CEPH Cluster: Chronology of work on the upgrade of our file storage to a new architecture (56Gb / s IB)
By launching our cloud, we began to provide a storage service similar to Amazon S3 (with a compatible API, so that Russian customers could use standard clients for working with S3 by changing only the endpoint to connect). The main task of the service is to store snapshots of virtual machines and various client files. Amazon was taken as a model where it is necessary to develop, and in early 2014 it became clear that the existing file storage was outdated, customers demanded modern features that were not available to us and so much like AWS. But the refinement of the existing solution of the luminaries with huge labor costs, so it was decided to build a new S3-compatible storage from scratch.
Next is a long process of searching and comparing existing solutions, then tests for performance and fault tolerance of the solution, writing a pile of papers, then several unsuccessful test migrations, fixing bugs in the architecture, working on the resulting errors and total background online migration of all data after two months of work .
')
It was a damn long time, but everything went smoothly.
What did you want
So, at the beginning of the work, the tasks were as follows:
- Under the repository lay a paid file system, good at the time of early cloud development, but not optimal at the current stage of growth and development.
- On the nose there were big projects that required fundamentally different approaches in terms of the amount of data stored. It was necessary to scale quickly and flexibly. The existing solution was difficult to configure and required considerable human resources to configure replication and monitor the health of the cluster.
- The old file system did not allow for the background rebalancing of data when adding new servers with disks, which is about 24 TB of raw space per server. And if, nevertheless, we were launching an active task, then we received a tremendous performance drawdown.
- Monitoring the old repository was problematic and costly. To this end, the duty shift of the data center once a day was tasked with manually checking the status and availability of disks in the file storage. All attempts to automate monitoring led to a significant additional load on the FS. For the new solution, it was necessary to write just a few plug-ins for the existing monitoring system in order to fully see the state of the cluster, without creating virtually any additional load.
- New buns were needed, in particular multipart upload. It was necessary to divide large files into chunks and keep resuming the files when the connection was suddenly broken - this is the story about channel optimization for a distant oil company, and about data delivery by suitcases right to the data center.
- Creating snapshots also needed to be upgraded, they were uploaded to the old storage via the 1Gb / s channel - the new Infiniband network should have provided a suitable channel for quickly removing online snapshots.
- We wanted to optimize the network infrastructure, and the new solution allowed us to utilize the existing Infiniband factory, which we use for virtual networks between VMs and delivery of LUNs from flash arrays to hypervisors.
How was the work
In September-October 2014, two solutions were considered: Swift + Swift3, Ceph + Rados Gateway. They compared compatibility with the Amazon S3 API, studied general information about solutions, documentation, roadmap products, assessed the quality of support and support for the open source community, the complexity of integration with the cloud, ease of maintenance and scaling. The Amazon S3 API has about 300 methods, which we tested for our applicants. When testing the first solution (Swift + Swift3), we got 136 failed tests, Ceph + Rados Gateway failed about 50.
Ceph, as expected, won because of its greater compliance with the above criteria.
The cluster architecture has not yet been invented, they only knew that there would be only three components (OSD, MON, RGW), so that where it would turn would remain a mystery. In November, began a thorough study of the documentation Ceph and writing his own on the development. On the basis of these documents, developers were able to understand how the cluster works and how it works.
At the same time, the cluster architecture was being designed (test and production). One diagram above, another one:

In December, we went to the first test stand. It was a reduced copy of the battle cluster, with only three servers in each data center. It was also stretched geographically (into two data centers). Here is the test cluster layout:

Few open-source products can boast of such detailed and high-quality documentation as that of Ceph, so we found no surprises and undocumented bugs. Having fully understood what Ceph is and what it is eaten with, we touched our own deployment utility. It turned out to be good for clusters with a simple architecture and network topology, which are often deployed separately from clients. But we needed a more flexible and convenient deployment utility for scanning directly in the cloud. We wrote a program that analyzed the configuration file and assembled the cluster in pieces, either sequentially or in parallel. Now in the config we specify the hosts, the components on them, and our software determines the number of data centers to which the solution is stretched, the type of data replication, which network to use for data transfer. This is especially true for cloud test benches, which can be perezalitsya several times a day.
