In-depth training in the garage - Data Brotherhood

Do you also find emoticons the most fun phenomenon?
In prehistoric times, when I was still a schoolboy and was just beginning to comprehend the delights of the Internet, from the very first contacts I added to ICQ, I was amused every day: well, really, imagine that your interlocutor makes a face that he sends you a smile!
Since then, a lot of water has flowed, but I have not matured: everyone sometimes continues to smile at the smiles sent to me, representing the sender with eyes of different sizes or a foolish smile on his entire face. But not everything is so bad, because on the other hand I became a developer and expert in data analysis and machine learning! And so, last year, my attention was attracted by a relatively new, but interesting and disturbing imagination technology of deep learning. Hundreds of the smartest scientists and the coolest engineers of the planet have been working on its problems for years, and finally, it became no more difficult to train deep neural networks with “classical” methods, such as ordinary regressions and wooden ensembles. And then I remembered smiles!
Imagine that to send a smile, you really could make a face, how cool would it be? This is a great deep learning exercise, I decided, and got to work.
')
In-depth training in the garage - Data Brotherhood
In-depth training in the garage - Two networks
In-depth training in the garage - Return smiles
Those who opened the post entirely, try not to disappoint, and not to repeat the storyline of countless posts on the Internet, which take the finished model from the article, pour tons of data into the network and magically everything turns out. I tried to approach the matter more methodically, to conduct a lot of experiments, study the results in detail and draw reasonable (haha, I hope!) Conclusions. Moreover, to obtain as a result, if not a model ready for use in real production, then at least conceptually capable of working in real-time with the application of understandable engineering efforts.
My story is not a fairy tale about how incredible results are obtained by the wave of a hand and the launch of a simple script. This story of successive failures that were slowly but surely overcome by long studies of modern and not-so-many articles and countless experiments.
Disclaimer
Many questions in this series of articles were not covered: how to select and change the learning rate, how to set up topologies, how to specifically handle the used data sets. I wanted to write about the project as a whole and talk about the fundamental problems facing me and their possible solutions, and not dig into the details.
I also want to apologize in advance for a wild amount of Anglicism: there is almost no Russian-language literature in this area, and I wrote as I was used to, although I tried to use Russian analogues in some places.
All materials, data sets, pictures and videos are taken from open sources and are used exclusively for educational purposes.
Oars into the water!
To begin with, tulchein: I decided to choose for myself a rather adult, but at the same time most flexible toolkit. This immediately discarded Caffe and various hardcore C ++ libraries, after all, this is a research project!
In principle, (at that time) only Theano and Torch remained (tensorflow has not yet come out). Both Python and Lua I know well and have quite a lot of experience with both languages, so the choice was purely tasteful: I chose Theano simply because it seemed to me more flexible, because even though it supports deep learning primitives, it generally builds arbitrary symbolic expressions, and seems more generalized. To compensate for the finished brick layers that Torch has and Theano doesn't have, I decided to use Lasagne, essentially the same bricks, but on top of Theano.
I’ll say right away that I didn’t choose well enough, that is, without having any experience with networks, so in the process I felt sorry for many times and turned back that I didn’t choose Torch. As a result, I still have not decided what is best :)
So, choose a platform, you can code! But what?
Task
The product is more or less clear: I want to send smiles without choosing them from the list, but depicting them on their faces. So, I want to make a face, be photographed, and the system, ideally, should understand for me what kind of smile I paint and write it in the message. Immediately disappoint: the prototype in the form of a plug-in for Skype, VTSAP or HENAUT never reached (for now?), There is not enough time, I only completed the system from the networks.
Fortunately, such product requirements can be easily transformed into technological ones: we need, in simple words, to be able to transform a selfie into a smile!
In order to convert a face into a smile, you must first find and highlight it (we don’t want to force the user to align the face on the screen, right?).
So, the algorithm:
- Looking for a face.
- Cut out.
- Convert to smile.
- ??????
- PROFIT!
Everything can be taught!
Just what? First, let's deal with the detection of faces. Internets are full of articles about the classification of images. But we, first of all, need not a classification, but detection! And it is much more difficult. Fortunately, here comes the first important insight: detection can be reduced to classification. Let's take our network and apply it not to the whole image, but to all the square windows inside this image. Or rather, not to all, but to windows of several sizes with an offset (4 i, 4 j) in (x, y), where i, j from (0, ceil (w / 4)), (0, ceil (h / four)).
