Database versioning on the fly
Hello, my name is Eugene, and I am a web developer. Several years ago, the DBA function (Database Administrator) peeled me, I received several certificates about this and solved the corresponding tasks. I have long wanted to describe the task of database versioning, but it seemed to me that for this there must be some kind of win-win options that are well-known to skillful uncles, and I just misunderstand something. Yesterday's interview and the subsequent search on thematic resources showed that this is not so, and the task is really complicated, relevant and not solved unequivocally. Let's sort it out by points.
We only use version control for DDL (Data Definition Language) queries. The data itself does not interest us. Why? Consider two extreme cases.
If you work with a complex database, the tables, oddly enough, are the least interesting in it (although they should also be under version control). It is much more difficult to deal with business logic, which is contained in triggers, views, packages and procedures, and similar objects. For example, in one of the databases with which I worked, there were packets of up to one and a half megabytes in size. These packages are constantly being edited, and it is vital to know who made the changes, when, it is desirable to know why, and how we would roll it back to any desired state.
')
Imagine an ideal world in which we have a clear TK, which does not change until the completion of the project. The release, after which we forget about what we did, and get a regular salary for the beautiful eyes. The ideal code that we wrote immediately taking into account all the nuances that works without errors and does not require maintenance. The lack of improvements, urgent bug fixes, integration mechanisms, the ability to work on a test base and test samples, the presence of ubiquitous unit tests, which say that everything is impeccable.
In this case, it is more than enough for us to use the version control system as the primary source of information about the state of the database, and roll out changes to the base from it. There is a single repository, there is a joint work on the code base - everything is beautiful and transparent. There are several products that seem to implement this functionality quite well.
Now open your eyes and look around. In most cases, the project is implemented according to the scheme, which I would call the UHV (made, rolled out, threw out). A huge percentage of completed projects can not be sold and closed without any prospects for the future. The remaining lucky people go through hundreds of iterations, after which the name of the initial TK remains, at best. In this reality, we are primarily concerned not with the speed of the product, its requirements and quality. We are worried about the speed of development, because, for obvious reasons, the largest part of the project budget - the cost of work in development hours - depends on it.
Yes it is wrong. The world is cruel, unjust, dynamic, and requires an instant reaction, even if quality suffers. All developers in their hearts strive for the ideal code, but most accept the terms of the deal with the devil, and seek an acceptable compromise between quality and speed. We try to do what is best, but we learn not to blush, if instead of half a year and a perfect product, we made an unstable and ugly decision in two weeks. Moreover, at some point an understanding comes that the “last bug” will never be found, and all we can do is just at some point stop searching for it and making a release. To bring the solution to the ideal - the lot of the simplest applications and console scripts - and even then it is often not possible to take into account some non-trivial moments. When we talk about large projects, the example of Oracle, Microsoft and Apple shows us that there is no perfect code. As an example, the classic DBA answer to the question that in the new release of the Oracle Database - “removed 30% of the old bugs, added 40% of the new ones”.
What does this mean when we are talking about a database? Usually it is like this:
Further, if a developer comes to the DBA and asks to return the previous version of its object, then the DBA can do it in three cases (using the example of Oracle):
The most realistic option is the third. But it is complicated by the fact that it is often unknown on what date the restoration needs to be performed, and the restoration of a database of, say, 10 terabytes is quite a long and resource-intensive operation. So usually DBA just throws up his hands, the developer frowns out coffee and goes to write his object from scratch.
What can we do to make life easier for developers? I see the only option - to version the base on the fact of the changes already made. Naturally, this does not give any opportunity to prevent possible errors - but it will give a way in a large percentage of cases to bring the desired object and the whole system back to life.
The first simple “head-on” solution is to periodically unload the entire database. But unloading the base takes a long time, and then we will not know who changed what, when and what. So obviously something is required more difficult. Namely, we only need to unload the modified DDL objects. To do this, you can use two approaches - use Audit, or create a system trigger. I used the second method. Then the sequence is as follows:
In addition, for each action we can get quite detailed information, including the full text of the request, the scheme, the name and type of the object, the IP address of the user, the network name of his machine, the name of the user, the type and date of changes. As a rule, this is enough to then find a developer and issue a medal.
Next, we want to have a repository, in which the base structure will be presented in an intuitive way so that we can compare different versions of the object. To do this, each time you change the base, you need to unload the changed objects and commit to the base. Nothing complicated! We create a Git repository, first we do a full upload there, then we create a service that monitors our table of changes, and in the case of new records, unloads the changed objects.
Side by side comparison
List of objects in the scheme
Change history of a specific object
Same thing on github
That is, we have a working tool with which you can find the source of any changes in the database and, if necessary, roll them back. In my case, the largest Git repository in Gitlab (your instance on a separate machine) occupies several hundred megabytes, there are about one hundred thousand commits in it, and at the same time it works quite quickly. Before moving to Gitlab, the same repository lived fine on github, and then on bitbucket.
