RESTful API Design Approaches

Author: Vyacheslav Mikhailov, Solutions Architect.
In this article I will share the experience of designing a RESTful API - I will show you with specific examples how to make at least simple services beautifully. We will also talk about what an API is and why it is needed; let's talk about the basics of REST — let's discuss how it can be implemented; let's touch the main web practices that depend on and do not depend on this technology. We will also learn how to make good documentation, spending a minimum of effort on this, and see what version numbering methods exist for the RESTful API.
Part 1. Theory
')
So, as we all know, the API is an application programming interface, a set of rules and mechanisms by which one application or component interacts with others.
Why is a good API important?
- Ease of use and support . A good API is easy to use and maintain.
- Good conversion among developers . If everyone likes your API, new customers and users come to you.
- Higher popularity of your service . The more users of the API, the higher the popularity of your service.
- Better isolation of components . The better the API structure, the better the isolation of the components.
- Good impression about the product . The API is like a UI for developers; This is what the developers are paying attention to first and foremost when meeting with the product. If the API is a curve, you as a technical expert will not recommend companies to use such a product, acquiring something third-party.
Now let's see what kinds of APIs there are.
API types by implementation method:
- Web service APIs
- XML-RPC and JSON-RPC
- SOAP
- REST
- WebSockets APIs
- Library-based APIs
- Java script
- Class-based APIs
- C # API
- Java
API types by application category:
- OS function and routines
- Access to file system
- Access to user interface
- Object remoting APIs
- CORBA
- .Net remoting
- Hardware APIs
- Video acceleration (OpenCL ...)
- Hard disk drives
- PCI bus
- ...
As we can see, the Web API includes XML-RPC and JSON-RPC, SOAP and REST.
RPC (remote procedure call - “remote procedure call”) is a very old concept, combining ancient, middle, and modern protocols that allow calling a method in another application. XML-RPC is a protocol that appeared in 1998 shortly after the appearance of XML. It was initially supported by Microsoft, but soon Microsoft completely switched to SOAP, therefore in the .Net Framework we will not find classes to support this protocol. Despite this, XML-RPC continues to live in different languages (especially in PHP) - apparently, developers deserve the love of simplicity.
SOAP also appeared in 1998 through the efforts of Microsoft. It was announced as a revolution in the software world. This is not to say that everything went according to Microsoft's plan: there was a huge amount of criticism due to the complexity and heavyness of the protocol. At the same time, there were those who considered SOAP a real breakthrough. The protocol continued to evolve and produce dozens of new and new specifications, until in 2003 the W3C approved SOAP 1.2 as a recommendation, which is the last one now. The SOAP family turned out impressive: WS-Addressing, WS-Enumeration, WS-Eventing, WS-Transfer, WS-Trust, WS-Federation, Web Single Sign-On.
Then, naturally, a really simple approach appeared - REST. The abbreviation REST stands for representational state transfer - “transfer of the presentation state” or, better to say, the presentation of data in a format convenient for the client. The term “REST” was introduced by Roy Fielding in 2000. The main idea of REST is that each call to the service takes the client application to a new state. In essence, REST is not a protocol or a standard, but an approach, an architectural style of API design.
What are the principles of REST?
- Client-server architecture - without this REST is unthinkable.
- Any data is a resource .
- Any resource has an ID by which data can be obtained.
- Resources can be interconnected - for this, either an ID is sent as part of the response, or, as is more often recommended, a link. But I have not yet reached the point that everything is so good that links can be easily used.
- Standard HTTP methods (GET, POST, PUT, DELETE) are used - since they are already incorporated in the protocol, we can use them to build the framework for interaction with our server.
- The server does not store the state - this means the server does not separate one call from another, it does not save all sessions in memory. If you have any scalable cloud, some farm of servers that implements your service, there is no need to ensure the consistency of the state of these services between all the nodes that you have. This greatly simplifies scaling - when adding another node, everything works fine.
What is REST good for?
- He is very simple!
- We are re-using existing standards that have been running for a very long time and are used on many devices.
- REST is based on HTTP => all the buns are available:
- Caching
- Scaling.
- Minimum overhead.
- Standard error codes.
- Very good prevalence (even IoT devices already know how to work on HTTP).
Best solutions (technology independent)
What are the best solutions in the modern world that are not related to a specific implementation? I advise you to use these solutions:
- SSL everywhere is the most important thing in your service, since without SSL, authorization and authentication are meaningless.
- Documentation and service version - from the first day of work.
- POST and PUT methods should return the object that they have changed or created, this will reduce the time for accessing the service by half.
- Support for filtering, sorting and paging - it is very desirable that it be standard and work out of the box.
- MediaType support . MediaType - a way to tell the server what format you want to get the content in. If you take any standard web API implementation and go there from the browser, the API will give you XML, and if you go through some Postman, it will return JSON.
- Prettyprint & gzip . Do not minimize requests and do not compact for JSON (the answer that comes from the server). The overhead of a prettyprint is a percent unit, which is obvious if you look at how many tabs take in relation to the total message size. If you remove the tabs and send everything in one line, start with debugging. As for gzip, it gives a gain at times. T. h. I strongly advise using both prettyprint and gzip.
- Use only the standard caching mechanism (ETag) and Last-Modified (last modified date) - these two parameters are enough for the server so that the client understands that the content does not require updating. There is no point in inventing something of your own.
- Always use standard HTTP error codes . Otherwise, you will one day have to explain to someone why you decided that the client in your project needs to interpret error 419 exactly as you came up with for some reason. This is inconvenient and ugly - the client will not thank you for that!
