Neurorevolution in heads and villages
Recently, more and more often you hear the opinion that a technological revolution is taking place now. Argued that the world is changing rapidly.

In my opinion this is really happening. And one of the main driving forces is the new learning algorithms that allow processing large amounts of information. Modern developments in the field of computer vision and machine learning algorithms can quickly make decisions with accuracy no worse than professionals.
')
I work in the field of image analysis. This is one of the areas that new ideas have touched the most. One of these ideas is convolutional neural networks. Four years ago, with their help, they first started winning image processing contests. Victory did not go unnoticed. Tens of thousands of followers began to engage and use neural networks, which until then had been on the sidelines. As a result, a boom a year or two ago began, which gave rise to many ideas, algorithms, and articles.
In my story, I will review the ideas that have appeared over the past couple of years and have hooked my subject. Why is happening - the revolution and what to expect from it.
Who will lose ten jobs in the coming years, and who will have new promising vacancies.
At the head of the ongoing revolution are several types of algorithms. The flagships are neural networks. About them there will be a speech.

Neural networks have appeared long ago. Back in the forties. The idea is simple: the best decision-making machine is the human brain. Let's emulate it. The idea is really awesome and simple. That's just all stumbles on the implementation. Neurons in the human brain ... Ghm. Lot. And the architecture is confusing.
Starting in the forties, every couple of years another breakthrough came in computing technology or in understanding the brain. And immediately the wave was rising: " Finally, neural networks will work! ". But after a couple of years, the wave went into decline.
When I was studying at senior courses (2007-2010), the generally accepted opinion was: " Yes, you got your neural networks! They do not work! They checked them ten times already. Take SVM, Random Forest or Adaboost! Easier, clearer, more accurate ." In a special honor were purely mathematical solutions of problems, when everything could be painted through a likelihood formula (such a solution, of course, cannot be surpassed).
What happened that by 2012 the neural networks were able to scatter and break all the Olympus? In my opinion the answer is simple. Nothing. Powerful enough video cards on which you can program by the time were already 8-9 years old. The ideas that made the breakthrough were sown in the late 80s and early 90s. CUDA appeared, but there were tools before it.


Just there was a systematic increase. Ideas that ate too much computing power in the 90s became real. Writing under the video card has become easier. Word by word, article by article, eye for eye. And suddenly, in 2012, the ImageNet contest wins the convolutional neural network . It does not just win, but with a separation from the nearest pursuer twice.

This is such a big, big base of words and pictures attached to them. Consisting of everything: objects, structures, creatures. Pictures can be a dozen, and maybe thousands. Depending on the complexity and prevalence of the concept:



Every year a competition is held on it. What percentage of concepts can the system recognize. The terms of the contest vary slightly, but the idea remains the same.
You, for certain, saw pictures with recognized objects from this base:

The topic is long. If interested - the best read articles: 1 , 2 , 3 .
In short. Convolutional networks, these are neural networks, where "convolutions" are the main element of learning. Convolutions are small pictures: 3 * 3, 5 * 5, 20 * 20. And at every level of the network dozens of them are trained. Besides them, nothing is learned. We teach the network to find such "convolutions" that maximize information about the image. This is the structure of such a network:

At the same time, such convolutions start working as cool feature detectors at once on many levels of depth and meaning. They can find both small features, and big, global. After filtering it looks something like this:

The convolutions themselves will, for example, be:

Or such:

And in dynamics the process will look like this:

Good criticism is in the article rocknrollnerd . Or here .
In short. What the network sees is we do not know. She does not “understand”, she “finds patterns”. No matter how insane they are. It is easy to deceive her, if these patterns are revealed. For example, these are the numbers 1-2-3-4-5-6-7-8-9 with a probability of 99.9%:


Does not look like it? Convolution networks are considered otherwise.
All that was above is the introduction to the article. And now the promised revolution. Where did the breakthrough happen and what does it lead to.

