Segmentation Fault (computer memory allocation)

When I make a mistake in the code, it usually results in the message “segmentation fault”, often shortened to “segfault”. And then my colleagues and management come to me: “Ha! We have a segfault for you to fix! ”-“ Well, yes, it’s my fault, ”I usually reply. But how many of you know what the segmentation fault actually means?
To answer this question, we need to go back to the distant 1960s. I want to explain how a computer works, or more precisely, how memory is accessed in modern computers. This will help you understand where this strange error message comes from.
')
All the information below is the basics of computer architecture. And without need, I will not go deep into this area. Also, I will apply the well-known terminology to everyone, so that my post will be clear to everyone who is not entirely on “you” with computer technology. If you want to study the issue of working with memory in more detail, you can refer to the numerous available literature. And at the same time do not forget to delve into the source code of the kernel of some OS, for example, Linux. I will not present here the history of computing technology, some things will not be covered, and some are greatly simplified.
A bit of history
Once computers were very large, weighed tons, while having one processor and memory of about 16 KB. Such a monster cost about $ 150,000 and could perform only one task at a time: only one process was performed at a time. The architecture of memory in those days can be schematically represented as follows:

That is, the OS accounted for, say, a quarter of all available memory, and the rest of the volume was given to user tasks. At that time, the role of the OS was to simply control the hardware using interrupts of the CPU. So OSes needed memory for themselves, for copying data from devices and for working with them ( PIO mode ). To display data on the screen, it was necessary to use part of the main memory, because the video subsystem either did not have its own RAM, or it had read kilobytes. And the program itself was executed in the area of memory that goes right after the OS, and solved its tasks.
Sharing resources
The main problem was that the device, worth $ 150,000, was single-tasking and spent whole days processing several kilobytes of data.
Due to the exorbitant cost, few could afford to purchase several computers at once to process several tasks at the same time. Therefore, people began to look for ways to share access to computing resources of a single computer. This is the era of multitasking. Please note that in those days no one even thought about multiprocessor computers. So how can you make a computer with one CPU do several different tasks?
The solution was to use the task scheduler (scheduling): while one process was interrupted, waiting for the completion of I / O operations, the CPU could execute another process. I’m not going to touch the task scheduler here anymore, this is too broad a topic, unrelated to memory.
If the computer is able to perform several tasks in turn, then the memory allocation will look like this:
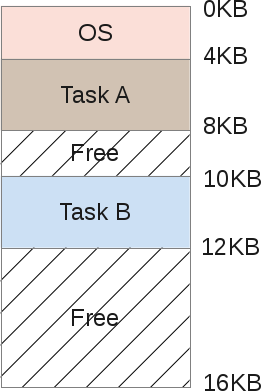
Tasks A and B are stored in memory, since copying them to disk and back is too expensive. And as the processor performs a particular task, it accesses the memory for the appropriate data. But there is a problem.
When one programmer writes code to perform task B, he must know the boundaries of the allocated memory segments. Suppose task B occupies a segment from 10 to 12 Kb in memory, then each memory address must be hard-coded within these limits. But if the computer performs three tasks at once, the memory will be divided into more segments, and therefore the segment for task B may be shifted. Then the program code will have to be rewritten so that it can operate with a smaller memory size, and also change all pointers.
Here another problem emerges: what if task B addresses the memory segment allocated for task A? This can easily happen, because when working with memory pointers it is enough to make a small mistake, and the program will access a completely different address, violating the integrity of the data of another process. At the same time, task A can work with very important data from the point of view of security. There is no way to prevent B from invading memory A. Finally, due to a programmer’s error, task B can overwrite the OS memory (in this case, from 0 to 4 KB).
Address space
To be able to safely perform several tasks stored in memory, we need help from the OS and hardware. In particular, the address space. This is a kind of memory abstraction allocated by the OS for some process. Today it is a fundamental concept that is used everywhere. At least, in ALL civilian computers, this approach is adopted, and the military can have its own secrets. Personal computers, smartphones, TVs, game consoles, smart watches, ATMs - poke into any device, and it turns out that the memory allocation in it is carried out according to the code-stack-heap (code-stack-heap) principle.
The address space contains everything you need to perform the process:
- Machine instructions to be executed by the CPU.
- The data with which these machine instructions will work.
Schematically, the address space is divided as follows:
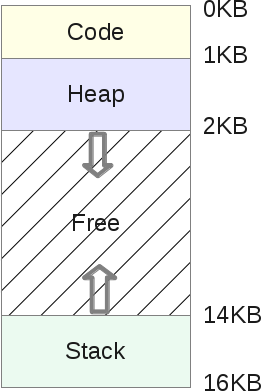
- A stack is a memory area in which a program stores information about called functions, their arguments, and each local variable in functions. The size of the area may vary as the program runs. When calling functions, the stack grows, and when completed, it decreases.
- A heap is a memory area in which a program can do whatever it wants. The size of the area may vary. The programmer has the opportunity to use part of the heap memory with the help of the
malloc()function, and then this memory area is increased. Returning resources is done usingfree(), after which the heap is reduced. - The code segment (code) is the area of memory in which the machine instructions of the compiled program are stored. They are generated by the compiler, but can also be written manually. Please note that this memory area can also be divided into three parts (text, data and BSS). This memory area has a fixed size determined by the compiler. In our example, let it be 1 KB.
Since the stack and the heap can vary in size, they are placed in opposite parts of the common address space. The directions for changing their sizes are shown by arrows. The OS’s responsibility is to ensure that these areas do not overlap each other.
Memory virtualization
Suppose task A has at its disposal all the available user memory. And then there is a problem B. How to be? The solution was found in virtualization .
Let me remind you of one of the previous illustrations, when A and B are in memory at the same time:
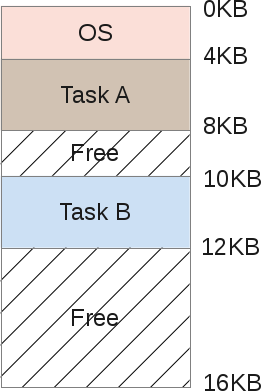
Suppose A is trying to access memory in its own address space, for example, using the index 11 Kb. It may even be her own stack. In this case, the OS needs to figure out how not to load the index 1500, because in fact it can point to the area of task B.
In fact, the address space that each program considers its memory is virtual memory . Fake And in the memory area of task A, the 11 Kb index will be a fake address. That is, the address of virtual memory.
Each program running on a computer works with fake (virtual) memory . With the help of some chips, the OS is deceiving the process when it accesses any area of memory. Thanks to virtualization, no process can access memory that does not belong to it: task A will not fit into the memory of task B or the OS itself. At the same time, at the user level, everything is absolutely transparent, thanks to the extensive and complex code of the OS kernel.
Thus, each memory access is controlled by the operating system. And this should be done very effectively, so as not to slow down the work of various running programs. Efficiency is ensured by hardware, primarily the CPU and some components like the MMU . The latter appeared as a separate chip in the early 1970s, and today MMUs are embedded directly into the processor and are mandatory used by the operating systems.
Here is a small C program that shows how to work with memory addresses:
#include <stdio.h> #include <stdlib.h> int main(int argc, char **argv) { int v = 3; printf("Code is at %p \n", (void *)main); printf("Stack is at %p \n", (void *)&v); printf("Heap is at %p \n", malloc(8)); return 0; } On my LP64 X86_64 machine, it shows the following result:
Code is at 0x40054cStack is at 0x7ffe60a1465cHeap is at 0x1ecf010As I described, the code segment first goes, then the heap, and then the stack. But all these three addresses are fake. The physical memory at 0x7ffe60a1465c does not store an integer variable with a value of 3. Never forget that all user programs manipulate virtual addresses, and only at the kernel level or hardware drivers are allowed to use physical memory addresses.
Call forwarding
Redirection (translation, translation, address translation) is the term for the process of matching a virtual address to a physical one. The MMU module does this. For each executing process, the OS should keep in mind that all virtual addresses match the physical ones. And this is quite an easy task. In fact, the OS has to manage the memory of each user process with each call. Thus, it transforms the nightmarish reality of physical memory into a useful, powerful and easy-to-use abstraction.
