Not neural networks at all

Recently, ZlodeiBaal wrote about achievements in convolutional neural networks (CNN) (and, by the way, he immediately set up and trained the network to find the area of the license plate ).
And I want to tell you about a fundamentally different and, probably, more complex model that Alexey Redozubov ( AlexeyR ) is currently developing , and about how we, of course, having ignored some important elements, and used it to recognize automobile license plates!
In this article, I will somewhat simplifiedly recall some points of this concept and show how it worked in our task.
')
If you spend a little time reading the latest news from neurobiology, then anyone who is familiar with computational neural networks will be somewhat uncomfortable. Moreover, a paranoid thought may appear: “it may be for nothing that they try to assemble AI from neurons, maybe the neurons are not the main ones there?” It was easier to examine the neurons because of their electrical activity. For example, there are much more glial cells than neurons, and with their function not everything is clear.
And it does not leave the general impression that those who are engaged in deep learning use the ideas of scientists of the 40s-60s, slowly, especially in the vast array of studies of neurobiologists.
AlexeyR swung at the concept of the brain, consistent with a little more modern studies of neuroscience.
For me personally, an important test of the adequacy of an idea is its constructiveness. Is it possible to arm yourself with this idea and build something really working?
Here I will try to convince you that the concept is constructive and very promising, including from a practical point of view.
To begin with, I will give my interpretations of the basic positions of Redozubov’s ideas, which seem important to me:
Non-classical neuron and wave identifiers
Scientists have long noticed that there are also metabotropic detectors on the body of a neuron outside the synaptic clefts, which are not obvious what they are doing. Here you can put on them the original mechanism for memorizing the strictly defined activity surrounding this detector. When this occurs, a single spike of the neuron (it is called spontaneous), on which this detector is located. This not tricky mechanism allows you to memorize and spread a unique pattern of information wave. In this series of articles you can find the source of this model. In general, this is very similar to the spread of rumors in a social group. It is not necessary for everyone to live side by side and get together so that information spreads. It is only important that the ties with the neighbors are rather dense.
Honestly, I am infinitely far from cell neurophysiology, but even after reading the article on the wiki , I can allow the existence of a different way of transmitting information other than synaptic.
The second, following from the first
Different areas of the brain are not connected by a large number of axons. Of course, there is darkness there, but certainly not from every neuron to every neuron at the next level, as is customary in computing neural networks now. And if we have learned to distribute unique wave identifiers, then we will communicate between zones using such discrete identifiers. All information processed by the brain will be described by discrete waves-identifiers (simply numbers), for example:
- position (say, the position of the object projection on the retina);
- time (the subjective feeling of time by man);
- scale;
- sound frequency;
- Colour
etc.
And we will use the package description, i.e. just a list of such discrete identifiers to describe what the zone recognized.
Third
Here everything is upside down as to what everyone is used to from Hubel and Wiesel
A little excursion into the history:
In 1959 Hubel and Wiesel set an interesting experiment. They looked at how neurons respond to various stimuli in the visual cortex of the first level. And found some organization in it. Some neurons responded to one tilt of the visual stimulus, others to another. Moreover, inside one minicolumn (vertical structure of 100-300 neurons in the neocortex), all neurons responded to the same stimuli. Then there were hundreds, if not thousands, of studies already with modern equipment, where selectivity was not found for anything only in different zones. And to the slope, and to the spatial frequency, and to the position, and the speed of movement, and to the frequency of sound. What parameter relevant for a given part of the brain was not set, we definitely found some selectivity.
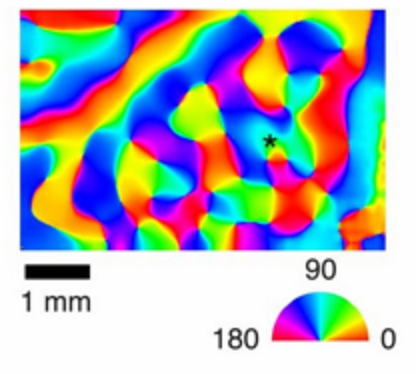
Visual Cortex Zone V1
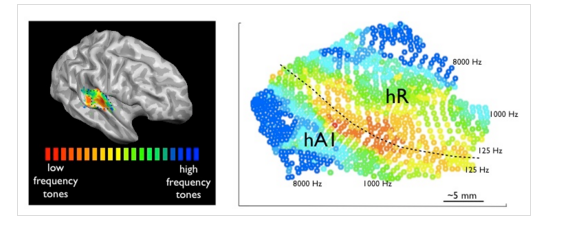
Depending on the frequency of the sound A1
And it is quite natural to conclude from this that neurons, as they learn, change synaptic weights so as to recognize the line or boundary of a certain inclination in their receptive zone. Following these ideas, Lekun and built convolutional networks.
But it will be much more effective, says Alexey Redozubov, if this mini-column remembers not a specific feature at all, but a context. The context, for example, is the angle of rotation. The second context is the position, the third is the scale. And the features will be generally common to some neighborhood on the bark.
Thus, we need self-organizing maps not for the input image (in the visual cortex), but for self-organizing maps of various contexts relevant to the visual cortex. At the same time, the proximity of these contexts can be estimated either due to their temporary proximity, or due to the proximity of identifier codes.
And why do we need this complexity with the context? And then, that any information we deal with looks completely different depending on the context. In the absence of any a priori information about the current context in which the observed entity is located, it is necessary to consider all possible contexts. Than in the framework of the proposed model, the minicolumns of the neocortex will be engaged.
Such an approach is only an interpretation of the same hundreds or thousands of experiments about self-organization in the cerebral cortex. Two results cannot be distinguished in the course of the experiment:
1) I see a tilted 45 degree relative to the vertical.
2) I see a vertical border inclined 45 degrees.
It seems that this is the same thing. But in the case of a second interpretation, it is possible to detect exactly the same activity in the same mini-column, if we show, say, a person’s face: “I see a vertical face tilted at 45 degrees”. And the zone will not be limited to the perception of only one type of objects.
On the other hand, the context and recognizable phenomenon will change places in another zone. For example, there are two ways in which visual information is analyzed: dorsal and ventral . For dorsal stream, the context is location in space, direction of movement, etc. And for ventral stream, the context may be the characteristics of the observed object, even the type of the object. If one of the visual processing streams is damaged, the person will not become blind. There will be problems with the perception of several objects at the same time, but over time, the ability to perceive and interact with several objects partially returns. Those. A good description of the object is obtained both in the “dorsal stream” and in the “ventral stream”. But it is better not to be ill at all and, on the one hand, to consider various hypotheses on the position, orientation, and on the other, the hypotheses of the type “I see a person”, “I see a head”, “I see a chair”. Tens of millions of those and other hypotheses are simultaneously analyzed in the optic tract.
And now, actually, about the license plate recognition algorithm, which is based on the ideas of AlexeyR .
License plate recognition
I will begin with examples of license plate recognition.

