What we should build LVM (principle of operation, performance, Thin Provision)
Despite the presence of several articles on Habré, about LVM2 and the performance of Thin Provisioning, I decided to conduct my research, since the available ones seemed to me superficial.
Who cares, welcome under cat.
Actually, LVM is a disk space management system. Allows you to logically combine several disk spaces (physical volumes) into one, and already from this space (Disk Group or volume group), you can select the partitions (Logical Volumes) that are available for work. The OS accesses them through DevMapper.
Logical volumes can be freely placed in a disk group, occupying continuous or discontinuous address ranges, or located partially on different disk groups. Logical volumes can be easily resized (but not everyone can do FS) or move between group disks, as well as create snapshots of the state of a logical volume (snapshot). Snapshots are the main interest in the article.
')
The idea here is simple, everything revolves around the tables of logical and physical addresses.
The general scheme is as follows: Physical volumes are reflected on the Disk group. The disk group is reflected on logical volumes.
Snapshots are a little different: the own table associates the blocks of the original volume and the snapshot blocks (a copy of the blocks of the original, before they are modified). It works on the principle of copying when recording (CoW, a copy of the block of the original volume is made, then this block is recorded in the original volume). It is impossible to create snapshot from snapshot.
Thin volumes work a little differently. A special volume is created in the volume group (a pool of thin volumes, actually consists of two, for data and metadata), from this pool there is a selection of virtual space for thin volumes. The space is virtual, because until the actual recording, the blocks are not allocated from the pool. And in general, you can set the virtual size of the volume, more than the pool. When the volume swells to the limit, the system will freeze the entry to it, until the pool size increases. Snapshots here are similar to their “fat” brothers, but they no longer operate with blocks, but with links to blocks. That is, after creating the snapshot, writing to the original happens the same way as before creating the snapshot (rewritable blocks are allocated from the pool). It is possible to create snapshots from snapshots, and you can also specify the external volume of the original (placed outside the thin pool in the same volume group, write-protected).
The performance of thick volumes without snapshots is equal to regular disk partitions (the difference is very small), but what about snapshots?
Tests showed hell and horror. Due to CoW, write operations to the original volume are slowed down dramatically! And the more snapshots, the worse.
The situation can be somewhat corrected by setting a larger fragment (by default, this is 4 kilobytes, which gives a large amount of small iops). The situation is incomparably better if you write not in the original volume, but in the snapshot.
Thin volumes show a more balanced picture. The speed of work depends little on the number of snapshots, and the speed is much lower than for a simple thick volume without snapshots and close to the speed of writing to a thick snapshot. The main contribution to the brakes makes the allocation of space (fragment size of 4 kilobytes).
Results:
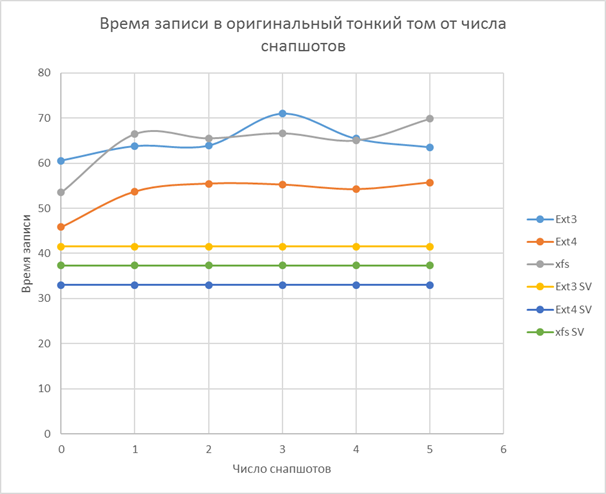
Fastest FS (in write mode): ext4, then xfs, at the end ext3
A partition or a logical volume (thick and thin) with a size of 50Gb was created. The resulting space was formatted in ext3, ext4 and xfs. After all the buffers were cleared and the tgz archive was unpacked (placed in tmpfs in memory) with Centos 7.3 Core image (Asterisk and FreePBX deployed) 2Gb in unpacked form. At the end I cleaned the buffers again. Time is measured from the beginning of unpacking to the final cleaning of the buffer.
For LVM, a snapshot was created, and then a directory was created in the original volume where the archive was unpacked. The procedure was repeated five times (without deleting snapshots or copies of files from the original volume).
Then, once unpacked the archive in each snapshot.
