How does split-testing in Badoo work?
If you enter the query “ab testing” in Google, then there are quite a lot of articles on the topic, but they have more theory and are aimed at managers, and ready-made client implementations like Google Analytics are offered as tools. There is also an article about a very simple server implementation (in the realities of the authors, I think this is quite enough).
Today I will talk about how this happens here in Badoo, with a huge number of users around the world.
We had a whole “zoo” of tools for split testing, led by an A / B framework, some of which were developed for other purposes. Among other shortcomings, all these tools used roughly the same method for dividing users into options - this is hashing the user ID plus the “salt”. This approach did not satisfy us, and it was decided to develop a new version, in which the shortcomings of the old versions could be avoided.
The main requirements for the new version of the split-testing tool were as follows:
')
Based on these requirements and taking into account the recommendations of the BI team, the following appeared in the new tool:
A new version of the A / B framework is called UserSplit Tool or just UserSplit . Development was an incremental way. Initially, the minimum possible working functionality was made so that the tool could be used immediately. And then new features were added and bugs were fixed.
Now I propose to consider in more detail our UserSplit as of the current moment and find out why it was necessary to do it.
The page looks like this:

Here, the main fields of information, except Key , Jira issue , Test managers and the button Create Hipchat room .
The Key field is a meaningful string that uniquely identifies the test. In the software API of developers, Key is used, and not the test ID, since it is more readable and also allows you not to be tied to the test ID.
On this page, you can specify the range of test dates (when it is active), the conditions for entering the test (for example, Country is Russia), as well as options. For each option, the name and percentage of users included in it are indicated. The name is used by the developers (instead of the variant ID) in order to understand which version of the test the user got into; it is unique to the test. Only one of the options can be a control, although the control version itself may be absent.
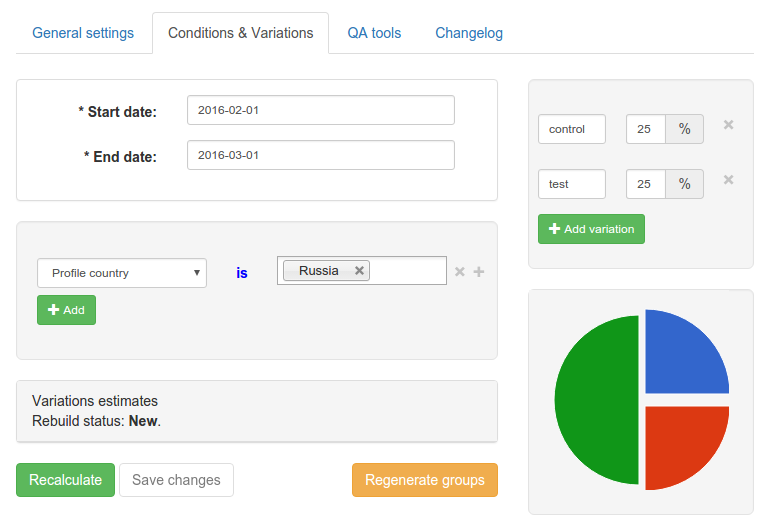
All that is on this page - the date range, test conditions, options - is the aforementioned group of test settings. There can be several such groups of settings, but there can be only one group directly tied to a test at a time — this is the current group of settings. Each time the test settings group changes, in fact, it does not change, but a new one is created. However, it does not immediately bind to the test, but only after it is ready. To prepare a group of settings, it is necessary to assign random split-groups for variants, as well as to calculate the test score and the intersection with other tests.
In an amicable way, any test should have at least 2 options for comparison. In most of the tests, the control version is used when we compare what was with what has become. But if a new “feature” is launched, and it has 2 design options, then there will not be a control version, since before it did not exist, so there is nothing to compare with. Now the control variant cannot be deleted, but if it is not needed, then it can be set to 0%. In the future, the interface is planned to change a little, but for now it is.
It is important that there is no additional logic for the control variant (except for hit logging), so that it does not differ from the case when the test is inactive. Otherwise, it turns out that this is not a control variant, but one of the tested ones.
Based on the requirements, the use of hashing the user ID plus salt is not suitable for dividing users, because It does not allow you to quickly evaluate how users get into the options (the base will rather slowly calculate the hash with salt on the fly, and for each test it will recalculate the hashes for all users with different salt, which is obviously a rather expensive operation). Also, hashing does not allow to achieve the maximum possible "non-interruption" of users between tests.
We decided to use split-groups instead. The idea is as follows: to issue new users (at registration) and already existing split-groups in the range from 1 to 2400 in a random way.
The number of 2400 is convenient in that it is easy to divide it into pieces in 5% increments. 120 groups fall into each 5%. And then these 120 groups are divided without remainder into 2, 3, 4, 5, 6, 8, 10, 12 variants. 7, 9 and 11 variants is an extremely rare case, we have not met, but if this is the case, then we can add the 2nd control variant and not take it into account in the statistics.
For guest (unauthorized) users, the split-group on the web is placed in a “cookie” and may well not coincide with the split-group of the user after login. This was done specifically so that guest users could see the same version of the site in the same browser (for example, an authorization or registration form), regardless of which split-group the last logged in user had. But now information about guest users is not uploaded to BI, therefore, when conducting such tests, the statistics are not complete. Now we are in the process of finalizing this part.
When adding options for a test, they are randomly assigned (according to percentages) split-groups. Those. if 10% of users are allotted to the option, then 240 random split-groups will correspond to it. It is worth noting that in the development process we did not implement the possibility of dividing users into equal groups, but made an indication of the percentages for each option, while if one option changes the percentage, then it changes for all others. Perhaps later we will make it possible to indicate the number of percentages for the test as a whole, and the split groups corresponding to this percentage will be divided equally between the options.
