Stack Overflow Architecture

To understand how this all works, let's start with the Stack Overflow indicators. So, below is the statistics for November 12, 2013 and February 9, 2016:
statistics
- 209,420,973 (+61,336,090) HTTP requests to our load balancer;
- 66,294,789 (+30,199,477) pages were loaded;
- 1,240,266,346,053 (+406,273,363,426) bits (1.24 TB) of HTTP traffic sent;
- 569,449,470,023 (+282,874,825,991) bits (569 GB) total received;
- 3,084,303,599,266 (+1,958,311,041,954) bits (3.08 TB) total sent out;
- 504,816,843 (+170,244,740) SQL queries (only from HTTP queries);
- 5,831,683,114 (+5,418,818,063) calls to Redis;
- 17,158,874 (not tracked in 2013) searches in Elastic;
- 3,661,134 (+57,716) Tag Engine requests;
- 607,073,066 (+48,848,481) ms (168 hours) of executing SQL queries;
- 10,396,073 (-88,950,843) ms (2.8 hours) spent on accessing Redis;
- 147,018,571 (+14,634,512) ms (40.8 hours) spent on requests to the Tag Engine;
- 1.609.944.301 (-1.118.232.744) ms (447 hours) spent on processing in ASP.Net;
- 22.71 (-5.29) ms on average (19.12 ms in ASP.Net) for the formation of each of the 49,180,275 requested pages;
- 11.80 (-53.2) ms on average (8.81 ms in ASP.Net) per each of 6,370,076 home pages.
You may ask why the processing time in ASP.Net significantly decreased compared with 2013 (when it was 757 hours) despite the addition of 61 million requests per day. This happened both due to equipment upgrades in early 2015, and due to some changes in the parameters in the applications themselves. Please do not forget that performance is our distinguishing feature. If you want me to talk in more detail about the characteristics of the equipment - no problem. In the next post will be detailed hardware specifications of all servers that provide the site.
')
So what has changed in the past 2 years? In addition to the replacement of some servers and network equipment, not very much. Here is the enlarged list of the hardware part, which ensures the work of the resource (highlighted differences compared with 2013):
- 4 Microsoft SQL Servers (new hardware for 2 of them);
- 11 IIS Web servers (new hardware);
- 2 Redis servers (new hardware);
- 3 Tag Engine servers (new equipment for 2 out of 3);
- 3 Elasticsearch servers (same old);
- 4 load balancers HAProxy (added 2 to support CloudFlare);
- 2 Fortinet 800C firewalls (instead of Cisco 5525-X ASAs);
- 2 Cisco ASR-1001 routers (instead of Cisco 3945 routers);
- 2 Cisco ASR-1001-x routers (new!).
What do we need to run Stack Overflow? This process has not changed much since 2013, but due to optimization and new hardware, we only need one web server. We did not want this, but we successfully checked it several times. I bring clarity: I declare that it works. I do not claim that this (running SO on a single web server) is a good idea, although it looks quite funny every time.
Now that we have some numbers for the concept of scale, let's look at how we do it. Since few systems work in complete isolation (and ours is not an exception), often concrete architectural solutions have almost no sense without a general picture of how these parts interact with each other. The purpose of this article is to cover this big picture. Numerous subsequent posts will look at individual areas in detail. This is a logistical overview of only the main features of our “hardware”, and only then, in the following posts, they will be considered in more detail.
In order for you to understand how our equipment looks today, I cite several of my photos of rack A (compared to its “sister” B rack) taken during our refit in February 2015:

And, ironically, since that week I have 255 more photos in the album (a total of 256, and yes - this is not a random number). Now, let's look at the equipment. Here is a logical diagram of the interaction of the main systems:

Fundamental rules
Here are some universally applicable rules, so I will not repeat them for each system:
- Everything is reserved.
- All servers and network devices are interconnected with at least 2 x 10 Gbit / s channels.
- All servers have 2 power inputs and 2 power supplies from 2 UPS units connected to two generators and two network lines.
- All servers between racks A and B have a redundant partner.
- All servers and services are backed up twice through another data center (Colorado), although here I will talk more about New York.
- Everything is reserved.
On the Internet
First you must find us - this is DNS. The process of finding us must be fast, so we are entrusting this to CloudFlare (currently), since their DNS servers are closer to almost all the rest of the DNS in the world. We update our DNS records through the API, and they do DNS hosting. But since we are “brakes” with deep-seated trust issues (for others), we also still have our own DNS servers. If an apocalypse happens (probably caused by the GPL, Punyon, or caching), and people will still want to program, so as not to think about it, we will switch to them.
