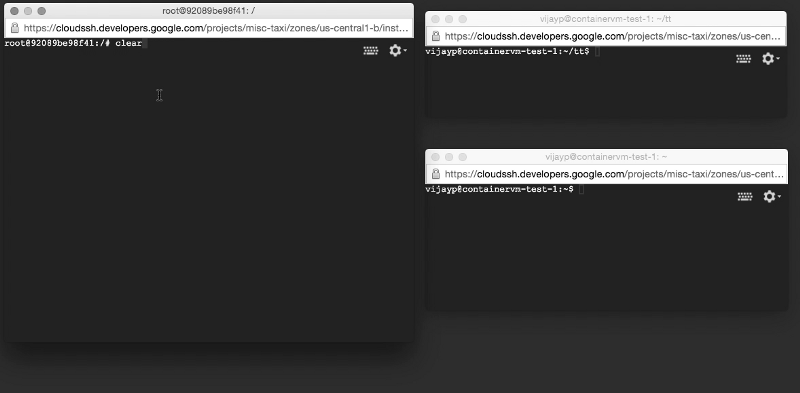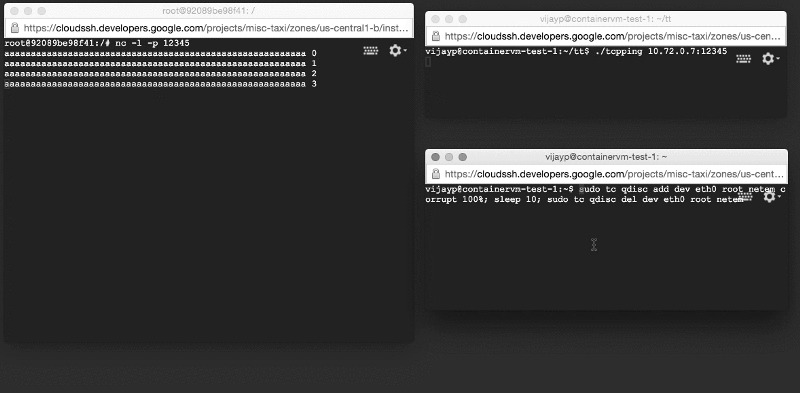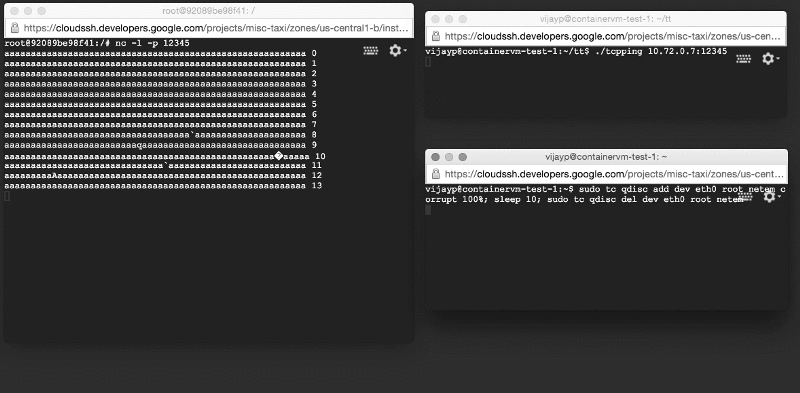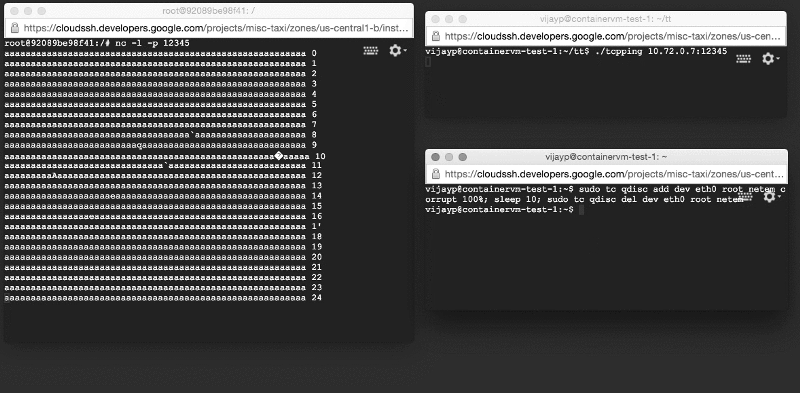
Damaged data is delivered to the application: look at the window on the left!