HTTP methods properties
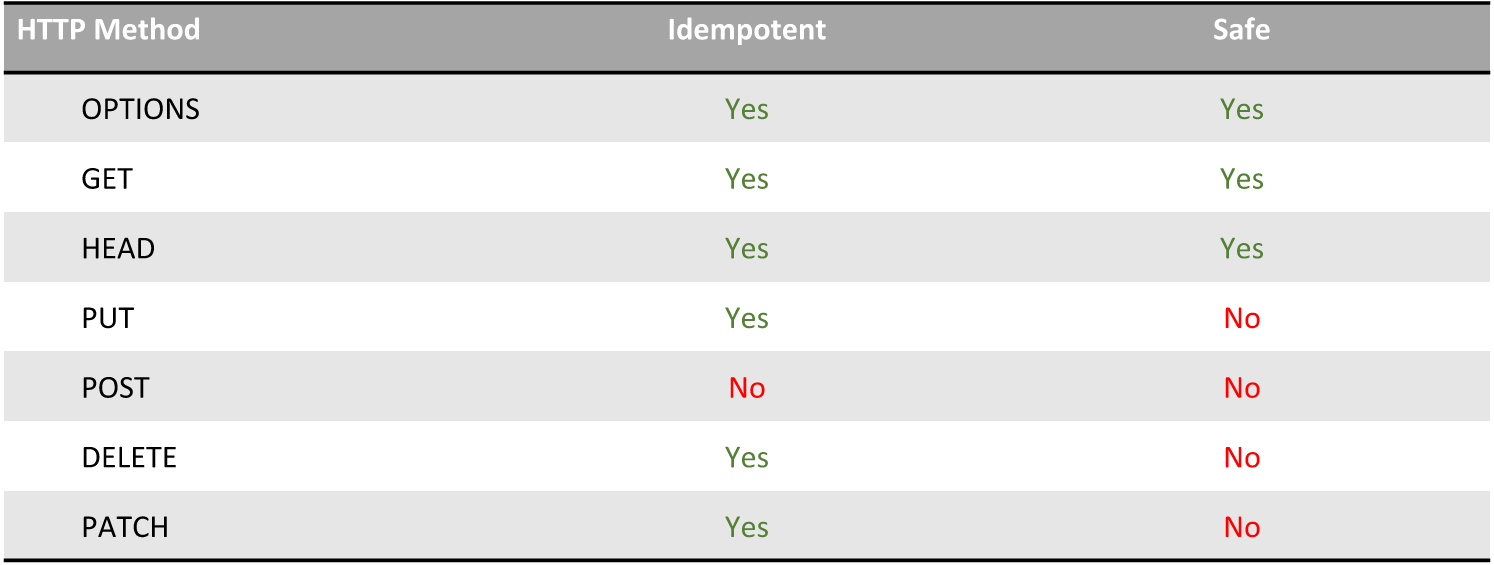
Today we will talk only about GET, POST, PUT, DELETE.
If we talk briefly about the rest presented in the table, OPTIONS - getting security settings, HEAD - getting headers without message body, PATCH - partial content change.
As you can see, all methods except POST, presented in the table, are idempotent. Idempotency - the ability to perform the same access to the service several times, with the answer each time being the same. In other words, it doesn't matter for what reason or how many times you performed this action. Suppose you performed an action to modify an object (PUT), and you received an error. You do not know what caused it and at what point, you do not know whether the object has changed or not. But, thanks to idempotency, you are guaranteed to be able to perform this action again, because customers can be sure about the integrity of their data.
“Safe” means that accessing the server does not change the content. So, GET can be called many times, but it will not change any content. If he changed the content, due to the fact that GET can be cached, you would have to deal with caching, invent some tricky parameters.
Part 2. Practice
Choosing technology
Now that we understand how REST works, we can start writing a RESTful API of a service that meets the principles of REST. Let's start with the choice of technology.
The first option is WCF Services . Everyone who has worked with this technology, usually no longer want to return to it - it has serious flaws and few advantages:
- webHttpBinding only (and then why the others? ..).
- Only HTTP Get & POST (and all) are supported.
+ Different XML, JSON, ATOM formats.
The second option is the Web API . In this case, the advantages are obvious:
+ Very simple.
+ Open source.
+ All HTTP features.
+ All MVC features.
+ Easy.
+ Also supports a bunch of formats.
Naturally, we choose the Web API. Now we select the appropriate hosting for the Web API.
Choosing a hosting for the Web API
There are enough options:
- ASP.NET MVC (good old).
- Azure (cloud structure).
- OWIN - Open Web Interface for .NET (fresh development from Microsoft).
- IIS
- Self-hosted
Owi
OWIN is not a platform or a library, but a specification that eliminates the strong coherence of the web application with the server implementation. It allows you to run applications on any platform that supports OWIN, without changes. In fact, the specification is very simple - it is just a “dictionary” of parameters and their values. Basic parameters are defined in the specification.
OWIN comes down to a very simple design:
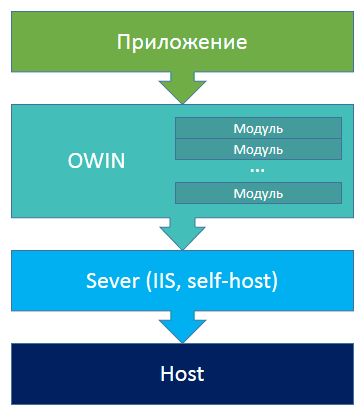
According to the scheme, we see that there is a host on which there is a server that supports a very simple “dictionary” consisting of a list of “parameter - value”. All modules that connect to this server are configured this way. A server supporting this contract tied to a specific platform can recognize all these parameters and initialize the infrastructure accordingly. It turns out that if you write a service that works with OWIN, you can freely, without changing the code, transfer it between platforms and use the same on other OSs.