For evaluation, we use the Exasol database (a recent article by my wildraid colleague was about it), so information about tests and setting groups (including test options and their split-groups) is downloaded into it.
In fact, split-groups are not issued in a completely random manner. All tests that intersect with the current by date (but do not occupy 100% of split-groups) are extracted from the database. Then, for these tests, based on the filter conditions (excluding split groups), a check is made through the Exasol database to see if there is a real intersection between them and the current test. Of the really intersecting tests are occupied by split-groups. Accordingly, when allocating split groups to the current test, first of all, there is a choice of free split groups, and only then - busy ones, if there are not enough free ones. Further selected groups are distributed randomly by options. This allows you to achieve the lowest possible intersection between tests while maintaining the homogeneity of the audience between the options, for example:
The first line shows the possible numbers of split groups (for clarity, I took only 10). In the 2nd, 3rd and 5th lines, we see test variants and the corresponding split-groups. In the 4th row of the table, the free split-groups are marked by pluses, and the minuses are occupied. Suppose we have a test "Test", which intersects with the tests "Test1" and "Test2". Suppose we need 4 split-groups for the “Test” test. First of all, we choose free split-groups 4 and 7, then - randomly from those employed, for example, 5 and 9. After that, we mix and distribute by options. Actually, the result is on the last row of the table - we have achieved the maximum “non-intersection” with other tests.
After the split-groups are given out to variants, the intersections with other tests are calculated (what percentage of users intersects with which test).
Next, we evaluate the test itself: how many users are included in which option, up to the user. With the help of these figures, it is possible to understand whether it is worth conducting a test on these conditions, in order to achieve a statistically significant result , and whether overlapping tests can not give a distortion of the results.
Here is the result of counting the test score and its intersections with other tests:
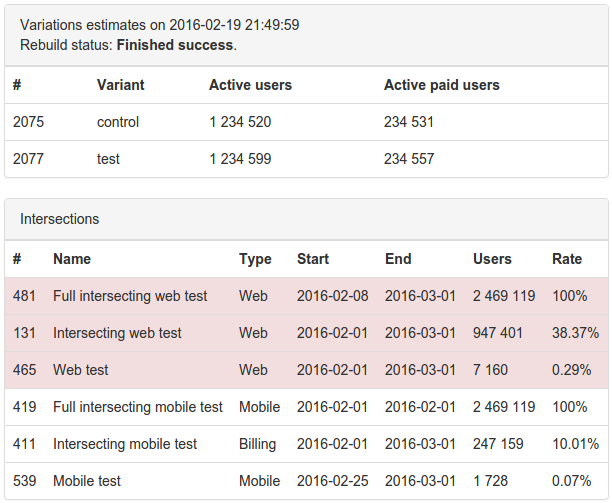
* All figures are fictional, any connection with reality is random.
Tests of the same type are highlighted in red. This is done for clarity, because, for example, mobile tests are unlikely to affect the tests on the web.
It is worth noting that the first implementation of the calculation of intersections was not very fast, and if at first the calculation was performed in seconds, then with an increase in the number of simultaneously running tests, it began to reach half an hour. Several optimizations were carried out, now the counting of intersections is no more than one and a half minutes, and the full implementation of the counting of intersections and estimation is up to two minutes.
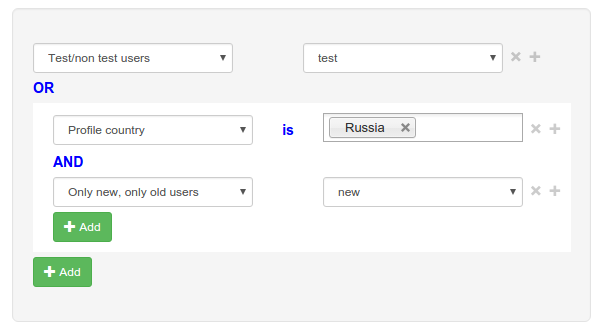
The UserSplit interface allows you to specify test conditions quite flexibly. You can use the operators AND and OR, you can take the conditions in brackets. Suppose we want the test to be available to all test users, as well as new users from Russia. Then you can create such a filter:
All possible filters available in the interface are easy to verify conditions, i.e. All data for these filters, as a rule, we already have in memory. If not, they can be easily downloaded.
There are also environment filters that show how and where the user came from. For example, this is the user agent, the country in which the user is currently located (not to be confused with the country specified by the user in the profile) and the user's platform (Web, iOS, Android, etc.). For guest users only environment-filters are available.
We want to conduct many tests at the same time, but if we run tests in all countries at once, they will intersect and, possibly, influence each other. To avoid this, tests can be run in different countries. In this case, another problem may come out - the test may well show itself in one country and badly in others. To prevent this from happening, the test conditions can be changed by adding more countries there. Thus, we can get more reliable results and make the right decision. As mentioned earlier, so that such test changes are not misleading when examining test reports, the report displays data for several test versions.
For ease of development, testing and finding the causes of problems, QA tools have been made.
Flow tests look like this:
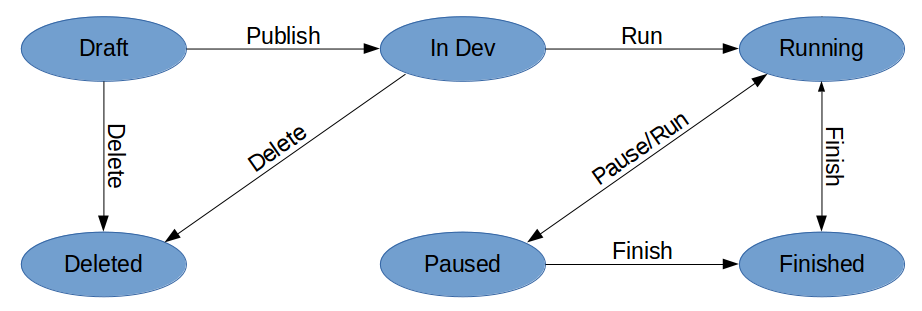
When a test has just been created, it is in Draft status. In this state, the product manager can “play” with him (see his assessment and intersections with other tests), while no one sees the test itself (except him and the super-users).
