From FineReader to data entry solutions: how the direction of DataCapture in ABBYY began
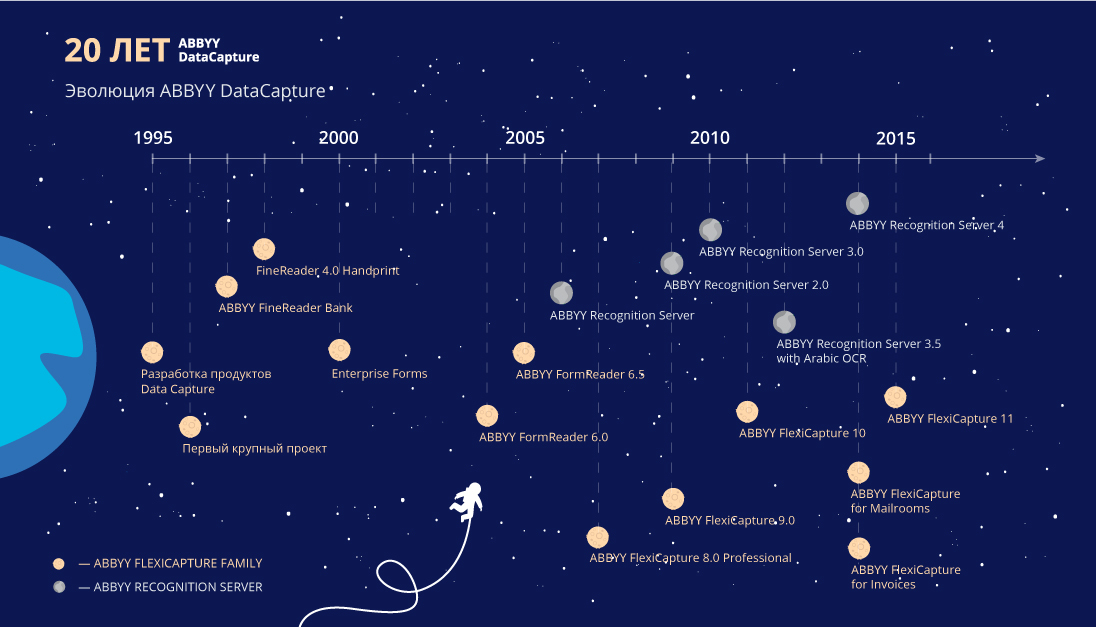
Many people know ABBYY, first of all, thanks to our mass programs - Lingvo, FineReader, various mobile applications. But at the same time, corporate direction has been and remains very important for us. In particular, on the basis of our text recognition technologies, we have created solutions for streaming the entry of documents and data. They are needed by all organizations dealing with large volumes of documents - from banks and insurance companies, to government departments, oil, energy, retail and many other companies. Recently this direction in ABBYY is 20 years old.
In the life of any technology company there are periods when the ball is ruled by developers. In mid-1995, the company Bit, as ABBYY was called before it was renamed in 1997, was dominated by an atmosphere of technological revolution. We just released a new version of FineReader 2.0 with a breakthrough recognition technology, written almost from scratch, and the product was gaining recognition before our eyes, winning tests and causing excitement among users. It was then that we decided to invest seriously in the program shell, since it has remained almost unchanged since the first version. The shell of version 3.0 was supposed to be large and spreading, as it was supposed to be a serious application at that time, and in the maximum configuration it had to provide rich functionality. The developers decided that in addition to books and office texts, we need to learn to introduce two more types of documents: printed forms and tabular reports from databases. Thus, in the bundle of FineReader, in addition to Standard and Professional versions, an Enterprise version appeared where these two functions were added.