Katana is an OWIN implementation from Microsoft. It allows you to place OWIN assemblies in IIS. This is how it looks, very simple:
[assembly: OwinStartup(typeof (Startup))] namespace RestApiDemo { public class Startup { public void Configuration(IAppBuilder app) { var config = new HttpConfiguration(); config.MapHttpAttributeRoutes(); app.UseWebApi(config); } } } You specify which class you have in Startup. This is a simple dll that rises IIS. Called the configurator. This code is enough to make it work.
We design the interface
Now we will design the interface and see how everything should look and what rules to comply with. All resources in REST are nouns, something that you can touch and touch.
As an example, take a simple model with a train schedule at the stations. Here are examples of simplest REST requests:
- Root (independent) API entities:
- GET / stations - get all the stations.
- GET / stations / 123 - get information on the station with ID = 123.
- GET / trains - the schedule of all trains.
- Dependent (on root) entities:
- GET / stations / 555 / departures - trains leaving from station 555.
Next, I will tell you more about DDD, why we are doing just that.
Controller
So, we have stations, and now we need to write the simplest controller:
[RoutePrefix("stations")] public class RailwayStationsController : ApiController { [HttpGet] [Route] public IEnumerable<RailwayStationModel> GetAll() { return testData; } RailwayStationModel[] testData = /*initialization here*/ } This is attribute based routing. Here we indicate the name of the controller and ask to give the list (in this case, random test data).
OData (www.odata.org)
Now imagine that you have more data than you need on the client (more than stealing hardly makes sense). At the same time, of course, I don’t want to write any pagination myself. Instead, there is a simple way to use the lightweight version of OData , which is supported by the Web API.
[RoutePrefix("stations")] public class RailwayStationsController : ApiController { [HttpGet] [Route] [EnableQuery] public IQueryable<RailwayStationModel> GetAll() { return testData.AsQueryable(); } RailwayStationModel[] testData = /*initialization here*/ } IQueryable allows you to use several simple but effective filtering and data management mechanisms on the client side. The only thing that needs to be done is to connect the OData assembly from NuGet, specify EnableQuery and return the iQueryable interface.
The main difference between this lightweight version and the full version is that there is no controller that returns metadata. A full OData slightly changes the answer (wraps the model you are going to return in a special wrapper) and knows how to return the associated tree of objects that you want to give to it. Also, the lightweight version of OData can't do things like join, count, etc.
Request Options
But what you can do:
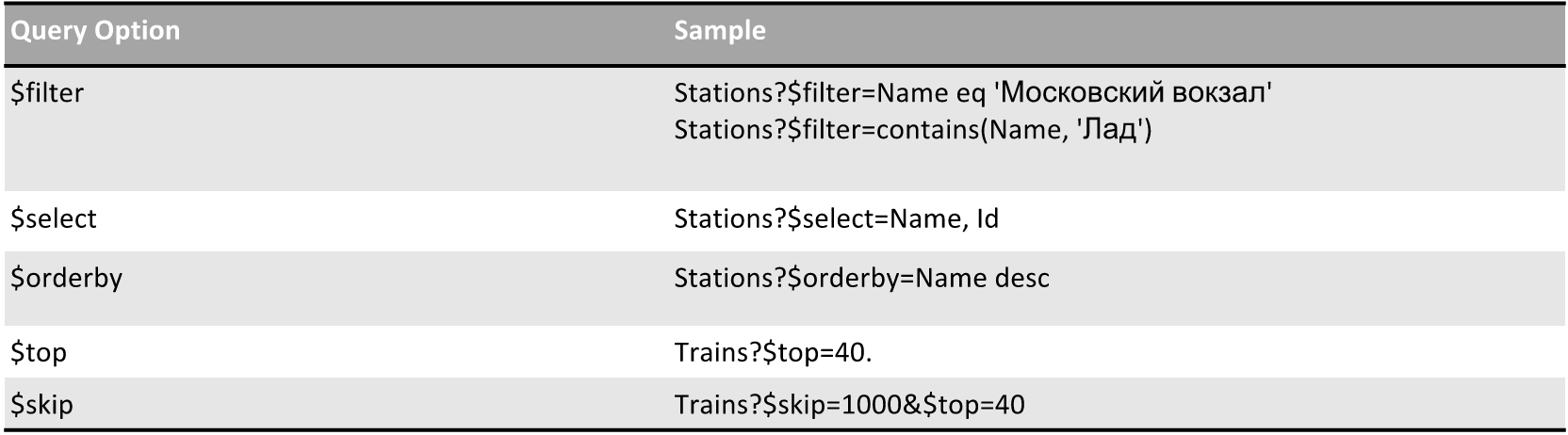
- $ filter - filter, by name, for example. All functions can be viewed on the OData website - they are very helpful and can significantly limit the selection.
- $ select is a very important thing. If you have a large collection and all objects are thick, but at the same time you need to create some kind of dropdown, in which there is nothing except the ID and the name you want to display, this function will help you, which will simplify and speed up the interaction with the server.
- $ orderby - sorting.
- $ top and $ skip - restriction on samples.
This is enough to not reinvent the wheel yourself. All this is able standard JS-library like Breeze.
EnableQuery Attribute
In fact, OData is such a thing that you can easily shoot yourself in the foot. If you have millions of records in the table, and you need to pull them from the server to the client, it will be hard, and if there are many such requests, it will be deadly.
For such cases, the EnableQuery attribute (see code above) has such a set of parameters that can be used to limit a lot: not to give more lines than necessary, not to let join, arithmetic operations, etc. At the same time, write yourself do not need anything.
- AllowedArithmeticOperators
- AllowedFunctions
- AllowedLogicalOperators
- AllowedOrderByProperties
- AllowedQueryOptions
- EnableConstantParameterization
- EnsureStableOrdering
- HandleNullPropagation
- MaxAnyAllExpressionDepth
- MaxExpansionDepth
- MaxNodeCount
- MaxOrderByNodeCount
- MaxSkip
- Maxtop
- PageSize
Dependent controller
So here are some simplest REST requests:
- GET / stations - get all stations
- GET / trains - all train schedules
- GET / stations / 555 / arrivals
- GET / stations / 555 / departures
Suppose we have station 555, and we want to receive all of its departures and arrivals. Obviously, an entity should be used here that depends on the essence of the station. But how to do it in controllers? If we do all this by routing attributes and put them into one class, it is clear that in this example, like us, there are no problems. But if you have a dozen nested entities and the depth grows even further, all this will grow into an unsupported format.
And there is a simple solution - in the routing attributes in the controllers, you can make variables:
[RoutePrefix("stations/{station}/departures")] public class TrainsFromController : TrainsController { [HttpGet] [Route] [EnableQuery] public IQueryable<TrainTripModel> GetAll(int station) { return GetAllTrips().Where(x => x.OriginRailwayStationId == station); } } Respectively, you take out all dependent entities in the separate controller. How many of them - it does not matter, since they live separately. From the point of view of the Web API, they will be perceived by different controllers - the system itself does not seem to know that they are dependent, despite the fact that in the URL they look so.
The only problem arises - here we have “stations”, and before that there were “stations”. If you change something in one place and change nothing in another, nothing will work. However, there is a simple solution - using constants for routing :
public static class TrainsFromControllerRoutes { public const string BasePrefix = RailwayStationsControllerRoutes.BasePrefix + "/{station:int}/departures"; public const string GetById = "{id:int}"; } Then the dependent controller will look like this:
[RoutePrefix(TrainsFromControllerRoutes.BasePrefix)] public class TrainsFromController : TrainsController { [HttpGet] [Route] [EnableQuery] public IQueryable<TrainTripModel> GetAll(int station) { return GetAll().Where(x => x.OriginRailwayStationId == station); } } You can do the simplest operations for dependent controllers - you just take and calculate the route yourself, and then you can’t go wrong. In addition, these things are useful in testing. If you want to write a test and then want to control it, rather than run every time through all the millions of your tests and correct all the lines where these relative URLs are indicated, then you can also use these constants. When you change them, your data changes everywhere. It is very convenient.
CRUD
So, we discussed with you how the simplest GET operations can look. Everyone understands how to make a single GET. But besides him, we need to discuss three more operations.
- POST - create a new entity
- POST / Stations - JSON description of the entity as a whole. The action adds a new entity to the collection.
- Returns the created entity (firstly, so that there are no double trips to the server, secondly, in order, if necessary, to return server-side parameters that were considered in this object and you need on the client).
- PUT - change entity
- PUT / Stations / 12 - Change entity with ID = 12. The JSON that comes in the parameter will be overwritten.
- Returns the modified entity. A path that has been applied many times must bring the system to the same state.
- DELETE
- DELETE / Stations / 12 - delete an entity with ID = 12.
More CRUD examples:
- POST / Stations - add the station.
- POST / Stations / 1 / Departures - add information about the departure from the station 1.
- DELETE / Stations / 1 / Departures / 14 - delete the record of the departure from the station 1.
- GET / Stations / 33 / Departures / 10 / Tickets — list of tickets sold for departure 10 from train station 33.
It is important to understand that nodes are necessarily some entities, something that can be “touched” (a ticket, a train, the fact of a train departure, etc.).
Anti-patterns
Here are some examples of how not to do it:
- GET / Stations /? Op = departure & train = 11
Here query string is used not only for data transfer, but also for actions. - GET / Stations / DeleteAll
This is a real life example. Here we do GET to this address, and he, in theory, should remove all entities from the collection - as a result, he behaves very unpredictably because of caching. - POST / GetUserActivity
Actually here is GET, which is written as POST. POST was needed because of the parameters of the request in the body, but you cannot transfer anything to the body of GET - you can only transfer GET to the query string. GET does not even support body as standard. - POST / Stations / Create
Here the action is specified in the URL - this is redundant.
Designing API
Suppose you have an API that you want to offer to people, and there is a domain model. How are API entities related to the domain model? Yes, they are not related, in fact. There is no need for this: what you do in the API is not related to your internal domain model.
The question may arise how to design an API if it is not a CRUD? To do this, we record any actions as commands for change. We save, read, delete a command, GET, check the status of this command. GET from a collection of commands - you get a list of all the commands that you sent for a particular entity.
Domain model
We will talk about the connection of the domain model with objects. In the example we have a hotel (Hotel), there are reservations (Reservation), rooms (Room) and devices (Device) attached to them. In our project, this allowed us to manage the rooms through these devices.
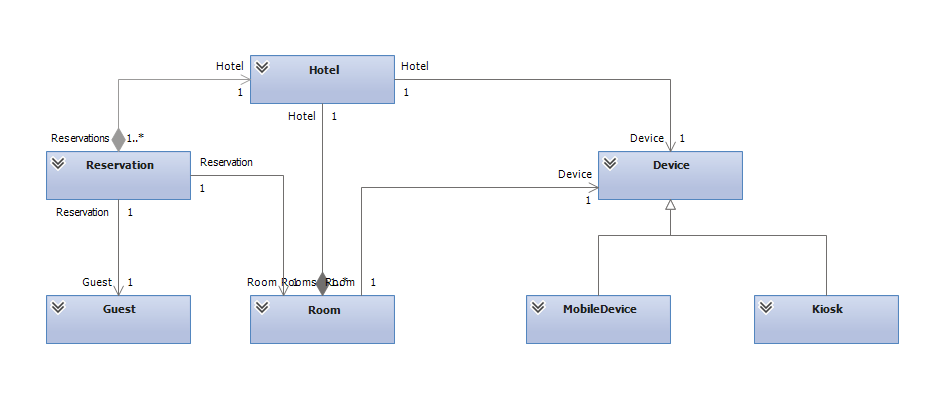
But here's the bad luck: the device - the essence that lives its own life, and it is not clear how to separate it from the hotel. But to divide the hotel and the device is, in fact, very simple - DDD will help. First of all, you need to figure out where the boundaries of the domain areas and where the boundaries of the entities responsible for the consistency of the system.
Bounded context (BC)
Bounded context (isolated subdomain) - in fact, sets of objects that are independent of each other and have completely independent models (different). In the example, we can take and pull apart hotels and devices on two different BCs - they are not interconnected, but there is duplication. There is an additional entity (AttachedDevice):
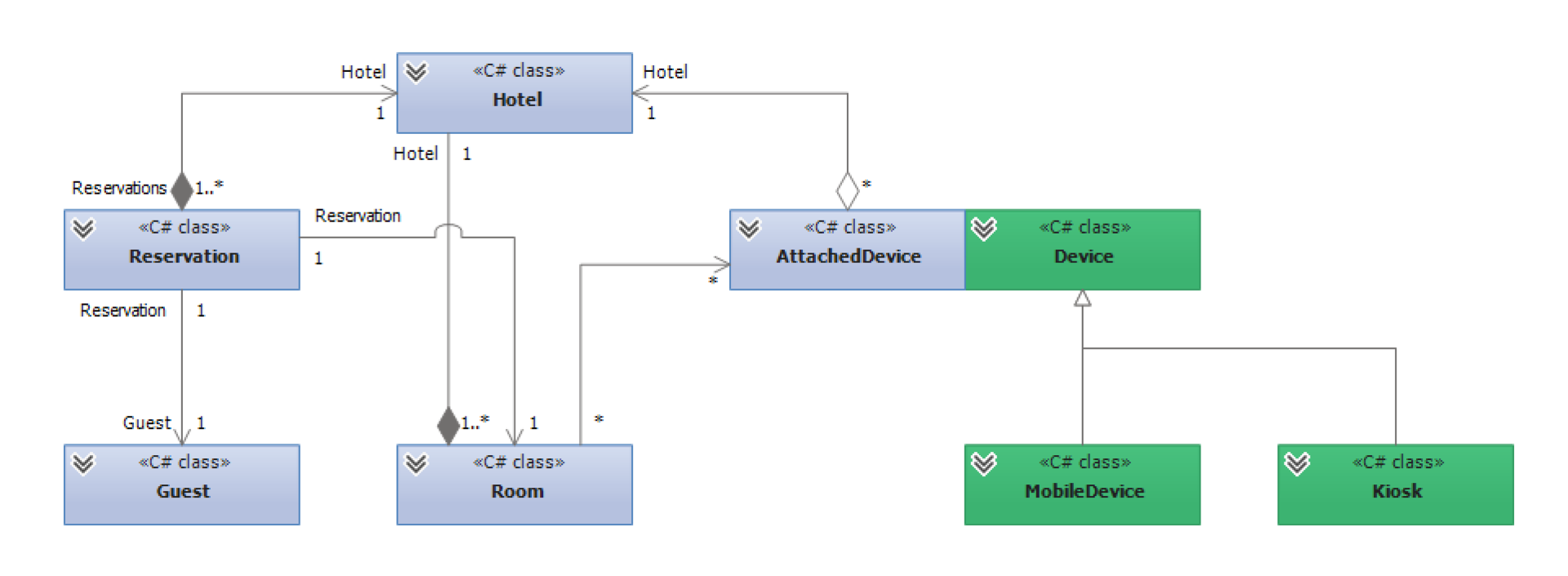
Here we have different representations of the same device, and there is nothing to worry about.
In DDD, aggregate route is an entity that owns all descendants. This is the top of our tree (Hotel); something for which you can pull out everything else. You can't take an AttachedDevice like this - it doesn't exist, and it doesn't make any sense. Likewise, the Room and Reservation classes make no sense being separated from the Hotel. Therefore, access to all these classes is exclusively through the root nature, through the Hotel, in this case. Device is another route from the very beginning, another tree with a different set of fields.
So, if you understand that one entity is playing in two different domains, just cut it - and this will be just a projection of the master entity. In AttachedDevice there will be, for example, fields with a room number, while in Device such fields are not needed.
Here are some examples of queries , how they might look in such a domain model:
- PUT / hotels / 555 / rooms / 105 / attachedDevices — replace the entire collection of attached devices with a new one.
- POST / hotels / 555 / rooms / 105 / attachedDevices - attach another device.
- DELETE / hotels / 12 - delete hotel description with ID = 12.
- POST / hotels / 123 / reservations - create a new reservation at the hotel ID = 123.