It turns out the algorithm (pseudo-code):
def windows(img): window_size = min(img.height, img.width) while not_too_small(window_size): y = 0 while y < img.height: while x < img.width: yield (x, y, x + window_size, y + window_size) x += dx if pixels_x_left_unyilded(): yield (img.width - window_size, y, img.width, y + window_size) y += dy if pixels_y_left_unyilded(): while x < img.width: yield (x, img.hight - window_size, x + window_size, img.hight + window_size) x += dx window_size /= resizing_factor dx /= resizing_factor dy /= resizing_factor So, we resize the image at several different scales and for each scale we go by a fixed-size window in increments of 4 pixels. And we carry out the classification of each square person / not person. After that, of course, we will have a lot of squares, which are lit up for each person, so that they will have to somehow be drained. Algorithms can come up with different, clever and not so, but I just choose the best lit square among the highly intersecting ones:
def filter_frames(frames): res = [] while len(frames) > 0: frames.sort(by=probability_of_face) res.append(frames[0]) frames = frames[1:] for f in frames: if intersection(res[-1], f) > big_enough: frames.remove(f) Taki are learning?
Why? By no means fortunate, I already armed myself with knowledge from several text and video courses on deep learning, several interesting blogs and a fairly large set of read articles on modern research (large by the standards of the month, at that time of preparation, but nevertheless, I enough).
If we want to work with images, we use convolutional networks. No exceptions.
In fact, there is another opinion from the great minds in this field: the correct use of ordinary layers, and the convolutions from the evil one. After all, in essence, they are nothing more than ordinary layers, but with the “hard-coded” property of independence from the position of the object. But this property, firstly, could be learned by the network itself, and secondly, it is generally not correct, because during the detection the position is just important for us!
The bad news for this approach is the inability of its implementation on modern hardware, so we postpone this option for a dozen years and make convolutionary networks.
And here we are very lucky, because it's pretty simple! Following the example of the first epic breakthrough of CNN - AlexNet, whose architecture is quite simple to repeat: take yourself convoluted-pooling layers, how much you can afford, and on top a couple of fully connected ones. The larger the network, the better, except for the fact that it is very easy to retrain, but, thank Hinton, it is very easy to cope with this using a technique called dropout and a small attenuation of the scales, just in case.
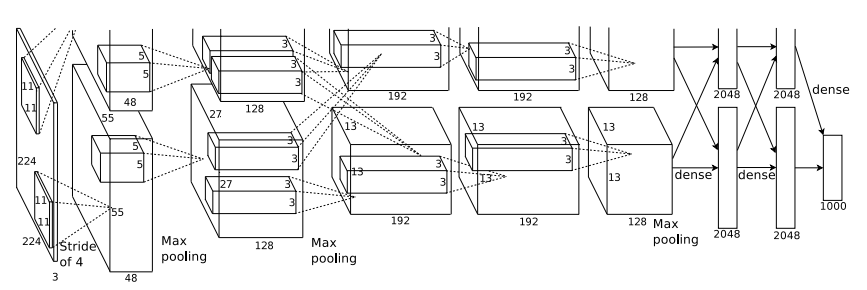
My first, still small, network:
def build_net12(input): network = lasagne.layers.InputLayer(shape=(None, 3, 12, 12), input_var=input) network = lasagne.layers.dropout(network, p=.1) network = conv(network, num_filters=16, filter_size=(3, 3), nonlin=relu) network = max_pool(network) network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=16, nonlin=relu) network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=2, nonlin=relu) return network It is small mainly because at that time I did not have available GPUs and I optimized on the CPU, which is very slow.
Well, we are learning at last?
And on what? Fortunately, good people have created many open datasets for the tasks of recognition and detection of faces. I first took dataset called FFDB. There are a lot of photos in it, in which faces are highlighted with ellipses (not directly over the photos, but the parameters of the ellipse are separately written in a text file). This dataset can only be used for educational purposes, but we have such goals, right? :) Additionally, I got there some data marked by me and obtained from photos similar to KDVV.