Let's take a closer look.
When the process starts, the OS reserves a fixed amount of physical memory for it, let it be 16 KB. The starting address of this address space is stored in a special variable
base . And in the bounds variable, the size of the allocated memory is recorded, in our example, 16 KB. These two values are written to each process table - PCB ( Process Control Block ).So this is the virtual address space:
And this is his physical image:

The OS decides to allocate a range of physical addresses from 4 to 20 Kb, that is, the
base value is 4 Kb, and the bounds value is 4 + 16 = 20 Kb. When a process is queued for execution (CPU time is allocated to it), the OS reads the values of both variables from the PCB and copies them to special CPU registers. Then the process starts and tries to access, say, a virtual address of 2 KB (in its heap). To this address, the CPU adds the base value received from the OS. Therefore, the physical address will be 2 + 4 = 6 Kb.Physical address = virtual address + base
If the resulting physical address (6 KB) gets out of the boundaries of the selected area (4-20 KB), this means that the process is trying to access memory that does not belong to it. The CPU then generates an exception and reports the OS, which handles the exception. In this case, the system usually signals a violation to the process: SIGSEGV , Segmentation Fault. This signal by default interrupts the execution of the process (this can be customized).
Memory reallocation
If task A is excluded from the execution queue, then it is even better. This means that the scheduler was asked to perform another task (say, B). While B is running, the OS can reallocate all the physical space of task A. During the execution of the user process, the OS often loses control of the processor. But when the process makes a system call, the processor returns to the control of the OS. Prior to this system call, the OS can do anything with memory, including completely redistributing the address space of the process to another physical partition.
In our example, this is quite simple: the OS moves the 16-kilobyte area to another free space of a suitable size and simply updates the values of the base and bounds variables for task A. When the processor returns to its execution, the redirection process still works, but the physical address space is already has changed.
From the point of view of task A, nothing changes, its own address space is still located in the range of 0–16 Kb. At the same time, the OS and the MMU fully control every access to the memory task. That is, the programmer manipulates the virtual area of 0-16 KB, and the MMU takes on the mapping to the physical addresses.
After redistribution, the memory image will look like this:
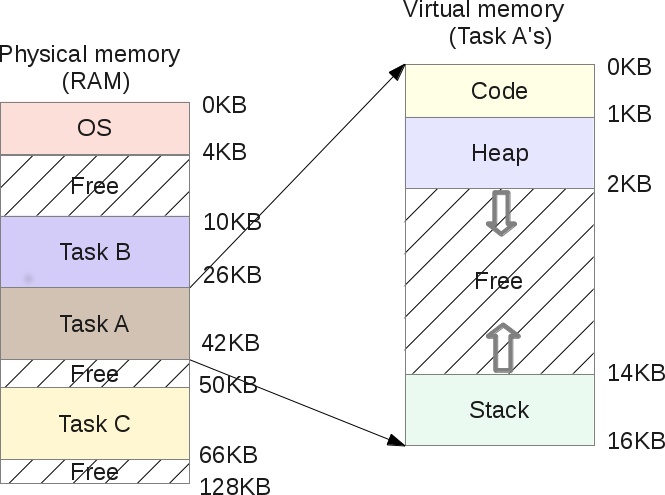
The programmer no longer needs to worry about which memory addresses his program will work with, no need to worry about conflicts. OS in conjunction with the MMU relieve him of all these concerns.
Memory segmentation
In previous chapters, we addressed the issues of redirection and memory redistribution. However, our memory model has several drawbacks:
- We assume that each virtual address space has a size of 16 KB. It has nothing to do with reality.
- The OS has to maintain a list of 16 KB of free ranges of physical memory in order to allocate them for new processes to be launched or to redistribute the currently selected areas. How can you effectively do all this without degrading the performance of the entire system?
- We allocate 16 Kb each process, but it’s not a fact that each of them will use the entire selected area. So we just lose a lot of memory from scratch. This is called internal fragmentation — memory is reserved but not used.
To solve some of these problems, let's consider a more complex memory organization system - segmentation. Its meaning is simple: the “base and bounds” principle extends to all three memory segments - a heap, a code segment and a stack, and for each process, instead of considering the memory image as a single unique entity.
As a result, we no longer lose memory between the stack and the heap:
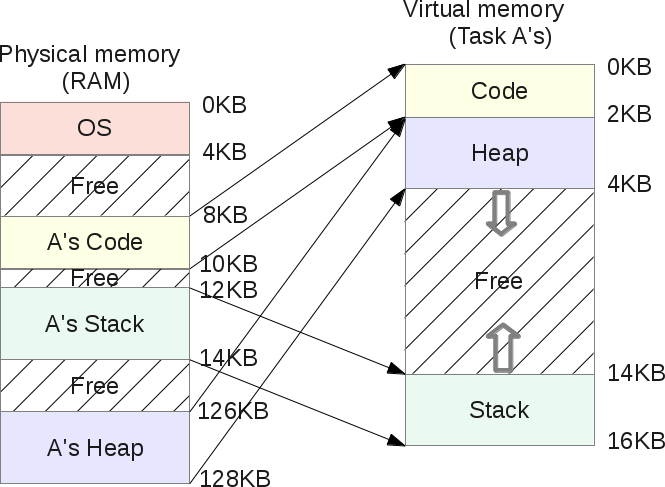
As you can see, the free space in the virtual memory of task A is no longer located in physical memory. And memory is now used much more efficiently. The OS now has to memorize three
base and bounds pairs for each task, one for each segment. MMU, as before, is engaged in redirection, but it already operates with three base
base
and three bounds .Suppose that for task heap A, the
base parameter is 126 Kb, and bounds is 2 Kb. Let task A refer to a virtual address of 3 Kb (in a heap). Then the physical address is defined as 3 - 2 Kb (beginning of the heap) = 1 Kb + 126 Kb (shift) = 127 Kb. This is less than 128, which means there will be no handling error.Segment sharing
Segmentation of physical memory not only does not allow virtual memory to eat off physical memory, but also makes it possible to share physical segments using virtual address spaces of different processes.
If you run task A twice, they will have the same code segment: the same machine instructions are executed in both tasks. At the same time, each task will have its own stack and heap, since they operate on different data sets.
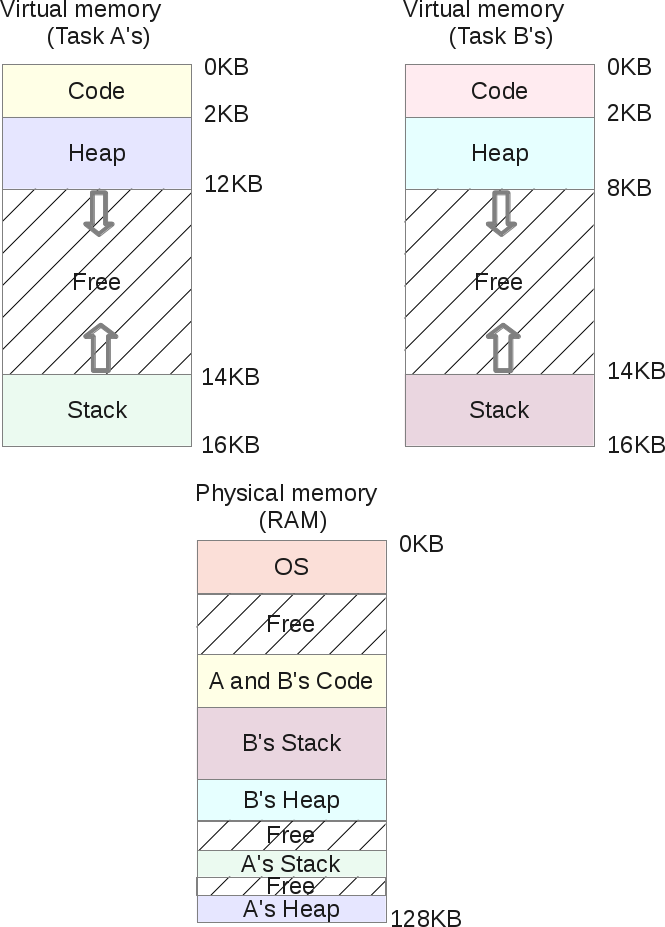
At the same time, both processes do not suspect that they share their memory with someone. This approach was made possible by the introduction of segment protection bits (segment protection bits).