After the test is ready, the product manager must publish it (Publish action) for developers. Now the test goes to In Dev status. In this status, the test date range is ignored and is available only to test users. We track hits from production, and as soon as they start to arrive, test managers are notified that the test is ready and can be run.
To run a test on real users, it must be transferred to the status of Running. For a temporary shutdown - pause (Paused status).
At the end of the test (Finish), you can take the resulting version and decide whether it will be applied everywhere (worldwide) or only according to the conditions of the test.
You can also do Reject if you want to leave the old version. At the same time, Reject is not the same as choosing the control variant, since it may not be, and none of the choices did not suit.
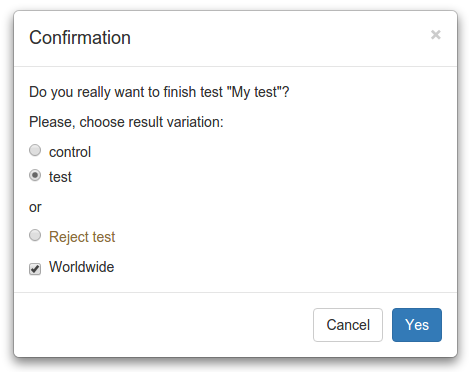
In the future, we plan to automatically set the task of “cutting out” the test from the code after it is completed.
It is quite expensive to take information about tests from the database or any other repository, just to check which options for which tests are active for the user. Therefore, we decided to store the test configuration on each server locally. The PHP file with an array (a separate file for each test) was selected as the config format. This choice allows you to spend a minimum of time processing the config by using the bytecode cache. Tests are laid out simultaneously on all servers (development, test and production), so that it does not happen that, in the environment of development and on “combat” machines, something works differently. For the layout, we use the same tools as for the other configs.
Since There are many servers, the layout does not take place instantly (about a couple of minutes), but for the problem being solved this is not critical. Moreover, the development environment is pretty fast in the first place. Those. if you need to fix something, then the changes can be seen pretty quickly.
Tests that need to be expanded are easy to notice - they are highlighted in red in the general list.
As part of a split test, it is important to collect statistics. Key KPI-indicators are already sent to BI with binding to the user, so most of the split tests do not need to send any additional statistics. Suffice it to say that the user has got into one or another version of the test. This action we have is sending a hit. The main thing here is not to be confused with the fact that the user has done some kind of action that needs to be measured as part of the test. For example, we have a green button and we want to check whether it will be clicked more often if we change its color to red. It turns out that you need to send a hit at the moment of displaying a green (control version) or red (testing option) button. In this case, it is assumed that clicks on the button are already sent to BI, and if this is not the case, then such sending must be added, otherwise we will not be able to evaluate the result of the experiment.
For developers, the old A / B framework provided the following methods:
It turns out that the implementation of all the logic of the A / B test fell on the shoulders of the developer. And the logic includes the conditions of entry (in which countries, etc.) and what percentage of users should fall into one or another option. In this case, the developer could easily make a mistake (due to carelessness or not understanding what audience homogeneity is).
For example, we need to select all users from Russia and divide in half.
Let's say the developer wrote the following code:
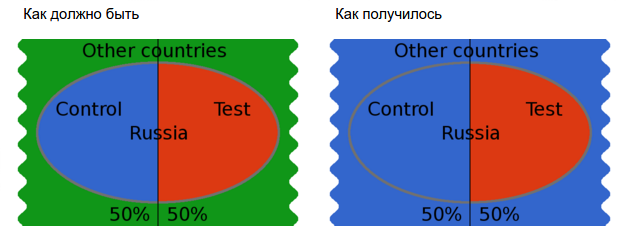
Those. The control version will get many more users, including users from another segment (other countries), which can lead to ambiguous results (users from other countries may behave differently).
In the new version of the software interface, for consistency, a special namespace \ UserSplit \ Tests was allocated for classes with constants. If the test does not have any additional logic, then you can use the class \ UserSplit \ Tests \ Common.
Checking for a hit in the variant looks like this:
When calling the method \ UserSplit \ SplitTests \ Checker :: getActiveVariant (), the log is automatically logged. It turns out that if there is no additional logic, then it will be impossible to unequally hit the hits, as in the old version.
To disable automatic logging of hits, you need to pass the 4th parameter to false and do not forget to log the hit later:
This may be necessary, for example, when sending emails. In this case, the user should hit the test only when he has read the letter (as a rule, there are ways to verify this).
If there is any additional logic in determining whether the user is in the test version, then you need to create your own class. It looks something like this:
Here you need to pay attention to the important points that are described in the comments. Given that it is easy to make a mistake here, you need to use this approach only in exceptional cases. There are two of them:
Tests that do not need any additional server logic can be performed completely on the client (mobile application or JS in the browser). For example, the color of the button can be tested completely on the client, especially since we now draw templates in JS, and not on the server. For this, the implementation of the mobile API and the interaction with JS were refined (in fact, now the same API is used there). It worked as follows: the client sent a list of supported tests (in the form of numbers - ID tests in the string format), and the server responded by sending a list of tests with active variants (in the same form). Since for new tests, we began to use test keys and option names, and it was easy to distinguish a number from a line, then for new tests we simply began to operate on them.