Participated in testing:
I will evaluate reliability simply by the level of complexity of the mechanism for accessing information. The harder it is, the lower its reliability (this has a rather distant relation to real reliability).
The most reliable, of course, looks like a regular section. Space is linear, no intermediate abstractions. There’s nothing to break. From cool buns there is nothing.
The second place will be taken by Fat Tom. Appearing abstractions certainly do not make it more reliable, but add a lot of flexibility. Recovering data from scattered LVM is not so easy, but most likely, most volumes will be placed linearly, with little fragmentation (and these fragments will probably be large, it is unlikely that you will expand the partitions with small blocks).
The most unreliable look Thin Tom. A complex mechanism for allocating space, initially fragmented space (but not the data itself, they are just placed compactly and even linearly). Damage to the address translation table will make the data extremely difficult to read. By the way, the reliability of btrfs, zfs or ntfs at a worse level. For thin volumes, only the distribution of space is in danger, and for the FS, there are also plenty of abstractions.
Thin Provisioning support appeared in RedHat Enterprise Linux 6.x, and in the 7th branch it became the default mode for LVM, even at the installation stage, which may indirectly indicate the reliability of the solution, and simple LVM2 has been working for a very long time, and there are no serious problems causes.
Having on hand a performance assessment, you can decide on the use of a particular technology for different scenarios.
For example, thick volumes will work well for virtualizing mass masses of the same type, without the need for backup on the fly (one master image, and a bunch of snapshots for target virtual machines, you can't take snapshots from snapshots). Space consumption will be acceptable, and performance and flexibility will be on top. In such a scenario, it is rarely necessary to write to the image of the original.
And thin volumes will adequately show themselves in the script above (they will simply be much slower), and in others, and will make it possible to create snapshots from snapshots, etc. In addition, thin volumes may be close to thick, after allocating space for recording or increasing the size of a fragment.
Who cares, welcome under cat.
Little about LVM2
Actually, LVM is a disk space management system. Allows you to logically combine several disk spaces (physical volumes) into one, and already from this space (Disk Group or volume group), you can select the partitions (Logical Volumes) that are available for work. The OS accesses them through DevMapper.
Logical volumes can be freely placed in a disk group, occupying continuous or discontinuous address ranges, or located partially on different disk groups. Logical volumes can be easily resized (but not everyone can do FS) or move between group disks, as well as create snapshots of the state of a logical volume (snapshot). Snapshots are the main interest in the article.
')
How LVM works
The idea here is simple, everything revolves around the tables of logical and physical addresses.
The general scheme is as follows: Physical volumes are reflected on the Disk group. The disk group is reflected on logical volumes.
Snapshots are a little different: the own table associates the blocks of the original volume and the snapshot blocks (a copy of the blocks of the original, before they are modified). It works on the principle of copying when recording (CoW, a copy of the block of the original volume is made, then this block is recorded in the original volume). It is impossible to create snapshot from snapshot.
Thin volumes work a little differently. A special volume is created in the volume group (a pool of thin volumes, actually consists of two, for data and metadata), from this pool there is a selection of virtual space for thin volumes. The space is virtual, because until the actual recording, the blocks are not allocated from the pool. And in general, you can set the virtual size of the volume, more than the pool. When the volume swells to the limit, the system will freeze the entry to it, until the pool size increases. Snapshots here are similar to their “fat” brothers, but they no longer operate with blocks, but with links to blocks. That is, after creating the snapshot, writing to the original happens the same way as before creating the snapshot (rewritable blocks are allocated from the pool). It is possible to create snapshots from snapshots, and you can also specify the external volume of the original (placed outside the thin pool in the same volume group, write-protected).
Performance
The performance of thick volumes without snapshots is equal to regular disk partitions (the difference is very small), but what about snapshots?
Tests showed hell and horror. Due to CoW, write operations to the original volume are slowed down dramatically! And the more snapshots, the worse.
The situation can be somewhat corrected by setting a larger fragment (by default, this is 4 kilobytes, which gives a large amount of small iops). The situation is incomparably better if you write not in the original volume, but in the snapshot.
Thin volumes show a more balanced picture. The speed of work depends little on the number of snapshots, and the speed is much lower than for a simple thick volume without snapshots and close to the speed of writing to a thick snapshot. The main contribution to the brakes makes the allocation of space (fragment size of 4 kilobytes).