The breakthrough is that people began to analyze and understand what these "convolutional networks" are. As a result - ask them the right questions.
Consider the “outdated algorithms” (it’s ridiculous to say this about ideas that are often ten years old), which have been searching for objects in the image. For example, a person (HOG), a person (Haar), or some more unique objects (SIFT, SURF, ORB):

In essence, the selection of primitives characteristic of the object in question, which we analyze, is used. The analysis can be made by some kind of automatic decision making system (SVM, AdaBoost), or by the person himself, by setting simple rules (via SIFT, SURF). Here is a good lecture by LeKun (the author of convolutional networks).
The first time after the appearance of the convolutional networks, they worked this way: the region was taken, its analysis was carried out, the decision was made whether there was a desired object in this region (for example, like this ). Convolution networks allocate more generalized primitives, and by them we have already looked at the object:

It turned out quite slowly + write a lot of logic.
But can not the convolution network find an object for us? Why bother with logic, with windows, with analysis?
It turns out it can. And in my opinion it is VERY cool. As an example, I like this article. In it, the neural network is trained to issue an x, y, w, h object. Simple and tasteful. One run of the network - all objects in the frame are found and marked. No need to run the network in different areas. And really, what's the difference: to train to issue an object class, or to teach to issue a class + parameters? The main thing is for each class to have a place in the output neurons, where one could put an answer:

At the output of the network, the volume of the size ((Number of classes) * 2 + 5 * 2) * 7 * 7. If there are 10 classes, then the volume is 30 * 7 * 7. Here 7 * 7 is the spatial coordinate. In fact, such a reduced image. For example, the 4 * 4 point is the center of the picture. At each such point we have 30 quantities. 10 of them to designate an object that is located at a point (the class of this object has a value of 1, the rest is 0). 4 more values - x, y, w, h of the rectangle at the point that determines the size of the object, if it is there. Another one is the confidence coefficient. The remaining 15 is a repetition of all that in case there was a center of two objects in one segment. Total is obtained:
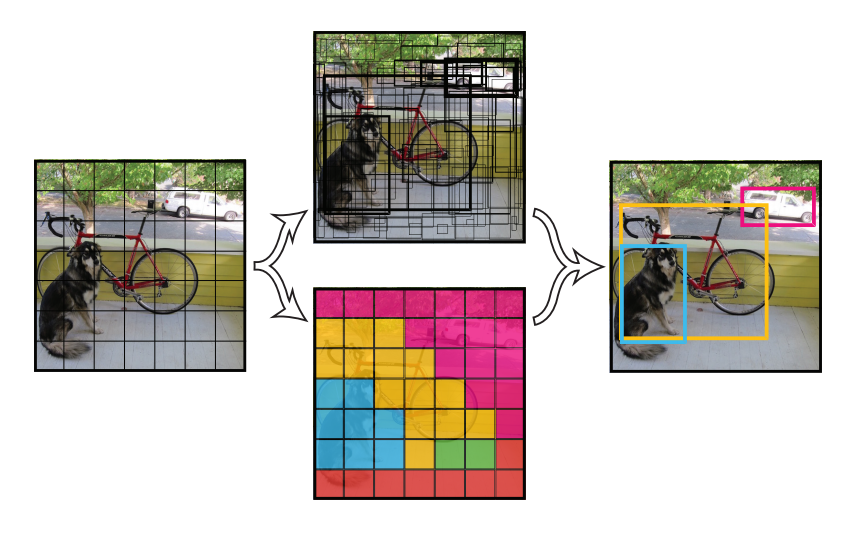
On the project site you can watch a lot of interesting videos:
Is it possible to submit to the network input a priori information different from the image? Of course! The main thing is to choose the network architecture, for example :
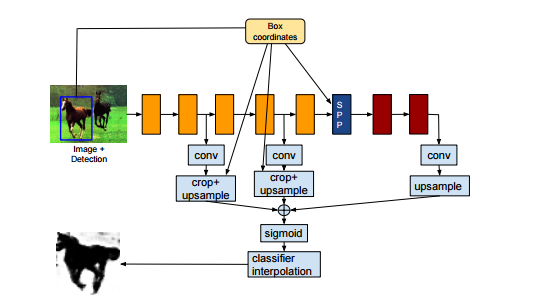
Here at the entrance of the network serves the image, as well as the approximate area where the interesting object is located. The network is learning to produce accurate crop + segment object. Now your network eats a priori data, determining for itself what it is and what to do with it.
In my opinion, these ideas are a breakthrough that allows you to completely get away from the old ideology of algorithms. Previously, everything was separate: logical data, images, connections. And now everything can be thrown into a common pot without much thought (yes, I lie, I lie, I need to think a lot - over the formation of the base, for example ). The main thing is to understand the sufficiency of the data. No need to understand at what stage of the algorithm is optimal what to combine. The network itself optimizes the interaction of data streams.
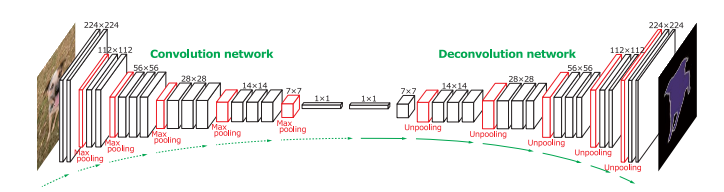
But this is not all that has become clear in the last two or three years. The second conceptual observation is that the network is a non-linear filter. Yes, it was known forty years ago. But only now it became clear what this means and what it leads to. The network can filter the input data and output both logic and an image at the output (or all at the same time).
The resulting logic or images can be input to other algorithms. Or at the entrance of the person.)
Let's start with the last job , which even seemed to skip the news. The network makes video markup from the DVR according to the type of object: “road”, “pedestrians”, “signs”, “marking”, etc.
Data that is so received can be submitted to the vehicle orientation input. This is a fundamentally new solution. Until now, object classification systems for automatic cars have been fundamentally different. They demanded lidars or at least a stereo camera.
Do you think this system is complex and monstrous? No, just a few trained layers, set up in a couple of days:

Direct conversion of data in response. Frames are processed quickly. On a laptop four years ago about a second per frame. On a more or less adequate computer - realtime.
There are several other networks that solve similar problems with a slightly different architecture (many of them were earlier than SegNet, but on the whole they worked worse): 1 , 2 , 3



Now neural networks solve problems and tasks that five years ago required a huge amount of power and were the result of the work of entire groups of scientists.
Surely many of you know that with two cameras you can restore the three-dimensional image. Teach the network to build it ?

This approach is good because the network itself will guess in which situations it is better to approximate by plane, and in what situations it is better not necessary. Yes, and to teach such a network is simple. Take a walk a couple of days with a stereo camera, dial a video. And the grid is not much more complicated than the ones above:

Optical stream is almost the same stereo match, right? Only now they decided to train with computer games:

I do not know how this works in practice, but the idea is cool.
Have you ever used Canny filtering in OpenCV? Surely you know that it is very difficult to choose its sensitivity so that it is the borders that stand out, and not any noise?



Here are three articles on how to do it differently, so that the result was the same and did not confuse you: 1 , 2 , 3

Well, yes, where do without it. A couple of weeks ago, a network for coloring old B & W films was slipping:

Not perfect, but funny.
It seems to me that soon Photoshop will acquire a number of new plug-ins ...

