Web file manager Sprut.IO in OpenSource
In Beg, we have long and successfully engaged in virtual hosting, we use a lot of OpenSource solutions, and now it is time to share our development with the community: the file manager Sprut.IO , which we developed for our users and which is used in our control panel. We invite everyone to join its development. How it was developed and why we were not satisfied with the existing analogues, what crutches of technology we used and to whom it can be useful, we will tell in this article.
Project website: https://sprut.io
The demo is available at the link: https://demo.sprut.io:9443
Source code: https://github.com/LTD-Beget/sprutio

In 2010, we used NetFTP, which quite tolerably solved the tasks of opening / loading / correcting several files.
However, users sometimes wanted to learn how to transfer sites between hosting or between accounts between us, but the site was large, and the Internet was not the best for users. In the end, we either did it ourselves (which was obviously faster), or explained what SSH, MC, SCP and other terrible things are.
')
Then we had the idea to make a WEB two-panel file manager that works on the server side and can copy between different sources at the speed of the server, and which will include: searching through files and directories, analyzing the occupied space (analogue to ncdu), simple file upload, well, a lot of interesting things. In general, everything that would make life easier for our users and us.
In May 2013, we put it in production on our hosting. In some moments it turned out even better than we originally wanted - to download files and access the local file system, they wrote a Java applet that allows you to select files and copy everything to hosting or vice versa from hosting (where copying is not so important, he knew how to work with remote FTP and the user's home directory, but unfortunately, browsers will not support it soon).
Having read about analogue on Habré , we decided to put our product in OpenSource, which turned out to be, as it seems to us,excellent working and can be useful. It took another nine months to separate it from our infrastructure and bring it to the proper form. Before the new year 2016, we released Sprut.IO.
We made for ourselves and used the most, in our opinion, new, stylish, youth tools and technologies. Often used what was already done for something.
There is some difference in the implementation of Sprut.IO and the version for our hosting, due to the interaction with our panel. For ourselves, we use: full-fledged queues, MySQL, an additional authorization server, which is also responsible for selecting the destination server on which the client is located, transport between our servers over the internal network, and so on.
Sprut.IO consists of several logical components:
1) web-muzzle
2) nginx + tornado, accepting all calls from the web,
3) final agents that can be hosted on one or on many servers.
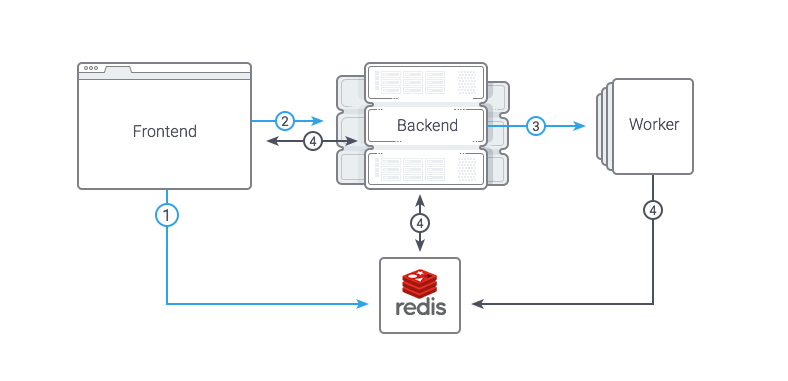
In fact, by adding a separate layer with authorization and server selection, you can make a multi-server file manager (as in our implementation). All elements can be divided into two parts: Frontend (ExtJS, nginx, tornado) and Backend (MessagePack Server, Sqlite, Redis).
The interaction scheme is presented below:

Web interface - everything is quite simple, ExtJS and a lot of code. The code was written in CoffeeScript. In the first versions, LocalStorage was used for caching, but in the end they refused because the number of bugs exceeded the benefits. Nginx is used to upload statics, JS code and files via X-Accel-Redirect (detailed below). He simply proxies the rest in Tornado, which, in turn, is a kind of router, redirecting requests to the desired Backend. Tornado scales well, and we hope we cut all the locks we’ve done.