')
Now I would never have taken up that, because it was insane. Our products solved the problem of entering the documents described above purely hypothetically: for all the development time, we have not seen a single real user who needs it. These users appeared later when they brought their real documents, and we realized that we still need to work and work. In particular, as it turned out, the task of entering such documents in reality is relevant only when there are many of them. And when there are a lot of them, then a “boxed” product working on one computer cannot be done here - we need a distributed system with many workplaces. And still need to be able to support high-speed scanners. And a lot of other things that our system did not know how then. Not to mention that the forms were mostly filled in by hand at that time, and FineReader was able to recognize only printed text.
Despite all these features, over time, we had the first clients. Among them were large Russian organizations that largely predetermined the development of the direction of stream data entry into ABBYY.
For example, at one time there was a now disbanded structure, which was called the "Tax Police". In the "dashing nineties", when large tax frauds were a mass phenomenon, people with weapons and appropriate powers were required to identify and neutralize various well-defended crooks, like all sorts of "lanterns" engaged in large cash withdrawal bypassing the law and the banks that kept them. Somehow they came at the beginning of 1996 to us, but not with verification, but with a problem. They regularly had operational tasks on working with primary documentation - payment orders, to identify schemes for circumventing laws and accumulating evidence. The tasks had to be solved quickly, until the suspects covered their tracks and disappeared behind the cordon. The bills were of terrible quality, some of them were typed on a typewriter on forms, and the forms differed in size and location of the fields, some - on dot-matrix printers on plain paper. Our technology team in record time, literally in 8 months, managed to create from scratch the technology of searching and extracting fields on such forms, which became the basis of the FlexiCapture technology.
It is appropriate to note here that initially our technologies were able to extract data from the so-called “hard”, standard forms. All copies of such documents before filling are the same, as they say, “on the light” - if you put them on each other, then the same fields will be in the same place. It is enough to determine the coordinates of these places - and when processing the values of the fields will be recognized. Everything is easy and clear. But not always the situation is so simple. Many of the documents from which you want to extract data are not rigid forms. So the bills that had to be processed by the Tax Police did not have a standard form: they were very different in clearance, not to mention the fact that some data could only be found by content. To extract data from them, we created a flexible description that allows you to operate not with the coordinates of the fields from which you need to extract information, but their location relative to the reference elements and each other, as well as the type of data to be recognized and their possible structure.
The form of the payment order has changed several times. At first there was an old Soviet one, then it was altered a little and allowed to print on blank sheets of paper, and then the Central Bank, tired of the constant need to cram modern data into an outdated format, once and for all changed the format of the payment order. Then it just mutated slightly: additional fields appeared, but the logic of the location of the information was preserved, so our “flexible” descriptions continued to work and the data was extracted correctly.
A little later, a similar task arose in the tax office. All sorts of investment funds that appeared while the mushrooms after the rain, huge trailers brought back sheets of paper on which faded inks using the dot-matrix printer printed reports on the income of their endless shareholders. With their considerable revenues, taxes were to be paid, and this had to be controlled. Therefore, we faced the task of entering data from all these forms back into computers. Here the same technology came in handy, which so far helped the Tax Police. The product that included this technology, we inside the company called FineReader Reference. It was a piece of the future FormReader.
The second piece of the FormReader came from another story. Somewhere in the year 1996, at about the same time as the Tax Police, the Pension Fund turned to us with the task of entering forms.
In 1995, the Pension Fund decided to centrally store information about Russian citizens. All working citizens had to fill out questionnaires with their personal data, and companies every six months should send to the Pension Fund information about the salaries paid to their employees. All information was collected in the regional offices of the Pension Fund, entered into a computer and sent to the central database. All this gigantic volume - about 150 million forms - was supposed to be processed by law in the first two months of the year.
At the Pension Fund, at first there was one document that we, in fact, developed, was called the “Insured Questionnaire”. It was a one-page document, and it had to be submitted only once for each person. Now only a small picture was at hand - just so you could get an idea about this antiquity.

All these forms were filled out by the hands of citizens who intended to entrust their savings to the Pension Fund. There was no alternative. And this meant that we would have to take into account in this way the entire able-bodied population of the country — almost 70 million citizens.