This is a fragment of the configuration file:
CEPH = {
"S3": {
"options": {
"suffix": "f",
"allow-deployment" : False,
"journal-dir": "/CEPH_JOURNAL"
},
"hosts": {
"ru-msk-vol51": [
{ "host": "XX087", "role": "rgw", "id": "a" },
{ "host": "XX088", "role": "rgw", "id": "b" },
{ "host": "XX088", "role": "mon", "id": "a" },
{ "host": "XX089", "role": "mon", "id": "b" },
{ "host": "XX090", "role": "mon", "id": "c" },
{ "host": "XX087", "role":"osd", "id":"0", "disk":"sdb"},
{ "host": "XX087", "role":"osd", "id":"1", "disk":"sdc"},
{ "host": "XX087", "role":"osd", "id":"2", "disk":"sdd"},
{ "host": "XX087", "role":"osd", "id":"3", "disk":"sde"},
{ "host": "XX087", "role":"osd", "id":"4", "disk":"sdf"},
{ "host": "XX087", "role":"osd", "id":"5", "disk":"sdg"},
.....
{ "host": "XX086", "role":"osd", "id":"114", "disk":"sdl"},
{ "host": "XX086", "role":"osd", "id":"115", "disk":"sdm"},
{ "host": "XX086", "role":"osd", "id":"116", "disk":"sdh"},
{ "host": "XX086", "role":"osd", "id":"117", "disk":"sdg"},
{ "host": "XX086", "role":"osd", "id":"118", "disk":"sdk"},
{ "host": "XX086", "role":"osd", "id":"119", "disk":"sdj"}
],
"ru-msk-comp1p": [
{ "host": "YY016", "role": "rgw", "id": "c" },
{ "host": "YY049", "role": "rgw", "id": "d" },
{ "host": "YY056", "role": "mon", "id": "d" },
{ "host": "YY068", "role": "mon", "id": "e" },
{ "host": "YY016", "role":"osd", "id":"48", "disk":"sdb"},
{ "host": "YY016", "role":"osd", "id":"49", "disk":"sdc"},
{ "host": "YY016", "role":"osd", "id":"50", "disk":"sdd"},
{ "host": "YY016", "role":"osd", "id":"51", "disk":"sde"},
{ "host": "YY016", "role":"osd", "id":"52", "disk":"sdf"},
{ "host": "YY016", "role":"osd", "id":"53", "disk":"sdg"},
.....
{ "host": "YY032", "role":"osd", "id":"102", "disk":"sdj"},
{ "host": "YY032", "role":"osd", "id":"103", "disk":"sdk"},
{ "host": "YY032", "role":"osd", "id":"104", "disk":"sdl"},
{ "host": "YY032", "role":"osd", "id":"105", "disk":"sdm"},
{ "host": "YY032", "role":"osd", "id":"106", "disk":"sdn"},
{ "host": "YY032", "role":"osd", "id":"107", "disk":"sdi"}
]
}
}
}Until February, we played on a devel-stand with testing software for scanning the cluster. Various cluster configurations were described in the files and launched by the deployment. As expected, it exploded. It was an iterative process of refinement and refinement. During the design and implementation, a new version of Ceph was released, in which the deployment and configuration of cluster components were slightly modified, and our product had to be added once again.
In February, the development of plug-ins for the existing monitoring system began. We set a goal to cover all the components of the solution and get detailed statistics from the cluster, which allowed us to quickly find specific points of failure and solve minor problems in minutes. By the end of March, the cloud code was ready to work with the new S3 cluster, which taught the cloud to work with the RadosGW API. Somewhere at the same time, we realized that we had forgotten something ... Namely, about a static website with which users can place static web sites in their bucket. It turned out that the RGW does not support this functionality out of the box, and we had to write a small addition to our solution in order to correct this omission.
