Pomp - metaframe for parsing sites
With asyncio support and inspired by Scrapy .
First of all, as a data collection tool used in my hobby project, which would not crush with its power, complexity and heritage. And yes, who will deliberately start something new on python2.x?
As a result, the idea was to make a simple framework for the modern python3.x ecosystem, but as elegant as Scrapy.
')
Under the cat review article about Pomp in the style of FAQ.
And indeed, after all, a lot can be done on a simple bundle of requests + lxml . In reality, the frameworks set the rules and the necessary abstractions, and take a lot of the routine on themselves.
Pomp out of the box does not provide something that can cover a wide range of requirements in solving the problems of parsing websites: parsing content, proxies, caching, processing redirects, cookies, authorization, form filling, etc.
In this and weakness and at the same time the power of Pomp. This framework is positioned as a "framework for frameworks", in other words, gives everything you need in order to make your framework and start productively "rivet" the web of spiders.
Pomp gives the developer:
Winning:
In other words, from Pomp you can do Scrapy if you work with the network on Twisted and parse the content using lxml, etc.
In the case when you need to process N sources, with a common data model and with periodic data updates - this is the ideal case of using Pomp.
If you need to process 1-2 sources and forget, then quickly and clearly do everything at requests + lxml, and do not use special frameworks at all.
You can try to compare only in the context of a specific task.
And what is better to say is difficult, but for me it is a question that has been solved, since I can build a system of any complexity using Pomp. Other frameworks often have to deal with their “frameworks” and even hammer nails with a microscope, for example, using Scrapy to work with headless browsers, leaving all the power of Twisted to an end.
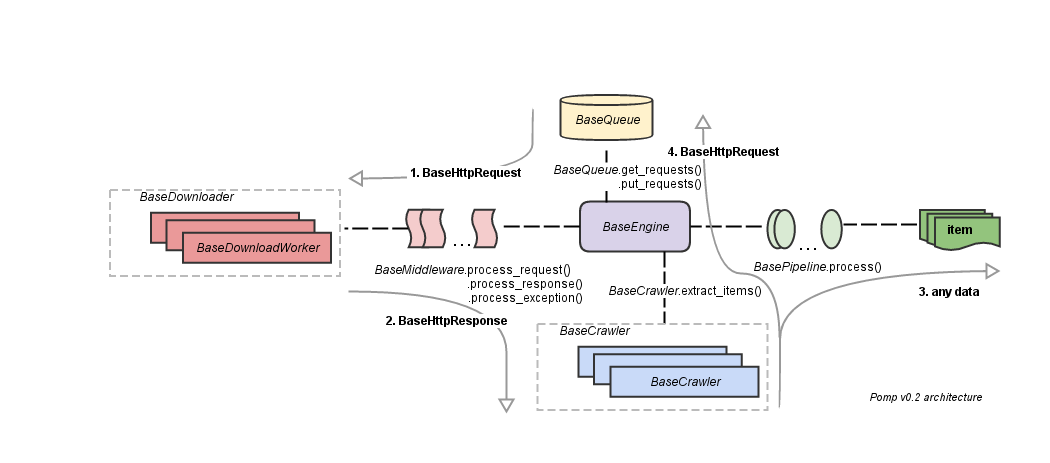
Main blocks:
- queue of requests (tasks);
- "transport" (on the diagram as BaseDownloader);
- middlewares for pre- and post-processing requests;
- pipelines for sequential processing / filtering / saving of extracted data;
- crawler to parse content and generate the following requests;
- the engine that links all the parts.
Search the page http://python.org/news for suggestions with the word
The example uses:
- Redis for organizing a centralized task queue;
- Apache Kafka for the aggregation of extracted data;
- Django on postgres for storing and displaying data;
- grafana with kamon dashboards to display the metrics for the operation of the kamon-io / docker-grafana-graphite cluster
- docker-compose to run this whole zoo on one machine.
The source code and launch instructions are available here - estin / pomp-craigslist-example .
As well as video without sound , where most of the time was spent on the deployment environment. On the video you can find some errors in collecting metrics about the size of the task queue.
Note : in the example, errors in the analysis of some pages were intentionally not corrected, so that exceptions would be investigated during the work process.
Pomp for the most part has already been formed and achieved its goals.
Further development is likely to be tighter integration with asyncio.
- project on bitbucket https://bitbucket.org/estin/pomp
- a mirror of the project on github https://github.com/estin/pomp
- documentation http://pomp.readthedocs.org/en/latest/
Why another one?