This is only a small number of networks and ideas. Their number is growing every day. Now there is a total breakthrough in medicine. Have you seen kaggle contests? How does the retina recognize diseases ? And what happens behind the scenes is generally scary. We have done knee photofluorography recognition in a week. Let it be bad, but it works. And here still the project raises the people. They assure that they can recognize everything medical, if only the base was.
And the number of Just For Fun applications will grow astronomically. Remember the application that the photos determine how old you are? Or your attraction? Wangju app appearances in the style of "look at yourself with a beard" or "turn me into Zeus."
In general, the convolutional networks and image analysis wherever there is. Even AlphaGo on their base analyzes the position in Go.
Do you really think that cars will not replace you? What is your area unique? Deep Mind system appeared in 10 year. A couple of years later, they began to address the “GO game” task. Four years later, they decided and are now challenging the world champion. For four years, even a child in Go will not be taught to play. Do you really think your profession is safe? What singularity is not here yet?
Everyone loves to joke about the fact that in a couple of years, as soon as the autopilot appears for cars, taxi drivers will start to burn cars, robots, like today they are burning “Uber” cars. Understand that many things will happen before that. Translators and legal assistants. Secretaries. Is your profession to decipher images? Radiologist? Cartographer? Will a video analytics specialist be needed in a couple of years, or will Google replace them with their services ?
Of course, the best translators will remain. As well as the best secretaries. Yes, and good radiologists, of course, will be needed (there must be someone to verify the diagnosis). Will remain all, whose specialty - the work of hands. For the time being, the mechanic is far from completely replacing surgeons and massage therapists (I think even 20-30 years will not even reach plumbers!). There will be professions that will manage robots and complexes from robots. There will be more people who will train the systems and support them. But medium and bad programmers, in my opinion, already in 5-10 years will begin to crowd the system of automatic programming.
In any case, we have to live in interesting times. And yes, while you slept the singularity is already here.
Well, I'm a little thicker, but in general, everything is fine, it will do for Friday.
If suddenly the topic is interested, then I advise a couple of places where information is much more than on a habr and is replenished regularly.
First, I like this community in contact. Yes, a lot of garbage, but practical things are almost never missed.
Secondly, about half of the above I took from here . There is much less information here, but they don’t miss the most valuable and interesting. Plus well structured.
Thirdly, SKolotienko also threw a good reference to the reddit.
And further. In order not to be unsubstantiated, my friend and I took one of the networks indicated here and tortured for a couple of weeks, forcing us to recognize what was coming to hand (since there were a lot of bases). Within a week, he will post an article with a bunch of sources and manuals. So watch out for Nikkolo . And Vasyutka for a couple of weeks wanted to publish some thoughts from the area where the neural networks intersect with sound logic.
In my opinion this is really happening. And one of the main driving forces is the new learning algorithms that allow processing large amounts of information. Modern developments in the field of computer vision and machine learning algorithms can quickly make decisions with accuracy no worse than professionals.
')
I work in the field of image analysis. This is one of the areas that new ideas have touched the most. One of these ideas is convolutional neural networks. Four years ago, with their help, they first started winning image processing contests. Victory did not go unnoticed. Tens of thousands of followers began to engage and use neural networks, which until then had been on the sidelines. As a result, a boom a year or two ago began, which gave rise to many ideas, algorithms, and articles.
In my story, I will review the ideas that have appeared over the past couple of years and have hooked my subject. Why is happening - the revolution and what to expect from it.
Who will lose ten jobs in the coming years, and who will have new promising vacancies.
Neural networks
At the head of the ongoing revolution are several types of algorithms. The flagships are neural networks. About them there will be a speech.
Neural networks have appeared long ago. Back in the forties. The idea is simple: the best decision-making machine is the human brain. Let's emulate it. The idea is really awesome and simple. That's just all stumbles on the implementation. Neurons in the human brain ... Ghm. Lot. And the architecture is confusing.
Starting in the forties, every couple of years another breakthrough came in computing technology or in understanding the brain. And immediately the wave was rising: " Finally, neural networks will work! ". But after a couple of years, the wave went into decline.
When I was studying at senior courses (2007-2010), the generally accepted opinion was: " Yes, you got your neural networks! They do not work! They checked them ten times already. Take SVM, Random Forest or Adaboost! Easier, clearer, more accurate ." In a special honor were purely mathematical solutions of problems, when everything could be painted through a likelihood formula (such a solution, of course, cannot be surpassed).
What happened that by 2012 the neural networks were able to scatter and break all the Olympus? In my opinion the answer is simple. Nothing. Powerful enough video cards on which you can program by the time were already 8-9 years old. The ideas that made the breakthrough were sown in the late 80s and early 90s. CUDA appeared, but there were tools before it.