After you find our “secret haven”, HTTP traffic will go through one of our four Internet service providers (Level 3, Zayo, Cogent, and Lightower in New York), and through one of our four local routers. In order to achieve maximum efficiency, we, together with our providers, use BGP (fairly standard) to manage traffic and provide several ways to transmit it. The ASR-1001 and ASR-1001-X routers are combined into 2 pairs, each of which serves 2 providers in active / active mode. Thus, we provide redundancy. Although they are all connected to the same 10 Gbps physical network, external traffic passes through separate isolated external VLANs that are also connected to load balancers. After passing through the routers, the traffic is directed to the load balancers.
I think it's time to mention that between our two data centers we use the MPLS line at 10 Gb / s, but this is not directly related to the maintenance of the site. It serves to duplicate data and restore them quickly in cases where we need a packet transfer. “But Nick, this is not a reservation!” Yes, technically you are right (absolutely right): this is the only “spot” on our reputation. But wait! Through our providers, we have two more fault tolerant OSPF lines (at the cost of MPLS - No. 1, and these are No. 2 and 3). Each of these devices connects faster to the corresponding device in Colorado, and if they fail, they distribute balanced traffic among themselves. We were able to make both devices connect to both devices in 4 ways, but they are all equally good.
Go ahead.
Load Balancers ( HAProxy )
Load balancers work on HAProxy 1.5.15 under CentOS 7 , our preferred version of Linux. HAProxy also restricts TLS (SSL) traffic. To support HTTP / 2, we will soon begin to carefully study HAProxy 1.7.
Unlike all other servers with dual network connection via LACP 10 Gb / s, each load balancer has 2 pairs of 10 Gb / s channels: one for the external network and one for the DMZ. For more efficient, managed SSL negotiation, these “boxes” have 64 GB or more of memory. When we can cache more TLS sessions in memory for reuse, less time is spent creating a new connection with the same client. This means that we can resume sessions more quickly and at lower cost. Given that RAM in terms of dollars is pretty cheap, this is an easy choice.
