MyHTML - HTML parser on the "bare" C with POSIX Threads support
Hello!
As it was possible to guess from the title, we will focus on HTML parsing (hereinafter referred to as html).
')
Preamble
Once I got the idea of "X", but for its implementation, you need a calculated DOM with all the styles and buns. Googling and Yandex showed nothing good. There are all sorts of wrappers for WebKit, but they do not work on all platforms, and very cropped. There are projects where WebKit is wrapped in a certain frontend with which you work via JavaScript. Something was tried, but the result was deplorable. Consumption of resources which only cost.
Wishlist
But I wanted, as it seemed, not so much:
- Renderer html without wild dependencies. Only a renderer, the network would fall on the user. In other words, the full calculation of html until drawing in the window.
- Ability to adjust wrapper for JavaScript engine
- The ability to easily make a wrapper for other programming languages
And I entered into an unequal battle!
Studied existing HTML and CSS (hereinafter cess) parsers.
Being a back-end developer, I was not always satisfied with existing HTML parsers. All of them were divided conditionally into three categories:
- Parsing as you please, having only your own idea about tokenization of html
- Somehow following the specification
- Parsing clearly following specifications
It would seem that there is a third point, and you can probably close the topic? But no, and here's why: all existing parsers are arranged according to the principle “Parsim and Dying”. This is when you give the program a whole html, the program returns the result and any subsequent manipulations are impossible, only reading. This fact greatly limits the scope of the parsers. It is worth making a remark, there are those who shift work with the DOM to a higher level. The meaning is this: parsim with a parser, and then through the wrapper we try to work with the DOM on, for example, Python, which is a little absurd.
Further, no one allowed to break into the stream (meaning html) at the time of parsing. This is extremely important for adjusting the JavaScript engine. I will not explain for a long time, but I'd better show you why:
Fragment of html document:
<script>document.write("<div cl");</script>ass="future"></div> The result of any browser with JS:
... <div class="future"></div> That is, in the end a full DIV element will be created. By the way, tokenization tag SCRIPT is still the case. I had to paint
scheme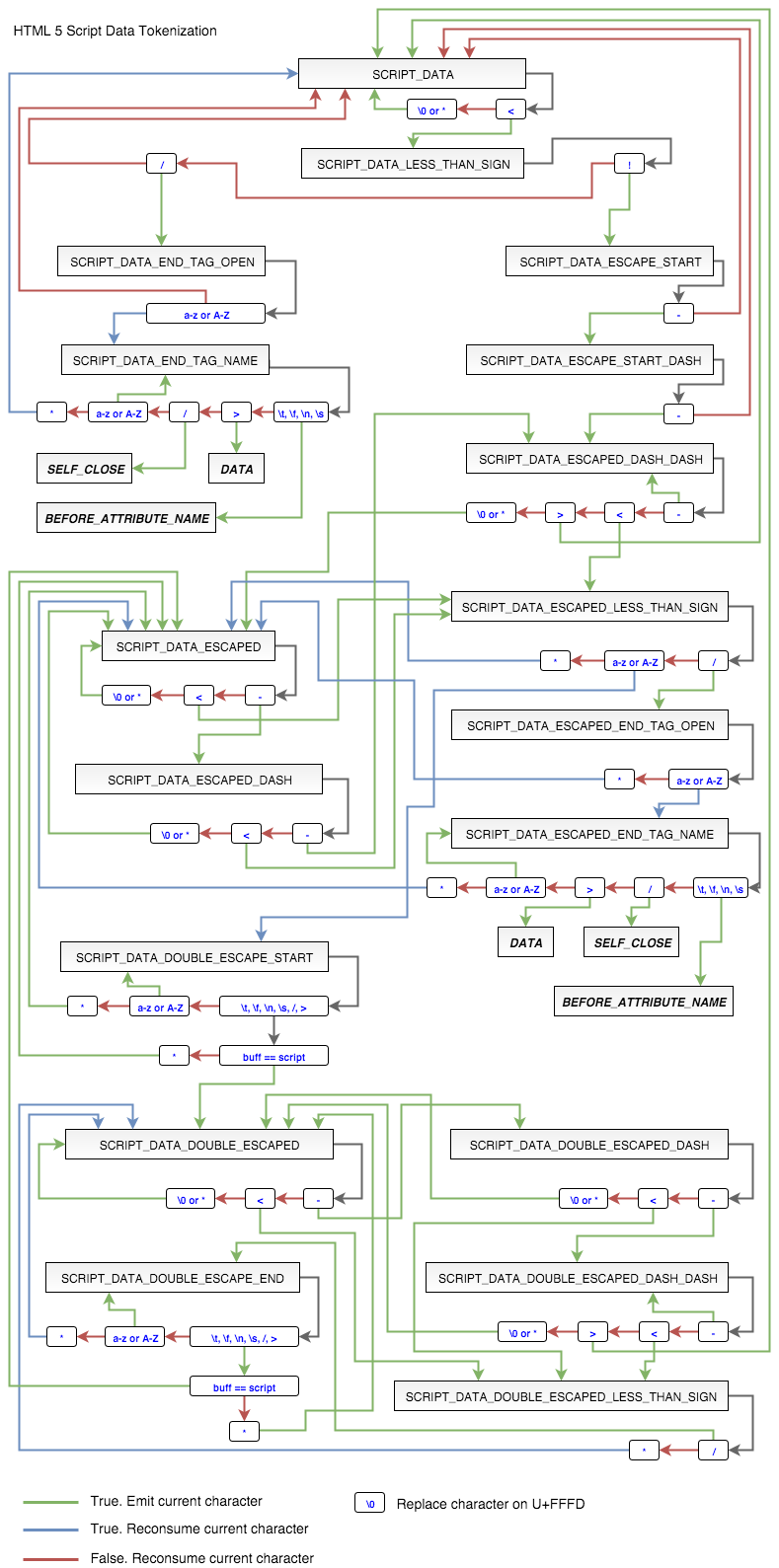
After all he saw, it was decided to write everything from scratch on C. The requirements for the code immediately arose:
- C99 support
- Ability to separate html parser from renderer to use separately
- No external dependencies
Why is it so tough right away - on Si ?! The solution must be embedded so that you can easily make a binding for a third-party programming language.
With varying success, it was possible to implement in draft form:
- Html parser
- Parser cess
- Selectors
- Inline Drawer, inline-block, block, table ...
You can write about the renderer for a long time, for the short phrase “Renderer of inline elements” there is not enough hiding: working with fonts according to the specification, calculating the size of the text, calculating the vertical-align, building an auxiliary tree for drawing the text, and a whole lot more.
In the end, after two or three years of slow development, I begin to convert the draft into a working one. The first, which is logical, was the html parser.
Now html parser has the following features:
- Asynchronously parse HTML, handle tokens, build a tree
- Full HTML 5 support to html.spec.whatwg.org/multipage specification
- We have two APIs: “High” level and “Low”. The first is a public api, which has a description and in general, everything is just like that of people, but does not allow seeing structures. The second is the use of source code directly.
- Ability to manipulate elements: add, delete, modify.
- The ability to manipulate the attributes of elements: add, delete, modify
- Supports 34 encoding per input. Only UTF-8 output, and all the work inside is only in UTF-8
- Can determine the text encoding. Unicode is now available: UTF-8, UTF-16LE, UTF-16BE (+ definition by BOM) and Russian: windows-1251, koi8-r, iso-8859-5, x-mac-cyrillic, ibm866
- Can work in Single Mode - without threads
- Parse HTML snippets
- Parsy chunks. You can give cut pieces of HTML (broken in an arbitrary place) and it will parse them without first accumulating the buffer.
- No external dependencies
- Supports C99
- Work with memory. Memory is cached, allocated in chunks and under objects. For example, deleting ten elements, and then adding ten others will not eat memory for new ones.
+ A whole bunch of small, but necessary pieces about which you can write for a long time.
Next up are the CSS parser and Render. I do everything alone, "gasoline" should be enough.
Any help is extremely welcome!
Thanks for attention! I hope you will be useful!
Actually the parser itself
PS: If the community shows interest in this topic, I can write narrowly focused articles on how the rendering calculation works and what difficulties I encountered / face.
Source: https://habr.com/ru/post/277031/
All Articles