Xeon Phi: Why do coprocessors use to create trading applications

In our blog on Habré, we write a lot about the development of trading robots and building the infrastructure for online trading. In the previous materials we looked at the topic of using FPGA and GPU , and today, we will talk about creating trading applications using Xeon Phi co-processors.
Modern stock exchanges broadcast information about the situation on the market with the help of special flow handlers (feed handlers), which contain information about stock quotes and orders to buy and sell. With the increase in the number of orders and the number of financial instruments being traded, the performance of trading systems also has to increase dramatically - otherwise trade delays are inevitable, which is often unacceptable.
')
In addition, many exchanges broadcast data in various formats, including multicast broadcast and point-to-point transmission over TCP / IP. The difficulty of working with proprietary financial protocols leads to the fact that in some cases, financial companies and private HFT traders prefer not to develop their own software processors of financial data flows, but to use commercial "iron" solutions to improve the performance of their applications.
There are two approaches to building trading applications. The first can be described as “generic” - in this case, the solution consists of a software application running on some widely used processors like Intel Xeon and standard operating systems like Linux. The second approach involves the creation of a "customized" solution using FPGA or ASIC, which allows the processing of financial data at much higher speeds. The second path is also characterized by increasing development and support costs.
An important aspect of any high-performance solution for working in the financial market is also the amount of delay introduced by the processing software. In the world of HFT, even microsecond delays can make trading unprofitable. The delay of the handlers depends on the number of cores that can be identified for them - usually their number is not particularly large, because the software that performs trading operations is also necessary for hardware resources. The task of reducing the insertion delay helps the use of Xeon Phi co-processors, which allow processing data at speeds comparable to the speed of their receipt.
Packet processing architecture
Intex Xeon Phi coprocessors allow you to create applications with an extremely high level of parallelism. The computing platform consists of the following components:
- A large number of sequential cache cores and threads for processing multiple independent data streams for optimal system performance.
- SIMD support using 512-bit vectors instead of using narrower MMX, SSE or AVX2.
- Supports high-performance instructions for performing square root, exponential, and reciprocal calculations.
- Large amount of available bandwidth for memory.
- High-performance communication tools - to prieru, PCI-bus between the host and the connected co-processors.
As a result, one or more streams on the host machine receive packets — it can be market data — via a socket connection from an external source using a standard network tool (NIC). The host generates a FIFO queue from the packets for further processing. A co-processor side thread running on the core processes each packet received through the FIFO and passes each packet through the thread processing algorithm. The result of his work is then again copied to the FIFO for further processing.
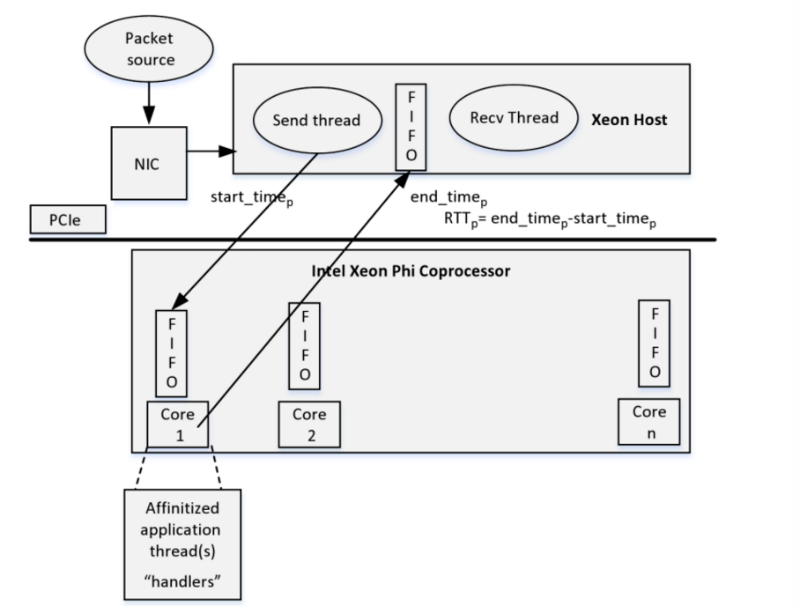
The architecture of a packet processing application using coprocessors
Effective inter-node communication between two adjacent processes is provided by the symmetric communication interface SCIF (Symmetric Communication Interface). As a result, applications transmit data using the SCIF API, which works similarly to the Berkeley Sockets API. SCIF drivers and libraries are symmetrically located on both sides of the PCI bus — the connection setup process is similar to the sockets API, where one side listens and accepts incoming connections, and the other connects to the remote process.
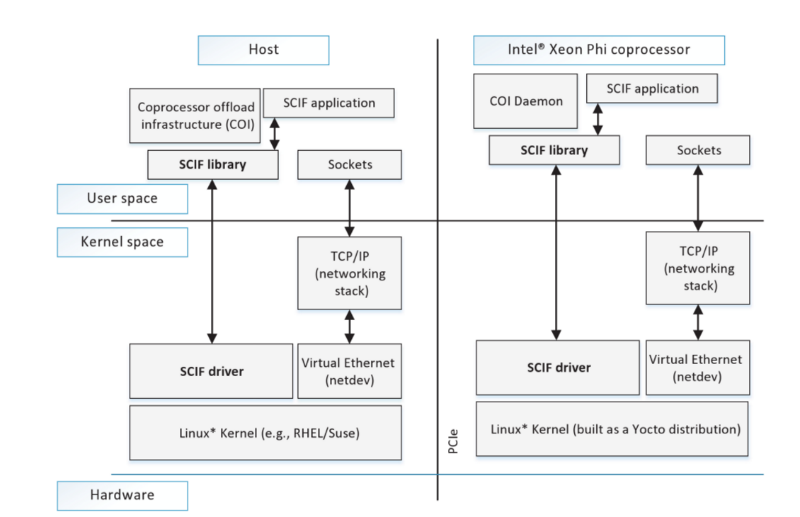
Intel Many-Core Platform Software (MPSS) stack, including SCIF driver and user mode library
For more information on working with memory and optimizing trading applications using Xeon Phi, see the book High Performance Parallelism Pearls Volume Two: Multicore and Many-core .
Next we look at the test implementation of the application on Xeon Phi.
Calculation of interest swaps LIBOR by the Monte Carlo method
The company that develops high-frequency trading solutions Xcelerit on its blog published a description of the implementation of the application for processing interest swaps LIBOR using the Monte Carlo method. We will take advantage of the highlights of this material.
To determine the value of a portfolio of LIBOR swaptions, a Monte Carlo simulation is used. With its help, thousands of possible future variants of the development of indicators of interest LIBOR are simulated - for this purpose, normally distributed random numbers are used. LIBOR uses the mechanism described by Prof. Mike Giles to calculate the rates and returns.
Portfolio sensitivity is calculated using algorithmic differentiation (Adjoint Algorithmic Differentiation, AD). The final values of the swaptions in the portfolio and the Greeks - in Greek letters denote the sensitivity of the option premium to changes in various values.
The implementation uses the SDK from Xcelerit. To obtain normally distributed random samples, a random number generator is required, then a LIBOR rate calculation module, portfolio definitions and Greeks. Then comes the final finding of the portfolio and values of the Greeks.