Load balancers themselves are fairly simple devices. We create the illusion that different sites are “sitting” on different IPs (mainly on issues of certification and DNS management), and we route to different output buffers based mainly on host headers. The only “famous” things we do are speed limits and some captures of headers (sent from our site level) to the HAProxy syslog message. Therefore, we can record performance metrics for each request. We will also tell about this later.
Site Level (IIS 8.5, ASP.Net MVC 5.2.3 and .Net 4.6.1)
Load balancers regulate the traffic of 9 servers, which we call “Primary” (01-09), and 2 web servers “Dev / meta” (10-11, Wednesday of our site). Primary servers manage things like Stack Overflow, Careers, and all of the Stack Exchange sites, except meta.stackoverflow.com and meta.stackexchange.com, which are hosted on the last 2 servers. The main Q & A application itself is multiplayer. This means that one application serves requests for all Q & A sites. Let's put it another way - we can manage the entire Q & A network with one application pool on the same server. Other applications, such as Careers, API v2, Mobile API, etc. placed separately. Here is the main and dev-levels in IIS:
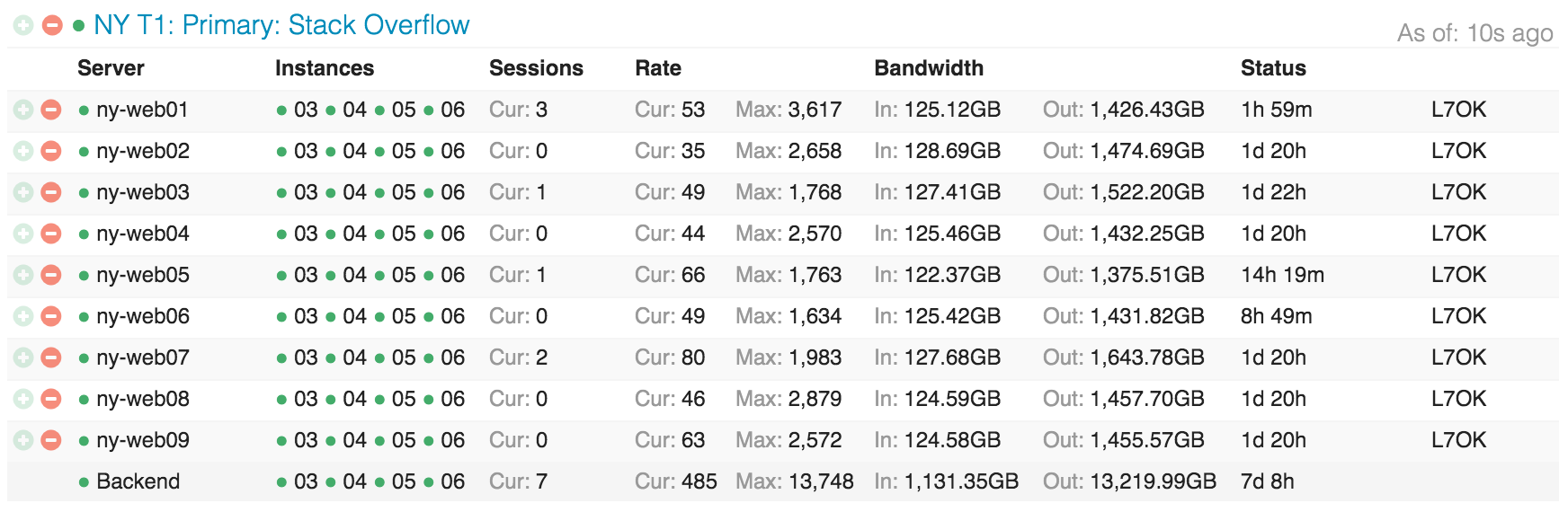
This is what the distribution of Stack Overflow by site level looks like, reminding Opserver (our internal dashboard):
... and this is what web servers look like in terms of load:
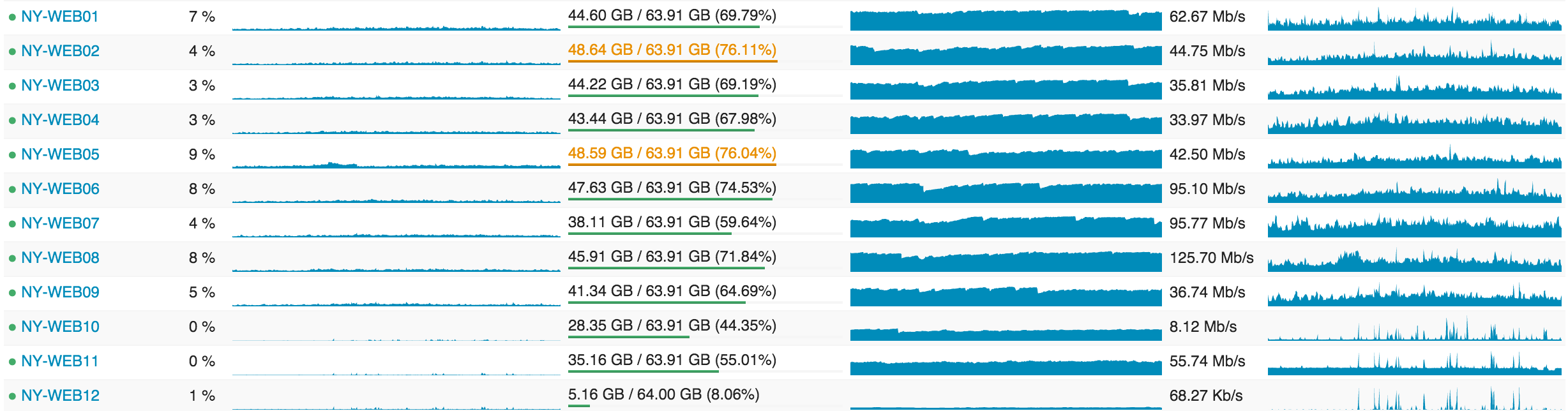
In the following posts, I will touch on why we are so “over-equipped”, but the most important points are: rolling builds, operational reserve and redundancy.
Service Link (IIS, ASP.Net MVC 5.2.3, .Net 4.6.1 and HTTP.SYS)
At the heart of these web servers is a very similar “service link”. It also works on IIS 8.5 for Windows 2012R2 and is responsible for internal services, maintaining the computational level of websites and other internal systems. There are two major “players”: “Stack Server”, which manages the Tag Engine and is based on http.sys (not under IIS), and Providence API (running on IIS). Fun fact: I have to configure a matching mask for each of these 2 processes in order to register them on different processors, because the Stack Server “clogs” the L2 and L3 caches when the list of questions is updated every 2 minutes.