Everything is there, let's go teach!
Let's go. And immediately, magically, it came out!
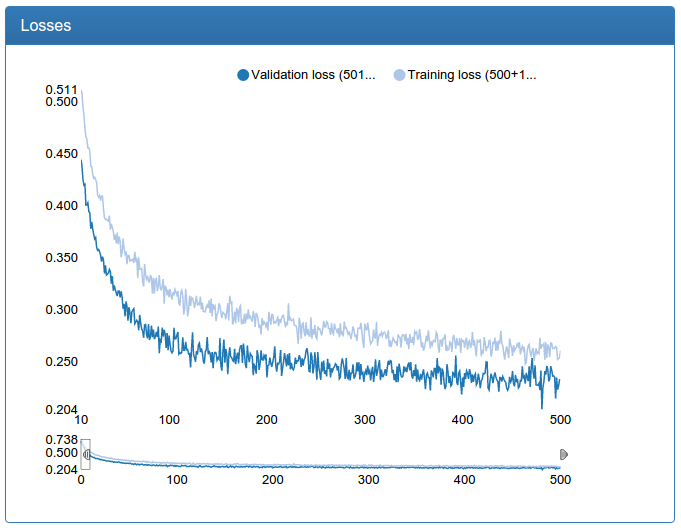
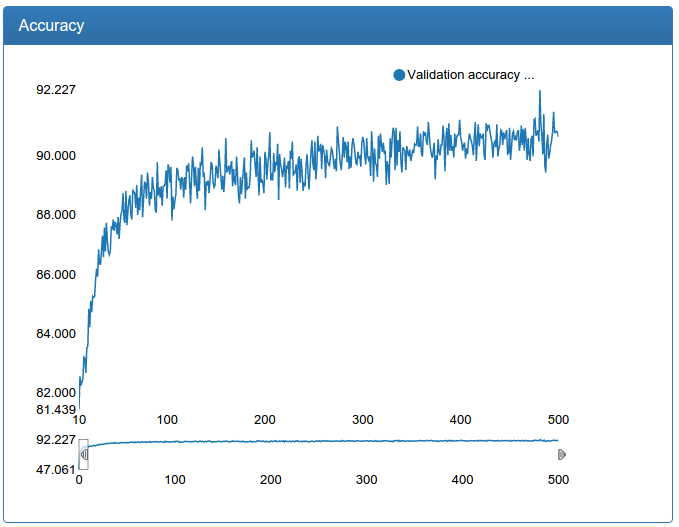

Screenshots were made in a specially developed system for monitoring neural network learning called DeepEvent, which I will write in a separate article if you are interested.
The first 10 iterations of training are cut off simply because they say little and depend heavily on the random initialization of weights.
In the example of work, all the windows in which the network has found a face are marked in red, the windows left after filtering are marked in green.
I also confess that there is a small deception: all the graphics were made much later not on the very experiments, but on slightly more advanced ones and where they need to be repaired, but similar. The fact is that DeepEvent was not developed immediately and the results of the first experiments were lost forever. Although, as I remember now, this network at the very beginning did not give 92%, but about 89.5%.
And here we see that although the network shows transcendental for such small efforts on the part of me 92%, the present quality of detection leaves much to be desired. What to do? Need to learn more network!
def build_net48(input): network = lasagne.layers.InputLayer(shape=(None, 3, 48, 48), input_var=input) network = lasagne.layers.dropout(network, p=.1) network = conv(network, num_filters=64, filter_size=(5, 5), nolin=relu) network = max_pool(network) network = conv(network, num_filters=64, filter_size=(5, 5), nolin=relu) network = max_pool(network) network = conv(network, num_filters=64, filter_size=(3, 3), nolin=relu) network = max_pool(network) network = conv(network, num_filters=64, filter_size=(3, 3), nolin=relu) network = max_pool(network) network = DenseLayer(lasagne.layers.dropout(network, p=.5), nolin=relu, num_units=256) network = DenseLayer(lasagne.layers.dropout(network, p=.5), nolin=relu, num_units=2) return network And nothing comes out. It turns out that they often forget to tell in articles, for deep learning you need a lot of data. Lots of. With the above dataset, it was worthy of me to train a small model, but a small model did not give the quality I wanted. The big model did not converge to normal minimums, and if you decrease the dropout thresholds, it quickly retrained, which is logical: it is not difficult for a large model to just remember a small amount of training data.