CQRS - Command Query Responsibility Segregation
I will not talk about architecture now, but I want to briefly describe what its principle of operation is. The CQRS architecture is based on the separation of data streams.

We have one stream through which the user sends to the server a command to change the domain. However, it’s not a fact that the change will really happen - the user does not operate on data directly. So, after the user sends a command to change the entity, the server processes it and puts it into some model that is optimized for reading - the UI reads this.
This approach will allow you to follow the principles of REST very easily. If there is a command, then there is an entity “list of commands”.
REST without PUT
In the simple CRUD world, PUT is the thing that changes objects. But if we strictly follow the principle of CQRS and do everything through commands, the PUT is lost, because we cannot change objects. Instead, we can only send a change command to the object. At the same time, you can monitor the execution status, cancel commands (DELETE), store changes history easily, and the user does not change anything, but simply reports intentions.
The REST without PUT paradigm is still controversial and not fully tested, but for some cases it is really well applicable.
Fine-grained VS coarse-grained
Imagine that you are doing a great service, a big object. Here you have two approaches: the fine-grained API and the coarse-grained API ("fine-grained" and "coarse-grained" API).
Fine-grained API:
- Many small objects.
- Business logic goes to the client.
- Need to know how objects are connected.
Coarse-grained API:
- Create more entities.
- Difficult to make local changes, for example
- POST / blogs / {id} / likes.
- It is necessary to track the status on the client.
- Large objects cannot be partially saved.
For a start, I advise you to design a fine-grained API: every time you create an object, send it to the server. For each action on the client side, a call is made to the server. However, it is easier to work with small entities than with large ones: if you write a large entity, it will be difficult for you to cut it later, it will be difficult to make small changes and pull out independent pieces from it. T. h. It is better to start with small entities and gradually enlarge them.
Version Numbering
It so happened that the contracts in our industry are very relaxed. For some reason, people think that if they took and made an API, this is their API, with which they can do anything. But it is not. If you once wrote an API and gave it to at least one counterparty, all is version 1.0. Any changes should now lead to a version change. After all, people will bind their code to the version that you gave them.
On the past, the project had to roll back the API several times simply because it was given to the client - we changed the error codes, but the client had already managed to get used to the old codes.
What are the currently known options for numbering versions of the Web API?

The simplest is to specify the version in the URL.
Here are the ready options when you don’t have to do anything yourself:
- aspnet.codeplex.com/SourceControl/latest#Samples/WebApi/NamespaceControllerSelector
- aspnet.codeplex.com/SourceControl/latest#Samples/WebApi/RoutingConstraintsSample
- www.strathweb.com/2015/10/global-route-prefixes-with-attribute-routing-in-asp-net-web-api
- github.com/climax-media/climax-web-http
Climax.Web.Http library
Here is one interesting finished option.
This is just routing attributes with constraint - if you did any serious objects, you probably did constraint. By the version number in this attribute, the guys just implemented constraint. Accordingly, one and the same attribute with different versions, but with the same controller name, you hang on two different classes and specify different versions. Everything works out of the box ...
VersionedRoute("v2/values", Version = 2)]<br> <br> config.ConfigureVersioning(<br> versioningHeaderName: "version", vesioningMediaTypes: null);<br> <br> config.ConfigureVersioning(<br> versioningHeaderName: null, <br> vesioningMediaTypes: new [] { "application/vnd.model"});<source lang="cs"> <h6><b></b></h6> open-source-, - Swagger. — Swashbuckle. <ul> <li>http://swagger.io/ </li> <li>https://github.com/domaindrivendev/Swashbuckle</li> </ul> Swashbuckle: <source lang="cs">httpConfiguration .EnableSwagger(c => c.SingleApiVersion("v1", ”Demo API")) .EnableSwaggerUi(); public static void RegisterSwagger(this HttpConfiguration config) { config.EnableSwagger(c => { c.SingleApiVersion("v1", "DotNextRZD.PublicAPI") .Description("DotNextRZD Public API") .TermsOfService("Terms and conditions") .Contact(cc => cc .Name("Vyacheslav Mikhaylov") .Url("http://www.dotnextrzd.com") .Email("vmikhaylov@dataart.com")) .License(lc => lc.Name("License").Url("http://tempuri.org/license")); c.IncludeXmlComme nts(GetXmlCommentFile()); c.GroupActionsBy(GetControllerGroupingKey); c.OrderActionGroupsBy(new CustomActionNameComparer()); c.CustomProvider(p => new CustomSwaggerProvider(config, p)); }) .EnableSwaggerUi( c => { c.InjectStylesheet(Assembly.GetExecutingAssembly(), "DotNextRZD.PublicApi.Swagger.Styles.SwaggerCustom.css"); }); } } As you can see, Swagger pulled out all that we have, pulled out XML comments.