These service "boxes" perform the responsible work of raising the Tag Engine and internal APIs, where we need redundancy, but not 9-fold. For example, downloading from the database (currently 2) all posts and their tags, which change every nth minute, is not very “cheap”. We do not want to download all this 9 times at the site level; enough 3 times and this provides us with sufficient "security." In addition, at the hardware level, we configure these “boxes” in different ways so that they are more optimized for various characteristics of the Tag Engine computational load and flexible indexing (which also works here). By itself, “Tag Engine” is a relatively complex topic and a separate post will be devoted to it. The main point: when you go to / questions / tagged / java, you load the Tag Engine to determine the corresponding requests. It does all our tag matching outside the search process, so new navigation and all the rest use these services for data processing.
Cache and Pub / Sub ( Redis )
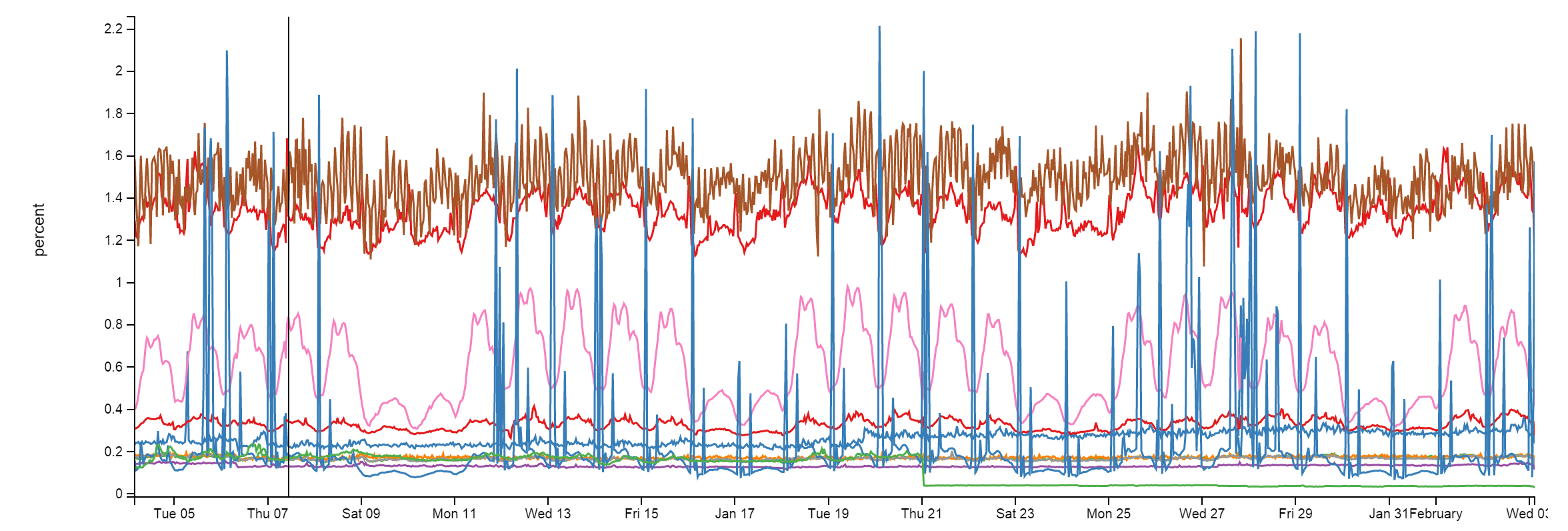
Here we use Redis for several things and they are unlikely to change much. Despite the implementation of approximately 160 billion operations per month, at each moment the CPU load is less than 2%. Usually much lower:
With Redis, we have an L1 / L2 cache system. “L1” is the HTTP cache on web servers or some running application. "L2" refers to Redis for sampling values. Our values are saved in Protobuf format through protobuf-dot-net by Marc Gravell. For the client, we use the StackExchange.Redis - open source project. When a single web server receives a cache miss (L1 or L2 cache), it takes a sample from the source (database request, API call, etc.) and places the result in the local cache and Redis. The next server, which needs to be sampled, can get L1 cache miss, but will find it in L2 / Redis, saving on a database query or an API call.
We also have a lot of Q & A sites, so each site has its own L1 / L2 caching: by the key prefix in L1 and by the database ID in L2 / Redis. We will look at this issue in more detail in the following posts.