By the way, here the number boundaries are not used, i.e. This recognition method is generally a little like the classical algorithms. Due to this, precious percentages are not lost due to the primary error in determining the boundaries of the number. Although, with this approach, nothing would be lost.
Architecture
To recognize license plates, we used 2 zones:
1) The first zone recognized everything that looked like letters and numbers in a car number.
Input information - images.
There were 5 parameters, according to which the whole zone was divided:
- position on X
- position by Y
- orientation
- scale along the X axis
- Y scale
As a result, about 700,000 hypotheses came out. That even for a video card on a laptop did not become a big problem.
zone exit - view description:
sign such and such, position, orientation, scale.
output visualization:

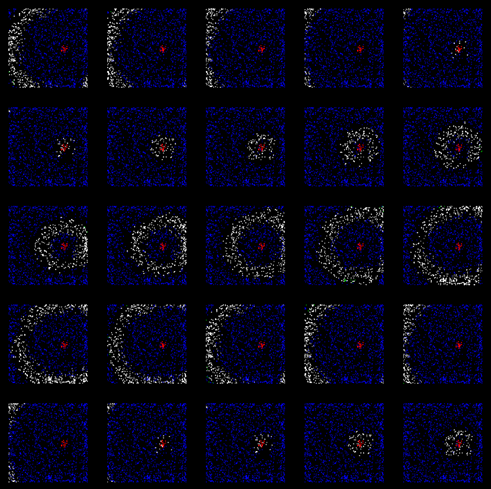
It is noticeable that not all the signs could be recognized at this level, it was full of false positives, if the number was rather dirty.
2) Second zone
input information - the output of the first zone.
Engaged in promising transformations. The hypothesis was about 6 million. And the only stable pattern that was recognized here was a car number in the format of 6 characters of a larger scale on the left and 3 characters of a smaller one on the right.
All possible perspective transformations were checked. In one of the variants, the signs from zone 1 “put together” in the best way possible in the pattern of the license plate known to us. This maximum and won.

But we know in what contexts there should be signs for a given perspective transformation, so we can project them back to the first zone and find the correct local maxima in the space of the first zone.

