Technosphere Mail.Ru - 2 years
Hi, Habr! In February, the Technosphere project is two years old. Over the past year there have been three major changes that have affected the learning process. The first of them concerned the selection of students - technical interviews. Previously, the student went to a technical interview, not knowing what tasks he would be offered to solve. Now we are sending students a case, a kind of technical problem, which needs to be solved in advance and on site to explain its solution to the teachers. After adding the case performance has improved dramatically. The transfer to the second semester in the Technosphere was 27 out of 40 students, that is 67% instead of the usual 40–50%.
Secondly, a laboratory was created at Technosphere, in which students are engaged in solving practical problems of the Mail.Ru Group, as well as external customers. For example, they investigate targeting algorithms for advertising campaigns, and also try to create heuristics that can improve the quality of advertising output. In essence, a laboratory is an alternative to an internship at a company. In it, you can work on solving various practical problems from the market, but at the same time, do not waste time traveling to the office, doing everything right in your department.
')
The third important step was the decision to switch to biennial training. This year we released the last group of guys who studied according to the annual program. The items that they mastered during the year were: algorithms for intelligent processing of large amounts of data, multi-threaded programming in C / C ++, DBMS, Hadoop, methods for processing large amounts of data and information retrieval.
Now we would like to put an end to the annual training program, showing you one of the graduation projects on the subject of “Information Search”. During the semester, the children were given homework, which eventually resulted in a large final project. The rules were as follows:
- The guys were divided into teams of 2-3 people.
- Task: to make a full search on one of the proposed sites. As planned, your search should consist of combined home + frontend + some kind of bun, for example spellchecker.
 Svyatoslav Feldsherov
Svyatoslav FeldsherovOur search engine worked on the site povarenok.ru . In our project, I was engaged in gathering all the components together and making the web. Initially, all the tasks on the course were in Python 2.7, and we, by inertia, somehow started to do a project on it. Therefore, to create a web application, we took Django. Now there is a feeling that it was a bust and it was possible to get by with something much simpler, but more on that later.
At the very beginning, we had a very simple idea: to take homework already written, glue them together and get an almost finished project. So we had the first search engine, on the project we called it a draft. At that moment, everything was very convenient: there was a Django application that was flying, a function was returned in the right place that returns search results, and a victory. But the whole construction started to slow down wildly when a popular word was requested on the full index. We had a couple of attempts to speed up Python, but nothing good came of it. Then Denis took and rewrote the entire search portion in C ++. Now, for my part, it all looked like this: try searching in a fast search engine, if it lies, go to the Python search, albeit slowly, but this is better than nothing.
Another epic happened with snippets and direct index. My first idea was to simply take the recipe summary and show it as a snippet. At first, it seemed to work well. But if you delve into the site, you can find something like this: “This recipe was announced by the author, a talented culinary specialist Olechka-Sarochka as“ The Most Delicious Tiramisu ”. And I did not change the name. How to avoid ... ". Such ingenuity of users ruined all my hopes for simple snippets. Somewhere by this time Daniel rolled out his snippet builder, and we again had some margin of safety: if the snippet builder fell, then look for a summary, and if it isn’t, then alas. By the way, it is here that Python 2.7 is especially good when you suddenly come across a broken encoding on a page.
The next thing I had to deal with was the spellchecker, but there everything was without any special adventures. And my last creation is the front-end to all of this, a large, time-consuming piece for us, but there is absolutely nothing to tell about it :). Who knows how, my bikes are not interesting to him, and who do not know how, we are clearly not the best example for training.
 Denis Kuplyakov
Denis KuplyakovMy part of the course work was to implement a boolean search with a ranking on this database of loaded pages, i.e., a text request is sent to the input, and the output should be URLs of pages in descending order of relevance. I really want the search to work quickly: the response to a query is no longer than a second.