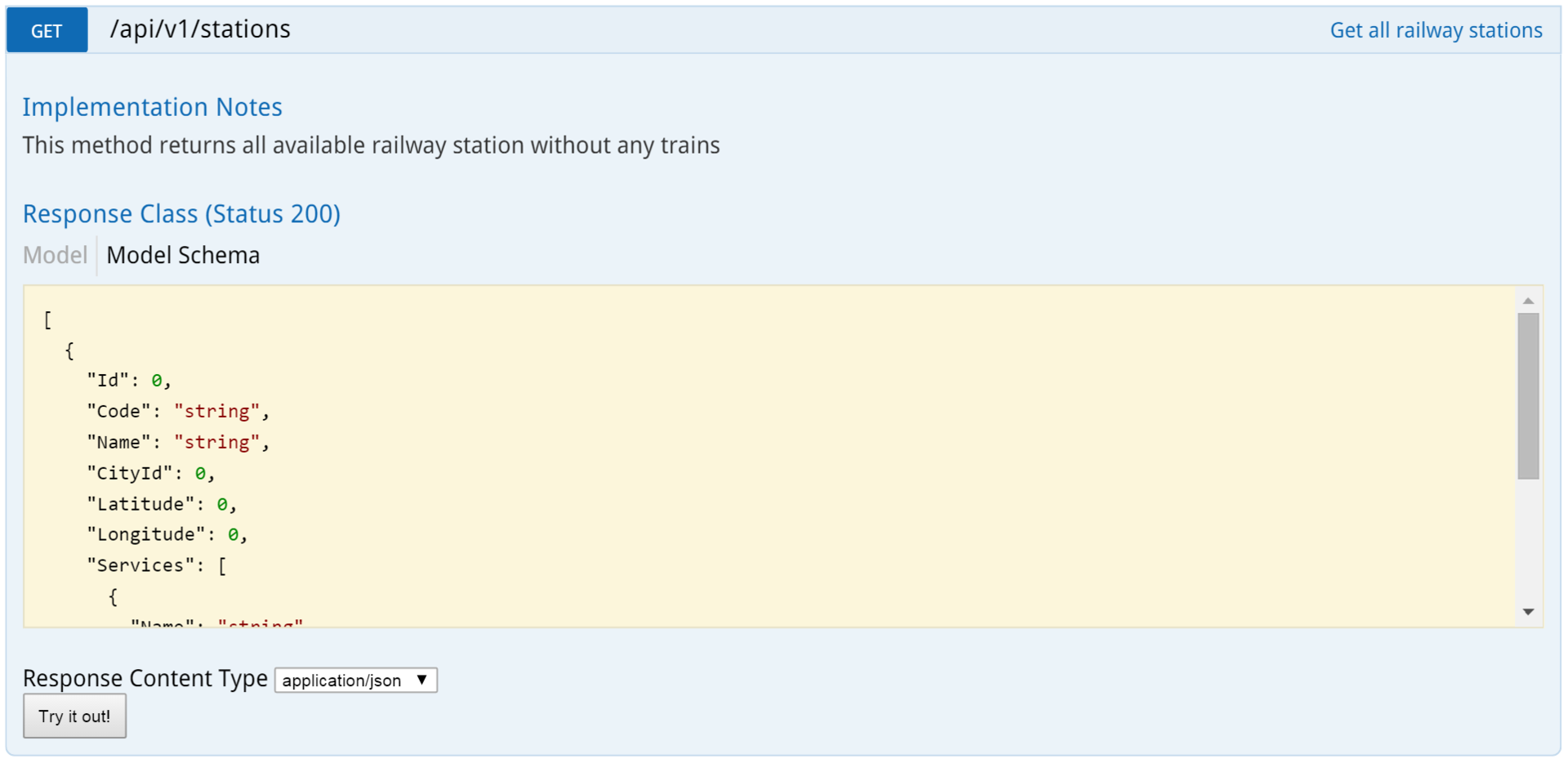
Below is a complete description of the GET model. If you click on a button, it will actually execute it and return the result.
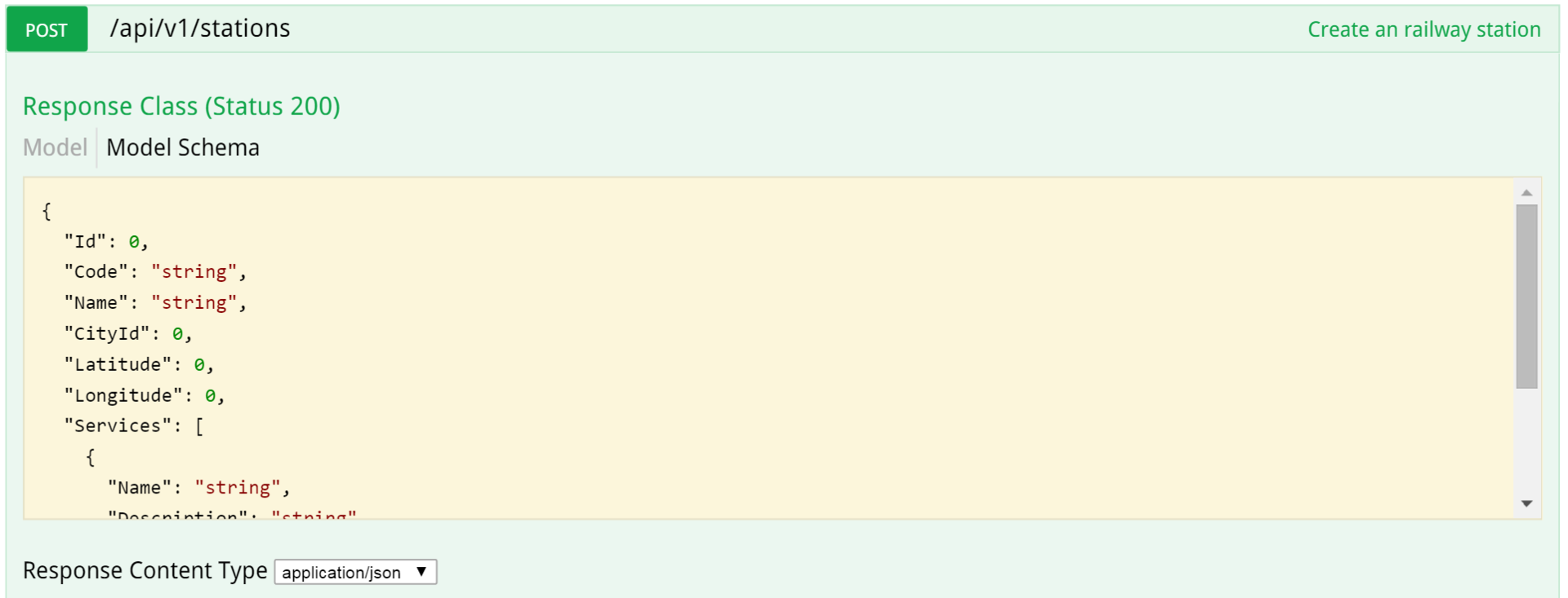
And here is the POST documentation, the first part:
Here is the second part:
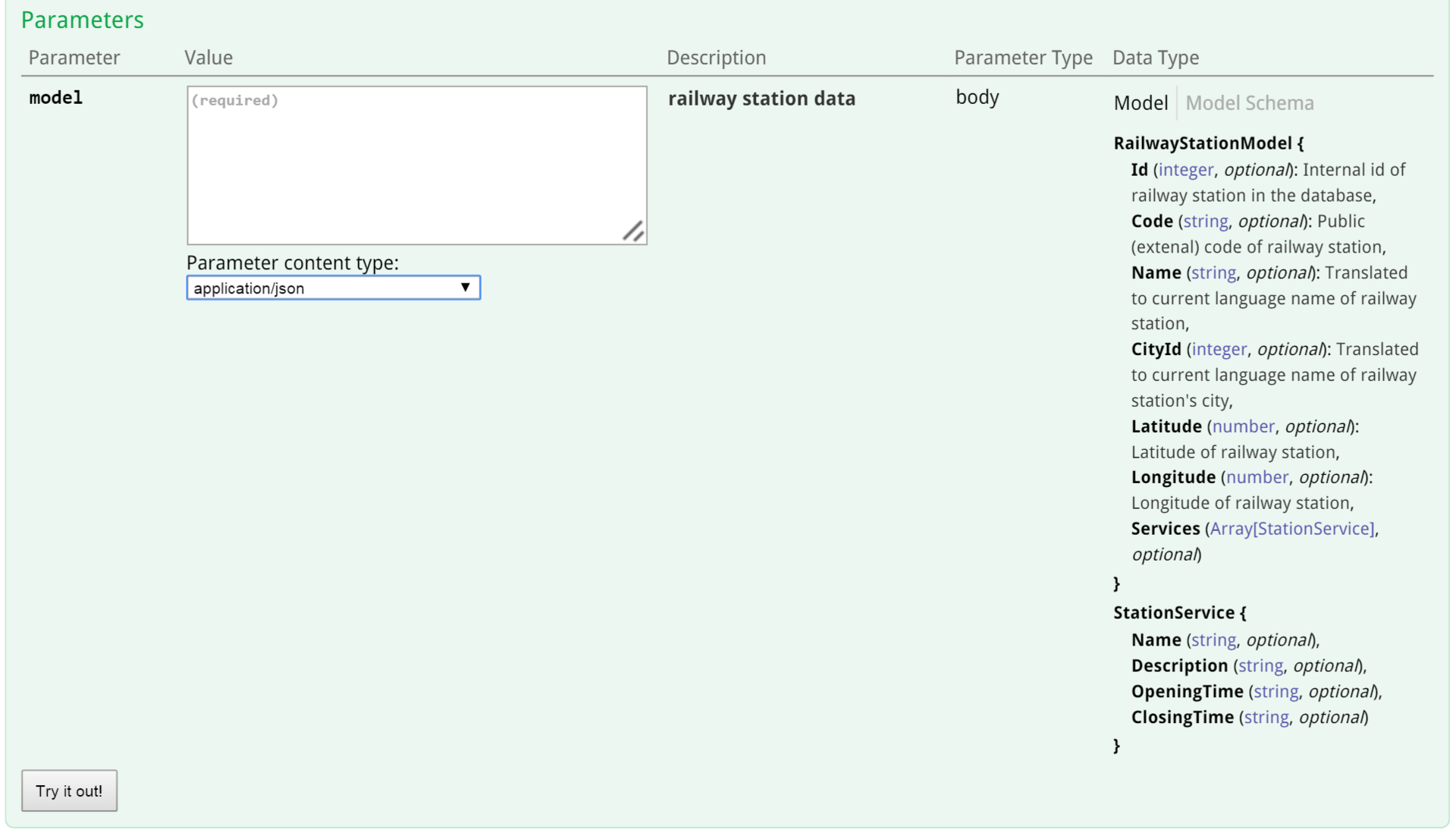
Everything that was written in the XML comments is here.
Sources
- www.vinaysahni.com/best-practices-for-a-pragmatic-restful-api
- www.strathweb.com/2015/10/global-route-prefixes-with-attribute-routing-in-asp-net-web-api
- www.thoughtworks.com/insights/blog/rest-api-design-resource-modeling
- jacobian.org/writing/rest-worst-practices
- piwik.org/blog/2008/01/how-to-design-an-api-best-practises-concepts-technical-aspects
- www.toptal.com/api-developers/5-golden-rules-for-designing-a-great-web-api
- www.odata.org
- owin.org
- pietschsoft.com/post/2014/06/15/cqrs-command-query-responsibility-segregation-design-pattern
- blog.pivotal.io/pivotal-labs/labs/api-versioning
Source: https://habr.com/ru/post/277419/
All Articles