How Relap.io is organized - a service that issues 30 billion recommendations per month
We have not written anything for a long time in our blog and come back with a story about our new project: Relap.io (relevant pages).
We launched the Relap.io B2B B2B service a year and a half ago. It makes life easier for editors and media readers. On weekdays, Relap.io serves 15 million unique users and issues 30 billion recommendations per month.
Now Relap.io is the largest recommendation platform in Europe and Asia.
')
Why do you need Relap.io
Depending on the user's behavior, we select articles that will be of interest to him. It looks like the “Read also” block or “It will be interesting for you”:
Now RIA Novosti , AdMe , COUB , TJournal , Layfhaker and other media use the service. Relap.io widgets are installed on more than 1000 sites. 50 of them are millionaires (1 million or more unique visitors per day).
Relap.io started with a simple beta. We took Surfingbird recommender algorithms and adapted them for third-party sites.
What is Relap.io made of
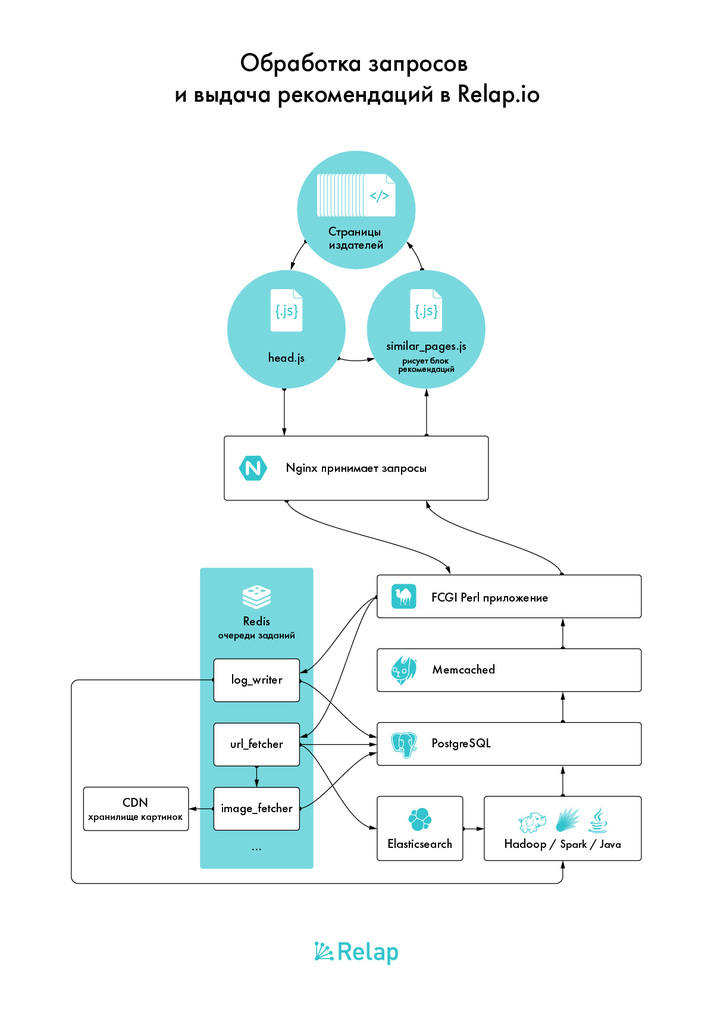
Every second, 15,000 http requests are sent to the Relap.io servers from users. Of them:
- 10K static: images for widgets, styles, static js.
- 5K dynamics: the collection of signals that form the training set and the formation of blocks of recommendations.
When we created the architecture, we had 2 requirements:
- it must withstand high loads;
- to scale.
Backends are two servers with a large amount of memory and bulk SSDs in RAID1. They are PostgreSQL fresh version, on one server - the master, on the second - the slave.
Workhorses - server more modest. They accept requests from the outside world. Two of them are Nginx-s, which are balanced with each other just by DNS. They scatter requests. They are caught by pearl barley FCGI workers.
The FCGI application is designed in such a way that the failure of PostgreSQL does not lead to an instantaneous failure of the entire service, we have about 10 minutes to fix fatal problems. Even if the automatic switch to the replica did not save the situation.
The same servers also perform other roles - most of the queues running on them that execute offline everything that can be done offline; memcached and redis instances, cron scripts.
Stand alone are the servers that form recommendations. For all but the team of mathematicians, this is more or less a black box. There, the FCGI and the queues throw data, and in response they insert into PostgreSQL fresh recommendations, calculated using different algorithms, for each active link in the database. Keywords - Hadoop, Spark, Elasticsearch as a stack, a thick layer of Java.
It only remains for the code to pick up the finished one, apply some filtering. We try to make it minimal and filter it at the generation and sorting stage.
All that can be hung with caches. PostgreSQL cache in memory, disk cache, memory card or redis, where it is more convenient, several types of caching right inside the process.
Why is that so?
PostgreSQL is the most comprehensive open-source database. Predictable, stable, popular. Nginx - much better withstand load scaling than Apache.
MySQL or Apache is more popular, but it seems to us that you can choose them for new projects only on shared hosting, where there is nothing else. Or if you know how to prepare and scale them very well.
You can choose shared hosting for a new project only if you know in advance that growth does not threaten it. Then the technology should be chosen according to the principle “and with what knowledge I will find the cheapest and fastest people” - most likely, people with knowledge of PHP, MySQL and Apache. A closed world of projects on shared-hosting.
Hadoop was taken because the team had no particular experience with any of these solutions. And this is a standard in the processing of big data. Here we just followed everyone.
We also needed a separate data storage for Hadoop, but PostgreSQL didn't work. For this we have chosen, oddly enough, Elasticsearch, at the same time having received full-text search and the ability to build algorithms using it. However, this was the wrong decision. It can quickly index everything and find, but not give away large amounts of data.
In the next series we will tell how we solved this problem.
Where is Relap.io hosted
With the growth of the load, we faced the problem of choosing a reliable hosting provider. Now we are hosted on Servers.com. They are powerful enough to withstand a load of 900,000 requests per minute. This is not a peak load, but a normal state on weekdays.
Last year we changed data center several times. First was DC Slavic. Surfingbird.ru is still hosted there.
Then in March 2015 moved to Hetzner. Then we issued 2K recommendations per second. The last move to Servers.com was 6K per second. Now 15K.
Relap.io integration to the site:
As widget
Boxed solution. The user puts our code in the head of the page on which the widget should be. Selects the type of widget and collects the design in the built-in constructor. The formation of recommendations and the frontend is completely on our side. So most sites are connected to Relap.io . For example, Layfhaker.
Via jsonp api
The site receives a description of our api. We give a large package of recommendations, and the site filters them already on its side and inserts them into the design. Integration via JSONP API allows you to use custom elements: a historical number of views, likes, and any other information about the link. In this way, for example, AdMe or COUB are connected to Relap.io.
In subsequent articles, we will talk in detail about technologies, machine learning algorithms and service infrastructure. Ask questions in the comments - be sure to answer them in the following publications.
Source: https://habr.com/ru/post/277559/
All Articles