Until the end of May, they wrote software for migration from the old cluster to the new one. The utility consistently took the file, wrote down the name, size, owner, rights and so on into the database, the file was assigned the status of "non-migrated", then attempts were made to migrate. After a successful migration, he was set to “migrated” status, with an unsuccessful migration attempt he was set to “error” status and this file had to be migrated again the next time the script was run.
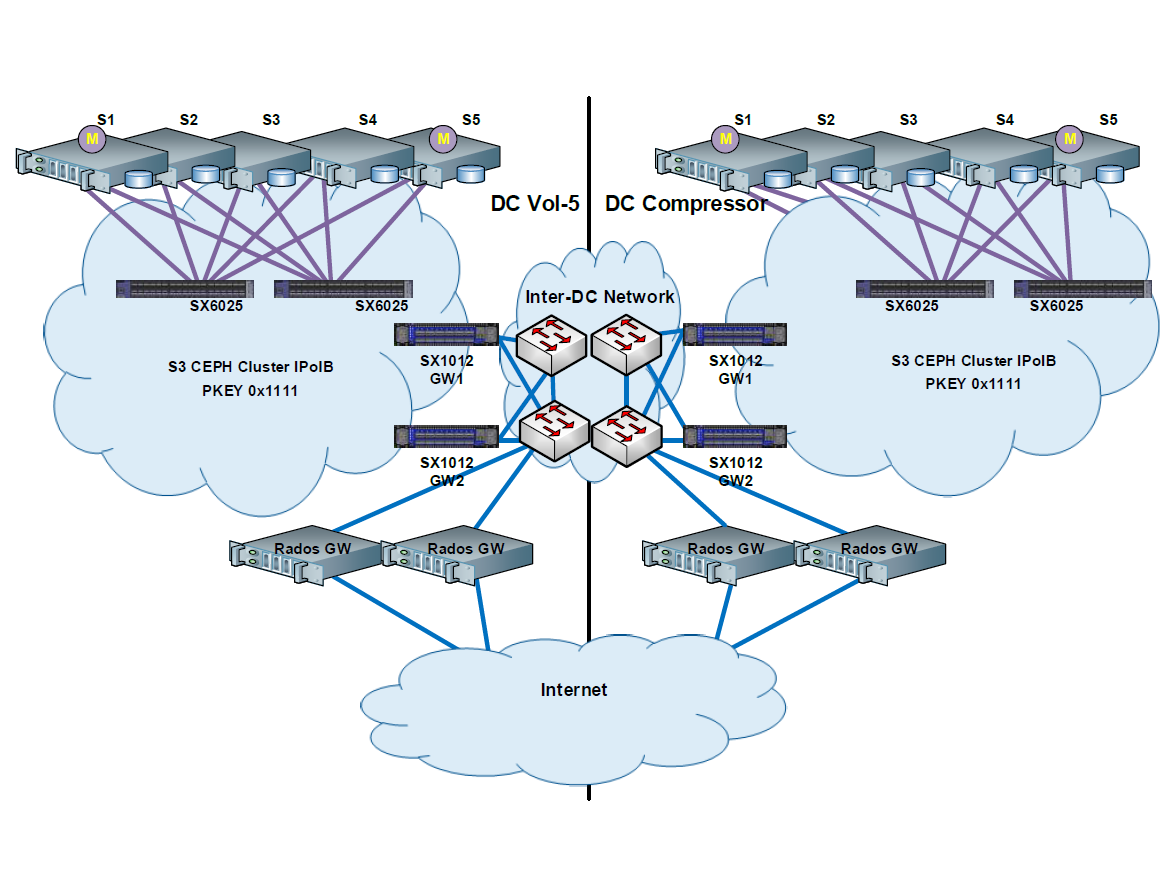
In May, the redesign and modification of the existing Infiniband factory for the CEPH cluster was completed . Ten servers were added to the factory for the Ceph cluster and a separate partition key was allocated, through which cluster traffic was separated from the rest of the traffic on the Infiniband network. In addition, 2 SX1012 switches with VPI licenses, which act as proxy between Ethernet and Infiniband cluster networks, were installed in each data center, thus servers in different data centers were in the same L2 segment. The switches were combined into a logical cluster and worked as one piece of hardware, balancing traffic and adding even more fault tolerance to the solution. From the point of view of the network, this is probably the most interesting part. About what exactly colleagues did on the physical level, you can read a little more here .