Just there was a systematic increase. Ideas that ate too much computing power in the 90s became real. Writing under the video card has become easier. Word by word, article by article, eye for eye. And suddenly, in 2012, the ImageNet contest wins the convolutional neural network . It does not just win, but with a separation from the nearest pursuer twice.
What is ImageNet
This is such a big, big base of words and pictures attached to them. Consisting of everything: objects, structures, creatures. Pictures can be a dozen, and maybe thousands. Depending on the complexity and prevalence of the concept:
Every year a competition is held on it. What percentage of concepts can the system recognize. The terms of the contest vary slightly, but the idea remains the same.
You, for certain, saw pictures with recognized objects from this base:
What is a convolutional network?
The topic is long. If interested - the best read articles: 1 , 2 , 3 .
In short. Convolutional networks, these are neural networks, where "convolutions" are the main element of learning. Convolutions are small pictures: 3 * 3, 5 * 5, 20 * 20. And at every level of the network dozens of them are trained. Besides them, nothing is learned. We teach the network to find such "convolutions" that maximize information about the image. This is the structure of such a network:
At the same time, such convolutions start working as cool feature detectors at once on many levels of depth and meaning. They can find both small features, and big, global. After filtering it looks something like this:
The convolutions themselves will, for example, be:
Or such:
And in dynamics the process will look like this:
Criticism
Good criticism is in the article rocknrollnerd . Or here .
In short. What the network sees is we do not know. She does not “understand”, she “finds patterns”. No matter how insane they are. It is easy to deceive her, if these patterns are revealed. For example, these are the numbers 1-2-3-4-5-6-7-8-9 with a probability of 99.9%:
Does not look like it? Convolution networks are considered otherwise.
Breakthrough
All that was above is the introduction to the article. And now the promised revolution. Where did the breakthrough happen and what does it lead to.
The breakthrough is that people began to analyze and understand what these "convolutional networks" are. As a result - ask them the right questions.
Consider the “outdated algorithms” (it’s ridiculous to say this about ideas that are often ten years old), which have been searching for objects in the image. For example, a person (HOG), a person (Haar), or some more unique objects (SIFT, SURF, ORB):
In essence, the selection of primitives characteristic of the object in question, which we analyze, is used. The analysis can be made by some kind of automatic decision making system (SVM, AdaBoost), or by the person himself, by setting simple rules (via SIFT, SURF). Here is a good lecture by LeKun (the author of convolutional networks).
The first time after the appearance of the convolutional networks, they worked this way: the region was taken, its analysis was carried out, the decision was made whether there was a desired object in this region (for example, like this ). Convolution networks allocate more generalized primitives, and by them we have already looked at the object:
It turned out quite slowly + write a lot of logic.
But can not the convolution network find an object for us? Why bother with logic, with windows, with analysis?
It turns out it can. And in my opinion it is VERY cool. As an example, I like this article. In it, the neural network is trained to issue an x, y, w, h object. Simple and tasteful. One run of the network - all objects in the frame are found and marked. No need to run the network in different areas. And really, what's the difference: to train to issue an object class, or to teach to issue a class + parameters? The main thing is for each class to have a place in the output neurons, where one could put an answer:
At the output of the network, the volume of the size ((Number of classes) * 2 + 5 * 2) * 7 * 7. If there are 10 classes, then the volume is 30 * 7 * 7. Here 7 * 7 is the spatial coordinate. In fact, such a reduced image. For example, the 4 * 4 point is the center of the picture. At each such point we have 30 quantities. 10 of them to designate an object that is located at a point (the class of this object has a value of 1, the rest is 0). 4 more values - x, y, w, h of the rectangle at the point that determines the size of the object, if it is there. Another one is the confidence coefficient. The remaining 15 is a repetition of all that in case there was a center of two objects in one segment. Total is obtained:
On the project site you can watch a lot of interesting videos:
Is it possible to submit to the network input a priori information different from the image? Of course! The main thing is to choose the network architecture, for example :
Here at the entrance of the network serves the image, as well as the approximate area where the interesting object is located. The network is learning to produce accurate crop + segment object. Now your network eats a priori data, determining for itself what it is and what to do with it.
In my opinion, these ideas are a breakthrough that allows you to completely get away from the old ideology of algorithms. Previously, everything was separate: logical data, images, connections. And now everything can be thrown into a common pot without much thought (
Network as a filter
But this is not all that has become clear in the last two or three years. The second conceptual observation is that the network is a non-linear filter. Yes, it was known forty years ago. But only now it became clear what this means and what it leads to. The network can filter the input data and output both logic and an image at the output (or all at the same time).
