Asynchronous parallel execution in PHP
A lot of rush is broken in the world on the topic of whether and how to create multithreading in PHP. Most often, it all comes down to the fact that it is impossible to do this or the discussion materializes in some awful crutches (oh, how many I have already seen). I want to state my point of view on this question. It is easy to guess that if my position was “so impossible” or “this is evil,” I would not have written this article. Just wait a minute, do not rush to get the rotten eggs and equip small household items for melee. I will try to diplomatically outline the topic and as objectively as possible to reveal the situation. So the most courageous of my readers can read the prayer from heresy and open the article.

There are many different terms: multithreading, multiprocess, asynchronous execution. They all mean different things. However, it often happens that in practice we, as consumers, are not so important in different processes, threads, or else how our program runs in parallel. If only she worked faster and did not lose responsiveness in the process of its implementation. Therefore, in this article I will consider all possible options for parallelizing PHP, regardless of the internal kitchen of this parallelization itself. That is, I will try to answer the question: how can I make so that some long action in my PHP code is performed in the background, while my code is busy with something else useful.
')
Actually, I believe that in 99% of cases it is not necessary (and notice that the author writes an article on the topic of parallelization). I worked for 8 years with PHP and until last week I always considered it a great folly to try to thread multithreading into PHP. The point is that the PHP task is to accept an incoming HTTP request and generate an answer to it. One request - one answer. The scheme is very simple, and it is very convenient to process linearly in one thread. It seems to me that in a client-server bundle on the server, it is not necessary to do something multi-threaded, except for some special circumstances that force you to do this and on which you can play to reduce the resources consumed and the response time. Why do I think so? After all, someone can say that if you parallelize some process, then it can run on 2 cores at once and thus execute faster. It's true. But there is always one nuance on the server: you must be ready to process N clients at the same time. And if your server code “sprawls out” on all 8 available cores, and at that moment a new incoming request comes, then it will have to huddle in the queue, waiting for some kernel to be ready to start processing it. And you will have a useless competition for the cycles of 8 CPUs between 16 threads / processes. That is why I believe that even if the server has resources that can be involved in the processing of an incoming request due to parallelization, it is better not to do so. We can say that parallelization is already present and so, because The server can simultaneously process several incoming requests. Well, it turns out that twisting parallelization into parallelization is already sort of a bust.
By this moment I already mentioned a glimpse of why multithreading is needed. It allows you to "break" a single thread of code execution. This results in several “useful” consequences. First, you can perform some kind of slow action in the background, while maintaining the responsiveness of the main program flow (asynchronous execution). For example: according to business logic, we need to exchange information with some peripheral device. This device is very slow, and the operation takes about 5 seconds. If all this is done in one stream, then the block diagram of our algorithm looks like this:

It is very likely that at least some of the “system destruction and cleanup after itself” can be performed without knowing the response from the peripheral device. Then you can call the peripheral device in a separate thread, and while the device responds, no one will forbid us to perform something from the “system destruction and cleanup” clause in the main thread. Then the block diagram looks like this:
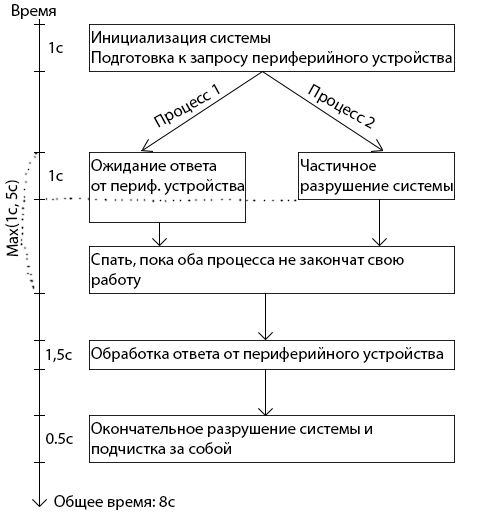
Well, the second big consequence of breaking this single thread of execution is that you can use more resources of the computer on which the code is executed. If this is some kind of laborious mathematical calculation, then it can be run on several threads (provided that the calculation algorithm allows it), and then several processor cores will immediately work on the result. That is, in the abstract formulation: if in several streams to compete for some resource, then it can be obtained more in the same period of time. Although, I have already said that this point is very doubtful for me in the case of server code (and we are considering just such a one).