The scale struck the imagination, and we set to work. As a result, another project appeared - FineReader Vector, which included, in addition to the recognition of printed forms, the ability to enter forms filled with block letters by hand. The forms, however, in contrast to the Etalon project, were supposed to have fixed, that is, the fields did not need to be searched for - they were always in the same places on the page. As a result, the pension fund did not wait for the appearance of the final product capable of introducing all 70 million forms throughout the country, and we managed to deliver it only to a few large regions. In other places, persistent and hardworking employees of the foundation have nothing to do and entered all forms manually. The poor ones.
Then the second form was required, which already came to the Pension Fund every year, was called “Individual data on the income of the insured person”, we also developed it for the Pension Fund. At first, this form was designed for handwritten completion, then programs appeared that learned to type data into it, and at the same time the pension fund came up with a way to accept this data on diskettes. I remember how the queues of accounting staff lined up at the offices, one after another shoving data and viruses onto a pensive drive 1.44 inches, and then retreating in the hope that the data were right there. It was tiring, so many, if the law allowed (and he demanded electronic data with a certain number of employees), preferred to bring handwritten papers. Now everything has long been wrong, and almost no one uses paper forms, but then whole warehouses were filled with them.
The ABBYY FormReader interface looked like this:

A little later, on the basis of the Etalon project, a successful product of FineReader Bank appeared, which allowed bank operators to instantly enter payment orders. Today it is almost a wonder - companies send bills electronically, and in those days paper bills were the main means of transferring money. The FineReader Bank operators were loved very much - it made their lives much easier for them, eliminating the need to knock on the keys from morning to evening.
The first FormReader, combining the results of work on these two projects, grew out of the boxed FineReader, and by itself was poorly suited for mass input tasks. Therefore, we had to make an add-on to it, which allows many people to work in one system. All this was cumbersome and did not have great technological prospects, so at some point we decided to create a new product from scratch, originally sharpened for distributed work, scaling and other enterprise requirements.
Thus, in 2007, 10 years after ABBYY began to work seriously on the mass data entry market, FlexiCapture came into being - the technology he inherited from FormReader, but was written entirely from scratch. But everything turned out to be not so simple - so that users could switch to it, it was required to cover all the possibilities of the previous product, which had been developed for many years. It took two years for the new product to completely replace the old FormReader with the advent of FlexiCapture 9.0.
This is what the interface of the eighth version of ABBYY FlexiCapture looked like:


FlexiCapture was the first independent solution to the direction of DataCapture in ABBYY and from the very beginning was focused on the global market - its sales began simultaneously in all major markets - in the USA and Western European countries. Conquering the market for mass data entry is difficult - it is very conservative. On such large and difficult tasks, people do not want to risk, and therefore rely, perhaps, not on the most progressive, but well-proven solutions. Over the 7 years of its existence, FlexiCapture has already become a basic solution, and is used in the most large-scale projects around the world, such as population censuses and other large government projects, automation systems for entering corporate-level documents in large international concerns, etc. ”.
Modern ABBYY FlexiCapture is constantly improving and is learning to solve all new problems. Today, it helps not only to extract data, but also to classify it, and besides a computer, you can work with the solution through a mobile client in the cloud. It is difficult to imagine that once, this important direction for companies today began with the ambitions of a young team and its desire to prove that technology can be more effective than hundreds of typists.
And finally, some statistics. Over 20 years of existence of ABBYY data entry products:
• More than 90 thousand organizations worldwide have become our clients. Among them are Deloitte, PepsiCo, Fuji Xerox, Allianz, L'Oréal, VTB, Sberbank, Alfa Bank, Raiffeisenbank, MMK, Ingosstrakh, SIBUR, the Ministry of Health of the Republic of Bangladesh, the National Assembly of Ecuador and many, many others.
• With our solutions, organizations annually process more than 800 million pages. This is a stack of papers 100 km high!
Source: https://habr.com/ru/post/277081/
All Articles