Augmentation
Well, I judged, we need more data - we will make more data! And I implemented a process that, as I later learned, is called data augmentation: this is when transformations are applied to the initial data, which effectively increases the size of the training sample hundreds or even thousands of times.
So, for each example, with a probability of 0.5, we reflect it horizontally, because this does not change the class of the person / person. Also, for each face I took not the original square, obtained from the ellipse that was present in the dataset, but, first, the square was accidentally slightly increased (or decreased) in a certain interval, and secondly, after that, it was slightly shifted in x and y at some intervals.
Additionally, later I still thought of taking this square itself, but of it, but accidentally slightly stretched either in x or y (50/50). As a result, it turns out a rectangle cut out from a picture with a face, which then must be turned into a square by compression. The difference of this transformation is that the previous one changes the size and position of the square but does not deform the face itself, and this transformation deforms the face: slightly stretches / compresses it either vertically or horizontally.
Pseudocode augmentation:
def get_rnd_img_frame(img, box, net_input_size): box = move_box(box, random(minx, maxx), random(miny, maxy)) box = scale_box(box, random(minscale, maxscale)) if random.random() >= 0.5: stretch_x, stretch_y = random(1., stretchx), 1 else: stretch_x, stretch_y = 1, random(1., stretchy) box = stretch_box(box, stretch_x, stretch_y) frame = img.crop(box) if random() > 0.5: frame = mirror(frame) return frame.resize((net_input_size.x, net_input_size.y)) Using the above combinations, I got an effectively infinite set of data: the probability of repeating a picture for 500 epochs of learning, according to my estimates, was somewhere around a tenth of a percent for my image size.
Here are the results of the same small model, but with added training and test sets:

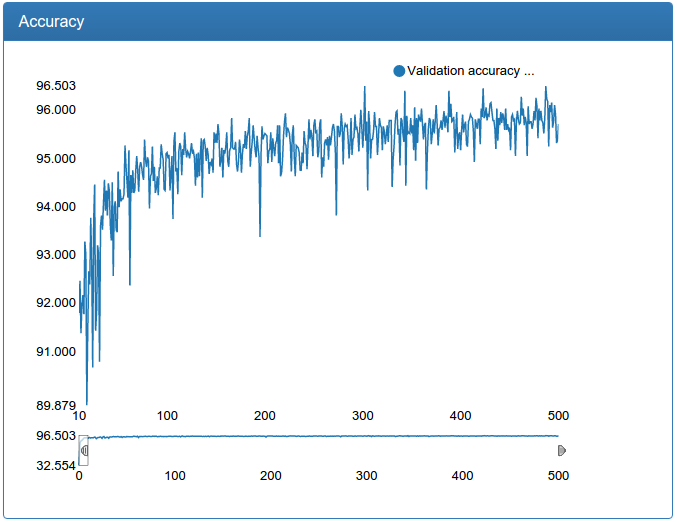

On the example of work, there are now blue squares, due to the fact that I divided the filtering into two stages: first, only windows of each size are filtered individually, choosing the best among their size (blue), and globally among all sizes (green), at the same time, for some reason I have reduced the window sliding step.
Optimization I
True, instead of a small amount of training data, I received another problem: a potentially infinite amount of data needs a potentially infinitely powerful computer! Or a clever trick. Since I specialize more in the software part, I decided that I would build a potentially infinitely powerful computer next time, and solve the current problem with a clever trick: I will not generate data for learning in advance and load it entirely into memory, and build an index in advance with The original unfinished dataset, which I will complement right in runtime. In essence, right during the iteration for each object in the mini-batche, I call the above algorithm and get updated data generated on the fly.
With this, by the way, is a funny story. When I debugged all this on the CPU and went to run on the GPU, I saw a furious performance drop: judge for yourself, the augmentation algorithm contains a bunch of logic, after which there is also a reflection and resize of the picture! And so for all 1024 elements of the mini-match, multiply by several dozen mini-batches per iteration!