Together with 2 main Redis servers (master / slave) that manage all requests for sites, we also have a machine learning system running on 2 more specialized servers (due to memory). It is used to display the recommended requests on the home page, to improve the issue, etc. This platform, called Providence, is served by Kevin Montrose.
The main Redis servers have 256 GB of RAM (about 90 GB are used), and the Providence servers have 384 GB of RAM installed (about 125 GB are used).
Redis is not only used to work with the cache — it also has a “publish & subscriber” algorithm (publish and subscribe), which works in such a way that one server can send a message, and all other “subscribers” will receive it - including downstream clients on Redis slave servers . We use this algorithm to flush the L1 cache on other servers when one web server does the deletion to maintain consistency. But there is another important use: websockets.
Websockets ( NetGain )
We use websockets to send real-time updates to users, such as notifications, counting votes, new navigation calculus, new answers and comments, etc.
The socket servers themselves use raw sockets running at the site level. This is a very small application on top of our open library: StackExchange.NetGain . During peak times, we simultaneously have about 500,000 parallel websocket channels open at the same time. This is a variety of browsers. Fun fact: some of these pages were opened more than 18 months ago. We do not know why. Someone has to check if these developers are still alive.
This is how the number of simultaneously open websockets changed this week:
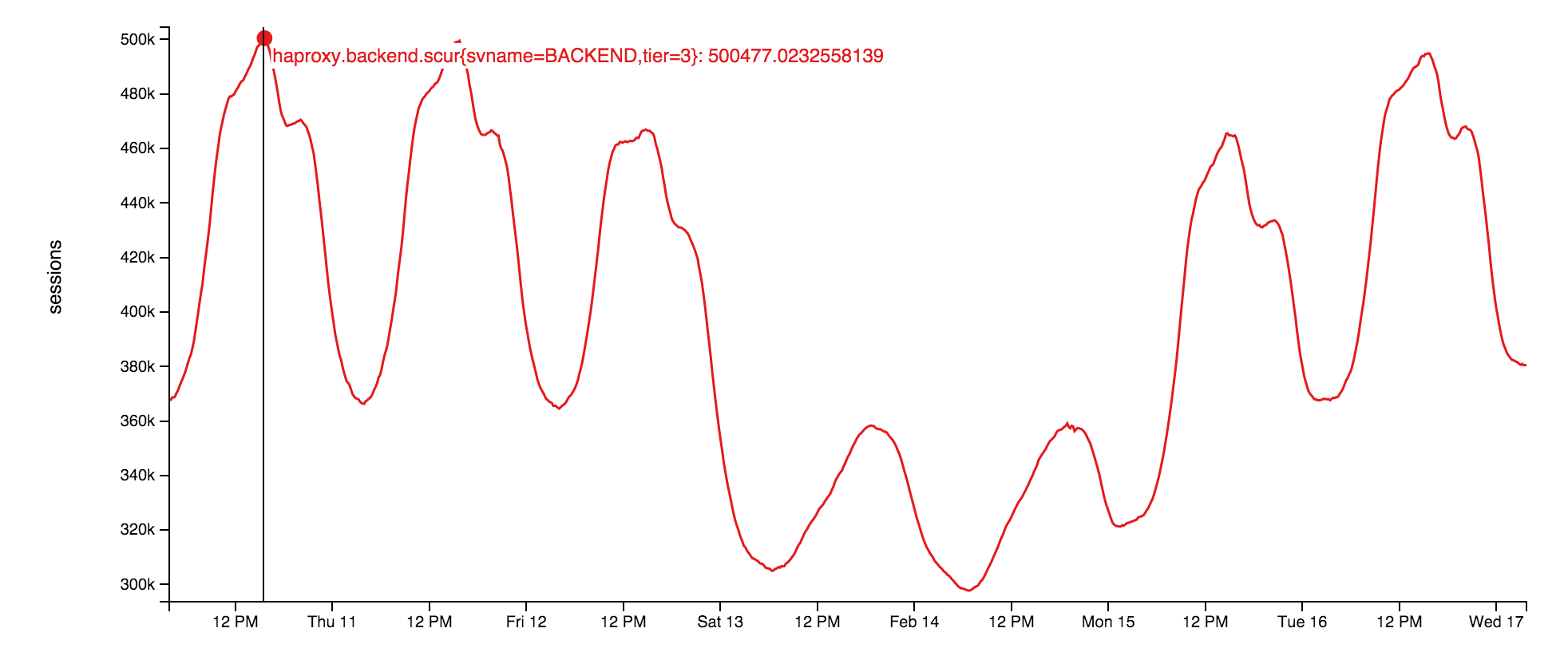
Why websocket? At our scale, they are much more effective than the survey. Just in this way, we can transfer more data to the user with fewer resources used, moreover, more quickly. But they also have problems, although the temporary port and the exhaustive search of all file descriptors on the load balancer are not serious problems. We will tell about them later.