Backend consists of several demons, which, as usual, are able to receive requests from the Frontend. Daemons are located on each destination server and work with the local file system, upload files via FTP, perform authentication and authorization, work with SQLite (editor settings, access to the user's FTP servers).
Requests to Backend are sent in two types: synchronous, which are performed relatively quickly (for example, listing files, reading a file), and requests to perform any long tasks (uploading a file to a remote server, deleting files / directories, etc.).
Synchronous requests - normal RPC. As a method of data serialization, msgpack is used, which has proven itself in terms of the speed of data serialization / deserialization and support among other languages. We also considered python-specific rfoo and google protobuf, but the first one didn’t work because of its binding to python (and its versions), and protobuf, with its code generators, seemed redundant to us, since the number of remote procedures is not measured in tens and hundreds, and there was no need to move the API into separate proto-files.
We decided to implement requests for long operations as simple as possible: there is a common Redis between Frontend and Backend, which stores the task being executed, its status and any other data. To run the task, use the usual synchronous RPC request. Flow turns out like this:
We took the path of least resistance and, instead of manual installation, prepared Docker images. Installation is essentially performed by several commands:
run.sh will check for the presence of images, in case they are not downloaded, and will launch 5 containers with system components. To update the images you need to run
Stop and delete images are respectively performed through the parameters stop and rm. Dockerfile assembly is in the project code, the assembly takes 10-20 minutes.
How to raise the environment for the development in the near future we will write on the site and in the wiki on github .
There are a lot of obvious opportunities for further improvement of the file manager.
As the most useful for users, we see:
If you have add-ons that may be useful to users, tell us about them in the comments or on the mailing list sprutio-ru@groups.google.com .
We will begin to implement them, but I will not be afraid to say this: it will take yearsif not decades . Therefore, if you want to learn how to program, know Python and ExtJS and want to gain development experience in an open project - we invite you to join the development of Sprut.IO. Moreover, we will pay a reward for each implemented feature, since we will not have to implement it ourselves.
The list of TODO and task execution status can be seen on the project website in the TODO section.
Thanks for attention! If it is interesting, we will be happy to write more details about the organization of the project and answer your questions in the comments.
Project website: https://sprut.io
The demo is available at the link: https://demo.sprut.io:9443
Source code: https://github.com/LTD-Beget/sprutio
Russian mailing list: sprutio-ru@groups.google.com
English mailing list: sprutio@groups.google.com
Project website: https://sprut.io
The demo is available at the link: https://demo.sprut.io:9443
Source code: https://github.com/LTD-Beget/sprutio
Why reinvent your file manager
In 2010, we used NetFTP, which quite tolerably solved the tasks of opening / loading / correcting several files.
However, users sometimes wanted to learn how to transfer sites between hosting or between accounts between us, but the site was large, and the Internet was not the best for users. In the end, we either did it ourselves (which was obviously faster), or explained what SSH, MC, SCP and other terrible things are.
')
Then we had the idea to make a WEB two-panel file manager that works on the server side and can copy between different sources at the speed of the server, and which will include: searching through files and directories, analyzing the occupied space (analogue to ncdu), simple file upload, well, a lot of interesting things. In general, everything that would make life easier for our users and us.
In May 2013, we put it in production on our hosting. In some moments it turned out even better than we originally wanted - to download files and access the local file system, they wrote a Java applet that allows you to select files and copy everything to hosting or vice versa from hosting (where copying is not so important, he knew how to work with remote FTP and the user's home directory, but unfortunately, browsers will not support it soon).
Having read about analogue on Habré , we decided to put our product in OpenSource, which turned out to be, as it seems to us,
How does he work
We made for ourselves and used the most, in our opinion, new, stylish, youth tools and technologies. Often used what was already done for something.
There is some difference in the implementation of Sprut.IO and the version for our hosting, due to the interaction with our panel. For ourselves, we use: full-fledged queues, MySQL, an additional authorization server, which is also responsible for selecting the destination server on which the client is located, transport between our servers over the internal network, and so on.