There are also tests of mixed type (I call them client-server), where both on the server and on the client you need to know which option is active. In this case, besides getting into the test, you need to check whether the client supports this test.
There was a problem with the fact that we can’t just add a check for additional conditions in client and client-server tests. Such a check can be automated by making such an interface:
After checking the conditions, we do an additional check: if the test has a PHP class (a class that is in the \ UserSplit \ Tests namespace and has the same name as the test key, but in CamelCase) and it implements this interface, then we call checkAdditionalConditions () method. If the result is false, then the user did not get into the test. We have not had time to implement this idea yet, but we are going to.
In the billing team, the “user groups” tool was developed. It was originally made to manage the availability of features for users.
It was used as follows: for example, we have seasonal presents for Christmas, but it makes no sense to display them in Muslim countries, because there it is not celebrated. In this case, we can create a user group in which the list of countries where Christmas is celebrated will be registered, and check the user for entry into it before displaying Christmas gifts. Accordingly, this user group can be changed (for example, add countries) via the web interface without attracting a developer. It would be wrong to use split tests in this case, since we do not need to compare options, we only need to enable the feature for a certain circle of users.
But, in addition to the direct appointment, this tool was used for split testing. For example, tests as an entity were absent there and were created in the form of several user groups representing options.
In general, split-testing tools and user groups are quite similar, and keeping two similar tools is not very good. Therefore, we decided to make user groups based on UserSplit, and to transfer user billing commands to UserSplit.
The interface (both software and web) looks almost the same as the split test interface, but it is simplified due to the lack of options. This is how the program interface looks like:
Sometimes it becomes necessary to go through all users that meet some conditions in order to perform an action. For split tests and user groups a UserSplit Iterator has been made. It allows you to create the correct SQL query in the database, including all the conditions of the test or group of users, and get only those users who fall into the test or user group.
In addition to the already voiced problems and plans, we have a couple more ideas:
In one of the tests conducted tokens (texts), where we renamed one of the paid features, we got a good profit increase. But such changes require a lot of developer resources. Since we have our own translation system of tokens, we decided to embed split testing in it, in order to attract a developer for this there was no need. Now this feature is under development by the back office team.
On the test page, it is planned to display a graph of how many users fall into which option, so that you can see if there is traffic on the test and how even it is between the options.
The result was a fairly powerful tool that can still be developed. It has been successfully used for six months. About 40 tests have been conducted so far and about 30 have been launched. On average, the check for user hit in tests is about 0.5 ms.
If you have questions on this topic - feel free to ask them in the comments.
And thanks to everyone who participated in the development of UserSplit!
Rinat Ahmadeev, PHP developer.
Today I will talk about how this happens here in Badoo, with a huge number of users around the world.
We had a whole “zoo” of tools for split testing, led by an A / B framework, some of which were developed for other purposes. Among other shortcomings, all these tools used roughly the same method for dividing users into options - this is hashing the user ID plus the “salt”. This approach did not satisfy us, and it was decided to develop a new version, in which the shortcomings of the old versions could be avoided.
The main requirements for the new version of the split-testing tool were as follows:
')
- we have a big project and a big team, so you need to do a lot of tests at the same time;
- tests that are running at the same time should intersect at the minimum among users; if there are intersections with other tests, information about this should be displayed to the manager;
- when creating a test, I would like to understand how many people will fall into each test version;
- so that when analyzing there were no questions why the test KPIs suddenly jumped, changes in test conditions should be displayed in the report;
- Software API for developers should be simple and reduce the likelihood of error;
- need the ability to change the test conditions without the involvement of the developer;
- for QA there should be a handy tool that allows you to specify an option for the user, regardless of whether the user falls under the test conditions or not;
- user check for entering the test should pass quickly enough so that it does not affect the page return time;
- The test should not be infinite, because over time it will greatly complicate the assessment of the intersections of the tests, and also introduce entropy into the code.
Based on these requirements and taking into account the recommendations of the BI team, the following appeared in the new tool:
- the ability to specify the conditions for entering the test in the form of a filter;
- the ability to specify the start and end dates of the test in the required fields;
- the ability to specify options for the test, as well as the percentage of options;
- when saving, the estimated hit score of users in the test options, as well as the intersection with other tests (as a percentage);
- each time a test changes, a new test settings group is created, so to speak, which includes filters, test start and end dates, as well as options, which allows you to see test changes in BI reports and understand the cause of jumps in the charts;
- to estimate the number of users on the fly. All users were divided into split-groups, and the distribution of users according to options was reduced to the distribution of split-groups by options.
A new version of the A / B framework is called UserSplit Tool or just UserSplit . Development was an incremental way. Initially, the minimum possible working functionality was made so that the tool could be used immediately. And then new features were added and bugs were fixed.
Now I propose to consider in more detail our UserSplit as of the current moment and find out why it was necessary to do it.
Basic properties of the test
The page looks like this:
Here, the main fields of information, except Key , Jira issue , Test managers and the button Create Hipchat room .
The Key field is a meaningful string that uniquely identifies the test. In the software API of developers, Key is used, and not the test ID, since it is more readable and also allows you not to be tied to the test ID.
Description of the remaining fields
In the Jira issue field, we specify the Jira task number. It is used to make it easier to find the task in which the test was made. Also, this task will receive automatic comments with notifications.
In the field Test managers we indicate those people who have access to edit the test; they will receive notifications from Hipchat. As a rule, the author of the test and the watchers of the Jira task come here.