Results:
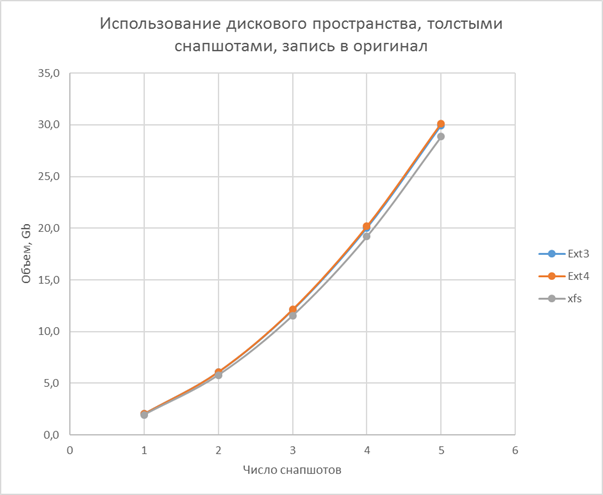
- Simple section ahead in speed, but not efficient in space
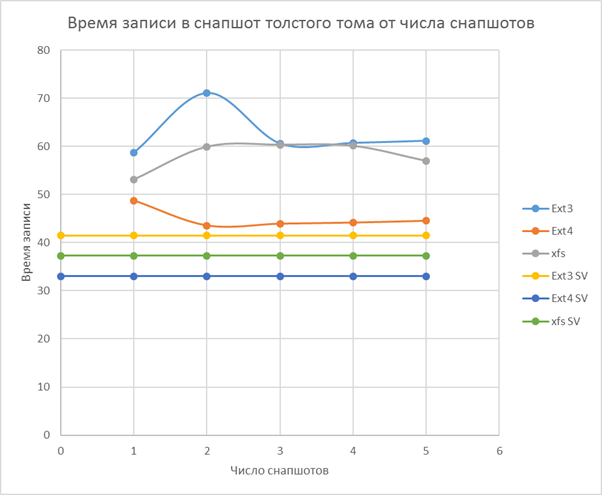
- A thick volume is fast, as long as there are no snapshots, it has an average efficiency over space.
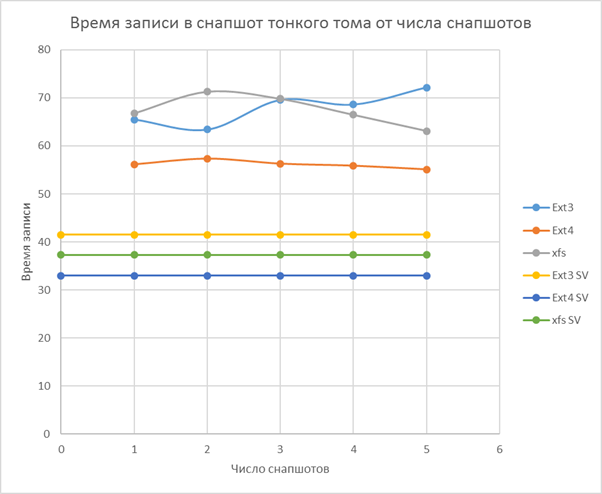
- Thin volume is the slowest, but its speed is weakly dependent on snapshots, the greatest efficiency in space
Fastest FS (in write mode): ext4, then xfs, at the end ext3
Charts and calculation

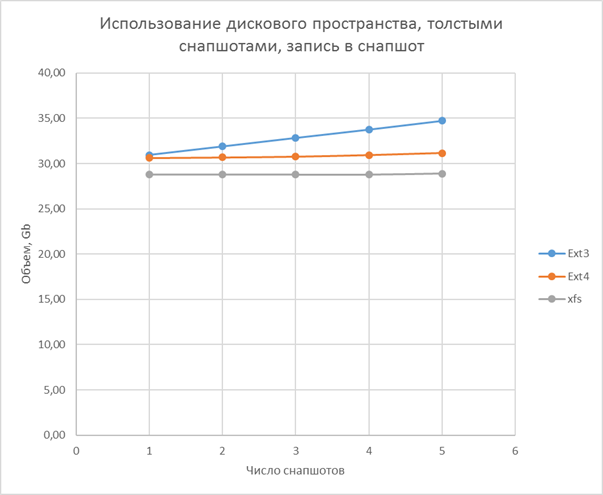
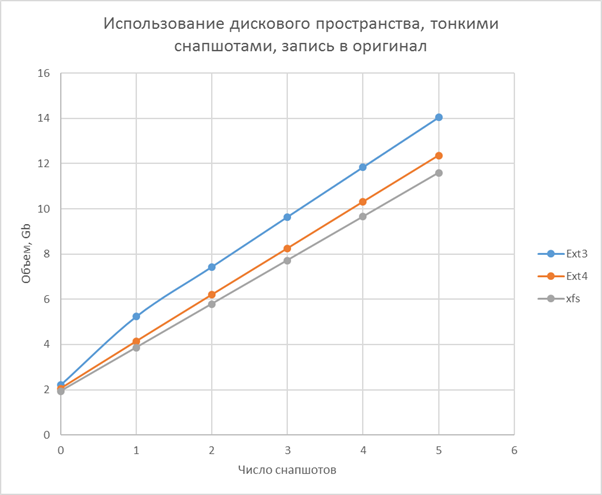
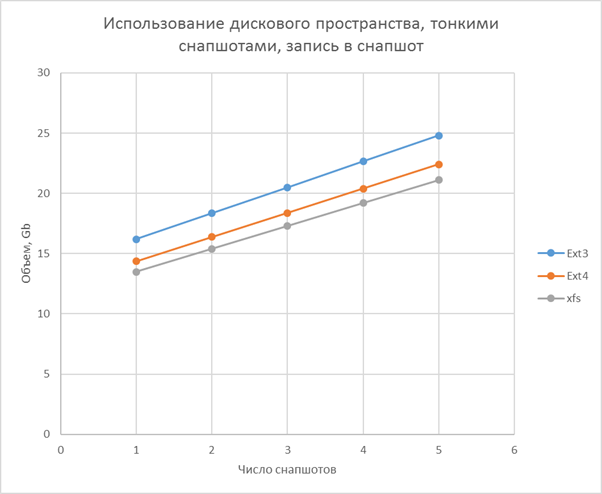
Testing method
A partition or a logical volume (thick and thin) with a size of 50Gb was created. The resulting space was formatted in ext3, ext4 and xfs. After all the buffers were cleared and the tgz archive was unpacked (placed in tmpfs in memory) with Centos 7.3 Core image (Asterisk and FreePBX deployed) 2Gb in unpacked form. At the end I cleaned the buffers again. Time is measured from the beginning of unpacking to the final cleaning of the buffer.
For LVM, a snapshot was created, and then a directory was created in the original volume where the archive was unpacked. The procedure was repeated five times (without deleting snapshots or copies of files from the original volume).
Then, once unpacked the archive in each snapshot.
Participated in testing:
- Gigabyte Z77X-D3H
- WDC WD7500AAKS-00RBA0
- Intel® Core (TM) i5-3570
- RAM 16Gb
Reliability
I will evaluate reliability simply by the level of complexity of the mechanism for accessing information. The harder it is, the lower its reliability (this has a rather distant relation to real reliability).
The most reliable, of course, looks like a regular section. Space is linear, no intermediate abstractions. There’s nothing to break. From cool buns there is nothing.