Sprut.IO consists of several logical components:
1) web-muzzle
2) nginx + tornado, accepting all calls from the web,
3) final agents that can be hosted on one or on many servers.
In fact, by adding a separate layer with authorization and server selection, you can make a multi-server file manager (as in our implementation). All elements can be divided into two parts: Frontend (ExtJS, nginx, tornado) and Backend (MessagePack Server, Sqlite, Redis).
The interaction scheme is presented below:
Frontend
Web interface - everything is quite simple, ExtJS and a lot of code. The code was written in CoffeeScript. In the first versions, LocalStorage was used for caching, but in the end they refused because the number of bugs exceeded the benefits. Nginx is used to upload statics, JS code and files via X-Accel-Redirect (detailed below). He simply proxies the rest in Tornado, which, in turn, is a kind of router, redirecting requests to the desired Backend. Tornado scales well, and we hope we cut all the locks we’ve done.
Backend
Backend consists of several demons, which, as usual, are able to receive requests from the Frontend. Daemons are located on each destination server and work with the local file system, upload files via FTP, perform authentication and authorization, work with SQLite (editor settings, access to the user's FTP servers).
Requests to Backend are sent in two types: synchronous, which are performed relatively quickly (for example, listing files, reading a file), and requests to perform any long tasks (uploading a file to a remote server, deleting files / directories, etc.).
Synchronous requests - normal RPC. As a method of data serialization, msgpack is used, which has proven itself in terms of the speed of data serialization / deserialization and support among other languages. We also considered python-specific rfoo and google protobuf, but the first one didn’t work because of its binding to python (and its versions), and protobuf, with its code generators, seemed redundant to us, since the number of remote procedures is not measured in tens and hundreds, and there was no need to move the API into separate proto-files.
We decided to implement requests for long operations as simple as possible: there is a common Redis between Frontend and Backend, which stores the task being executed, its status and any other data. To run the task, use the usual synchronous RPC request. Flow turns out like this:
- Frontend puts in a radish task with the status of "wait"
- Frontend makes a synchronous request in the backend, passing the task id there
- The backend accepts the task, sets the status “running”, does the fork, and performs the task in the child process, immediately returning the response to the backend
- Frontend looks at the status of the task or tracks changes to any data (for example, the number of copied files, which is periodically updated from the Backend).
Interesting cases worth mentioning.
Download files from Frontend
Task:
Upload the file to the destination server, while Frontend does not have access to the file system of the destination server.
Decision:
For transferring files, msgpack-server did not fit, the main reason was that the package could not be transferred byte-wise, but only entirely (it must first be fully loaded into memory and only then serialized and transmitted, with a large file size it will be OOM) in the end, it was decided to use a separate daemon for this.
The operation process is the following:
We receive the file from nginx, we write it to the socket of our daemon with the header, where the temporary location of the file is indicated. And after the file is fully transferred, send the request to RPC to move the file to the final location (already to the user). To work with the socket, we use the pysendfile package, the server itself is self-written based on the standard Python library asyncoreEncoding definition
Task:
Open the file for editing with the definition of encoding, write with the original encoding.
Problems:
If the user does not recognize the encoding correctly, then when making changes to the file with the subsequent recording, we can get a UnicodeDecodeError and the changes will not be recorded.
All the “crutches” that were eventually made are the result of working on tickets with files received from users, we also use all the “problem” files for testing after making changes to the code.
Decision:
Having studied the Internet in search of this solution, we found the chardet library. This library, in turn, is the port of the Mozilla uchardet library. For example, it is used in the well-known editor https://notepad-plus-plus.org
Having tested it with real examples, we realized that in reality it might be wrong. Instead of CP-1251, for example, “MacCyrillic” or “ISO-8859-7” may be issued, and instead of UTF-8 it may be “ISO-8859-2” or the special case “ascii”.
In addition, some of the files on the hosting were utf-8, but they contained strange characters, either from editors who cannot work correctly with UTF, or else from where, especially for such cases, they also had to add “crutches”.Example of encoding recognition and file reading, with comments# uchardet Mozilla - python chardet # https://github.com/chardet/chardet # # dev , . # # - , . 50000 - self.charset_detect_buffer = 50000 # part_content = content[0:self.charset_detect_buffer] + content[-self.charset_detect_buffer:] chardet_result = chardet.detect(part_content) detected = chardet_result["encoding"] confidence = chardet_result["confidence"] # , windows # - utf-8 cp-1251 - re_utf8 = re.compile('.*charset\s*=\s*utf\-8.*', re.UNICODE | re.IGNORECASE | re.MULTILINE) html_ext = ['htm', 'html', 'phtml', 'php', 'inc', 'tpl', 'xml'] # , if confidence > 0.75 and detected != 'windows-1251' and detected != FM.DEFAULT_ENCODING: if detected == "ISO-8859-7": detected = "windows-1251" if detected == "ISO-8859-2": detected = "utf-8" if detected == "ascii": detected = "utf-8" if detected == "MacCyrillic": detected = "windows-1251" # - charset if detected != FM.DEFAULT_ENCODING and file_ext in html_ext: result_of_search = re_utf8.search(part_content) self.logger.debug(result_of_search) if result_of_search is not None: self.logger.debug("matched utf-8 charset") detected = FM.DEFAULT_ENCODING else: self.logger.debug("not matched utf-8 charset") elif confidence > 0.60 and detected != 'windows-1251' and detected != FM.DEFAULT_ENCODING: # # elif detected == 'windows-1251' or detected == FM.DEFAULT_ENCODING: pass # , , , UTF-8 )) else: detected = FM.DEFAULT_ENCODING encoding = detected if (detected or "").lower() in FM.encodings else FM.DEFAULT_ENCODING answer = { "item": self._make_file_info(abs_path), "content": content, "encoding": encoding }Parallel text search in files, taking into account the file encoding
Task:
Organize text search in files with the possibility of using shell-style wildcards in the name, that is, for example, 'pupkin@*.com' '$ * = 42;' etc.
Problems:
The user enters the word "Contacts" - the search shows that there are no files with the given text, but in reality they exist, but on the hosting we meet many encodings even in the framework of one project. Therefore, the search should also take this into account.
Several times we were faced with the fact that users mistakenly could enter any lines and perform several search operations on a large number of folders, which further led to an increase in the load on the servers.
Decision:
Multitasking was organized fairly standardly using the multiprocessing module and two queues (a list of all files, a list of found files with the required entries). One worker builds a list of files, and the others, working in parallel, parse it and directly search.
The search string can be represented as a regular expression using the fnmatch package. Link to the final search implementation.
To solve the problem with encodings, an example of code with comments is given; it uses the already familiar package chardet .Implementation example worker# self.re_text = re.compile('.*' + fnmatch.translate(self.text)[:-7] + '.*', re.UNICODE | re.IGNORECASE) # remove \Z(?ms) from end of result expression def worker(re_text, file_queue, result_queue, logger, timeout): while int(time.time()) < timeout: if file_queue.empty(): continue f_path = file_queue.get() try: if is_binary(f_path): continue mime = mimetypes.guess_type(f_path)[0] # mime if mime in ['application/pdf', 'application/rar']: continue with open(f_path, 'rb') as fp: for line in fp: try: # unicode line = as_unicode(line) except UnicodeDecodeError: # , unicode, charset = chardet.detect(line) # if charset.get('encoding') in ['MacCyrillic']: detected = 'windows-1251' else: detected = charset.get('encoding') if detected is None: # ( break try: # line = str(line, detected, "replace") except LookupError: pass if re_text.match(line) is not None: result_queue.put(f_path) logger.debug("matched file = %s " % f_path) break except UnicodeDecodeError as unicode_e: logger.error( "UnicodeDecodeError %s, %s" % (str(unicode_e), traceback.format_exc())) except IOError as io_e: logger.error("IOError %s, %s" % (str(io_e), traceback.format_exc()))
The final implementation adds the ability to set the execution time in seconds (timeout) - the default is 1 hour. In the processes of the workers, the execution priority is lowered to reduce the load on the disk and on the processor.Unpacking and creating file archives
Task:
Allow users to create archives (zip, tar.gz, bz2, tar) and unpack them (gz, tar.gz, tar, rar, zip, 7z)
Problems:
We encountered many problems with “real” archives, including cp866 (DOS) file names and backslashes in file names (windows). Some libraries (standard ZipFile python3, python-libarchive) did not work with Russian names inside the archive. Some library implementations, in particular SevenZip, RarFile, do not know how to unpack empty folders and files (they are constantly found in archives with CMS). Also, users always want to see the process of performing an operation, and how to do it if the library does not allow (for example, simply making an extract () call)?