Button Create Hipchat room creates a room in the messenger and adds all the test managers there. Notifications will also be sent to this room, in addition, you can discuss the details of the test here. You can also add other users to the room directly from the UserSplit interface:
Now there are two:
In the future, it is planned to make a notice of the imminent end of the test, and possibly some other notices.
In the field Test managers we indicate those people who have access to edit the test; they will receive notifications from Hipchat. As a rule, the author of the test and the watchers of the Jira task come here.
Button Create Hipchat room creates a room in the messenger and adds all the test managers there. Notifications will also be sent to this room, in addition, you can discuss the details of the test here. You can also add other users to the room directly from the UserSplit interface:
Notifications
Now there are two:
- notification of the imminent start of the test (the starting date is approaching);
- notice that the code for the test is laid out "for battle" and the test can be run.
In the future, it is planned to make a notice of the imminent end of the test, and possibly some other notices.
Test conditions and options
On this page, you can specify the range of test dates (when it is active), the conditions for entering the test (for example, Country is Russia), as well as options. For each option, the name and percentage of users included in it are indicated. The name is used by the developers (instead of the variant ID) in order to understand which version of the test the user got into; it is unique to the test. Only one of the options can be a control, although the control version itself may be absent.
All that is on this page - the date range, test conditions, options - is the aforementioned group of test settings. There can be several such groups of settings, but there can be only one group directly tied to a test at a time — this is the current group of settings. Each time the test settings group changes, in fact, it does not change, but a new one is created. However, it does not immediately bind to the test, but only after it is ready. To prepare a group of settings, it is necessary to assign random split-groups for variants, as well as to calculate the test score and the intersection with other tests.
Options
In an amicable way, any test should have at least 2 options for comparison. In most of the tests, the control version is used when we compare what was with what has become. But if a new “feature” is launched, and it has 2 design options, then there will not be a control version, since before it did not exist, so there is nothing to compare with. Now the control variant cannot be deleted, but if it is not needed, then it can be set to 0%. In the future, the interface is planned to change a little, but for now it is.
It is important that there is no additional logic for the control variant (except for hit logging), so that it does not differ from the case when the test is inactive. Otherwise, it turns out that this is not a control variant, but one of the tested ones.
Split user groups
Based on the requirements, the use of hashing the user ID plus salt is not suitable for dividing users, because It does not allow you to quickly evaluate how users get into the options (the base will rather slowly calculate the hash with salt on the fly, and for each test it will recalculate the hashes for all users with different salt, which is obviously a rather expensive operation). Also, hashing does not allow to achieve the maximum possible "non-interruption" of users between tests.
We decided to use split-groups instead. The idea is as follows: to issue new users (at registration) and already existing split-groups in the range from 1 to 2400 in a random way.
The number of 2400 is convenient in that it is easy to divide it into pieces in 5% increments. 120 groups fall into each 5%. And then these 120 groups are divided without remainder into 2, 3, 4, 5, 6, 8, 10, 12 variants. 7, 9 and 11 variants is an extremely rare case, we have not met, but if this is the case, then we can add the 2nd control variant and not take it into account in the statistics.
For guest (unauthorized) users, the split-group on the web is placed in a “cookie” and may well not coincide with the split-group of the user after login. This was done specifically so that guest users could see the same version of the site in the same browser (for example, an authorization or registration form), regardless of which split-group the last logged in user had. But now information about guest users is not uploaded to BI, therefore, when conducting such tests, the statistics are not complete. Now we are in the process of finalizing this part.
When adding options for a test, they are randomly assigned (according to percentages) split-groups. Those. if 10% of users are allotted to the option, then 240 random split-groups will correspond to it. It is worth noting that in the development process we did not implement the possibility of dividing users into equal groups, but made an indication of the percentages for each option, while if one option changes the percentage, then it changes for all others. Perhaps later we will make it possible to indicate the number of percentages for the test as a whole, and the split groups corresponding to this percentage will be divided equally between the options.
Test grade
For evaluation, we use the Exasol database (a recent article by my wildraid colleague was about it), so information about tests and setting groups (including test options and their split-groups) is downloaded into it.
In fact, split-groups are not issued in a completely random manner. All tests that intersect with the current by date (but do not occupy 100% of split-groups) are extracted from the database. Then, for these tests, based on the filter conditions (excluding split groups), a check is made through the Exasol database to see if there is a real intersection between them and the current test. Of the really intersecting tests are occupied by split-groups. Accordingly, when allocating split groups to the current test, first of all, there is a choice of free split groups, and only then - busy ones, if there are not enough free ones. Further selected groups are distributed randomly by options. This allows you to achieve the lowest possible intersection between tests while maintaining the homogeneity of the audience between the options, for example:
| one | 2 | 3 | four | five | 6 | 7 | eight | 9 | ten | |
|---|---|---|---|---|---|---|---|---|---|---|
| Test1 | A | B | B | A | ||||||
| Test2 | A | B | A | A | B | B | ||||
| - | - | - | + | - | - | + | - | - | - | |
| Test | A | B | B | A |
After the split-groups are given out to variants, the intersections with other tests are calculated (what percentage of users intersects with which test).
Next, we evaluate the test itself: how many users are included in which option, up to the user. With the help of these figures, it is possible to understand whether it is worth conducting a test on these conditions, in order to achieve a statistically significant result , and whether overlapping tests can not give a distortion of the results.
Here is the result of counting the test score and its intersections with other tests:
* All figures are fictional, any connection with reality is random.
Tests of the same type are highlighted in red. This is done for clarity, because, for example, mobile tests are unlikely to affect the tests on the web.
It is worth noting that the first implementation of the calculation of intersections was not very fast, and if at first the calculation was performed in seconds, then with an increase in the number of simultaneously running tests, it began to reach half an hour. Several optimizations were carried out, now the counting of intersections is no more than one and a half minutes, and the full implementation of the counting of intersections and estimation is up to two minutes.