Search ( Elasticsearch )
Spoiler: this is not something that you can come to delight.
The Web site level performs a solid search job compared to Elasticsearch 1.4, which uses a very thin high-performance client called StackExchange.Elastic. Unlike most other tools, we do not plan to post it in the public domain simply because it reflects only a very small subset of the APIs that we use. I am convinced that his release "in the light" will do more harm than good because of the confusion among the developers. We use Elastic to search, compute related queries and tips on how to form a question.
Each cluster of Elastic (there is one such in each data center) has 3 nodes, and each site has its own index. Careers has several additional indexes. This makes our system a bit non-standard: our 3 server clusters are a bit more “pumped up” with all these SSD storages, 192 GB of memory and a double network of 10 Gbit / s per channel.
The same application domains (yes, we are touched on .Net Core ...) on the Stack Server, where the Tag Engine is installed, also continuously index items in Elasticsearch. Here we use some tricks, such as ROWVERSION in SQL Server (data source), compared to the “last position” document in Elastic. Since it behaves like a sequence, we can simply use and index any items that have changed since the last pass.
The main reason we stopped at Elasticsearch instead of something like the full-text SQL search is the scalability and better distribution of money. SQL CPUs are quite expensive, Elastic is cheap and today has much better characteristics. Why not Solr ? We want to search the entire network (many indexes at once), but this was not supported by Solr at the time of the decision. The reason that we have not yet switched to 2.x is a substantial share of “types” , because of which we will have to reindex everything for updating. I simply do not have enough time to make a plan someday and make the changes necessary for the transition.
Databases (SQL Server)
We use SQL Server as our only source of reliable information. All Elastic and Redis data is obtained from the SQL server. We have 2 clusters of SQL servers running AlwaysOn Availability Groups . Each of these clusters has one master (performing almost the entire load) and one replica in New York. In addition, there is still one remark in Colorado (our data center with dynamic copying). All replicas are asynchronous.
The first cluster is a set of Dell R720xd servers, each with 384 GB of RAM, 4 TB PCIe SSDs and 2 x 12 cores. It has Stack Overflow, Sites (notorious, I will explain later), PRIZM and Mobile databases.
The second cluster is a set of Dell R730xd servers, each with 768 GB of RAM, 6 TB PCIe SSD, and 2 x 8 cores. Everything else is on this cluster. The “everything else” list includes Careers, Open ID, Chat, our Exception log and some Q & A sites (for example, Super User, Server Fault, etc.).
The use of CPU at the database level is something we prefer to avoid, but, in fact, at the moment it has increased slightly due to some cache issues that we are now solving. Now NY-SQL02 and 04 are assigned by the masters, 01 and 03 by the replicas that we rebooted today after updating the SSD. Here are the past 24 hours:

We use SQL quite simply. It's just - it's fast. While some queries may be insane, our interaction with SQL itself is just a classic. We have one “ancient” Linq2Sql , but all new developments use Dapper - our open-source Micro-ORM, using POCOs . Let me say it differently: Stack Overflow has only 1 procedure stored in the database, and I intend to translate that last piece into code.
Libraries
Well, let us switch to something that can directly help you. Some of these things I mentioned above. Here I will provide a list of most of the open .Net libraries that we support for worldwide use. We put them in open access, because they have no key business value, but they can help the world of developers. I hope you find them useful:
- Dapper (.Net Core) - high-performance Micro-ORM for ADO.Net;
- StackExchange.Redis - high-performance client Redis;
- MiniProfiler - a low -volume profiler that we use on each page (supports only Ruby, Go and Node);
- Exceptional - error log for SQL, JSON, MySQL, etc .;
- Jil - high-performance (de) serializer JSON;
- Sigil - Assistant .Net CIL generation (when C # is not fast enough);
- NetGain - high-performance websocket server;
- Opserver - a control dashboard that polls most systems directly and also receives data from Orion, Bosun or WMI;
- Bosun is a server database monitoring system written in Go.
Next will be a detailed list of the available hardware on which our software works. Then we will go further. Stay with us.
Source: https://habr.com/ru/post/278391/
All Articles