Decision:
ZipFile libraries, as well as libarchive-python, had to be fixed and connected as separate packages to the project. For libarchive-python, I had to fork the library and adapt it to python 3.
Creating files and folders with zero size (the bug is noticed in the SevenZip and RarFile libraries) had to be done in a separate cycle at the very beginning according to the file headers in the archive. For all the bugs, the developers have unsubscribed, we will find the time, then we will send a pull request to them, apparently, they are not going to fix it.
Separately done processing gzip compressed files (for sql dumps, and so on.), There were no crutches using the standard library.
Operation progress is monitored using the IN_CREATE system call yesterday using the pyinotify library. Of course, it does not work very precisely (it does not always work when the nesting of files is large, so the magic factor of 1.5 is added), but the task to display at least something similar for users performs. Not a bad decision, given that there is no way to track this without rewriting all the libraries for archives.
Code unpacking and creating archives.Sample code with comments# # , , , windows . # , ZipFile python 3 from lib.FileManager.ZipFile import ZipFile, is_zipfile from lib.FileManager.LibArchiveEntry import Entry if is_zipfile(abs_archive_path): self.logger.info("Archive ZIP type, using zipfile (beget)") a = ZipFile(abs_archive_path) elif rarfile.is_rarfile(abs_archive_path): self.logger.info("Archive RAR type, using rarfile") a = rarfile.RarFile(abs_archive_path) else: self.logger.info("Archive 7Zip type, using py7zlib") a = SevenZFile(abs_archive_path) # , ( ) for fileinfo in a.archive.header.files.files: if not fileinfo['emptystream']: continue name = fileinfo['filename'] # windows - try: unicode_name = name.encode('UTF-8').decode('UTF-8') except UnicodeDecodeError: unicode_name = name.encode('cp866').decode('UTF-8') unicode_name = unicode_name.replace('\\', '/') # For windows name in rar etc. file_name = os.path.join(abs_extract_path, unicode_name) dir_name = os.path.dirname(file_name) if not os.path.exists(dir_name): os.makedirs(dir_name) if os.path.exists(dir_name) and not os.path.isdir(dir_name): os.remove(dir_name) os.makedirs(dir_name) if os.path.isdir(file_name): continue f = open(file_name, 'w') f.close() infolist = a.infolist() # . # not-ascii - , extractall() # not_ascii = False try: abs_extract_path.encode('utf-8').decode('ascii') for name in a.namelist(): name.encode('utf-8').decode('ascii') except UnicodeDecodeError: not_ascii = True except UnicodeEncodeError: not_ascii = True # ========== # - # ========== t = threading.Thread(target=self.progress, args=(infolist, self.extracted_files, abs_extract_path)) t.daemon = True t.start() # IN_CREATE # , , , def progress(self, infolist, progress, extract_path): self.logger.debug("extract thread progress() start") next_tick = time.time() + REQUEST_DELAY # print pprint.pformat("Clock = %s , tick = %s" % (str(time.time()), str(next_tick))) progress["count"] = 0 class Identity(pyinotify.ProcessEvent): def process_default(self, event): progress["count"] += 1 # print("Has event %s progress %s" % (repr(event), pprint.pformat(progress))) wm1 = pyinotify.WatchManager() wm1.add_watch(extract_path, pyinotify.IN_CREATE, rec=True, auto_add=True) s1 = pyinotify.Stats() # Stats is a subclass of ProcessEvent notifier1 = pyinotify.ThreadedNotifier(wm1, default_proc_fun=Identity(s1)) notifier1.start() total = float(len(infolist)) while not progress["done"]: if time.time() > next_tick: count = float(progress["count"]) * 1.5 if count <= total: op_progress = { 'percent': round(count / total, 2), 'text': str(int(round(count / total, 2) * 100)) + '%' } else: op_progress = { 'percent': round(99, 2), 'text': '99%' } self.on_running(self.status_id, progress=op_progress, pid=self.pid, pname=self.name) next_tick = time.time() + REQUEST_DELAY time.sleep(REQUEST_DELAY) # , op_progress = { 'percent': round(99, 2), 'text': '99%' } self.on_running(self.status_id, progress=op_progress, pid=self.pid, pname=self.name) time.sleep(REQUEST_DELAY) notifier1.stop()Increased security requirements
