Perfect UI framework
Hello, my name is Dmitry Karlovsky, and I ... an architect of many frameworks widely known in narrow circles. I have never been satisfied with the need to solve the same problems from time to time, so I always try to solve them radically. But before solving them, you need to find and realize that it is rather difficult to be captured by habits, patterns, stereotypes and “ready-made” solutions. Every time I encounter problems in the implementation of the task, I wonder "what the hell is wrong with this tool?" and, of course, I am going to saw my tool: function, module, library, framework, programming language, computer architecture ... stop, I have not yet come to the last.
Today we will talk about JS-frameworks. No, I will not talk about the next ready-made solution, not the purpose of the post. I just want to sow in your minds a few simple ideas that you will not find in the documentation to any popular framework. And at the end we will try to form a vision of an ideal architecture for building a user interface.

Long debug cycle
A typical debug loop looks like this:
- Editing the code.
- Application launch.
- Check and detect problems.
- Research their causes.
And this cycle is repeated for any typo. The faster the developer understands where and why he made a mistake, the faster he realizes everything. Therefore, the programmer should receive feedback as quickly as possible, right in the process of writing code. This is where the development environment tools help, which analyze the dialed code in real time and check if it will all work. As a result, it is very important that the development environment can get as much specific information as possible from the code. To achieve this, the language used must be statically typed as much as possible. JavaScript is typed only dynamically, from which the IDE tries to guess the types by circumstantial signs (typical patterns, JSDocs), but, as practice shows, even in the most advanced development environments, this turns out badly.
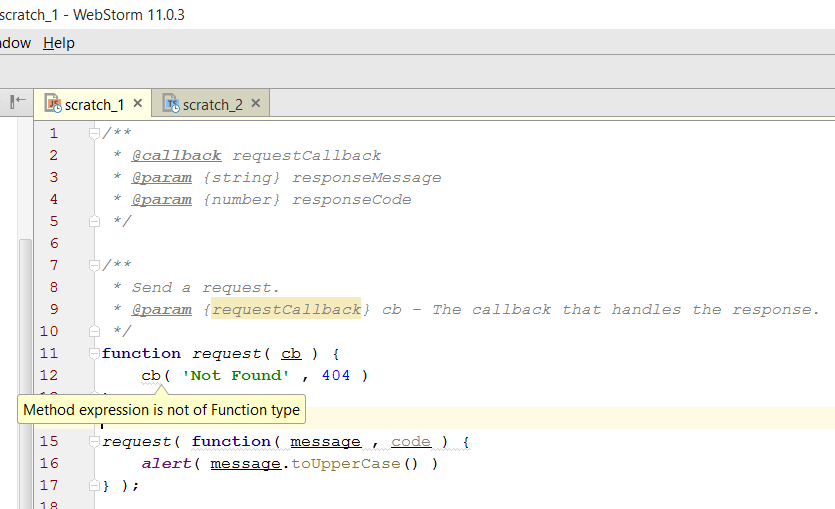
However, there is a minimalistic JavaScript extension that adds optional static typing to it - TypeScript. Even a simple text editor like GitHub Atom understands it perfectly.
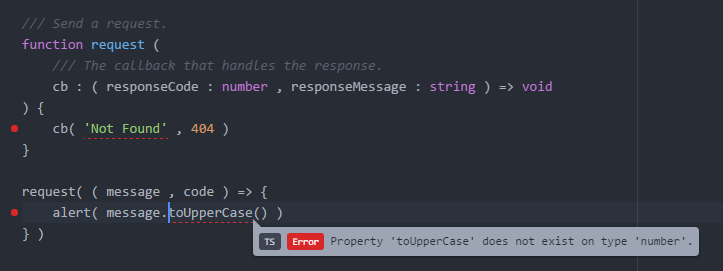
Currently TypeScript is the best language for developing web applications. AngularJS developers have already understood this. Do not miss the train!
The second echelon in the acceleration of the debugging cycle is automated tests that allow you to quickly check the performance and detect the location of the fault. Unfortunately, many testing frameworks are concentrated only in the first phase (verification), but the second (fault localization) is often not even thought about, although it is no less important. For example, the popular QUnit test framework wraps all the tests in try-catch, so as not to stop at the very first test fallen, and at the end draw a beautiful report that is rather useless in finding the cause of a malfunction. All he can give out is the name of the test and the non-clickable boxteam. But there is a crutch - you can add the parameter? Notrycatch to the link , which does not always work , and then the tests should fall down on the first error, after which, depending on the debugging mode, you will get either to stop the debugger at the point of exception, or clickable one fallen dough in the console. But the solution without crutches would be ideal: in the stop mode for exceptions, stop at each (and not only at the first), and in the logging mode, log all drops to the console with clickable center path. This is not as difficult as it may seem - it is enough to run the tests in separate event handlers, and in no case do not wrap them in a try-catch.
In the light of the above, it is worth emphasizing that try-catch is better not to use not only in the test framework, but also in any other, because by catching an exception you lose the opportunity to stop the debugger at the place of its occurrence. The only sensible use of try-catch in JavaScript is to ignore expected exceptions, such as making jQuery at startup, checking browser support for some features. And that is why such a crutch, as a debugger option “to stop not only on uncaught exceptions,” helps badly, because it gives too many false positives that have to be scrolled.
The last nail in the coffin of try-catch can be hammered by the fact that at least V8 does not optimize the functions containing this construction.
You need to write the code so that it can calmly fall at any moment without breaking the entire application.
It is for reasons of convenience of debugging that there are no try-catch in the latest implementation of atoms , but there is an error event handling, according to which the synchronization of atoms is resumed taking into account the fallen ones.
Where is what lies?

How to quickly go to the declaration of the entity? How to quickly find all places to use an entity? How to find an entity ad by name? These detective investigations reduce developer productivity and distract from the problem being solved. Static typing, as noted above, allows the development environment to understand the semantics of the code: where what type is declared, what type the function returns, what types I can use in the current context. But it is equally important to locate and name files according to simple and universal rules, because working with files is not only and not so much the means of the development environment. For example, grouping files makes sense not by type, but by functionality. Modules with related functions - in larger modules. A collection of various modules of one author - in the package. This logic is embedded in the PMS architecture (Package / Module * / Source). In it, the directory hierarchy exactly repeats the namespace hierarchy in the code. Because of this, by the name of the entity you can always understand where it should lie. This property is used by the pms collector to build a tree of module dependencies: it analyzes the sources for use of third-party modules, then serializes the resulting graph so that by the time the dependent module is executed, all its dependencies are also executed. And this does not require any special ads in the code. No AMD, LMD, CommonJS. No import, require, include. You simply write the code as if the necessary modules were already declared in the same file as yours, and the collector takes care of the rest. This is a direct analogue of autoloading classes from PHP, but it works with any modules containing source codes in a wide variety of languages.
Due to the fact that dependencies between modules are monitored automatically, it becomes very easy to add new modules and transfer existing ones. To create a module, it is enough to create a directory. To add code to it in any language, simply create a file. But the most important thing is that only those modules that are actually used are used in the release, but not everything. This allows you to build the code of the framework and libraries not from several large modules, 90% of the functions of which are not used, but from a multitude of microscopic modules, without leading to kilometer-sized footcloths. For comparison: the JavaScript code of ToDoMVC on Angular2 weighs a total of 1.6MB (320KB in compressed form), and on $ mol - 140KB (22KB in the same way). Compare the scale. Do I need to tell which application will open faster on the mobile phone through EDGE? And do not say that now 4G is everywhere - in Moscow even EDGE is intermittently caught in many places. And what does the modern industry offer us? To connect libraries entirely, and then with cunning magic to cut out all unnecessary? Pity my CPU!
Micromodular architecture allows you to create compact and fast applications.
Many now have probably already had their hands on expressing kilobytes of righteous anger and outrage at my unprofessionalism in the comments. But let me rewind time a few years ago and remind you of one similar situation. Not so long ago, XML technologies were in the trend, everyone actively wrote on XHTML, fluttered in front of XSLT, and exchanged data exclusively through XML. If you did not put "/" at the end of the incorporeal tags or, God forbid, did not pass the html-validation, then you were looked upon as unprofitable. But somehow it hurt a lot of difficulties with this technology stack. I had to read the kilometer specifications, put up with strict restrictions, insert a bunch of crutches, and the bright future did not come - the browsers did not bring XHTML support to mind. Developer dissatisfaction grew, enthusiasm faded away, until it suddenly became clear that working with poor JSON (compared to powerful XML) made it easier and faster to work; that the rigor and redundancy of XML does not give a special profit; that what thousands of developers believed was not the best idea. A similar situation was with the vendor prefixes in CSS: first they copy-paste them with their hands, then special utilities appeared that copy-paste them automatically, and now they are methodically removed from them, since they do not solve any problems, introducing only unnecessary complexity. But back to the "modules". Let's write a couple of simple modules on, for example, RequireJS:
// my/worker.js define( function( require ) { var $ = require( 'jQuery' ) return function () { $('#log').text( 'Hello from worker' ) return 1 } } ) // my/app.js define( function( require ) { var jQuery = require( 'jQuery' ) var worker = require( 'my/worker' ) var count = 0 return function () { $('#log').text( 'Hello from app' ) count += worker() count += worker() } } ) What is wrong with this code:
- The same module (which is jQuery) in different files has different local names. That is, the programmer needs to constantly keep in mind how jQuery is called in each module. Why do we have the opportunity to name the same entity differently? To confuse everyone?
- We do not have easy access to the count variable. We can't open the console and just type
app.countto find out what the value is there now. To do this, you need to pretty much juggle the debugger. - Each time using any entity, you need to check that it is "imported", and ceasing to use it, you must also delete these "imports." The existence of a special tool for automatic synchronization of the list of imports with code emphasizes their meaninglessness - this is a typical, easily automated infrastructure code, to which the programmer, generally speaking, has no business.
- A lot of extra code, which is often just generated from the template, because no one likes to write the same thing with their hands.
How to solve these problems without creating new ones? And it's very simple, let's use the jam.js format:
// jq/jq.js // my/worker.jam.js var $my_worker = function () { $jq('#log').text( 'Hello from worker' ) return 1 } // my/app.jam.js var $my_app = function () { $jq('#log').text( 'Hello from app' ) $my_app.count += $my_worker() $my_app.count += $my_worker() } $my_app.count = 0 The code turned out to be much smaller and it was all in business, and in order to work with it we no longer need a powerful development environment. We do not have to wrestle with which module is called jQuery, because it is called the same everywhere - according to the path to it in the file system. At the same time, we can always copy $my_app.count to the console to view the current status. That is what we should strive for, and not to isolate everything and everyone.
The railing helps not to fall into the abyss, but you should not surround yourself with them.
But what is really needed is the namespace, and the directory structure is the best way to guarantee the absence of conflicts in the namespace.
Bloat code

If before there were disputes whether it is worthwhile to load jQuery on a hundred kilobytes, now nobody is confused by the connection of the megabyte framework. Some even take pride in having written millions of lines of code to implement a not too complicated application. And if the problem was only in the download speed of these elephants, but the speed of their initialization. But there are much more significant problems arising from this. The more code, the more errors in it. Moreover, the more code, the greater the percentage of these errors. So if you see a huge mature framework, then you can be sure that a lot of man hours have been spent on debugging such amounts of code. And a lot more to spend, both on existing bugs that have not yet been noticed, and on bugs introduced by new features and refactorings. And don't be fooled by the “100% test coverage” or “a team of highly qualified specialists with a decade of experience” - there are definitely no bugs in the empty file. The complexity of maintaining a code grows non-linearly as it grows. The development of the framework / library / application slows down until it degenerates completely into endless patching of holes, without significant improvements, but requiring a steady increase in staff. So, if someone offers you to write additional code to transform Camel Ids Directives into directives-with-hyphens identifiers, just because JS traditionally uses one notation, and CSS is different, not compatible with it, then spit it into face and use universal_notation_identifiers, which does not require any additional code or development environment with complex heuristic matching algorithms.
A large amount of code does not always mean a large number of possibilities. Often this is a consequence of using too verbose tools, over-sophisticated logic and banal copy-paste (including code generation). You should not go to extremes, giving all the variables one-letter names, but you should be wary about seeing tens of thousands of lines drawing a simple form on the screen. You can not pay attention to this, believing that you do not need to understand it, limited to only reading the documentation; believing that the public API is enough for any women; believing that the bugs are either not present, or they will be quickly corrected by the maintainers. But practice shows that sooner or later you will have to climb into this pile of code, if you do not make changes, then at least investigate its work. And the more code, the harder it is to understand. But even harder to understand the code, full of abstractions. A small number of literate abstractions can significantly simplify the code, but we get a sharply opposite effect when we make them indiscriminately. Factories, proxies, adapters, registries, services, providers, directives, decorators, impurities, types, components, containers, modules, applications, strategies, commands, routers, generators, iterators, monads, controllers, models, displays, display models, presenters , templates, builders, virtual home, dirty checks, binders, events, streams ... Even experienced developers are lost in this variety of abstractions. And try to explain to a beginner how to make a simple component on such a framework so that you do not cry with bloody tears and look at what he did.
The simpler the better.
Development difficulty

As the application grows, it becomes more and more difficult to make changes to it without breaking it. It is required to take into account an increasing number of states simultaneously, scattered across different parts of the application. Many implicit internal agreements inevitably begin to contradict each other. Therefore, it is important that only one place in the code is responsible for one state. If you change the value of a variable from several different event handlers, then sooner or later you will get the wrong value, which will look like a glitch, and you will have to spend quite a bit of time searching for the cause. On the contrary, if you express any state as a function of other states, then even if your variable takes the wrong value, you always know where to look for the error - in the function of calculation or the data it receives.
Continuing to develop the theme, we note that such a function does not simply allow one state to be calculated on the basis of the others, this function is a dependency between states declared in the code, an invariant that must be kept up to date throughout the life of the application. That is, if the dependency state changes, then all dependent states should be updated automatically, without relying on the attentiveness and hard work of the developer.
Reactive architecture greatly simplifies support.
Often, when developing frameworks, the main attention is paid to such things as "simplicity", "flexibility" and "speed", but such important quality as "investigability" is almost ignored. It is assumed that the developer who started working with him has already read all the documentation, understood it correctly and is a very talented person in general. But the truth of life lies in the fact that the documentation is often incomplete, poorly structured, in a non-native language and requires a lot of time to complete the study, which is always lacking, and the developer often does not have ten years of experience and a thorough knowledge of patterns. Therefore, the best documentation is examples. The best examples are tests. And the best way to understand how it works is to disassemble. So it is important not to isolate the internal state, but to provide easy and convenient access to it. Through the console, through a debugger, through logs. It is necessary to name the same entities equally in different places: the names of variables in different modules, the names of modules in different contexts, the names of classes in scripts, styles and layout, etc. And also it is necessary to add information about not obvious connections between entities. For example, look at this code:
<div class="my-panel"> <button class="my-button_danger"></button> </div> How can you guess that both of these elements were added to the tree by the my-page component? Add the missing information:
<div class="my-page_content my-panel"> <button class="my-page_remove my-button_danger"></button> </div> Now it became clear where to dig, and who is to blame for the fact that the page delete button is not on that panel. Another striking example is associated with parsing. When you use JSON.parse, you lose the information about the location of the data in the source file. Therefore, when during the subsequent validation you find an error, you cannot tell the user "On such and such a line not a valid e-mail was found," but you have to invent crutches like "Nevalidny e-mail on the way departaments [2] .users [14] .mails [0] ". On the contrary, when using the tree format, you can always get information about the place of its declaration from the node:
core.exception.RangeError@./jin/tree.d(271): Range violation ./examples/test.jack.tree#87:20 cut-tail ./examples/test.jack.tree#87:11 cut-head ./examples/test.jack.tree#88:7 body ./examples/test.jack.tree#85:6 jack ./examples/test.jack.tree#83:0 test ./examples/test.jack.tree#1:1 Bread crumbs do not interfere either in the user interface or in the program code.
Component decomposition

The most important aspect of any framework is the implementation of a single interaction protocol. Actually, in the case of a micromodular framework, the only thing the core does is to organize the interaction of modules, both standard and custom. In the case of ui framework, its main task is to organize the interaction of components - such mini applications, which themselves can work, but they also support some API for interacting with other components, allowing you to build more complex components from them like legoes; full applications. Let's take a look at what modern frameworks offer us ...
AngularJS

Ad components:
angular.module( 'my' ).component( 'panel' , { transclude : { myPanelHead : '?head', myPanelBody : 'body' }, template: ` <div class="my-panel"> <div class="my-panel-header" ng-transclude="head"></div> <div class="my-panel-bodier" ng-transclude="body">No data</div> </div> ` } ) To declare the components, we needed to write some scripts, some templates and attach some config describing the API to them. It turned out quite verbose and confusing. It is necessary to keep in mind that ng-transclude contains not just text, but the name of the parameter, the value of which will be inserted inside the element. It is necessary to carefully support the mapping of external parameter names to internal ones. It is necessary for all elements to arrange classes so that they can be stylized. And now we will try to use this component:
<body ng-app="my"> <my-panel> <my-panel-head>My tasks</my-panel-header> <my-panel-body> <my-task-list assignee="me" status="todo" /> </my-panel-body> </my-panel> </body> As you can see, for each parameter we had to add additional tags. Since all these tags are in the same namespace, we had to add a prefix to each parameter with the name of the component (these tags will be inserted into the result tree for some reason, as they are). Yes, in the simplest cases, you can use the attributes, but if there is a chance that you will need to insert an embedded component, and not just a line of text, then you have to use such bulky constructions.
And now a typical situation: there is a ready-made component and we need to customize it slightly. For example, add a basement. The trouble with many such frameworks is that the components implemented on them are too rigid and isolated. You cannot simply inherit from a component and slightly change its behavior. Instead, you need to either make changes to the source component itself, complicating it and making you know too much:
angular.module( 'app' ).component( 'myPanelExt' , { scope : { myPanelShowFooter : '=' }, transclude : { myPanelHead : '?head', myPanelBody : 'body', myPanelFoot : '?foot' }, template: ` <div class="my-panel" my-panel-show-footer="true"> <div class="my-panel-header" ng-transclude="head"></div> <div class="my-panel-bodier" ng-transclude="body">No data</div> <div class="my-panel-header" ng-transclude="foot" ng-if="myPanelShowFooter"></div> </div> ` } ) Either copy-paste, creating a new component very similar to the old one, but slightly different:
angular.module( 'app' ).component( 'myPanelExt' , { transclude : { myPanelHead : '?head', myPanelBody : 'body', myPanelFoot : '?foot' }, template: ` <div class="my-panel"> <div class="my-panel-header" ng-transclude="head"></div> <div class="my-panel-bodier" ng-transclude="body">No data</div> <div class="my-panel-header" ng-transclude="foot"></div> </div> ` } ) ReactJS

Ad components:
class MyPanel extends React.Component { render() { return ( <div class="my-panel"> <div class="my-panel-header">{this.props.head}</div> <div class="my-panel-bodier">{this.props.body}</div> </div> ) } } Already much better, although there is still an inseparable start on JS. Why is that bad? Because not everywhere JS is an optimal programming language. In the web you have no choice. But under iOS, Swift or ObjectiveC would be better, under Android - Java, and under desktops the choice of languages is generally huge, but the light on the JS has not come together. We still have the problem of stiffness and isolation of the components, so with customization everything is almost as bad as in AngularJS. "Almost", because we can break up our pattern into small pieces, which will allow us to further redefine them:
class MyPanel extends React.Component { header() { return <div class="my-panel-header">{this.props.head}</div> } bodier() { return <div class="my-panel-bodier">{this.props.body}</div> } childs() { return [ this.header() , this.bodier() ] } render() { return <div class="my-panel">{this.childs()}</div> } class MyPanelExt extends MyPanel { footer() { return <div class="my-panel-footer">{this.props.foot}</div> } childs() { return [ this.header() , this.bodier() , this.footer() ] } } We got a good flexibility, but lost the visibility of the hierarchy of elements. And the use of XML syntax in this case becomes redundant. Especially extravagant would be the use of the component without splitting into functions:
class MyApp extends MyPanel { render() { return ( <MyPanel head="My Tasks" body={ <MyTaskList assignee="me" status="todo" /> } /> ) } } Polymer

Ad components:
<dom-module id="my-panel"> <template> <div class="header"> <content select="[my-panel-head]" /> </div> <div class="bodier"> <content /> </div> </template> <script> Polymer({ is: 'my-panel' }) </script> </dom-module> Obtaining parameters through selectors is striking, which makes the use of a component not very intuitive:
<link rel="import" href="../../my/panel/my-panel.html"> <dom-module id="my-app"> <template> <my-panel> <div my-panel-head>My tasks</div> <my-task-list assignee="me" status="todo" /> </my-panel> </template> <script> Polymer({ is: 'my-app' }) </script> </dom-module> In general, the description of the component is similar to a hack that takes someone else's tree and modifies it beyond recognition. In the intricacies of the real and the shadow tree is quite difficult to understand.
Inheritance is not supported yet, so we use the power of copy-paste:
<dom-module id="my-panel-ext"> <template> <div class="header"> <content select="[my-panel-head]" /> </div> <div class="bodier"> <content /> </div> <div class="footer"> <content select="[my-panel-foot]" /> </div> </template> <script> Polymer({ is: 'my-panel-ext' }) </script> </dom-module> Separately, it is worth noting the problem of stylization. Each component draws with it its own styles, which by default are isolated from all other components. On the one hand, this allows the use of short class names within one component, on the other hand, it adds problems when it is necessary to customize the visualization of the components in a particular context of use.
Spherical perfect framework

Let's try to formulate what is needed to describe a component. No matter how much you want to reuse ready-made components as they are when building an interface, they always need to be customized. That is, the component description must support inheritance. In order for components to be able to assemble arbitrary interfaces, it is required that they can be inserted into each other in an arbitrary manner. That is, we need polymorphism. In order for the same components to be used from different languages, their description should be declarative, and the syntax should be as simple and clear as possible. Well, nobody canceled static typing.
As shown above, XML does not meet these requirements at all. In general, all attempts to make an XML template from XML look like a cross between a hedgehog and a snake. That XML is embedded in JS, then JS is embedded in XML, or even invented its own primitive programming language with XML syntax.
Let's use the tree syntax to declare a simple component:
$my_panel $mol_view Here we simply say that the component $ my_panel is the successor of $ mol_view. We do not care how and in what language $ mol_view is implemented, but we argue that $ mol_panel should be implemented in the same way. For example, the above description may expand into the following DOM tree:
<div id="$my_panel.Root(0)" my_panel mol_view></div> As you can see, some attributes were automatically generated for the element. First of all, this id is the global identifier of the component. It is not for nothing that it has such a strange appearance, because it can be copied and pasted into the console, thereby obtaining direct access to the component instance for this responsible item. This greatly simplifies the debugging and investigation of someone else's code. Next are the attributes intended primarily for styling. You can define styling for the base component, and then reload it for the heir:
[mol_view] { animation : mol_view_showing 1s ease; } [my_panel] { animation : none; } As you can see, we didn’t even need the css preprocessor to implement CSS inheritance. That is, for the declaration of inheritance, we have only one place in the code - this is the description of the component. And you don’t need to be separately inherited in JS, separately in CSS, separately in HTML. According to this description, a TypeScript class for this component can also be generated:
module $.$$ { export class $my_panel extends $.$mol_view { } } The $ mol_view component can provide a standard sub property for defining a list of child nodes. So let's add the ability to declare and overload properties:
$my_panel $mol_view head / body / \No data Head $mol_view sub <= head / Body $mol_view sub <= body / sub <= Head - <= Body - Here we declared the head and body properties, which are the contents of the header and body of the panel. After the name we specified the default value. For a component to be self-sufficient, the default values must always be. , Head Body, $mol_view sub — . , , :
$my_app $my_panel head / \My tasks body / <= Tasks $my_task_list assignee \me status \todo , ReactJS, . , :
$my_panel $mol_view sub / <= Head $mol_view sub <= head / <= Body $mol_view sub <= body / \No data . , bem-like :
<div id="$my_panel.Root(0)" my_panel mol_view> <div id="$my_panel.Root(0).Head()" mol_view my_panel_head></div> <div id="$my_panel.Root(0).Body()" mol_view my_panel_body></div> </div> , . :
$my_panel_ext $my_panel sub / <= Head - <= Body - <= Foot $mol_view sub <= foot / ? , - . , . TypeScript, :
namespace $.$$ { export class $my_panel extends $.$my_panel { @ $mol_mem foot_showed( next = false ) { return next } sub(){ return [ this.Head() , this.Body() , ... this.foot_chowed() ? [ this.Foot() ] : [] , ] } } } , . , , :
$my_panel_demo $mol_demo_large sub / <= Simple $mol_panel foot_showed false head / \I am simple panel <= Footered $mol_panel foot_showed true head / \I am panel with footer typescript , . IDE view.tree , , , , , .
Performance
, , . - . , . , , , . . — , , . , , , . , , ( — ) , . , , , .
jQuery : , HTML , , . , . , . , , . , , , . — , .
, ReactJS — , DOM , JS , DOM. , , : , , , , , . AngularJS , , - , , , . Polymer 100500 .
, , , , — .
. . , . — ToDoMVC . — , . ToDoMVC , , ToDoMVC Benchmark .


2 :
- 100 . setTimeout, 100 . 0 100. .
- , . setTimeout 100 . . . , , , .
, , - .
:

2 . . 2.5, 3.
10 .
Call to action
Enough tolerating this! , , , , , .
Main characteristics
- .
- .
- .
- .
- Compact size.
- .
- .
- .
- / .
')
Source: https://habr.com/ru/post/276747/
All Articles