Test conditions
The UserSplit interface allows you to specify test conditions quite flexibly. You can use the operators AND and OR, you can take the conditions in brackets. Suppose we want the test to be available to all test users, as well as new users from Russia. Then you can create such a filter:
Internal device and condition processing
The conditions shown in the screenshot are converted to JSON format:
For optimization, we do not handle all conditions. For example:
(A AND B) OR C
If A is false, then condition B will not be processed and processing will immediately go to condition C.
If A and B are true, then the condition C will not be processed and the total value will be true, i.e. user is subject to filter conditions.
[ { "filter":"is_test_user", "operator":"eq", "value":"Yes" }, "OR", [ { "filter":"country_id", "operator":"in", "value":["50"] }, "AND", { "filter":"is_new_user", "operator":"eq", "value":"1" } ] ] For optimization, we do not handle all conditions. For example:
(A AND B) OR C
If A is false, then condition B will not be processed and processing will immediately go to condition C.
If A and B are true, then the condition C will not be processed and the total value will be true, i.e. user is subject to filter conditions.
All possible filters available in the interface are easy to verify conditions, i.e. All data for these filters, as a rule, we already have in memory. If not, they can be easily downloaded.
There are also environment filters that show how and where the user came from. For example, this is the user agent, the country in which the user is currently located (not to be confused with the country specified by the user in the profile) and the user's platform (Web, iOS, Android, etc.). For guest users only environment-filters are available.
Change test conditions
We want to conduct many tests at the same time, but if we run tests in all countries at once, they will intersect and, possibly, influence each other. To avoid this, tests can be run in different countries. In this case, another problem may come out - the test may well show itself in one country and badly in others. To prevent this from happening, the test conditions can be changed by adding more countries there. Thus, we can get more reliable results and make the right decision. As mentioned earlier, so that such test changes are not misleading when examining test reports, the report displays data for several test versions.
QA tools
For ease of development, testing and finding the causes of problems, QA tools have been made.
QA tools description
Sometimes it is quite difficult to make the user get under the test conditions. It may be even more difficult with a split group, especially if a small percentage of users are used for the test. And if a developer can do, say, a “hack” in the code in order to see the desired test version, then a QA specialist is simply not allowed to do this. Therefore, so-called QA tools were created for developers, for QA-specialists.
QA tools consist of two tools:
You can add a user to the option by user ID or by device_id (convenient for guest users using mobile applications). In this case, you can specify for which user ID you need to do this - from the production environment or development environment (devel checkbox).
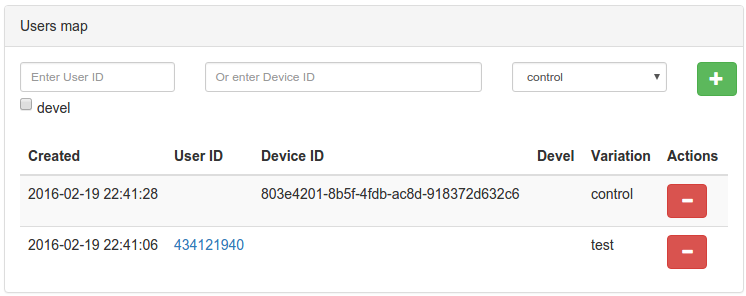
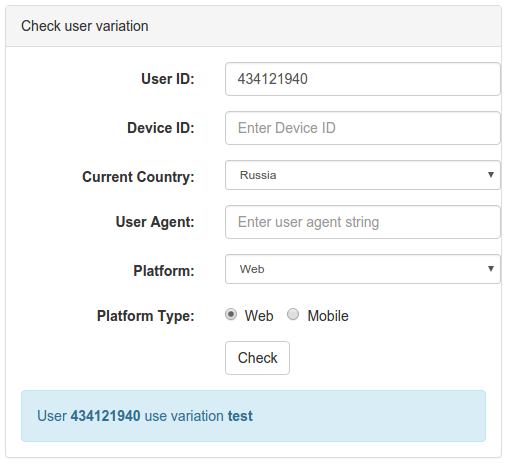
When checking a user for getting into the test version, you must specify a user ID or device_id, as well as environment-filter values, if necessary. When clicking on the Check button, we will see which version of the test the user got, or the reason for which he did not get (the split-group did not fit, did not pass under the conditions, etc.).
When conducting automated tests, as a rule, random users are taken from the pool. It turns out that different users fall into different variants of split tests, because of what autotests break. Therefore, a special API was made for automated tests, which allows you to specify which user falls into which option. But this problem is not completely solved, because new split tests are constantly appearing that make auto tests unstable. We plan to make a method in the API that will disable all tests for the user. Accordingly, if you need to check some version of the split test, then for such a user it will be possible to turn on any one split test after turning off all the others.
QA tools consist of two tools:
- add user to option;
- check which option falls into the user.
Add user to option
You can add a user to the option by user ID or by device_id (convenient for guest users using mobile applications). In this case, you can specify for which user ID you need to do this - from the production environment or development environment (devel checkbox).
Check user hit option
When checking a user for getting into the test version, you must specify a user ID or device_id, as well as environment-filter values, if necessary. When clicking on the Check button, we will see which version of the test the user got, or the reason for which he did not get (the split-group did not fit, did not pass under the conditions, etc.).
Automated Testing
When conducting automated tests, as a rule, random users are taken from the pool. It turns out that different users fall into different variants of split tests, because of what autotests break. Therefore, a special API was made for automated tests, which allows you to specify which user falls into which option. But this problem is not completely solved, because new split tests are constantly appearing that make auto tests unstable. We plan to make a method in the API that will disable all tests for the user. Accordingly, if you need to check some version of the split test, then for such a user it will be possible to turn on any one split test after turning off all the others.
