Meet Apache Spark
Hello, dear readers!
We are finally starting to translate a serious book about the Spark framework:

')
Today we bring to your attention the translation of the review article on the possibilities of Spark, which, we believe, can rightfully be called a bit stunning.
I first heard about Spark at the end of 2013, when I became interested in Scala - Spark was written in this language. Somewhat later, I began to develop, for the sake of interest, a project from the field of Data Science, dedicated to predicting the survival of the passengers of the Titanic . It turned out to be a great way to learn about Spark programming and its concepts. I strongly recommend getting to know all novice Spark developers .
Today, Spark is used in many of the largest companies, such as Amazon, eBay and Yahoo! Many organizations operate Spark in clusters of thousands of nodes. According to the Spark FAQ, the largest of these clusters has more than 8,000 nodes. Indeed, Spark is a technology that is worth taking note of and exploring.

This article offers an introduction to Spark, examples of usage, and sample code.
What is Apache Spark? Introduction
Spark is an Apache project that is positioned as a tool for "lightning-fast cluster computing." The project is being developed by a thriving free community, currently the most active of the Apache projects.
Spark provides a fast and versatile data processing platform. Compared to Hadoop, Spark accelerates the work of programs in memory by more than 100 times, and on disk - more than 10 times.
In addition, Spark code is written faster, since here you will have more than 80 high-level operators. To appreciate this, let's look at the analogue “Hello World!” From the world of BigData: an example of word counting (Word Count). A program written in Java for MapReduce would contain about 50 lines of code, and in Spark (Scala) we need only:
When studying Apache Spark, it is worth noting another important aspect: it provides a ready-made interactive shell (REPL). With the help of REPL, you can test the result of executing each line of code without having to first program and complete the entire task. Therefore, it is possible to write ready-made code much faster, moreover, situational analysis of data is provided.
In addition, Spark has the following key features:
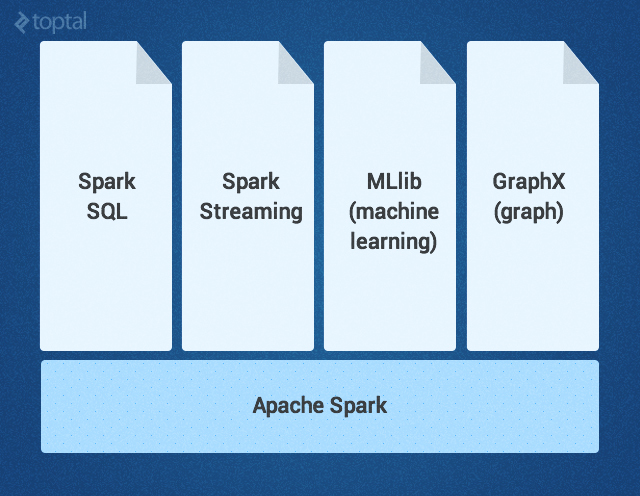
The Spark core is complemented by a set of powerful high-level libraries that seamlessly fit into it within the framework of the same application. Currently, such libraries include SparkSQL, Spark Streaming, MLlib (for machine learning), and GraphX — all of which will be discussed in detail in this article. Other libraries and Spark extensions are also under development.
Spark Core
The Spark core is a basic engine for large-scale parallel and distributed data processing. The kernel is responsible for:
Spark introduces the concept of RDD (sustainable distributed data set) - an immutable fault-tolerant distributed collection of objects that can be processed in parallel. RDD can contain objects of any type; RDD is created by loading an external data set or distributing a collection from the main program (driver program). RDD supports two types of operations:
Transformations in Spark are carried out in the "lazy" mode - that is, the result is not calculated immediately after the transformation. Instead, they simply “memorize” the operation to be performed and the data set (for example, a file) on which to perform the operation. Calculation of transformations occurs only when an action is invoked, and its result is returned to the main program. Thanks to this design, Spark’s efficiency is enhanced. For example, if a large file was converted in various ways and passed to the first action, Spark will process and return the result only for the first line, and will not work on the whole file in this way.
By default, each transformed RDD can be recalculated whenever you perform a new action on it. However, RDDs can also be stored in memory for a long time using the storage or caching method; in this case, Spark will keep the necessary elements on the cluster, and you will be able to request them much faster.
SparkSQL
SparkSQL is a Spark component that supports querying data either using SQL or using the Hive Query Language . The library originated as an Apache Hive port for working on top of Spark (instead of MapReduce), and is now integrated with the Spark stack. It not only provides support for various data sources, but also allows interweaving SQL queries with code transformations; It turns out a very powerful tool. The following is an example of a Hive-compatible query:
Spark streaming
Spark Streaming supports real-time streaming processing; Such data can be log files of the working web server (for example, Apache Flume and HDFS / S3), information from social networks, for example, Twitter, as well as various message queues such as Kafka. "Under the hood" Spark Streaming receives input data streams and splits the data into packets. They are further processed by the Spark engine, after which the final data stream is generated (also in batch form) as shown below.

The Spark Streaming API exactly corresponds to the Spark Core API, so programmers can easily work with both packet and stream data at the same time.
MLlib
MLlib is a machine learning library that provides various algorithms designed for horizontal scaling on a cluster for classification, regression, clustering, co-filtering, etc. Some of these algorithms also work with streaming data — for example, linear regression using the usual least squares method or k-means clustering (the list will expand soon). Apache Mahout (machine learning library for Hadoop) has already left MapReduce, now its development is being done in conjunction with Spark MLlib.
Graphx
GraphX is a library for manipulating graphs and performing parallel operations with them. The library provides a universal tool for ETL, research analysis and graph-based iterative computing. In addition to the built-in operations for graph manipulation, a library of ordinary algorithms for working with graphs, for example, PageRank, is also provided here.
How to use Apache Spark: event detection example
Now that we’ve figured out what Apache Spark is, let's think about what tasks and problems will be solved most effectively with it.
Recently I came across an article about an experiment on recording earthquakes by analyzing the flow of Twitter. By the way, the article demonstrated that this method allows one to learn about an earthquake more quickly than from reports of the Japanese Meteorological Agency. Although the technology described in the article is not similar to Spark, this example seems to me interesting in the context of Spark: it shows how you can work with simplified code fragments and without code-glue.
First, it will be necessary to filter out those tweets that seem relevant to us — for example, with the mention of “earthquake” or “tremors”. This can be done easily with Spark Streaming, like this:
Then we will need to perform a certain semantic analysis of tweets to determine if the jolts mentioned in them are relevant. Probably, such tweets as “Earthquake!” Or “Now shakes” will be considered positive results, and “I am at a seismological conference” or “Yesterday was shaking terribly” - negative. The authors of the article used the support vector machine (SVM) for this purpose. We will do the same, just implement the streaming version as well . The resulting sample code from MLlib would look something like this:
If the percentage of correct predictions in this model suits us, we can proceed to the next stage: respond to the detected earthquake. For this, we will need a certain number (density) of positive tweets received during a certain period of time (as shown in the article). Please note: if tweets are accompanied by geolocation information, then we can determine the coordinates of the earthquake. Armed with this knowledge, we can use SparkSQL and query the existing Hive table (where data about users who want to receive notifications about earthquakes are stored), retrieve their email addresses and send them personalized warnings like this:
Other uses for Apache Spark
Potentially, the scope of application of Spark, of course, is far from being limited to seismology.
Here is an indicative (that is, by no means exhaustive) selection of other practical situations where high-speed, diverse and bulky processing of big data is required, for which Spark is so well suited:
In the gaming industry: processing and detection of patterns describing game events coming in a continuous stream in real time; as a result, we can immediately react to them and make good money on it, using player retention, targeted advertising, auto-correction of the difficulty level, etc.
In e-commerce, real-time transaction information can be transferred to a stream clustering algorithm, for example, by k-average or be subjected to joint filtering, as in the case of ALS . Results can even be combined with information from other unstructured data sources — for example, customer reviews or reviews. Gradually, this information can be used to improve the recommendations in the light of new trends.
In the financial or security field, the Spark stack can be used to detect fraud or intruders, or to authenticate with risk analysis. Thus, you can get first-class results by collecting huge amounts of archived logs, combining them with external data sources, for example, with information about data leaks or hacked accounts (see, for example, https://haveibeenpwned.com/ ), and also use connection / query information, focusing, for example, on geolocation by IP or on time data
Conclusion
So, Spark helps to simplify non-trivial tasks associated with high computational load, processing large amounts of data (both in real time and archived), both structured and unstructured. Spark provides seamless integration of complex features — for example, machine learning and algorithms for working with graphs. Spark carries the processing of Big Data to the masses. Try it - you will not regret!
We are finally starting to translate a serious book about the Spark framework:
')
Today we bring to your attention the translation of the review article on the possibilities of Spark, which, we believe, can rightfully be called a bit stunning.
I first heard about Spark at the end of 2013, when I became interested in Scala - Spark was written in this language. Somewhat later, I began to develop, for the sake of interest, a project from the field of Data Science, dedicated to predicting the survival of the passengers of the Titanic . It turned out to be a great way to learn about Spark programming and its concepts. I strongly recommend getting to know all novice Spark developers .
Today, Spark is used in many of the largest companies, such as Amazon, eBay and Yahoo! Many organizations operate Spark in clusters of thousands of nodes. According to the Spark FAQ, the largest of these clusters has more than 8,000 nodes. Indeed, Spark is a technology that is worth taking note of and exploring.
This article offers an introduction to Spark, examples of usage, and sample code.
What is Apache Spark? Introduction
Spark is an Apache project that is positioned as a tool for "lightning-fast cluster computing." The project is being developed by a thriving free community, currently the most active of the Apache projects.
Spark provides a fast and versatile data processing platform. Compared to Hadoop, Spark accelerates the work of programs in memory by more than 100 times, and on disk - more than 10 times.
In addition, Spark code is written faster, since here you will have more than 80 high-level operators. To appreciate this, let's look at the analogue “Hello World!” From the world of BigData: an example of word counting (Word Count). A program written in Java for MapReduce would contain about 50 lines of code, and in Spark (Scala) we need only:
sparkContext.textFile("hdfs://...") .flatMap(line => line.split(" ")) .map(word => (word, 1)).reduceByKey(_ + _) .saveAsTextFile("hdfs://...") When studying Apache Spark, it is worth noting another important aspect: it provides a ready-made interactive shell (REPL). With the help of REPL, you can test the result of executing each line of code without having to first program and complete the entire task. Therefore, it is possible to write ready-made code much faster, moreover, situational analysis of data is provided.
In addition, Spark has the following key features:
- Currently provides APIs for Scala, Java, and Python, as well as support for other languages (for example, R)
- Well integrated with the Hadoop ecosystem and data sources (HDFS, Amazon S3, Hive, HBase, Cassandra, etc.)
- Can work on clusters running Hadoop YARN or Apache Mesos, and also work offline
The Spark core is complemented by a set of powerful high-level libraries that seamlessly fit into it within the framework of the same application. Currently, such libraries include SparkSQL, Spark Streaming, MLlib (for machine learning), and GraphX — all of which will be discussed in detail in this article. Other libraries and Spark extensions are also under development.
Spark Core
The Spark core is a basic engine for large-scale parallel and distributed data processing. The kernel is responsible for:
- memory management and recovery after failures
- cluster scheduling
- interaction with storage systems
Spark introduces the concept of RDD (sustainable distributed data set) - an immutable fault-tolerant distributed collection of objects that can be processed in parallel. RDD can contain objects of any type; RDD is created by loading an external data set or distributing a collection from the main program (driver program). RDD supports two types of operations:
- Transformations are operations (eg, mapping, filtering, merging, etc.) performed on RDD; the result of the transformation becomes the new RDD containing its result.
- Actions are operations (for example, reduction, counting, etc.) that return the value resulting from some calculations in RDD.
Transformations in Spark are carried out in the "lazy" mode - that is, the result is not calculated immediately after the transformation. Instead, they simply “memorize” the operation to be performed and the data set (for example, a file) on which to perform the operation. Calculation of transformations occurs only when an action is invoked, and its result is returned to the main program. Thanks to this design, Spark’s efficiency is enhanced. For example, if a large file was converted in various ways and passed to the first action, Spark will process and return the result only for the first line, and will not work on the whole file in this way.
By default, each transformed RDD can be recalculated whenever you perform a new action on it. However, RDDs can also be stored in memory for a long time using the storage or caching method; in this case, Spark will keep the necessary elements on the cluster, and you will be able to request them much faster.
SparkSQL
SparkSQL is a Spark component that supports querying data either using SQL or using the Hive Query Language . The library originated as an Apache Hive port for working on top of Spark (instead of MapReduce), and is now integrated with the Spark stack. It not only provides support for various data sources, but also allows interweaving SQL queries with code transformations; It turns out a very powerful tool. The following is an example of a Hive-compatible query:
// sc – SparkContext. val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc) sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)") sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src") // HiveQL sqlContext.sql("FROM src SELECT key, value").collect().foreach(println) Spark streaming
Spark Streaming supports real-time streaming processing; Such data can be log files of the working web server (for example, Apache Flume and HDFS / S3), information from social networks, for example, Twitter, as well as various message queues such as Kafka. "Under the hood" Spark Streaming receives input data streams and splits the data into packets. They are further processed by the Spark engine, after which the final data stream is generated (also in batch form) as shown below.
The Spark Streaming API exactly corresponds to the Spark Core API, so programmers can easily work with both packet and stream data at the same time.
MLlib
MLlib is a machine learning library that provides various algorithms designed for horizontal scaling on a cluster for classification, regression, clustering, co-filtering, etc. Some of these algorithms also work with streaming data — for example, linear regression using the usual least squares method or k-means clustering (the list will expand soon). Apache Mahout (machine learning library for Hadoop) has already left MapReduce, now its development is being done in conjunction with Spark MLlib.
Graphx
GraphX is a library for manipulating graphs and performing parallel operations with them. The library provides a universal tool for ETL, research analysis and graph-based iterative computing. In addition to the built-in operations for graph manipulation, a library of ordinary algorithms for working with graphs, for example, PageRank, is also provided here.
How to use Apache Spark: event detection example
Now that we’ve figured out what Apache Spark is, let's think about what tasks and problems will be solved most effectively with it.
Recently I came across an article about an experiment on recording earthquakes by analyzing the flow of Twitter. By the way, the article demonstrated that this method allows one to learn about an earthquake more quickly than from reports of the Japanese Meteorological Agency. Although the technology described in the article is not similar to Spark, this example seems to me interesting in the context of Spark: it shows how you can work with simplified code fragments and without code-glue.
First, it will be necessary to filter out those tweets that seem relevant to us — for example, with the mention of “earthquake” or “tremors”. This can be done easily with Spark Streaming, like this:
TwitterUtils.createStream(...) .filter(_.getText.contains("earthquake") || _.getText.contains("shaking")) Then we will need to perform a certain semantic analysis of tweets to determine if the jolts mentioned in them are relevant. Probably, such tweets as “Earthquake!” Or “Now shakes” will be considered positive results, and “I am at a seismological conference” or “Yesterday was shaking terribly” - negative. The authors of the article used the support vector machine (SVM) for this purpose. We will do the same, just implement the streaming version as well . The resulting sample code from MLlib would look something like this:
// , , LIBSVM val data = MLUtils.loadLibSVMFile(sc, "sample_earthquate_tweets.txt") // (60%) (40%). val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L) val training = splits(0).cache() val test = splits(1) // , val numIterations = 100 val model = SVMWithSGD.train(training, numIterations) // , model.clearThreshold() // val scoreAndLabels = test.map { point => val score = model.predict(point.features) (score, point.label) } // val metrics = new BinaryClassificationMetrics(scoreAndLabels) val auROC = metrics.areaUnderROC() println("Area under ROC = " + auROC) If the percentage of correct predictions in this model suits us, we can proceed to the next stage: respond to the detected earthquake. For this, we will need a certain number (density) of positive tweets received during a certain period of time (as shown in the article). Please note: if tweets are accompanied by geolocation information, then we can determine the coordinates of the earthquake. Armed with this knowledge, we can use SparkSQL and query the existing Hive table (where data about users who want to receive notifications about earthquakes are stored), retrieve their email addresses and send them personalized warnings like this:
// sc – SparkContext. val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc) // sendEmail – sqlContext.sql("FROM earthquake_warning_users SELECT firstName, lastName, city, email") .collect().foreach(sendEmail) Other uses for Apache Spark
Potentially, the scope of application of Spark, of course, is far from being limited to seismology.
Here is an indicative (that is, by no means exhaustive) selection of other practical situations where high-speed, diverse and bulky processing of big data is required, for which Spark is so well suited:
In the gaming industry: processing and detection of patterns describing game events coming in a continuous stream in real time; as a result, we can immediately react to them and make good money on it, using player retention, targeted advertising, auto-correction of the difficulty level, etc.
In e-commerce, real-time transaction information can be transferred to a stream clustering algorithm, for example, by k-average or be subjected to joint filtering, as in the case of ALS . Results can even be combined with information from other unstructured data sources — for example, customer reviews or reviews. Gradually, this information can be used to improve the recommendations in the light of new trends.
In the financial or security field, the Spark stack can be used to detect fraud or intruders, or to authenticate with risk analysis. Thus, you can get first-class results by collecting huge amounts of archived logs, combining them with external data sources, for example, with information about data leaks or hacked accounts (see, for example, https://haveibeenpwned.com/ ), and also use connection / query information, focusing, for example, on geolocation by IP or on time data
Conclusion
So, Spark helps to simplify non-trivial tasks associated with high computational load, processing large amounts of data (both in real time and archived), both structured and unstructured. Spark provides seamless integration of complex features — for example, machine learning and algorithms for working with graphs. