In simple words about a particle filter

In this article I will tell you about one of the optimal filtering methods - Particle Filter - and show that it is much easier to apply such a filter than you think.
Optimal filtering
The optimal filtering algorithms are used in the calculation of systems under the influence of random processes. These algorithms allow us to obtain an estimate of the system state parameters with a minimum standard deviation.
Particle filter
Particle filter is one of the most popular methods for optimal filtration. This method was used on the Stanford Junior autonomous car, which finished second at the DARPA Challenge in 2007.
')
The particle filter makes it possible to obtain an estimate (approximate value) of the parameters of the system or object (we denote them as parameters A), which cannot be measured directly. To build this assessment, the filter uses measurements of other parameters (parameters B) associated with the first. Let's show it on the diagram:
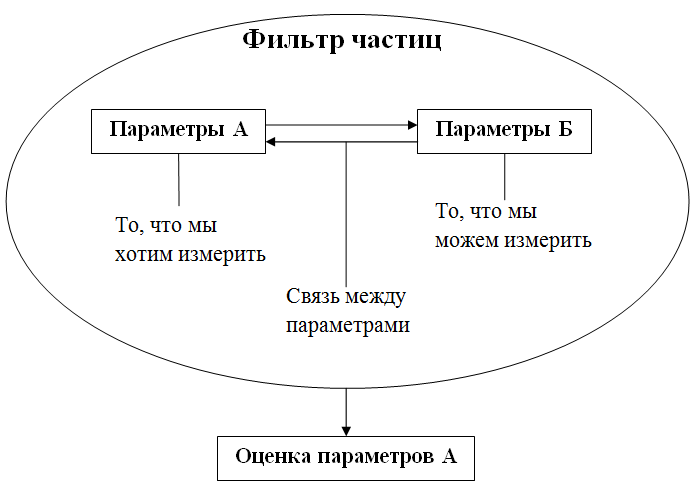
To evaluate the parameters of A, the filter creates a lot of hypotheses (particles) about the current value of these parameters. At the initial moment of time, these hypotheses are completely random, but at each iteration of the filtering cycle the filter will remove hypotheses that will not pass the validation test based on measurements of parameters B.
Thus, of the many hypotheses, in the end, only those that are closest to the true value of the parameters A will remain.
This article describes one of the simplest options for applying a particle filter. The robot moves in two-dimensional space and can measure the distance to certain objects in this space (landmarks). The task is to determine the location (coordinates) of the robot.
At the same time, the robot can make turns with an accuracy of ± 5 degrees (turning error), move with an accuracy of ± 20 meters (movement error) and measure the distance to landmarks with an accuracy of ± 15 meters.
The particle filter algorithm is divided into two parts: initialization and the main filtering cycle.
Initialization
Before starting the filtering, the particle filter needs to be initialized - set the parameters, initial distribution and other conditions of the filter operation.
The main parameter of the particle filter is the number of these particles (we denote this number N). Everything is simple: the more particles - the more accurate the filter, and the more calculations need to be carried out at each iteration of the main loop.
The initial distribution of particles depends on a priori information. For example, if we know that the robot is in a cell with coordinates (0, 0), then all particles must be randomly distributed inside this cell.

(Click on the image to enlarge.)
At the same time, the orientation of the robot (in the drawings, the robot is represented as an animal) inside this cell is unknown to us, so the orientation of each particle is random (from -180 to 180 degrees).
If there is no a priori information, then particles are distributed randomly throughout the map.
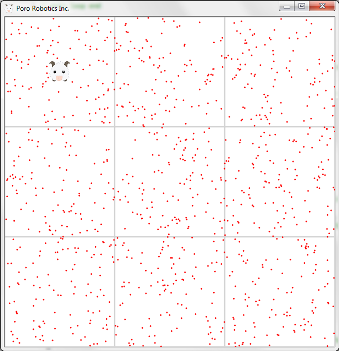
The main parameter of each particle is its weight. The particle weight determines the probability that the coordinates of this particle coincide with the coordinates of the robot. Since we assume that the full set of particles describes the position of our robot, the total weight of all particles is one (this means that the robot is inside the area covered by all the particles).
At the same time, regardless of the availability of a priori information, the weight of all particles at the initial moment of time should be the same and equal to 1 / N.
Also at the initialization stage, one should impose restrictions on the motion of particles (if any). In this example, the particles have only one limitation - if the particle goes beyond the map, its weight becomes zero.
If you have a map of the area, then on this map are landmarks for which we will take measurements. These reference points also need to be added to the particle filter. (It is possible to use a filter without a known map of the area and location of landmarks, but this is a topic for another article.)
In this example, four reference points are used, located at the corners of the map (they are not indicated in the figures).
Main filter loop
The main filtration cycle is divided into three phases:
Motion (Motion Update)
At this stage, the robot makes a movement and, since the movement of the robot occurs with errors, loses information about its location.
Let me explain about the loss of information:
Suppose you are standing still and know your geographic coordinates exactly. Then you take 100 steps forward. Since you are not a robot, and you cannot make 100 steps of the same length, you cannot determine the distance that you will go through these 100 steps (however, even if you were a robot, you would still have a movement error). Therefore, when you stop again, you will know your coordinates only approximately.
Thus, having made a move, you moved from “I know exactly where I am” to “I know about where I am” - that is, lost information.
Since each particle is a model of a robot, it should move like a robot. For example, if you give the robot the command “drive 200 meters forward”, then all particles must receive the exact same command. At the same time, since the orientation of all particles is different, the “forward” of them is also different.
The calculation of the new coordinates of the robot is quite simple:
First, we rotate the robot at a given angle, simply adding the value of this angle to the current orientation of the robot:
Orientation = Orientation + angle Then we calculate the new coordinates from pure trigonometry:
newX = oldX - distance * Sin(Orientation) newY = oldY + distance * Cos(Orientation) In this example, the zero angle of rotation of the robot corresponds to the direction downwards, and the angle of ninety degrees to the direction to the left.
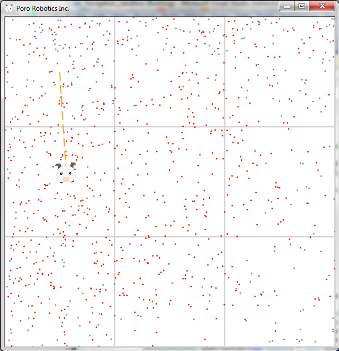
The figure shows that after the movement of the robot, the distribution of particles has shifted. At the same time, particles with low weight turned gray — these particles are still involved in the assessment and the change in the color of the particles is made solely for clarity.
We also note that due to the turning error, the robot did not drive vertically downwards, but deviated by 3.7 degrees. The movement error led to the fact that the robot did not drive 200 meters, but 185.
Do not forget that each particle is a model of the robot, and its movement also occurs with an error. At the same time, despite the fact that the model of particle errors is exactly the same as the model of robot errors, the actual error (the error obtained on the performed movement, in the example shown is 3.7 degrees and 15 meters, respectively) of the particle movement does not depend on the actual error of the robot.
Measurement update
At this stage, the robot makes measurements and receives new information about its location.
Let's complete the previous example, when we took 100 steps and lost information:
By measuring your coordinates at a new point, you move from “I approximately know where I am” to “I know exactly where I am again” - that is, you receive information.
The physics of the measurements do not matter, the main thing is that these measurements allow you to specify the parameters that you estimate with the particle filter.
In this example, the distance to the reference point is measured with a measurement error (± 15 meters). So far everything is simple: we make measurements for the robot and for all particles.
The formula for calculating the distance to the reference point:
measurement = Sqrt((orientierX - robotX)^2 + (orientierY - robotY)^2) Now we need to compare the measurements made by each particle with the measurements made by the robot in order to determine the weight of each particle.
To compare the measurements, we will use the normal distribution formula:
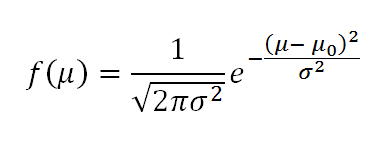 ,
,where σ ^ 2 is the standard deviation (measurement error); μ0 - expectation (measurement of the robot); μ - value value (particle measurement); f (μ) is the probability of obtaining the value of μ for given μ0 and σ ^ 2.
If you use more than one guideline (and in most cases it is), then to calculate the particle weight, you just need to multiply the probabilities of the measurements made. In this example, there are four landmarks and the particle weight is determined as follows:
particleList[i].weight = f(measurement[i][0]) * f(measurement[i][1]) * f(measurement[i][2]) * f(measurement[i][3]) Fine! We processed the received information and calculated the weight of each particle. But now the total weight of all particles exceeds one, and therefore it needs to be normalized (I remind you that the total weight of particles must be equal to 1).
S = Sum(weight) for i in range(N): weight[i] = weight[i]/S Now the total weight of the particles is equal to one and we can proceed to the last step of the filtration cycle.
Resampling
Screening is needed in order to weed out particles with low weight, because they, in fact, are a dead weight. The weight of the screened particles is small, which means that the probability of locating the robot next to these particles is negligibly small. So why should we continue to model the movement and measurements of these particles, if we have already decided that they do not correspond to the position of the robot, it will be much more efficient to replace them with new particles, which will improve the accuracy of the object state estimation (in this example, the coordinates of the robot).
The essence of the screening is to create a new array of N particles from the array of N particles, which will include only the particles with the highest weight. To be more precise, each particle from the first array goes to the second (survives screenings) with a probability equal to its weight.
Example:
If the particle weight is 0.0001, and the number of particles is N = 1000, then the probability that this particle will survive the screenings is equal to:
1 - (1 - 0.0001)^1000 = 0.095 = 9.5 % If the particle's weight is equal to 0.005 (recall that the initial weight of all particles was 1 / N = 0.001), then the probability that it will survive the dropout is equal to:
1 - (1 - 0.005)^1000 = 0.993 = 99.3 % There are many ways to apply such an algorithm for screening, but I will tell you about one of the simplest and most effective - the resampling wheel.
Consider this algorithm for example. Take an array of seven particles (N = 7), and present their weight as follows:
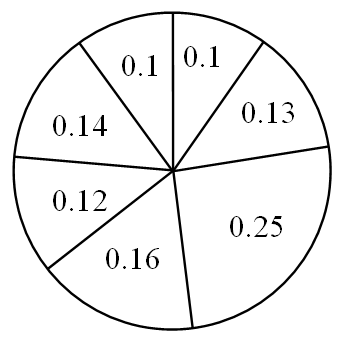
The algorithm starts with a random particle, so we take a random variable:
index = random.randint(0, 6) # index0 And we introduce the variable β, equal to zero.
betta = 0 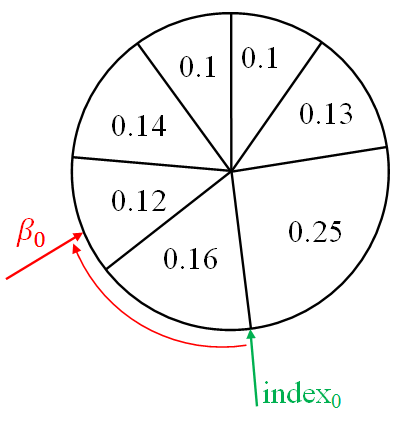
Now we add to β a random number from zero to twice the maximum weight (in this case, the maximum weight is 0.25):
betta = betta + random.uniform(0, 2*max(weight)) # betta0 After that, we compare the value of β with the value of the weight of the current particle. If β is greater than the particle weight, then we subtract the particle weight from β and increase the index by 1:
if betta > weight[index]: betta = betta - weight[index] index = index + 1 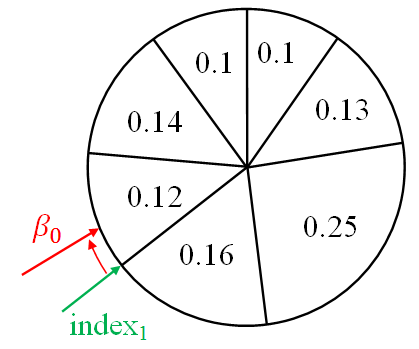
As soon as β becomes less than the particle weight - we add a copy of this particle to the new particle array, return to the beginning of the cycle and increase β by a random number from zero to twice the maximum weight.
newParticleList.append(particleList[index]) betta = betta + random.uniform(0, 2*max(weight)) # betta1 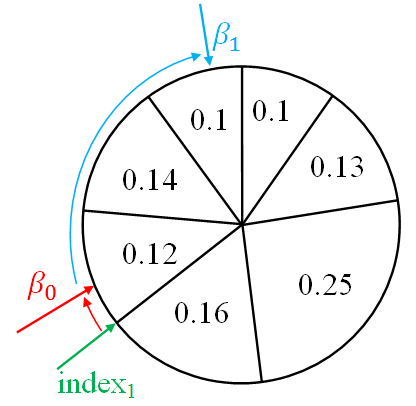
The complete code for the dropout algorithm:
index = random.randint(0, 6) betta = 0 for i in range(N): betta = betta + random.uniform(0, 2*max(weight)) while betta > weight[index]: betta = betta - weight[index] index = (index + 1)%N # 0 N newParticleList.append(particleList[index]) particleList = newParticleList Thus, each particle enters a new array with a probability equal to its weight, and can be added to a new array several times. After the dropout, the particles should be normalized again:
S = Sum(weight) for i in range(N): weight[i] = weight[i]/S It is not necessary to do screenings on each iteration of the filtering cycle, however, it is highly recommended at the first iterations - this will allow you to screen out unnecessary particles faster (especially if there is no a priori information) and get an accurate estimate. After this, screenings can be performed at regular intervals, for example, after every 20th or 100th iteration.
After the first screening, the distribution of particles in the above example will look like this:
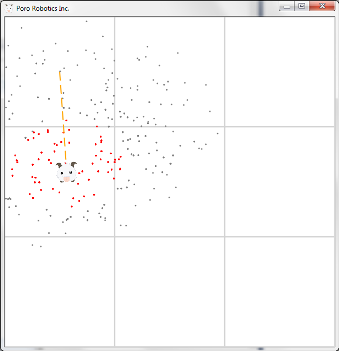
Getting an assessment of the state of the object
You can get an estimate of the state of an object from a particle filter, no matter what phase it is in now. To do this, it is enough to sum up the parameters of all particles multiplied by their weight:
estimateX = 0 estimateY = 0 for i in range(N): estimateX = estimateX + particleList[i].X*particleList[i].weight estimateY = estimateY + particleList[i].Y*particleList[i].weight The result of the particle filter:
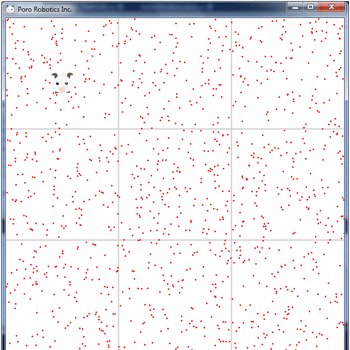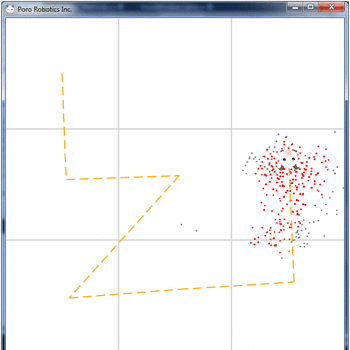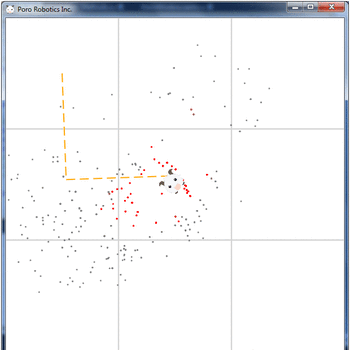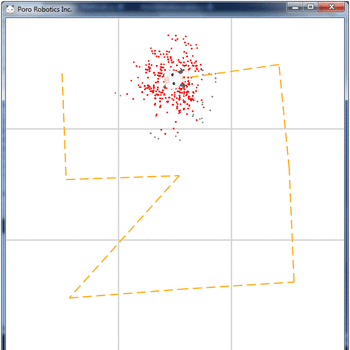
Conclusion
By applying the particle filter in the above example, we managed to get the coordinates of the robot with an accuracy of 12.9 meters, with an error of movement of 20 meters and an error of measurement of 15 meters, in just 8 iterations of the main cycle.
After reviewing the basic principles of building a particle filter, you can now apply it to solve your own problems!
Related Links
A course of lectures on autonomous navigation systems
Another example of the implementation of the particle filter
Stanford junior
Source: https://habr.com/ru/post/276801/
All Articles