I decided to implement the search as a separate process with several processing threads, for submitting requests to use sockets. I chose C ++ as the main programming language. This allowed us to ensure high speed and efficient memory management. As a result, the following architecture was developed:
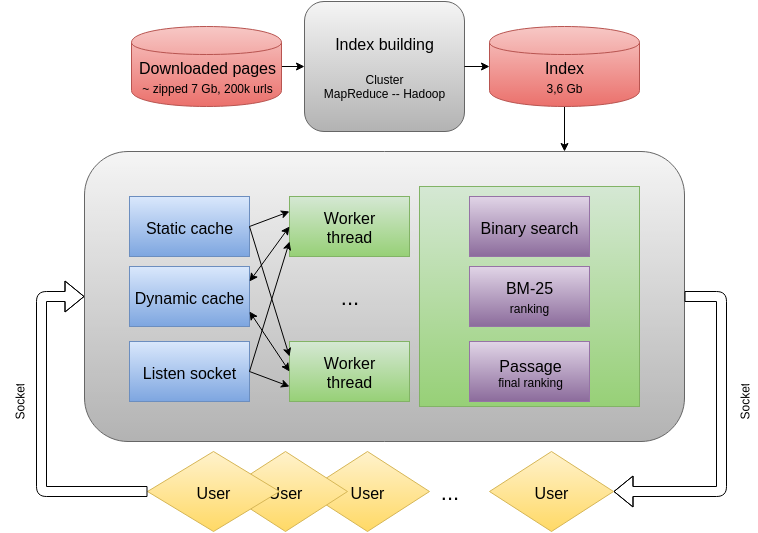
The source data are the downloaded pages of the site povarenok.ru. In total there were about 200 thousand different URLs compressed with zip and written in Base64 . To successfully perform a search on a large number of pages, it is necessary to build a reverse index on them: a list of pages on which it is presented is assigned to each word. Lists of the positions of occurrences of words in the pages are also needed - they are used at the ranking stage. To build them quickly enough, a training cluster with Hadoop was used. Processing was done in Python in streaming mode. Below is a general processing scheme:
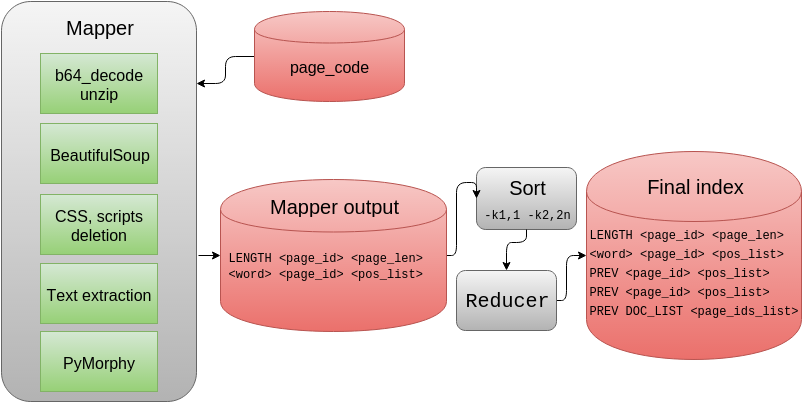
To work with the contents of web pages, the Beautiful Soup library was used, which allows you to easily remove CSS, scripts and select text from a page. Words are reduced to normal form with pymorphy2 .
After the Map operation, the output contains records about the length (number of words) on the pages and lists of word positions. Words are encoded in Base64 to avoid problems with encodings, lists are compressed using the simple-9 algorithm and also recorded in Base64.
MapReduce is configured to sort by the first two fields (the second is interpreted as a number), and then at the Reduce stage, length records are saved, word lists are grouped, the word itself is written once, and then the special string PREV is used (use the previous word). This trick reduced the index by 20 percent. LENGTH, DOC_LIST and PREV are special strings containing non-Base64 characters.
Networking was implemented using the libevent library. To create threads, we used std :: thread from C ++ 11. Incoming requests are placed in the queue, from where they are taken out by workers. For parallel use, the queue is “protected” by std :: mutex.
Boolean search. The incoming request is divided into words, lists of pages are loaded for them from the index. Lists are sorted and quickly intersect. In order not to look for an analogue of pymorphy2 for C ++, the user himself normalizes the words in the request (the requesting code uses Python). As a result, we obtain a list of pages that have all the words.
Draft ranking: BM25. The resulting pages need to be ranked, but to do it qualitatively for everyone immediately comes computationally expensive and therefore long. For this reason, the first ranking is done using the Okapi BM25 algorithm. Details about him can be read in Wikipedia . I used the standard parameters: k1 = 2.0, b = 0.75. From the index at this stage, we need for the pair (word, page) to get the length of the list of occurrences.
The final ranking: passage. This ranking applies only to the most relevant pages after the draft ranking (for example, to the first three hundred). The idea of the algorithm: in the text of the page there are windows containing search words, for each window the following characteristics are calculated:
- proximity to the top of the page;
- the ratio of words from the query to the total number of words in the window;
- total TF-IDF words in the window;
- the degree of similarity of the order of words in the window to the order that was in the request.
These characteristics are reduced to the same scale and are combined into a linear combination — the maximum such characteristic across all windows becomes the document's rank. It would be correct to choose coefficients to achieve the best result, but I used equal coefficients. From the index at this stage you need to load for the pairs (word, page) the lists of entries themselves.
Reduction factors based on site structure. An obvious consideration: pages with comments, anecdotes (yes, and this is on the "Cook") are not as necessary for the user as the recipes. To distinguish the structure of the site, I compared each URL with a certain set of features based on the occurrence of certain segments in the address. Then spent clustering. The result was a splitting of URLs into groups: blogs, recipes, albums, etc. Then, for some of them, I introduced selected decreasing coefficients - they are multiplied by the ranks issued by the BM25 and the passage algorithm. This made it possible to reduce the output of the mobile version page, the page with comments, blogs, etc.
The bottleneck in the search is access to the hard disk. For everything to work quickly, you need to reduce their number. For this, I tried to put as much information as possible into memory. The memory of our server was not enough to save everything, and in addition it is necessary to take into account that a lot of additional memory is required for organizing random access (pointers, etc.).