We were also able to reproduce this test system on cloud platforms. The default Kubernetes configuration shows the same picture (for example, when using the Google Container Engine). The default Docker configuration (with NAT) is secure, and the Docker configuration on IPv6 is not.
We eliminate the error
After studying the network kernel code, it became clear that this error was in the veth module of the kernel. In the kernel, in packets that come from real network devices, the parameters ip_summed are assigned the value CHECKSUM_UNNECESSARY if the hardware has checked the checksums, or CHECKSUM_NONE if the packet is bad or it was not possible to check it.
The code in veth.c replaced CHECKSUM_NONE with CHECKSUM_UNNECESSARY. This led to the fact that the checksums that were to be checked and rejected by the software were simply silently ignored. After removing this code, packets were transferred from one stack to another unchanged (as expected, tcpdump showed incorrect checksums on both sides), and were delivered (or delayed) correctly to applications. We did not check all possible network configurations, only a few common ones, such as Bridge-container connection, using NAT between the host and the container, and routing from real devices to containers. We effectively implemented this in the work of Twitter (disabling the calculation of the checksum when receiving and unloading veth-devices).
We do not know exactly why the code was written this way, but we believe that this is an optimization attempt. Often, veth devices are used to connect containers on the same physical machine. Logically, packets transmitted between containers (or virtual machines) within a single physical host should not calculate or verify checksums: the only possible source of damage is the host's own RAM, since packets are never transmitted over the wire. Unfortunately, this optimization does not work even as it was intended: for locally transmitted packets, the ip_summed parameter is set as CHECKSUM_PARTIAL, and not as CHECKSUM_NONE.
This code was written for the first driver release (commit e314dbdc1c0dc6a548ecf [NET]: Virtual ethernet device driver). The release of Commit 0b7967503dc97864f283a net / veth: Fix packet checksumming (December 2010) fixed this for packets created locally and transmitted to real devices without changing CHECKSUM_PARTIAL. However, this problem is still not resolved for packets transmitted from real devices.
The following is a patch for the kernel:
diff — git a/drivers/net/veth.cb/drivers/net/veth.c
index 0ef4a5a..ba21d07 100644
— — a/drivers/net/veth.c
+++ b/drivers/net/veth.c
@@ -117,12 +117,6 @@ static netdev_tx_t veth_xmit(struct sk_buff *skb, struct net_device *dev)
kfree_skb(skb);
goto drop;
}
- /* don't change ip_summed == CHECKSUM_PARTIAL, as that
- * will cause bad checksum on forwarded packets
- */
- if (skb->ip_summed == CHECKSUM_NONE &&
- rcv->features & NETIF_F_RXCSUM)
- skb->ip_summed = CHECKSUM_UNNECESSARY;
if (likely(dev_forward_skb(rcv, skb) == NET_RX_SUCCESS)) {
struct pcpu_vstats *stats = this_cpu_ptr(dev->vstats);
findings
Overall, I'm really impressed with the netdev group and Linux kernel experts. The code was inspected fairly quickly, our patch was connected for several weeks, and a month later it provided retro-support for the old, stable version (3.14 +) with various kernel distributions (Canonical, Suse). With all the advantages of the container environment, it really came as a big surprise to us that this error existed for many years unnoticed. I wonder how many failures and other unpredictable behavior of application programs could be caused by it!
Source: https://habr.com/ru/post/278885/
All Articles