The biggest, and the only significant, I think - is the additional cost of maintaining multi-point, both at run time (the threads need to somehow share information with each other so that they can work for the common good) and during development time (multi-threaded / asynchronous programs are harder to write and maintain, since it is much easier for the human brain to perceive the linear logic of execution). After all, we always perceive the world “here and now”, and to realize that somewhere else something else is happening, always turns out not as bright as the current scene “here and now”. It turns out that a multi-threaded program will consume more resources, performing the same task as a single-threaded program. It is also very likely that it will require more time to develop and maintain / expand. What is the result? Multithreading can give an increase in the speed of work due to parallel execution, and multipoint will consume more resources due to the need for synchronization and data exchange between threads. In general, as always: parallelization is just a tool. If used properly, it can be useful, otherwise it will be overweight.
I am working on a website that estimates the cost of sending a parcel from point A to point B. In essence, this is an aggregator of freight forwarders API. Well, you guessed it? With the cold cache, in the worst cases, it could turn out that from 1 incoming request to my website they “grow” under 200 requests for API from different carriers. Naturally, making 200 synchronous HTTP requests is a sin much worse than twisting multithreading in PHP. Therefore, out of 2 evils, I chose the least. I really had one in a million cases in this situation. Additional threads do not consume a lot of CPU cycles, no network, no hard disk, very roughly speaking, I needed threads in which I just needed to sleep for 1-2 seconds (while the carrier’s API response is generated). Disclaimer: Think 10 times, first implement it somewhere in the project. In 8 years of work, I first met a case where it makes sense. Wear this collar around your neck only if you really need one.
Before I get to the concrete implementation methods that I have tried, let me introduce some theoretical reflections on this topic. The largest division of the algorithms is split along the fork / thread line of the current PHP process or the launch of a new child process. First, I found only 1 possible implementation on forking the current PHP process (which turned out to be inoperative to everything else). Secondly, fork in PHP is clearly an example of poor parallelization. Why? Yes, because in a parallel stream, you should try to bring out only the action that is performed slowly (communication with the peripheral device, and not the interpretation of its response; the execution of the HTTP request, and not its interpretation again). See the item about parallelizing server code at the top to see why you need to do this. Thirdly, fork'aya full program, you commit yourself to synchronize data between them, and it is very difficult. On the other hand, if you create a child process with literally a couple of lines of code that perform some kind of dreary and long-sleeping operation, you don’t need to synchronize anything and you don’t “crawl” to the other cores of your server. Well, as a bonus, this approach is much more flexible - you can run not a PHP child process, but a bash script or C program, or whatever it is, only your imagination limits you (and Linux knowledge, of course).
Let us dwell on child processes. How can you organize communication between parent and child processes? Of course, you can organize their communication on files, you can on the database or on some other data storage. But to support the “zoo” files of 200 pieces for each incoming request in my particular case looked very gemmno. I didn’t want to work with the database in order not to exhaust connections to MySQL (after all, it would be 200 connections per 1 incoming request - with such arithmetic I won’t be able to scale my code too much and I very quickly put it into the number of connections to the database). Fortunately, good old Linux already has tools for communication between processes (it has been for 20 years already and it seems that everyone has enough of it, which means that it should be enough for me and you too). Thus, my goal was to find such an ideal implementation of creating child processes so that:
As for me, the most delusional thing I saw about PHP parallelization is to run
Another thing, if the requests are sent to another server, as in my case. Here, I consider using
An example (I will say straight away, I didn’t really try it very hard, because the inflexibility of this approach strongly scared me away): php.net/manual/en/function.curl-multi-exec.php
If you compile PHP with the
Supposedly,
The quickest implementation method that allows you to run any command in the OS (read “very flexible”). Before the collision with my current task, I only once resorted to this function. But I had another case there, I just needed to run the command, give it input arguments and forget about it. I didn't need any answers from her. In the process of execution, the team itself will write down the result itself. Then I implemented it like this:
Without an ampersand at the end of the command, it would be executed synchronously, i.e. The PHP process would have slept until the end of the work of the team. To tell the truth, I didn’t stay too long with this method, but in theory, all the necessary input arguments can be passed through the command arguments. STDERR and STDOUT commands can be redirected to files or named pipes. If you really need, you can pre-write STDIN to a file or a named pipe. In the worst case, it turns out somewhere such Frankenstein:
The biggest drawback is that there is no good way to determine if the team has completed its work. But if you initially lay down a certain interface of the contents of STDOUT, then you can live quite well and on this method. You then need to periodically read the contents of STDOUT, and further, based on your protocol of the contents of STDOUT, you can interpret the state of the command. Under the transfer of meta information about the current status, you can get a separate file descriptor (4th, say).