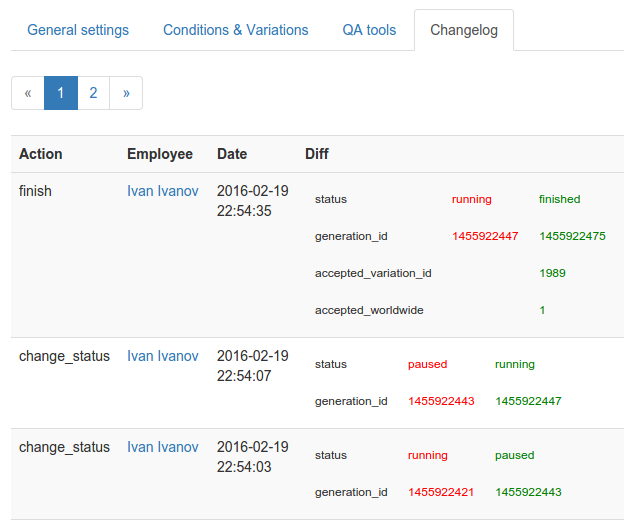
Test change log
Test change log
To simplify the search for the causes of problems, all test changes are written to the database and displayed on the Changelog page:
Flow tests
Flow tests look like this:
When a test has just been created, it is in Draft status. In this state, the product manager can “play” with him (see his assessment and intersections with other tests), while no one sees the test itself (except him and the super-users).
After the test is ready, the product manager must publish it (Publish action) for developers. Now the test goes to In Dev status. In this status, the test date range is ignored and is available only to test users. We track hits from production, and as soon as they start to arrive, test managers are notified that the test is ready and can be run.
To run a test on real users, it must be transferred to the status of Running. For a temporary shutdown - pause (Paused status).
End of tests
At the end of the test (Finish), you can take the resulting version and decide whether it will be applied everywhere (worldwide) or only according to the conditions of the test.
You can also do Reject if you want to leave the old version. At the same time, Reject is not the same as choosing the control variant, since it may not be, and none of the choices did not suit.
In the future, we plan to automatically set the task of “cutting out” the test from the code after it is completed.
Test Layout
It is quite expensive to take information about tests from the database or any other repository, just to check which options for which tests are active for the user. Therefore, we decided to store the test configuration on each server locally. The PHP file with an array (a separate file for each test) was selected as the config format. This choice allows you to spend a minimum of time processing the config by using the bytecode cache. Tests are laid out simultaneously on all servers (development, test and production), so that it does not happen that, in the environment of development and on “combat” machines, something works differently. For the layout, we use the same tools as for the other configs.
Since There are many servers, the layout does not take place instantly (about a couple of minutes), but for the problem being solved this is not critical. Moreover, the development environment is pretty fast in the first place. Those. if you need to fix something, then the changes can be seen pretty quickly.
Tests that need to be expanded are easy to notice - they are highlighted in red in the general list.
Statistics
As part of a split test, it is important to collect statistics. Key KPI-indicators are already sent to BI with binding to the user, so most of the split tests do not need to send any additional statistics. Suffice it to say that the user has got into one or another version of the test. This action we have is sending a hit. The main thing here is not to be confused with the fact that the user has done some kind of action that needs to be measured as part of the test. For example, we have a green button and we want to check whether it will be clicked more often if we change its color to red. It turns out that you need to send a hit at the moment of displaying a green (control version) or red (testing option) button. In this case, it is assumed that clicks on the button are already sent to BI, and if this is not the case, then such sending must be added, otherwise we will not be able to evaluate the result of the experiment.
Software interface
For developers, the old A / B framework provided the following methods:
// , \ABFramework\Utils::matchPercentage( $user_id, // ID , ( ) $from_percent, $to_percent, $salt // , , ); // , .. , \ABFrameworkAPI::addHit($user_id, $test_id, $experiment_id, $variation_id); It turns out that the implementation of all the logic of the A / B test fell on the shoulders of the developer. And the logic includes the conditions of entry (in which countries, etc.) and what percentage of users should fall into one or another option. In this case, the developer could easily make a mistake (due to carelessness or not understanding what audience homogeneity is).
For example, we need to select all users from Russia and divide in half.
Let's say the developer wrote the following code:
if ($country_id == \Country::RUSSIA && \ABFramework\Utils::matchPercentage($user_id, 0, 50, 'salt')) { $variation_id = static::VARIATION_ID_TEST; } else { $variation_id = static::VARIATION_ID_CONTROL; } \ABFrameworkAPI::addHit($user_id, static::TEST_ID, static::EXPERIMENT_ID, $variation_id); Those. The control version will get many more users, including users from another segment (other countries), which can lead to ambiguous results (users from other countries may behave differently).
In the new version of the software interface, for consistency, a special namespace \ UserSplit \ Tests was allocated for classes with constants. If the test does not have any additional logic, then you can use the class \ UserSplit \ Tests \ Common.
Checking for a hit in the variant looks like this:
$Environment = \UserSplit\CheckerEnvironment::byGlobals(); // environment-, . $Checker = \UserSplit\SplitTests\Checker::getInstance(); // DI , , .. $variant = $Checker->getActiveVariant(\UserSplit\Tests\Common::MY_SPLIT_TEST_KEY, $User, $Environment); if ($variant === \UserSplit\Tests\Common::MY_SPLIT_TEST_VARIANT_TEST) { // } else { // } When calling the method \ UserSplit \ SplitTests \ Checker :: getActiveVariant (), the log is automatically logged. It turns out that if there is no additional logic, then it will be impossible to unequally hit the hits, as in the old version.