Static cache. At the beginning of the search, the entire index is read and loaded into memory:
- for each word, the offset of the list of pages in the index file;
- lengths of all pages;
- for all pairs (word, page) the length of the list of positions;
- for all pairs (word, page) the offset of this list in the index file.
The first allows you to quickly load lists from a hard disk at the stage of a boolean search. The second and third allow you to calculate BM25, without referring to the hard disk. The fourth is similar to the first, but to speed up the passage algorithm.
Dynamic cache. Since the search works through the pages of the culinary site, some words like “recipe”, “pie” are very common. Immediately there is an idea to cache hard disk access. To do this, using boost :: shared_lock and C ++ templates, I implemented a cache that can be used from various threads. Record life time is limited by time, the crowding out strategy is LRU .
Evaluation of search quality. For evaluation, we were given a set of 1000 pairs of queries and marker pages, which are considered to be the most relevant to each other. The quality can be judged by the average position of the marker among the results.
To automate testing, a Python script was written that sends requests to several threads and generates a report with graphs. This allowed us to quickly track the appearance of bugs and the effectiveness of modifications. The following version of the search, which we presented at the defense of the project, had such statistics:
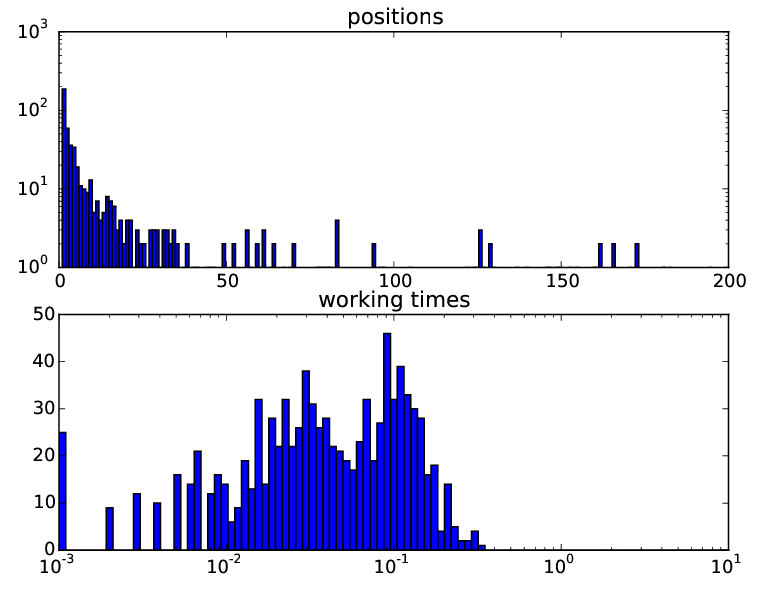
The upper graph shows the distribution of the number of markers by position in the issue. As you can see, most markers are in the top 20.
The lower graph shows the distribution of requests by runtime. The average request time was 58 ms, which, in combination with the other components of the project, allowed to fit in a second of time for the request.
 Daniel Polykovsky
Daniel PolykovskyMy responsibility was to develop the three components of the project: a spellchecker, a direct index and snippets.
The guardian was based on probability theory (Bayes formula). To correct errors, it was necessary to compare the "similarity" of two words. For this, a modified Damerau-Levenshteyn distance was used. The Russian language is characterized by errors associated with the doubling of certain letters. Such errors were considered more likely than, for example, the omission of a letter, and doubling the letter n was punished significantly less than doubling the letter e . Also the guardian was able to restore the register, which helped to improve its visual component. An interesting part of the development was the collection of word statistics. Initially, a dictionary built on the site povarenok.ru was used, but later it was supplemented with a frequency dictionary of the Russian language (O. N. Lyashevskaya, S. A. Sharov, 2009). The result was a very accurate system that could very quickly correct up to two errors, including gluing the words together. By the time the project was defended, we were able to find one mistake in the guard: the phrase “lordly liver” was replaced with “royally liver”.
The second part was splitting the text into sentences and building snippets (summary of the page). Machine learning was used for partitioning. The selection of signs turned out to be a very interesting task, as a result, we managed to invent them at about 20. The result was quite high, and it was still possible to improve it by adding a few regular expressions. The training was conducted on the OpenCorpora dataset, therefore, there were errors associated with words specific to the culinary theme: for example, the reduction of the tsp. (teaspoon) was divided into two sentences. On many pages of the povarenok.ru site, a summary of the article was marked up, which we could not use. If all the words from the query were found only in the title of the page, then it was shown as a snippet.
***
Perhaps in the future we will continue to publish graduation projects, stay tuned to our blog updates!
The Mail.Ru Technosphere is one of the many educational projects of the Mail.Ru Group, united on the IT.Mail.Ru platform, created for those who are keen on IT and are seeking to develop professionally in this area. It also presents the championships of the Russian Ai Cup, the Russian Code Cup and the Russian Developers Cup, educational projects Technopark in MSTU. Bauman and Technotrack MIPT. In addition, using IT.Mail.Ru, you can use tests to test your knowledge of popular programming languages, learn important news from the IT world, visit or watch broadcasts from specialized events and lectures on IT topics.
Source: https://habr.com/ru/post/277019/
All Articles