So, our next candidate looks a little better than the
Supposedly, the
Among the shortcomings: it is impossible to know the current status of the child team. Sometimes it can be important. Imagine that we run 10 asynchronous commands. They all run for about 2 seconds, ± 10%. And in the main PHP process, at the end of each team we want to interpret the results. Each such interpretation will take us 0.5 seconds. If we had the opportunity to find out whether such a subsidiary team finished the work, then we could read the STDOUT of those subsidiary teams that have already completed their work. And while we are engaged in the interpretation of the current child team, the other running child commands are very likely to have time to complete by the time we are ready to interpret their result. Alas, we can not do that. The maximum that we can do in this way is to read STDOUT, and if the STDOUT of the subsidiary command is still open, then our main PHP process will sleep until the subsidiary command closes it or finishes its work (which also implicitly closes pipe). We lose a little asynchrony, because in certain situations we can “run into” a long “dream” of the main PHP process.
The second drawback: one-way communication. It would be nice to have 3 descriptors at once ... for all occasions, so to speak. And if you can do without STDIN (you can shove all the input data into the input arguments of the child command), then without STDERR it's still more difficult. Craftsmen can come up with such a solution:
But then you will have to disassemble the porridge yourself in STDOUT, since there at any time can be the contents of STDERR. If you need STDERR, then you have to create named pipes or temporary files and redirect the STDERR stream to them yourself at the OS level. Looking ahead, I will say that if you really need STDERR, then it is better not to fool with
Total we have a winner! It fits us with all the criteria and runs with a fairly small amount of code in PHP. In practice, I have been using this method for about a week now and have no complaints. The website and server have not yet seen the real load, because the website has not yet reached the final stage, but pah-pah-pah I have no reason to complain, and it seems I wrote the code, the possibility of the existence of which I did not believe 10 days ago.
I told about dry asynchrony implementations in PHP. But in practice, everything is so simple and beautiful never happens, is not it? Asynchrony is no exception. In conclusion, I want to give some tricks that will help you at the application level at the time of applying these techniques.
If you want to exchange information between 2 PHP processes, it is likely that at some point you will want to “push” some complex data structures inherent in your project between STDIN / STDOUT (read “not scalars”). The first thing that comes to mind is to stuff them into the PHP
Skillful use of asynchronous calling is a big science. It is not hard to guess that it is necessary to launch an asynchronous child command as aggressively as possible (eager) and read the results of its work as lazy as possible. After all, this way your team will have a maximum time for execution and your main stream will not be blocked in hibernation, waiting for the end of its work. Not all program architectures conveniently fall under this principle. You should understand that to run a child command and the next line to read its result is to make yourself worse. If you plan to use asynchrony, try to think about your architecture as early as possible and always keep it in mind. Using my specific example, I’ll say that when I came to understand that I needed to parallelize my PHP process, I had to rewrite the main website engine, having deployed it with a more convenient side to asynchrony.
Asynchrony is an extra expense. To synchronize data (if you have one), to create and kill a child process, to open and close a file descriptors, etc. On my laptop, an asynchronous call to a simple
Secondly, supposedly, you are doing something asynchronously because it is executed slowly. So why not kill 2 birds with one stone? Cache the results of an asynchronous command in some permanent storage, be it a database, file system or memcache. Naturally, this item makes sense only if your results do not lose their relevance too quickly. Moreover, put this cache in front of all asynchronous to avoid those 3 ms. Just in case, I will give a flowchart of my thoughts:

Knowing the theory is good. But usually the lazy and practical guys want to download any library, connect it, pull a couple of methods and solve their problem. Based on the last solution (through
The object of discussion - what do I mean by multitasking / multithreading?
There are many different terms: multithreading, multiprocess, asynchronous execution. They all mean different things. However, it often happens that in practice we, as consumers, are not so important in different processes, threads, or else how our program runs in parallel. If only she worked faster and did not lose responsiveness in the process of its implementation. Therefore, in this article I will consider all possible options for parallelizing PHP, regardless of the internal kitchen of this parallelization itself. That is, I will try to answer the question: how can I make so that some long action in my PHP code is performed in the background, while my code is busy with something else useful.
')
And why is it even necessary?
Actually, I believe that in 99% of cases it is not necessary (and notice that the author writes an article on the topic of parallelization). I worked for 8 years with PHP and until last week I always considered it a great folly to try to thread multithreading into PHP. The point is that the PHP task is to accept an incoming HTTP request and generate an answer to it. One request - one answer. The scheme is very simple, and it is very convenient to process linearly in one thread. It seems to me that in a client-server bundle on the server, it is not necessary to do something multi-threaded, except for some special circumstances that force you to do this and on which you can play to reduce the resources consumed and the response time. Why do I think so? After all, someone can say that if you parallelize some process, then it can run on 2 cores at once and thus execute faster. It's true. But there is always one nuance on the server: you must be ready to process N clients at the same time. And if your server code “sprawls out” on all 8 available cores, and at that moment a new incoming request comes, then it will have to huddle in the queue, waiting for some kernel to be ready to start processing it. And you will have a useless competition for the cycles of 8 CPUs between 16 threads / processes. That is why I believe that even if the server has resources that can be involved in the processing of an incoming request due to parallelization, it is better not to do so. We can say that parallelization is already present and so, because The server can simultaneously process several incoming requests. Well, it turns out that twisting parallelization into parallelization is already sort of a bust.
By this moment I already mentioned a glimpse of why multithreading is needed. It allows you to "break" a single thread of code execution. This results in several “useful” consequences. First, you can perform some kind of slow action in the background, while maintaining the responsiveness of the main program flow (asynchronous execution). For example: according to business logic, we need to exchange information with some peripheral device. This device is very slow, and the operation takes about 5 seconds. If all this is done in one stream, then the block diagram of our algorithm looks like this:
It is very likely that at least some of the “system destruction and cleanup after itself” can be performed without knowing the response from the peripheral device. Then you can call the peripheral device in a separate thread, and while the device responds, no one will forbid us to perform something from the “system destruction and cleanup” clause in the main thread. Then the block diagram looks like this:
Well, the second big consequence of breaking this single thread of execution is that you can use more resources of the computer on which the code is executed. If this is some kind of laborious mathematical calculation, then it can be run on several threads (provided that the calculation algorithm allows it), and then several processor cores will immediately work on the result. That is, in the abstract formulation: if in several streams to compete for some resource, then it can be obtained more in the same period of time. Although, I have already said that this point is very doubtful for me in the case of server code (and we are considering just such a one).
Disadvantages and difficulties of parallelization
The biggest, and the only significant, I think - is the additional cost of maintaining multi-point, both at run time (the threads need to somehow share information with each other so that they can work for the common good) and during development time (multi-threaded / asynchronous programs are harder to write and maintain, since it is much easier for the human brain to perceive the linear logic of execution). After all, we always perceive the world “here and now”, and to realize that somewhere else something else is happening, always turns out not as bright as the current scene “here and now”. It turns out that a multi-threaded program will consume more resources, performing the same task as a single-threaded program. It is also very likely that it will require more time to develop and maintain / expand. What is the result? Multithreading can give an increase in the speed of work due to parallel execution, and multipoint will consume more resources due to the need for synchronization and data exchange between threads. In general, as always: parallelization is just a tool. If used properly, it can be useful, otherwise it will be overweight.
What made me implement multithreading in PHP
I am working on a website that estimates the cost of sending a parcel from point A to point B. In essence, this is an aggregator of freight forwarders API. Well, you guessed it? With the cold cache, in the worst cases, it could turn out that from 1 incoming request to my website they “grow” under 200 requests for API from different carriers. Naturally, making 200 synchronous HTTP requests is a sin much worse than twisting multithreading in PHP. Therefore, out of 2 evils, I chose the least. I really had one in a million cases in this situation. Additional threads do not consume a lot of CPU cycles, no network, no hard disk, very roughly speaking, I needed threads in which I just needed to sleep for 1-2 seconds (while the carrier’s API response is generated). Disclaimer: Think 10 times, first implement it somewhere in the project. In 8 years of work, I first met a case where it makes sense. Wear this collar around your neck only if you really need one.