To disable automatic logging of hits, you need to pass the 4th parameter to false and do not forget to log the hit later:
$variant = $Checker->getActiveVariant(\UserSplit\Tests\Common::MY_SPLIT_TEST_KEY, $User, $Environment, false); // - $Checker->logHit(\UserSplit\Tests\Common::MY_SPLIT_TEST_KEY, $variant, $User); This may be necessary, for example, when sending emails. In this case, the user should hit the test only when he has read the letter (as a rule, there are ways to verify this).
If there is any additional logic in determining whether the user is in the test version, then you need to create your own class. It looks something like this:
namespace UserSplit\Tests; class MySplitTest { const KEY = 'my_split_test'; const VARIANT_CONTROL = 'control'; const VARIANT_TEST = 'test'; public static function getInstance() { // } public function getActiveVariant(\User $User, $is_log_hit = false) { $Environment = \UserSplit\CheckerEnvironment::byGlobals(); $Checker = \UserSplit\SplitTests\Checker::getInstance(); $variant = $Checker->getActiveVariant(static::KEY, $User, $Environment, false); // : , if (!$variant) { return $variant; } if (!$this->checkSomeAdditinalCondition($User)) { return false; } if ($is_log_hit) { // : , $Checker->logHit(static::KEY, $variant, $User); } return $variant; } } Here you need to pay attention to the important points that are described in the comments. Given that it is easy to make a mistake here, you need to use this approach only in exceptional cases. There are two of them:
- there is some difficult condition (for example, an additional request to the database), therefore, it would not be desirable to add it to the possible test conditions, but it is better to check it last;
- There is some unique condition that is unlikely to be needed in other tests.
Client tests
Tests that do not need any additional server logic can be performed completely on the client (mobile application or JS in the browser). For example, the color of the button can be tested completely on the client, especially since we now draw templates in JS, and not on the server. For this, the implementation of the mobile API and the interaction with JS were refined (in fact, now the same API is used there). It worked as follows: the client sent a list of supported tests (in the form of numbers - ID tests in the string format), and the server responded by sending a list of tests with active variants (in the same form). Since for new tests, we began to use test keys and option names, and it was easy to distinguish a number from a line, then for new tests we simply began to operate on them.
There are also tests of mixed type (I call them client-server), where both on the server and on the client you need to know which option is active. In this case, besides getting into the test, you need to check whether the client supports this test.
There was a problem with the fact that we can’t just add a check for additional conditions in client and client-server tests. Such a check can be automated by making such an interface:
namespace UserSplit; interface AdditionalConditions { /** * @param \User $User * @param \UserSplit\CheckerEnvironment $Environment * @return boolean */ public static function checkAdditionalConditions(\User $User, \UserSplit\CheckerEnvironment $Environment); } After checking the conditions, we do an additional check: if the test has a PHP class (a class that is in the \ UserSplit \ Tests namespace and has the same name as the test key, but in CamelCase) and it implements this interface, then we call checkAdditionalConditions () method. If the result is false, then the user did not get into the test. We have not had time to implement this idea yet, but we are going to.
User groups
In the billing team, the “user groups” tool was developed. It was originally made to manage the availability of features for users.
It was used as follows: for example, we have seasonal presents for Christmas, but it makes no sense to display them in Muslim countries, because there it is not celebrated. In this case, we can create a user group in which the list of countries where Christmas is celebrated will be registered, and check the user for entry into it before displaying Christmas gifts. Accordingly, this user group can be changed (for example, add countries) via the web interface without attracting a developer. It would be wrong to use split tests in this case, since we do not need to compare options, we only need to enable the feature for a certain circle of users.
But, in addition to the direct appointment, this tool was used for split testing. For example, tests as an entity were absent there and were created in the form of several user groups representing options.
In general, split-testing tools and user groups are quite similar, and keeping two similar tools is not very good. Therefore, we decided to make user groups based on UserSplit, and to transfer user billing commands to UserSplit.
The interface (both software and web) looks almost the same as the split test interface, but it is simplified due to the lack of options. This is how the program interface looks like:
$Environment = \UserSplit\CheckerEnvironment::byGlobals(); // environment-, . $Checker = \UserSplit\UserGroups\Checker::getInstance(); // DI , , , .. $is_in_group = $Checker->isInGroup(\UserSplit\Groups\Common::MY_USER_GROUP_KEY, $User, $Environment); if ($is_in_group) { // , } UserSplit Iterator
Sometimes it becomes necessary to go through all users that meet some conditions in order to perform an action. For split tests and user groups a UserSplit Iterator has been made. It allows you to create the correct SQL query in the database, including all the conditions of the test or group of users, and get only those users who fall into the test or user group.
Plans
In addition to the already voiced problems and plans, we have a couple more ideas:
- testing tokens;
- preliminary schedules.
Testing tokens
In one of the tests conducted tokens (texts), where we renamed one of the paid features, we got a good profit increase. But such changes require a lot of developer resources. Since we have our own translation system of tokens, we decided to embed split testing in it, in order to attract a developer for this there was no need. Now this feature is under development by the back office team.
Preliminary schedules
On the test page, it is planned to display a graph of how many users fall into which option, so that you can see if there is traffic on the test and how even it is between the options.
Result
The result was a fairly powerful tool that can still be developed. It has been successfully used for six months. About 40 tests have been conducted so far and about 30 have been launched. On average, the check for user hit in tests is about 0.5 ms.
If you have questions on this topic - feel free to ask them in the comments.
And thanks to everyone who participated in the development of UserSplit!
Rinat Ahmadeev, PHP developer.
Source: https://habr.com/ru/post/278089/
All Articles