First of all, as a data collection tool used in my hobby project, which would not crush with its power, complexity and heritage. And yes, who will deliberately start something new on python2.x?
As a result, the idea was to make a simple framework for the modern python3.x ecosystem, but as elegant as Scrapy.
')
Under the cat review article about Pomp in the style of FAQ.
Why do we need frameworks for parsing sites?
And indeed, after all, a lot can be done on a simple bundle of requests + lxml . In reality, the frameworks set the rules and the necessary abstractions, and take a lot of the routine on themselves.
Why is pomp positioned as a "metaframe"?
Pomp out of the box does not provide something that can cover a wide range of requirements in solving the problems of parsing websites: parsing content, proxies, caching, processing redirects, cookies, authorization, form filling, etc.
In this and weakness and at the same time the power of Pomp. This framework is positioned as a "framework for frameworks", in other words, gives everything you need in order to make your framework and start productively "rivet" the web of spiders.
Pomp gives the developer:
- necessary abstractions (interfaces) and architecture similar to Scrapy;
- does not impose a choice of methods for working with the network and parsing the extracted content;
- can work both synchronously and asynchronously;
- competitive mining and parsing of content ( concurrent.futures );
- does not require a "project", settings and other restrictions.
Winning:
- run on python2.x, python3.x and pypy (you can even run on google app engine)
- You can use your favorite library to work with the network and to parse content;
- enter your turn tasks;
- develop your spider cluster;
- simpler transparent integration with headless browsers (see phatnomjs integration example).
In other words, from Pomp you can do Scrapy if you work with the network on Twisted and parse the content using lxml, etc.
When should Pomp be used and when not?
In the case when you need to process N sources, with a common data model and with periodic data updates - this is the ideal case of using Pomp.
If you need to process 1-2 sources and forget, then quickly and clearly do everything at requests + lxml, and do not use special frameworks at all.
Pomp vs Scrapy / Grab / etc?
You can try to compare only in the context of a specific task.
And what is better to say is difficult, but for me it is a question that has been solved, since I can build a system of any complexity using Pomp. Other frameworks often have to deal with their “frameworks” and even hammer nails with a microscope, for example, using Scrapy to work with headless browsers, leaving all the power of Twisted to an end.
Architecture
Main blocks:
- queue of requests (tasks);
- "transport" (on the diagram as BaseDownloader);
- middlewares for pre- and post-processing requests;
- pipelines for sequential processing / filtering / saving of extracted data;
- crawler to parse content and generate the following requests;
- the engine that links all the parts.
Simplest example
Search the page http://python.org/news for suggestions with the word
python simplest regexp. import re from pomp.core.base import BaseCrawler from pomp.contrib.item import Item, Field from pomp.contrib.urllibtools import UrllibHttpRequest python_sentence_re = re.compile('[\w\s]{0,}python[\s\w]{0,}', re.I | re.M) class MyItem(Item): sentence = Field() class MyCrawler(BaseCrawler): """Extract all sentences with `python` word""" ENTRY_REQUESTS = UrllibHttpRequest('http://python.org/news') # entry point def extract_items(self, response): for i in python_sentence_re.findall(response.body.decode('utf-8')): item = MyItem(sentence=i.strip()) print(item) yield item if __name__ == '__main__': from pomp.core.engine import Pomp from pomp.contrib.urllibtools import UrllibDownloader pomp = Pomp( downloader=UrllibDownloader(), ) pomp.pump(MyCrawler()) An example of creating a "cluster" for craigslist.org parsing
The example uses:
- Redis for organizing a centralized task queue;
- Apache Kafka for the aggregation of extracted data;
- Django on postgres for storing and displaying data;
- grafana with kamon dashboards to display the metrics for the operation of the kamon-io / docker-grafana-graphite cluster
- docker-compose to run this whole zoo on one machine.
The source code and launch instructions are available here - estin / pomp-craigslist-example .
As well as video without sound , where most of the time was spent on the deployment environment. On the video you can find some errors in collecting metrics about the size of the task queue.
Note : in the example, errors in the analysis of some pages were intentionally not corrected, so that exceptions would be investigated during the work process.
Future plans
Pomp for the most part has already been formed and achieved its goals.
Further development is likely to be tighter integration with asyncio.
Links
- project on bitbucket https://bitbucket.org/estin/pomp
- a mirror of the project on github https://github.com/estin/pomp
- documentation http://pomp.readthedocs.org/en/latest/
Source: https://habr.com/ru/post/278445/
All Articles