The evolution of my thoughts (my algorithm)
Before I get to the concrete implementation methods that I have tried, let me introduce some theoretical reflections on this topic. The largest division of the algorithms is split along the fork / thread line of the current PHP process or the launch of a new child process. First, I found only 1 possible implementation on forking the current PHP process (which turned out to be inoperative to everything else). Secondly, fork in PHP is clearly an example of poor parallelization. Why? Yes, because in a parallel stream, you should try to bring out only the action that is performed slowly (communication with the peripheral device, and not the interpretation of its response; the execution of the HTTP request, and not its interpretation again). See the item about parallelizing server code at the top to see why you need to do this. Thirdly, fork'aya full program, you commit yourself to synchronize data between them, and it is very difficult. On the other hand, if you create a child process with literally a couple of lines of code that perform some kind of dreary and long-sleeping operation, you don’t need to synchronize anything and you don’t “crawl” to the other cores of your server. Well, as a bonus, this approach is much more flexible - you can run not a PHP child process, but a bash script or C program, or whatever it is, only your imagination limits you (and Linux knowledge, of course).
Let us dwell on child processes. How can you organize communication between parent and child processes? Of course, you can organize their communication on files, you can on the database or on some other data storage. But to support the “zoo” files of 200 pieces for each incoming request in my particular case looked very gemmno. I didn’t want to work with the database in order not to exhaust connections to MySQL (after all, it would be 200 connections per 1 incoming request - with such arithmetic I won’t be able to scale my code too much and I very quickly put it into the number of connections to the database). Fortunately, good old Linux already has tools for communication between processes (it has been for 20 years already and it seems that everyone has enough of it, which means that it should be enough for me and you too). Thus, my goal was to find such an ideal implementation of creating child processes so that:
- The parent process could write to the child's STDIN;
- The parent process knew the PID of the child process (useful if you need to send some kind of signal to the child process or check whether it has finished its work);
- The parent process could read from the STDERR and STDOUT child process;
- The parent process knew the exit code of the child process when it was completed;
- The child process knew the PPID (PID of its parent). Again, this can be convenient for communicating via signals. As we mentioned above, we will mainly consider parallelization through the launch of a child process. The child process does not have to be a PHP interpreter, so this clause does not relate directly to the parent and parallelize PHP in general. It is more likely a problem of the child process to get around the situation and find out your PPID.
Via curl_multi_exec ()
As for me, the most delusional thing I saw about PHP parallelization is to run
curl_multi_exec() on my own website. If you want to execute something asynchronously on the local OS, why do you even need to connect the HTTP stack to this case? Just because cURL can do asynchronous requests? The argument is weak. Implementing asynchrony in such a way is relatively convenient, but you will have an extra load on your web server, and it will be more difficult to configure it optimally in terms of max child work processes (in Apache prefork MPM this is “MaxClients”, in PHP FPM this is “pm.max_children”) because it is very likely that there is a huge difference between valid incoming requests and your internal requests that are degenerate from asynchrony. Well, you can forget about data synchronization issues between subprocesses. Your maximum communication is an HTTP request and an HTTP response. You can still communicate through the database, but I'm afraid to imagine what you have to do if you use transactions and you need to see the same transaction from both handlers.Another thing, if the requests are sent to another server, as in my case. Here, I consider using
curl_multi_exec() to be justified. Your main plus: you can start with a half-kick, there is no need to do much work. Your disadvantages: not every program logic can be “turned out” in such a way that it is possible to run several cURL requests from one place and process their results in the same place. For example, requests can go to 2 different hosts, and each of the hosts can respond in its own format. Thus, your code can easily become inconvenient in supporting around this curl_multi_exec() call. The second disadvantage is that you have little flexibility. In this approach, you can never do anything other than HTTP requests asynchronously.An example (I will say straight away, I didn’t really try it very hard, because the inflexibility of this approach strongly scared me away): php.net/manual/en/function.curl-multi-exec.php
Via pcntl_fork ()
If you compile PHP with the
