Material on working with Apache Lucene and creating a simple fuzzy search
 The post is designed for beginners, for people unfamiliar with Apache Lucene technology. There is no material about how Apache Lucene is built inside, what algorithms, data structures and methods were used to create the framework. The post is a teaser teaching material written to show how to organize the simplest fuzzy search through the text.
The post is designed for beginners, for people unfamiliar with Apache Lucene technology. There is no material about how Apache Lucene is built inside, what algorithms, data structures and methods were used to create the framework. The post is a teaser teaching material written to show how to organize the simplest fuzzy search through the text.The github code, the post itself as documentation and some data for testing search queries are provided as material for training.
Introduction
Details about the Apache Lucene library are written here and here . The article will include such terms as: query, indexing, analyzer, fuzzy matches, tokens, documents. I advise you to read this article first . In it, these terms are described in the context of the Elasticsearch framework, which is based on Apache Lucene libraries. Therefore, the basic terminology and definitions are the same.
Tools
This article describes how to use Apache Lucene 5.4.1. The source code is available on github , in the repository there is a small set of data for testing. In fact, the article is a detailed documentation of the code in the repository. You can start “playing” with a project by running tests in the BasicSearchExamplesTest class.
Creating indexes
You can index documents using the MessageIndexer class. It has an index method:
')
public void index(final Boolean create, List<Document> documents) throws IOException { final Analyzer analyzer = new RussianAnalyzer(); index(create, documents, analyzer); } It accepts the variable create and documents . The create variable is responsible for the behavior of the indexer. If it is true, then the indexer will create a new index even if the index already existed. If false, the index will be updated.
The variable documents is a list of Document objects. Document is an indexing and searching object. It is a set of fields, each field has a name and a text value. In order to get a list of documents created class MessageToDocument . Its task is to create a Document using two string fields: body and title.
public static Document createWith(final String titleStr, final String bodyStr) { final Document document = new Document(); final FieldType textIndexedType = new FieldType(); textIndexedType.setStored(true); textIndexedType.setIndexOptions(IndexOptions.DOCS); textIndexedType.setTokenized(true); //index title Field title = new Field("title", titleStr, textIndexedType); //index body Field body = new Field("body", bodyStr, textIndexedType); document.add(title); document.add(body); return document; } Note that the index method by default uses RussianAnalyzer , available in the lucene-analyzers-common library.
To play with the creation of the index, go to the class MessageIndexerTest .
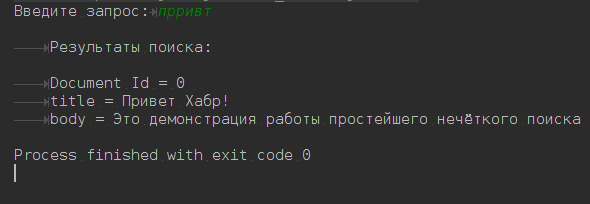
Search
To demonstrate the basic search capabilities, the BasicSearchExamples class has been created . It implements two search methods: simple search by token and fuzzy search. For a simple search, the searchIndexWithTermQuery () and searchInBody () methods are responsible, the fuzzySearch () method is used for fuzzy searching.
In Lucene, there are many ways to create a query, but for simplicity, conventional search methods are implemented only using the QueryParser and TermQuery classes. Fuzzy search methods use FuzzyQuery, which depends on one important parameter: maxEdits . This parameter is responsible for the fuzziness of the search, details here . Roughly speaking, the bigger it is, the more vague the search will be. Immerse yourself in a variety of ways to make a request here .
To play with the search go to the class BasicSearchExamplesTest
The task
To play with the project it was not boring to try to complete several tasks:
- Do an interactive console search. The search should show the issue and ask for the next request.
- Now the search works only with the body field. Make the search work in the title and body fields at the same time.
- Count the number of indexed words (tokens)
- Expand the Message model, add a region (region) and date of the message creation (creationDate) to it. Do not forget to add new fields to be indexed in the MessageToDocument class. Add new search methods with filter by region and date
- Look at the MoreLikeThisQuery query class. Try grouping all documents by similarity using the score value.
- Download this file , it has about 5000 different messages. Check out how grouping, new queries and filters work.
Conclusion
The advantage of Apache Lucene in its simplicity, high speed and low resource requirements. The lack of good documentation, especially in Russian. The project is developing very quickly, so the books, tutorials and Q / A, with which the Internet is clogged, have long lost their relevance. For example, it took me 4-5 days just to figure out how to get the vector model TF-IDF out of Lucene indices. I hope that this post will attract the attention of specialists to this problem of lack of information.
For those who want to dive into the world of Apache Lucene, I advise you to take a look at the Elasticsearch documentation. Many things are very well described there, with links to reputable sources and with examples.
Offtop
This is my first more or less serious post. Therefore, I ask you to express criticism, feedback and suggestions. I could write a few more articles, as I’m now working closely with Apache Lucene.
Source: https://habr.com/ru/post/277509/
All Articles