The second place will be taken by Fat Tom. Appearing abstractions certainly do not make it more reliable, but add a lot of flexibility. Recovering data from scattered LVM is not so easy, but most likely, most volumes will be placed linearly, with little fragmentation (and these fragments will probably be large, it is unlikely that you will expand the partitions with small blocks).
The most unreliable look Thin Tom. A complex mechanism for allocating space, initially fragmented space (but not the data itself, they are just placed compactly and even linearly). Damage to the address translation table will make the data extremely difficult to read. By the way, the reliability of btrfs, zfs or ntfs at a worse level. For thin volumes, only the distribution of space is in danger, and for the FS, there are also plenty of abstractions.
Production application
Thin Provisioning support appeared in RedHat Enterprise Linux 6.x, and in the 7th branch it became the default mode for LVM, even at the installation stage, which may indirectly indicate the reliability of the solution, and simple LVM2 has been working for a very long time, and there are no serious problems causes.
Having on hand a performance assessment, you can decide on the use of a particular technology for different scenarios.
For example, thick volumes will work well for virtualizing mass masses of the same type, without the need for backup on the fly (one master image, and a bunch of snapshots for target virtual machines, you can't take snapshots from snapshots). Space consumption will be acceptable, and performance and flexibility will be on top. In such a scenario, it is rarely necessary to write to the image of the original.
And thin volumes will adequately show themselves in the script above (they will simply be much slower), and in others, and will make it possible to create snapshots from snapshots, etc. In addition, thin volumes may be close to thick, after allocating space for recording or increasing the size of a fragment.
Source: https://habr.com/ru/post/277663/
All Articles