Task:
Do not allow the user to access the destination server
Problems:
Everyone knows that hundreds of sites and users can be on the hosting server at the same time. In the first versions of our product, workers could perform some operations with root-privileges, in some cases theoretically (probably) you could get access to other people's files, folders, read too much or break something.
Unfortunately, we cannot give specific examples, there were bugs, but they did not affect the server as a whole, and were more our mistakes than a security hole. In any case, as part of the hosting infrastructure, there are load reduction and monitoring tools, and in the version for OpenSource we decided to seriously improve security.
Decision:
All operations were rendered, in the so-called workers, (createFile, extractArchive, findText), etc. Each worker, before starting work, performs PAM authentication, as well as the user's setuid.
In this case, all workers work in a separate process and differ only in wrappers (waiting or not waiting for an answer). Therefore, even if the algorithm itself for performing a particular operation may contain a vulnerability, there will be isolation at the level of system rights.
The application architecture also does not allow direct access to the file system, for example, via a web server. This solution allows you to effectively take into account the load and monitor user activity on the server by any third-party means.
Installation
We took the path of least resistance and, instead of manual installation, prepared Docker images. Installation is essentially performed by several commands:
user@host:~$ wget https://raw.githubusercontent.com/LTD-Beget/sprutio/master/run.sh user@host:~$ chmod +x run.sh user@host:~$ ./run.sh run.sh will check for the presence of images, in case they are not downloaded, and will launch 5 containers with system components. To update the images you need to run
user@host:~$ ./run.sh pull Stop and delete images are respectively performed through the parameters stop and rm. Dockerfile assembly is in the project code, the assembly takes 10-20 minutes.
How to raise the environment for the development in the near future we will write on the site and in the wiki on github .
Help us make Sprut.IO better
There are a lot of obvious opportunities for further improvement of the file manager.
As the most useful for users, we see:
- Add SSH / SFTP support
- Add WebDav Support
- Add terminal
- Add the ability to work with Git
- Add file sharing feature
- Add switching themes and creating different themes
- Make a universal interface for working with modules
If you have add-ons that may be useful to users, tell us about them in the comments or on the mailing list sprutio-ru@groups.google.com .
We will begin to implement them, but I will not be afraid to say this: it will take years
The list of TODO and task execution status can be seen on the project website in the TODO section.
Thanks for attention! If it is interesting, we will be happy to write more details about the organization of the project and answer your questions in the comments.
Project website: https://sprut.io
The demo is available at the link: https://demo.sprut.io:9443
Source code: https://github.com/LTD-Beget/sprutio
Russian mailing list: sprutio-ru@groups.google.com
English mailing list: sprutio@groups.google.com
Source: https://habr.com/ru/post/277449/
All Articles