The resulting logic or images can be input to other algorithms. Or at the entrance of the person.)
Let's start with the last job , which even seemed to skip the news. The network makes video markup from the DVR according to the type of object: “road”, “pedestrians”, “signs”, “marking”, etc.
Data that is so received can be submitted to the vehicle orientation input. This is a fundamentally new solution. Until now, object classification systems for automatic cars have been fundamentally different. They demanded lidars or at least a stereo camera.
Do you think this system is complex and monstrous? No, just a few trained layers, set up in a couple of days:
Direct conversion of data in response. Frames are processed quickly. On a laptop four years ago about a second per frame. On a more or less adequate computer - realtime.
There are several other networks that solve similar problems with a slightly different architecture (many of them were earlier than SegNet, but on the whole they worked worse): 1 , 2 , 3
Now neural networks solve problems and tasks that five years ago required a huge amount of power and were the result of the work of entire groups of scientists.
Stereo match
Surely many of you know that with two cameras you can restore the three-dimensional image. Teach the network to build it ?
This approach is good because the network itself will guess in which situations it is better to approximate by plane, and in what situations it is better not necessary. Yes, and to teach such a network is simple. Take a walk a couple of days with a stereo camera, dial a video. And the grid is not much more complicated than the ones above:
Optical stream
Optical stream is almost the same stereo match, right? Only now they decided to train with computer games:
I do not know how this works in practice, but the idea is cool.
Filtration
Have you ever used Canny filtering in OpenCV? Surely you know that it is very difficult to choose its sensitivity so that it is the borders that stand out, and not any noise?
Here are three articles on how to do it differently, so that the result was the same and did not confuse you: 1 , 2 , 3
Paint it
Well, yes, where do without it. A couple of weeks ago, a network for coloring old B & W films was slipping:
Not perfect, but funny.
Supersolution
It seems to me that soon Photoshop will acquire a number of new plug-ins ...
Others from the world of convolutional networks
This is only a small number of networks and ideas. Their number is growing every day. Now there is a total breakthrough in medicine. Have you seen kaggle contests? How does the retina recognize diseases ? And what happens behind the scenes is generally scary. We have done knee photofluorography recognition in a week. Let it be bad, but it works. And here still the project raises the people. They assure that they can recognize everything medical, if only the base was.
And the number of Just For Fun applications will grow astronomically. Remember the application that the photos determine how old you are? Or your attraction? Wangju app appearances in the style of "look at yourself with a beard" or "turn me into Zeus."
In general, the convolutional networks and image analysis wherever there is. Even AlphaGo on their base analyzes the position in Go.
Future
Do you really think that cars will not replace you? What is your area unique? Deep Mind system appeared in 10 year. A couple of years later, they began to address the “GO game” task. Four years later, they decided and are now challenging the world champion. For four years, even a child in Go will not be taught to play. Do you really think your profession is safe? What singularity is not here yet?
Everyone loves to joke about the fact that in a couple of years, as soon as the autopilot appears for cars, taxi drivers will start to burn cars, robots, like today they are burning “Uber” cars. Understand that many things will happen before that. Translators and legal assistants. Secretaries. Is your profession to decipher images? Radiologist? Cartographer? Will a video analytics specialist be needed in a couple of years, or will Google replace them with their services ?
Of course, the best translators will remain. As well as the best secretaries. Yes, and good radiologists, of course, will be needed (there must be someone to verify the diagnosis). Will remain all, whose specialty - the work of hands. For the time being, the mechanic is far from completely replacing surgeons and massage therapists (I think even 20-30 years will not even reach plumbers!). There will be professions that will manage robots and complexes from robots. There will be more people who will train the systems and support them. But medium and bad programmers, in my opinion, already in 5-10 years will begin to crowd the system of automatic programming.
In any case, we have to live in interesting times. And yes, while you slept the singularity is already here.
Little basement
If suddenly the topic is interested, then I advise a couple of places where information is much more than on a habr and is replenished regularly.
First, I like this community in contact. Yes, a lot of garbage, but practical things are almost never missed.
Secondly, about half of the above I took from here . There is much less information here, but they don’t miss the most valuable and interesting. Plus well structured.
Thirdly, SKolotienko also threw a good reference to the reddit.
And further. In order not to be unsubstantiated, my friend and I took one of the networks indicated here and tortured for a couple of weeks, forcing us to recognize what was coming to hand (since there were a lot of bases). Within a week, he will post an article with a bunch of sources and manuals. So watch out for Nikkolo . And Vasyutka for a couple of weeks wanted to publish some thoughts from the area where the neural networks intersect with sound logic.
Source: https://habr.com/ru/post/277069/
All Articles