The execution time of this algorithm was about 15s on the not the fastest NVIDIA GF GT 740M.
More recognition examples

Particularly indicative are 3 and 4 columns of license plates.
You can close half (and even more) of the sign, but the only correct hypothesis about the position and orientation of the car sign will still be chosen, since we know his model. This is a fundamental property of the human brain - only by several signs (sometimes mistakenly) to recognize objects and phenomena.
And in the fourth example, due to the imperfect work of the first zone, most of the figures were “lost”. But again, due to the idea of how the car number looks like, the hypothesis of a perspective transformation was correctly chosen. And already due to the back projection on the first zone of information about where signs should be, the number is successfully recognized! Some of the information was lost, but recovered due to what we know - “there must be numbers and letters”.
Training
Directly in the example, the training was carried out, on the one hand, the simplest: “once shown and remembered”. On the other hand, in order to get a strong recognition algorithm, it was enough just to show 22 characters for the first zone and one car number for the second zone. This is super fast learning. Thousands of images were not needed.
Of course, the data were not noisy with noise, all the relevant signs were determined in advance, therefore, in this implementation, the self-study did not develop fully.
But the concept has an unusual and powerful self-learning mechanism. More precisely, there is a need to teach two things:
1) How the same features are transformed in different contexts. And to answer a no less difficult question: what is the context for this zone? Intuitively, it seems that for sound is frequency and tempo. For movements - the direction of movement and pace. For images - for which zone of 2D transformation, for some already 3D.
2) Find stable situations, i.e. a set of features that often appear in different contexts.
Over the past few months, something has turned out to be done in the direction of self-study. For example, when working with visual images, an object simply appears twice in the frame in a different context (scale, orientation, position) and it is possible to obtain its portrait, which is then suitable for recognition, despite the rather complex background and noise. All this looks like super-fast self-learning.
Unfortunately, a detailed description of self-learning mechanisms will remain outside the scope of this article.
And what about the convolutional networks of Jan Lekun?
Convolutional networks (CNN) also fit perfectly into this model. Convolution with cores is made for each position X, Y. Those. at each level, in each position, one of the memories (cores) is sought, so the position is the very context. And even the location of close positions is necessary, since This is used at the next downsample level, where a local maximum of 4 points is selected. Due to this, it turns out to train the neural network at once for all positions on the image. In other words, if we have learned to recognize the cat in the upper left corner, then we will definitely recognize her in the center. It is worth noting that we cannot immediately recognize it, rotated 45 degrees, or of any other scale. A large training sample will be required for this.
Convolutional networks due to such a mechanism, devices have become a very powerful tool in capable hands. But there are several drawbacks that are compensated by various methods, but are fundamental:
- only the context of the situation has been fixed, although even when working with images, orientation, scale, perspective, movement speeds when working with video and other parameters are important;
- so it is necessary to increase the training sample, since the convolutional network does not have a transformation mechanism, except for displacement, and hope that the rest of the patterns will “emerge” after a long training;
- there is no mechanism to “memorize everything”, only a change in weights. Once seen, it will not help with further training, which means that the training sample needs to be properly organized and, in any case, increased again. In other words: the memory is separated from the architecture of CNN.
- loss of information during downsample and subsequent upsample (in CNN based autoencoders), i.e. if you build feedback or reverse projection in CNN, then there are problems with fidelity;
- each next level continues to operate with spatial invariance “in the plane”, and at the highest levels, due to the lack of constructive ideas, they again come to, for example, fully connected architecture;
- it is rather difficult to track and debug those “models” that were formulated during the training, and they are not always correct.
It is possible to strengthen convolutional networks, for example, to “sew up” some more parameters, except X, Y. But in general, it is necessary to develop not the simplest algorithms for the self-organization of a context map, to organize a “reinterpretation” of memories, a generalization in different contexts and much more, which is not quite similar to the basic ideas of CNN.
Conclusion
One example with the recognition of numbers, implemented in a very curtailed manner, of course, is not enough to say that we have in our hands a new constructive model of the brain. Just try the pen. There is still a lot of interesting work. Now AlexeyR is preparing examples with classic MNIST on one zone, self-learning of several zones for speech recognition. In addition, we learn to work with less structured information — people's faces. There can not do without a powerful self-study. And it is these practical examples that make literally every 2 weeks revise some details of the concept. You can talk as much as you like about a slim concept and write excellent books, but it is much more important to create really working programs.
As a result, step by step, there should be a sufficiently developed model, which will be much more universal than the existing CNN or, say, RNN in relation to the input information, sometimes learning from just a few examples.
We invite you to follow the development of the model in this blog and blog AlexeyR !
Source: https://habr.com/ru/post/277163/
All Articles