In June, unfolded produtiv. Everything went smoothly and according to the engineers' regulations. Servers for the cluster were already available, we had to transfer several servers from one data center to another. Further, as it should be, testing of servers began, they checked memory, disks. With disks it was the most interesting of all: each disk was tested by dd and fio and completely filled with zeros several times. About 20% of all drives immediately went back to the replacement vendor. All work was completed within 1–2 weeks.
Until July, minor bugs ruled and added small things. There were two major changes in the cluster architecture:
- Ceph logs are transferred to flash drives. There was an intense appeal to the logs, and the usual SATA-disks that are used in our solution did not cope with the task: the cluster performance subsided and slow requests constantly rained up, after which the cluster went into the WARN state. Thought, thought and come up with. Each disk for journals was presented from two different flash storage systems on the Infiniband network, multipath devices were collected on the host and were combined into software reyd. We thought that this was an excellent fault-tolerant solution, but in practice, when there was a problem with one of the storage systems or the IB network or multipath, the software reyd was falling apart, and we had to assemble it by hand. Therefore, in the end, it was decided to abandon the presented drives and switch to local SSDs.
- Abandoned Ethernet management networks in favor of Infiniband. Initially, two networks were used in the cluster, one for management - 1Gb / s, the second for data transfer between cluster hosts - 56Gb / s. And when they began to test the performance of the cluster and upload files to it, they found that the download speed does not exceed 1Gb / s. We thought and wondered for a long time, finally we looked at the loading of interfaces and understood what our problem was: RGW contacted the cluster monitors via the control network and then started downloading data via the same network. We abandoned the control network on Ethernet and transferred everything to Infiniband, after which the tests showed completely different results.
At this stage, the iron workers mocked the cluster as much as they could: they took out the disks "on hot", cut down the servers, and generally tried in every way to cause a violation of data integrity. So to say, determined the boundaries of the possible. The system proved to be very good, and failed to completely break the cluster.
After a full migration began in test mode , in particular, to check the shaping when working with a huge amount of data. I had to remember all the unloved tc, read the documentation several times and finally wrote a few magic rules that will limit the speed. The migration was slow, the communication channel was wildly shaped, so that customers would not feel a performance drop on the old cluster. A full copy was created only in August - two weeks after the start. And they started the integrity check - they compared MD5 sums of files. There was also a separate test endpoint API for the new cluster, through which test accounts and access to the files in them were checked (all standard actions that can be performed in S3).
In September, we checked everything again and decided to switch. We wrote instructions for switching from the old cluster to the new one, transferred the old cluster to the maintenance mode and were able to migrate the last gigabytes. All work took a couple of hours, there were no surprises.
As a result, we reached the rebalance rate that we could not get before: 1 disk at 2 TB is rebalanced in 3-4 hours (without loss of speed for customers who constantly use file storage).
PS Half a year has passed since the launch of the combat cluster. Since then, we have upgraded from Giant to Hammer and are waiting for the next updates. Yes, not everything is as smooth in Ceph as we would like, there are bugs that we and our customers find. In the next update of ceph-0.94.6, three backward from master PR are captured by us, and we must always remember that Ceph is an open source product, therefore you may need to fix something yourself. We believe that the Ceph + RGW bundle that we use is ready for industrial use, which it now demonstrates in our combat cluster. And as I wrote above, we use Ceph only as an object-oriented storage, neither block-oriented, nor CEPHFS. As for plans for the future, now we have started testing the transition of Ceph from EL6 to EL7 and further updating to the Infernalis version.
There will be questions about working with Ceph in high-loaded cloud environments - write here in the comments or email: SButkeev@croc.ru
Source: https://habr.com/ru/post/277011/
All Articles