In general, of course, it categorically did not suit me, and I went to understand. And it turned out that everything is quite logical: in a single-threaded python program, the GPU simply sleeps while the CPU slowly generates a minibatch. Laziness is bad, we have to fight it, and I decided that the GPU should pry, like a galley slave, every moment I have!
Decision? Do not block the GPU! Let's, the CPU will asynchronously prepare the next batch, while the GPU learns the network on the current one. So I did. And I was absolutely confident in the success of this operation, but I was disappointed: it almost did not help. It turned out that the CPU runs much longer than the GPU, especially on small networks, and the GPU still sleeps most of the time.
Well, in vain, have I designed all these web services? How to optimize parallel approximately the same read-only processing of a large array of objects? Sharding (it is MapReduce)! Let’s, I decided, we’ll run a lot of processes and give each one a piece of the mini-batches that they will process, put the results into a queue and then, without waiting, process the piece of the next mini-match if the queue is not full. Additionally, we will launch another process that will listen to this queue, understand to which mini-match a piece belongs, collect from the mini-fitch pieces and put it in the second turn, from which the main process working with the GPU already takes the data.
And, finally, having armed with a server with 32 cores and running the generation of augmented data in 32 processes (+ two almost always waiting in a queue or a GPU) and loading it I don’t want to, since the second era, the GPU almost stopped sleeping.
Hurray, we learn!
So, now you can teach not a toy model of normal size and success!, If properly tuned, it does not retrain and does not hang out of minimums.
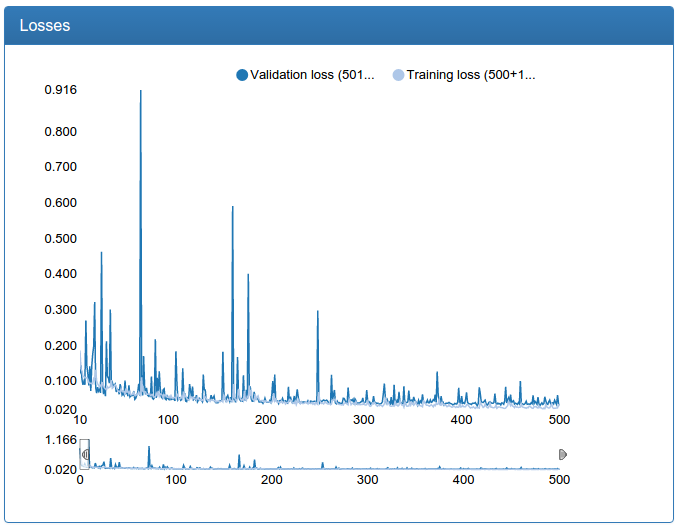
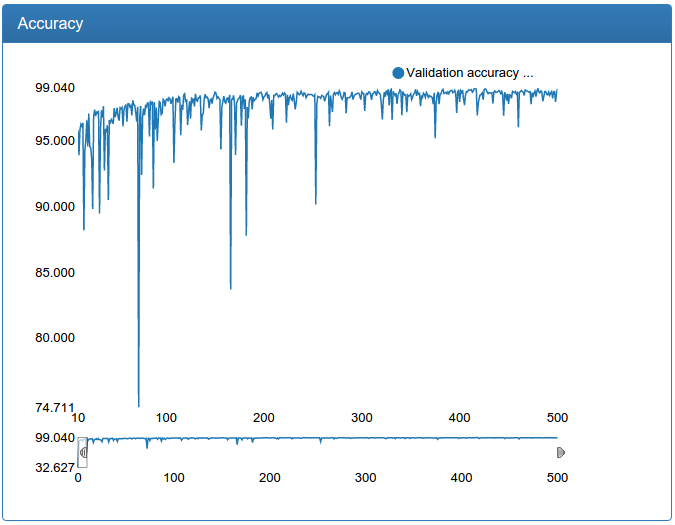

Here, it is clearly seen how dumb bursts appear in the learning process (why it will be next), but in the end everything becomes more or less good, although it is still a little more talkative.
In the following series:
Even more data, even more networks, calibration, mind-blowing ensembles of networks, modern technologies, more pictures, girls and drama!
Source: https://habr.com/ru/post/277267/
All Articles