The table below shows a comparison of two possible implementations of such an application — one using sequential C ++, and the other using the SDK to work with Xeon Phi.
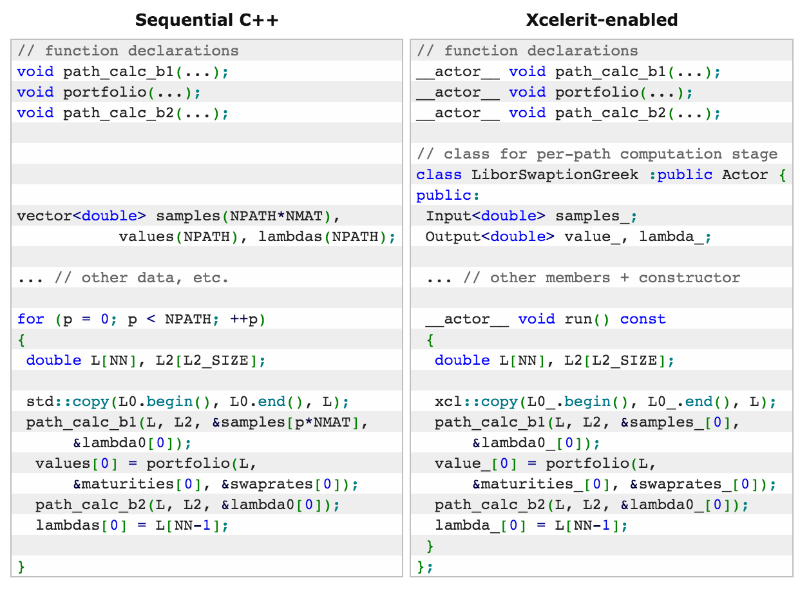
The application uses native Xeon Phi mode, without using the main processor. The test environment had the following configuration:
- CPU : Haswell Xeon E5-2697 v31 (14 cores, 2x HT) and Xeon Phi 7120P1 (61 core, 4x HT)
- HT : Hyper-threading Enabled
- OS : RedHat Enterprise Linux 6 (64bit)
- RAM : 64GB
- Development Tools : Xcelerit SDK 3.0.0b / ICC 15.0
During the experiment, the computation time of the test application on two processors and the sequential implementation on a single Haswell CPU core were compared. By computation time is meant the execution of all stages of the algorithm described above.

The graph below shows a comparison of the speed of an implementation run on Haswell for numbers with double and single precision:
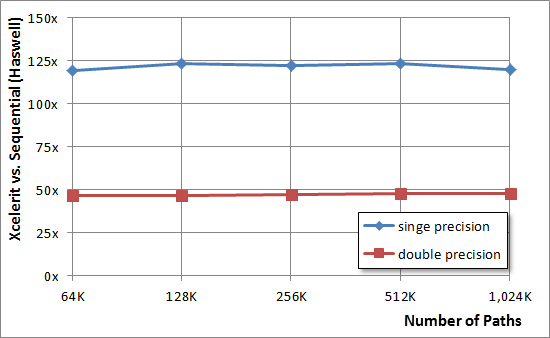
When using Xeon Phi, the results are as follows:

If in the previous case we managed to achieve processing acceleration of 50x and 125x for single and double precision, then with the help of co-processors these values were increased to 75x and 150x, respectively.
Other materials about hardware and online trading:
Source: https://habr.com/ru/post/277463/
All Articles