For each physical segment of the OS being created, it registers the
bounds value, which is used by the MMU for subsequent redirection. But at the same time, the so-called permission flag is also registered.Since the code itself cannot be modified, all code segments are created with RX flags. This means that the process can load this area of memory for later execution, but no one can write to it. The other two segments, heap and stack, have RW flags, that is, the process can read and write to these two of its segments, but the code cannot be executed from them. This is done to ensure security, so that an attacker could not damage the heap or stack by incorporating his code into them to gain root rights. This was not always the case, and hardware support is required for the high efficiency of this solution. In Intel processors, this is called “ NX bit ”.
Flags can be changed during the program execution, for this purpose mprotect () is used .
Under Linux, all these memory segments can be viewed using the / proc / {pid} / maps or / usr / bin / pmap utilities .
Here is an example in PHP:
$ pmap -x 31329 0000000000400000 10300 2004 0 rx-- php 000000000100e000 832 460 76 rw--- php 00000000010de000 148 72 72 rw--- [ anon ] 000000000197a000 2784 2696 2696 rw--- [ anon ] 00007ff772bc4000 12 12 0 rx-- libuuid.so.0.0.0 00007ff772bc7000 1020 0 0 ----- libuuid.so.0.0.0 00007ff772cc6000 4 4 4 rw--- libuuid.so.0.0.0 ... ... It has all the necessary details regarding the memory allocation. Virtual addresses, permissions for each memory area are displayed. Each shared object (.so) is located in the address space in the form of several parts (usually code and data). Code segments are executable and are shared in physical memory by all processes that have placed a similar shared object in their address space.
Shared Objects is one of the biggest advantages of Unix and Linux systems, providing memory savings.
Also, using the mmap () system call, you can create a shared area that is converted to a shared physical segment. Then each region will have an index s, meaning shared.
Segmentation constraints
So, the segmentation solved the problem of unused virtual memory. If it is not used, it is not placed in physical memory due to the use of segments that correspond to the amount of memory used.
But this is not entirely true.
Let's say the process requested 16 kb from the heap. Most likely, the OS will create a segment of the appropriate size in physical memory. If the user then releases 2 KB from them, then the OS will have to reduce the size of the segment to 14 KB. But what if the programmer then asks for another 30 KB from the heap? Then the previous segment should be increased more than twice, and is it possible to do this? Perhaps, it is already surrounded by other segments that do not allow it to increase. Then the OS will have to look for 30 KB of free space and redistribute the segment.

The main drawback of the segments is that because of them the physical memory is very fragmented, as the segments grow and shrink as user processes request and free memory. And the OS has to maintain a list of free sites and manage them.
Fragmentation can lead to the fact that some process will request a memory size that will be larger than any of the free sections. And in this case, the OS will have to refuse the process of allocating memory, even if the total amount of free areas will be significantly larger.
The OS may try to place the data more compactly, combining all the free areas into one big chunk, which can later be used for the needs of new processes and redistribution.
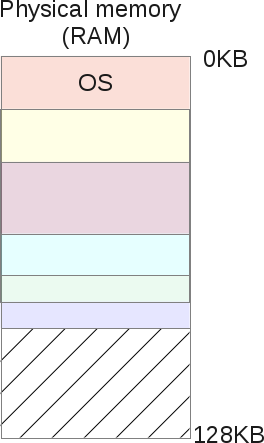
But such optimization algorithms heavily load the processor, and yet its power is needed to perform user processes. If the OS begins to reorganize the physical memory, the system becomes inaccessible.
So the segmentation of memory entails a lot of problems associated with memory management and multitasking. It is necessary to somehow improve the segmentation capabilities and correct the deficiencies. This is achieved through another approach - virtual memory pages.