Data about what objects we then have:
You can also modify the program for updating an outdated database — unload the old version, unload the new version on top of it, fix the difference in semi-automatic mode.
As a recommendation, I will also add that it is better to periodically upload the current version over what is in the repository - in case of any changes that the logic of the upload algorithm could not cover.
There is a link to my PHP algorithm and installation guide at the end of the article, but I sincerely recommend that you use it only for reference - it was written long ago and very crookedly with your left hand during other tasks. The only plus is that, oddly enough, it works.
I sincerely wish you not to have to work with such a workflow. And I hope that this publication will help you if your world is still far from ideal.
Are you versioning your database? In the right way, or in fact? Maybe there are implementations for other DBMS - MySQL, Postgres? Or is there some fundamentally different good approach that I overlooked?
What we are versioning
We only use version control for DDL (Data Definition Language) queries. The data itself does not interest us. Why? Consider two extreme cases.
- Little data (say, less than 50 megabytes). In this case, we can simply periodically make a full dump of the database and safely add it to the repository.
- There is a lot of data (more than a gigabyte). In this case, versioning will not help us much, it will still be quite problematic to understand this. It is advisable in this case to use a standard scheme with backups and an archive log, which allows us to get a complete version of the database at any time.
Why do we need to version DDL?
If you work with a complex database, the tables, oddly enough, are the least interesting in it (although they should also be under version control). It is much more difficult to deal with business logic, which is contained in triggers, views, packages and procedures, and similar objects. For example, in one of the databases with which I worked, there were packets of up to one and a half megabytes in size. These packages are constantly being edited, and it is vital to know who made the changes, when, it is desirable to know why, and how we would roll it back to any desired state.
')
Perfect world
Imagine an ideal world in which we have a clear TK, which does not change until the completion of the project. The release, after which we forget about what we did, and get a regular salary for the beautiful eyes. The ideal code that we wrote immediately taking into account all the nuances that works without errors and does not require maintenance. The lack of improvements, urgent bug fixes, integration mechanisms, the ability to work on a test base and test samples, the presence of ubiquitous unit tests, which say that everything is impeccable.
In this case, it is more than enough for us to use the version control system as the primary source of information about the state of the database, and roll out changes to the base from it. There is a single repository, there is a joint work on the code base - everything is beautiful and transparent. There are several products that seem to implement this functionality quite well.
Real world
Summary of this part
Now open your eyes and look around. In most cases, the project is implemented according to the scheme, which I would call the UHV (made, rolled out, threw out). A huge percentage of completed projects can not be sold and closed without any prospects for the future. The remaining lucky people go through hundreds of iterations, after which the name of the initial TK remains, at best. In this reality, we are primarily concerned not with the speed of the product, its requirements and quality. We are worried about the speed of development, because, for obvious reasons, the largest part of the project budget - the cost of work in development hours - depends on it.
Yes it is wrong. The world is cruel, unjust, dynamic, and requires an instant reaction, even if quality suffers. All developers in their hearts strive for the ideal code, but most accept the terms of the deal with the devil, and seek an acceptable compromise between quality and speed. We try to do what is best, but we learn not to blush, if instead of half a year and a perfect product, we made an unstable and ugly decision in two weeks. Moreover, at some point an understanding comes that the “last bug” will never be found, and all we can do is just at some point stop searching for it and making a release. To bring the solution to the ideal - the lot of the simplest applications and console scripts - and even then it is often not possible to take into account some non-trivial moments. When we talk about large projects, the example of Oracle, Microsoft and Apple shows us that there is no perfect code. As an example, the classic DBA answer to the question that in the new release of the Oracle Database - “removed 30% of the old bugs, added 40% of the new ones”.
Who is to blame and what to do?
What does this mean when we are talking about a database? Usually it is like this:
- Access to the database is a large number of developers
- Often there is a need to roll back an object.
- No one ever admits that it was he who broke the object.
- Modifications are often incomprehensible
Further, if a developer comes to the DBA and asks to return the previous version of its object, then the DBA can do it in three cases (using the example of Oracle):
- If the previous version is still preserved in UNDO
- If the object was simply deleted and stored in the trash can (RECYCLEBIN)
- If he can deploy a full backup of the database to the desired date
The most realistic option is the third. But it is complicated by the fact that it is often unknown on what date the restoration needs to be performed, and the restoration of a database of, say, 10 terabytes is quite a long and resource-intensive operation. So usually DBA just throws up his hands, the developer frowns out coffee and goes to write his object from scratch.
What can we do to make life easier for developers? I see the only option - to version the base on the fact of the changes already made. Naturally, this does not give any opportunity to prevent possible errors - but it will give a way in a large percentage of cases to bring the desired object and the whole system back to life.
Implementation on the example of Oracle
The first simple “head-on” solution is to periodically unload the entire database. But unloading the base takes a long time, and then we will not know who changed what, when and what. So obviously something is required more difficult. Namely, we only need to unload the modified DDL objects. To do this, you can use two approaches - use Audit, or create a system trigger. I used the second method. Then the sequence is as follows:
- Create a table in which data about DDL queries will be stored.
- Create a system trigger that will write to this table.
In addition, for each action we can get quite detailed information, including the full text of the request, the scheme, the name and type of the object, the IP address of the user, the network name of his machine, the name of the user, the type and date of changes. As a rule, this is enough to then find a developer and issue a medal.
Next, we want to have a repository, in which the base structure will be presented in an intuitive way so that we can compare different versions of the object. To do this, each time you change the base, you need to unload the changed objects and commit to the base. Nothing complicated! We create a Git repository, first we do a full upload there, then we create a service that monitors our table of changes, and in the case of new records, unloads the changed objects.
What it looks like
Normal comparison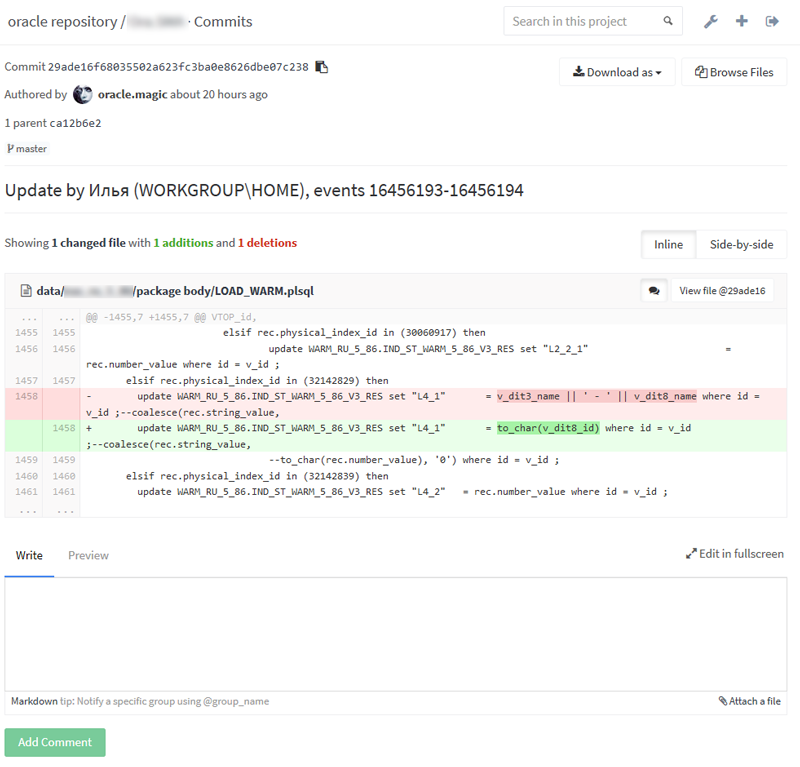
Side by side comparison
List of objects in the scheme
Change history of a specific object
Same thing on github
That is, we have a working tool with which you can find the source of any changes in the database and, if necessary, roll them back. In my case, the largest Git repository in Gitlab (your instance on a separate machine) occupies several hundred megabytes, there are about one hundred thousand commits in it, and at the same time it works quite quickly. Before moving to Gitlab, the same repository lived fine on github, and then on bitbucket.
Data about what objects we then have:
- Tables
- representation
- materialized views
- triggers
- sequences
- users (with password hashes that can be used to recover the old password)
- packages, functions, procedures
- database links (also with password hashes)
- grants
- with their state
- synonyms
You can also modify the program for updating an outdated database — unload the old version, unload the new version on top of it, fix the difference in semi-automatic mode.
Minuses
- Some changes may occur too quickly, and the service will not have time to upload intermediate results - but they are hardly relevant to us, and you can find them in the table of changes.
- Some changes can affect several objects at once - for example, deleting a schema or DROP CASCADE - but this can also be correctly worked out if desired, the question is only in implementation.
- Due to the fact that password repositories are stored in the repository, it cannot be issued directly to developers.
As a recommendation, I will also add that it is better to periodically upload the current version over what is in the repository - in case of any changes that the logic of the upload algorithm could not cover.
There is a link to my PHP algorithm and installation guide at the end of the article, but I sincerely recommend that you use it only for reference - it was written long ago and very crookedly with your left hand during other tasks. The only plus is that, oddly enough, it works.
Conclusion
I sincerely wish you not to have to work with such a workflow. And I hope that this publication will help you if your world is still far from ideal.
Are you versioning your database? In the right way, or in fact? Maybe there are implementations for other DBMS - MySQL, Postgres? Or is there some fundamentally different good approach that I overlooked?
Links
- A great discussion of how to version base on stackoverflow
- Implementing the right approach from Liquibase
- Same old Java + SVN implementation
- My tool's website with installation instructions
- My tool code repository on github
- You can take me to work here.
Source: https://habr.com/ru/post/277359/
All Articles