--enable-pcntl , then the PHP functions _ * () will appear in PHP. These functions provide the framework for forking the current PHP process. The most interesting of these is pcntl_fork() . She does the fork of the PHP process and in the parent process returns the PID of the child, in the child it returns zero. While I was typing this code just an example, I had a question in my head. And if PHP works as an Apache module from under an Apache process worker, how will fork happen here? After all, in theory, fork will be a whole Apache worker process. And then how does the Apache master process respond to this case? There was a kind of division by zero in the air ... By the time I finished typing example with pcntl_fork() , the answer became obvious. Still not guess? Everything is very simple! When PHP runs from under the Apache module, pcntl_fork() not declared, even if your PHP is compiled with the appropriate flag.Supposedly,
pcntl_fork() can be used when PHP is running from the CLI. I am not sure about the CGI and FastCGI interfaces. Since I was limited in time and did not study the vacuum space in the full moon of a leap year, but solved a specific problem, then I no longer paid attention to this option. As I understand it, if pcntl_fork() can be run from the FastCGI interface, then this option should work with the Nginx + PHP-FPM bundle (Apache can also be used instead of Nginx in this formula, just who uses Apache with PHP-FPM?). Maybe someone from the readers have more experience in this issue? Write comments, and I will expand this section according to your additions. I can assume that you expect enough problems related to file descriptors and connections to the database, if you go through the fork.Through exec ()
The quickest implementation method that allows you to run any command in the OS (read “very flexible”). Before the collision with my current task, I only once resorted to this function. But I had another case there, I just needed to run the command, give it input arguments and forget about it. I didn't need any answers from her. In the process of execution, the team itself will write down the result itself. Then I implemented it like this:
exec("my-command --input1 a --input2 b &") Without an ampersand at the end of the command, it would be executed synchronously, i.e. The PHP process would have slept until the end of the work of the team. To tell the truth, I didn’t stay too long with this method, but in theory, all the necessary input arguments can be passed through the command arguments. STDERR and STDOUT commands can be redirected to files or named pipes. If you really need, you can pre-write STDIN to a file or a named pipe. In the worst case, it turns out somewhere such Frankenstein:
exec("my-command --inputargument1 a --inputargument2 b < my-stdin.txt > my-stdout.txt 2> my-stderr.txt &") The biggest drawback is that there is no good way to determine if the team has completed its work. But if you initially lay down a certain interface of the contents of STDOUT, then you can live quite well and on this method. You then need to periodically read the contents of STDOUT, and further, based on your protocol of the contents of STDOUT, you can interpret the state of the command. Under the transfer of meta information about the current status, you can get a separate file descriptor (4th, say).
Via popen ()
So, our next candidate looks a little better than the
exec("my-command &") option. Have you already noticed that I am trying to build them in ascending order? This method allows you to run the command and returns the file descriptor to the pipe. Depending on the 2nd argument of the popen() function, this will be either the STDIN of the child command or the STDOUT of the child command. It turns out somehow one-sided ... Either deaf or dumb, but conveniently in 1 line and with minimal low-level sea. I liked this option the most: $stdout = popen('my-command --inputargument1 a', 'r'); // STDOUT. // , PHP // - . do_something_while_asynchronous_command_works(); // , // , . // STDOUT // ( ). STDOUT pipe // , , // . $output = array(); while (!feof($stdout)) { $output[] = fgets($stdout); } pclose($stdout); // // . do_something_with_asynchronous_command_results($output); Supposedly, the
pclose() function will return the exit code of the child command. However, php.net warns that you don’t need to trust this value. I can’t say any additional practical notes about this, because This method is practically not tested.Among the shortcomings: it is impossible to know the current status of the child team. Sometimes it can be important. Imagine that we run 10 asynchronous commands. They all run for about 2 seconds, ± 10%. And in the main PHP process, at the end of each team we want to interpret the results. Each such interpretation will take us 0.5 seconds. If we had the opportunity to find out whether such a subsidiary team finished the work, then we could read the STDOUT of those subsidiary teams that have already completed their work. And while we are engaged in the interpretation of the current child team, the other running child commands are very likely to have time to complete by the time we are ready to interpret their result. Alas, we can not do that. The maximum that we can do in this way is to read STDOUT, and if the STDOUT of the subsidiary command is still open, then our main PHP process will sleep until the subsidiary command closes it or finishes its work (which also implicitly closes pipe). We lose a little asynchrony, because in certain situations we can “run into” a long “dream” of the main PHP process.
The second drawback: one-way communication. It would be nice to have 3 descriptors at once ... for all occasions, so to speak. And if you can do without STDIN (you can shove all the input data into the input arguments of the child command), then without STDERR it's still more difficult. Craftsmen can come up with such a solution:
$stdout = popen('my-command --inputargument1 a 2>&1', 'r') But then you will have to disassemble the porridge yourself in STDOUT, since there at any time can be the contents of STDERR. If you need STDERR, then you have to create named pipes or temporary files and redirect the STDERR stream to them yourself at the OS level. Looking ahead, I will say that if you really need STDERR, then it is better not to fool with
popen() , but go to the next paragraph of the article.Via proc_open ()
proc_open() is something like popen() older brother. He does the same thing, but he can support more than 1 pipe. Here is an example: $descriptorspec = array( 0 => array('pipe', 'r'), 1 => array('pipe', 'w'), 2 => array('pipe', 'w'), // . // , ! ); $pipes = array(); $process = proc_open('my-command –inputargument1 a', $descriptorspec, $pipes); // $process – . // $pipes – $desciptorspec // . // pipe, // PHP . $meta_info = proc_get_status($process); // $meta_info // , ( // ) PID ). // http://php.net/manual/en/function.proc-get-status.php // , STDIN. fwrite($pipes[0], $stdin); fclose($pipes[0]); do_something_while_asynchronous_command_works(); // , // . $stdout = stream_get_contents($pipes[1]); $stderr = stream_get_contents($pipes[2]); // // , . // $fdX = stream_get_contents($pipes[$x]); foreach ($pipes as $pipe) { if (is_resource($pipe)) { fclose($pipe); } } $exit_code = proc_close($process); $exit_code = $meta_info['running'] ? $exit_code : $meta_info['exitcode']; Total we have a winner! It fits us with all the criteria and runs with a fairly small amount of code in PHP. In practice, I have been using this method for about a week now and have no complaints. The website and server have not yet seen the real load, because the website has not yet reached the final stage, but pah-pah-pah I have no reason to complain, and it seems I wrote the code, the possibility of the existence of which I did not believe 10 days ago.
Specific tricks and tricks
I told about dry asynchrony implementations in PHP. But in practice, everything is so simple and beautiful never happens, is not it? Asynchrony is no exception. In conclusion, I want to give some tricks that will help you at the application level at the time of applying these techniques.
base64_encode (serialize ())
If you want to exchange information between 2 PHP processes, it is likely that at some point you will want to “push” some complex data structures inherent in your project between STDIN / STDOUT (read “not scalars”). The first thing that comes to mind is to stuff them into the PHP
serialize() function (and unserialize() , respectively, on the other side of the channel). Everything would be fine, but serialize() can insert null byte or something else, and it will break your stream. I had problems with non-ASCII characters like á, í, ú. In the end, in practice, I simply wrap the serialization result in base64 to make sure that no heresy will fall into the I / O streams.Run as early as possible, consume results as late as possible.
Skillful use of asynchronous calling is a big science. It is not hard to guess that it is necessary to launch an asynchronous child command as aggressively as possible (eager) and read the results of its work as lazy as possible. After all, this way your team will have a maximum time for execution and your main stream will not be blocked in hibernation, waiting for the end of its work. Not all program architectures conveniently fall under this principle. You should understand that to run a child command and the next line to read its result is to make yourself worse. If you plan to use asynchrony, try to think about your architecture as early as possible and always keep it in mind. Using my specific example, I’ll say that when I came to understand that I needed to parallelize my PHP process, I had to rewrite the main website engine, having deployed it with a more convenient side to asynchrony.
Cover asynchronous call with synchronous cache
Asynchrony is an extra expense. To synchronize data (if you have one), to create and kill a child process, to open and close a file descriptors, etc. On my laptop, an asynchronous call to a simple
echo "a" takes about 3 ms. It seems to be not much, but I told you that I have up to 200 asynchronous calls. 200 x 3 = 600 ms. So I have already lost 600 ms to nowhere.Secondly, supposedly, you are doing something asynchronously because it is executed slowly. So why not kill 2 birds with one stone? Cache the results of an asynchronous command in some permanent storage, be it a database, file system or memcache. Naturally, this item makes sense only if your results do not lose their relevance too quickly. Moreover, put this cache in front of all asynchronous to avoid those 3 ms. Just in case, I will give a flowchart of my thoughts:
A small framework for lazy and practical guys.
Knowing the theory is good. But usually the lazy and practical guys want to download any library, connect it, pull a couple of methods and solve their problem. Based on the last solution (through
proc_open() ) I created a very small library. It is also convenient to use for synchronous cache, as I described it in the previous section. Link: github.com/bucefal91/php-asyncSource: https://habr.com/ru/post/278755/
All Articles