Memory pagination
As mentioned above, the main disadvantage of segmentation is that the segments very often change their size, and this leads to memory fragmentation, which may cause a situation when the OS does not allocate the necessary memory for processes. This problem is solved with the help of pages: each location that the kernel makes in physical memory has a fixed size. That is, pages are areas of physical memory of a fixed size, nothing more. This greatly simplifies the task of managing free volume and eliminates fragmentation.
Let's look at an example: a 16 KB virtual address space is paginated.
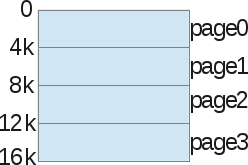
We are not talking about a heap, stack, or code segment. Just divide the memory into pieces of 4 KB. Then we do the same with physical memory:
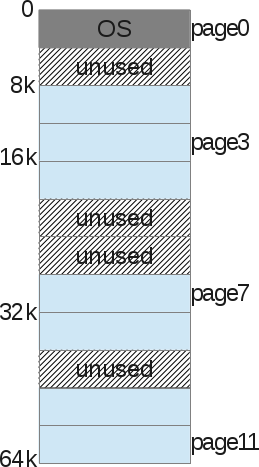
The OS stores the process page table (process page table), which presents the relationship between the process virtual memory page and the physical memory page (page frame).

Now we have got rid of the problem of searching for free space: the page frame is either used or not (unused). Unlike the kernel, it is easier to find a sufficient number of pages to fulfill the process request for memory allocation.
A page is the smallest and indivisible unit of memory that the OS can operate on.
Each process has its own page table, in which redirection is presented. Here not the values of the borders of the region are used, but the number of the virtual page (VPN, virtual page number) and shift (offset).
Example: the size of the virtual space is 16 KB, therefore, we need 14 bits to describe the addresses (2 14 = 16 KB). The page size is 4 Kb, which means we need 4 Kb (16/4) to select the desired page:

When a process wants to use, for example, the address 9438 (outside the boundaries of 16,384), it requests in binary code 10.0100.1101.1110:

This is the 1246th byte in the virtual page number 2 ("0100.1101.1110" -th byte in the "10" -th page). Now the OS simply needs to refer to the process page table to find this page number 2. In our example, it corresponds to an eight-thousandth byte of physical memory. Therefore, the virtual address 9438 corresponds to the physical address 9442 (8000 + offset 1246).
As already mentioned, each process has only one page table, since each process has its own redirection, as in the case of segments. But where exactly are all these tables stored? Probably, in physical memory, where else can it be?
If the page tables themselves are stored in memory, then you need to access memory in order to receive a VPN. Then the number of calls to it is doubled: first, we retrieve the number of the desired page from memory, and then we turn to the data itself stored in this page. And if the speed of access to memory is small, then the situation looks pretty sad.
Fast forwarding buffer (TLB, Translation-lookaside Buffer)
Using pages as the primary tool for maintaining virtual memory can lead to severe performance degradation. Splitting the address space into small pieces (pages) requires storing a large amount of data on the placement of pages. And since this data is stored in memory, then each time the process accesses the memory, one more, additional access is performed.
Equipment maintenance is used again to maintain performance. As with segmentation, we use hardware methods to help the kernel to efficiently perform redirects. To do this, use the TLB, which is part of the MMU, and is a simple cache for some VPN redirects. TLB , .
MMU , VPN TLB, VPN. , . , MMU , , TLB, .
, , . , , , TLB . . - . . , Linux «» 2 4 .
, . , TLB , . (spacial locality efficiency): , , , TLB .
, TLB ASID (Address Space Identifier, ). PID, . , , ASID, TLB , .
: , TLB. , . , . 86- 4 , . , , (« », dirty bit), (protection bit), (reference bit) .. , SIGSEGV, “segmentation fault”, .
, . , , , (page eviction), «» ( , ).
Conclusion
, “segmentation fault”. . , MMU . , — , ( read only-), — SIGSEGV, “segmentation fault”. - “General protection fault”. Linux 86/64-, , — SIGSEGV . , . , , .
Source: https://habr.com/ru/post/277759/
All Articles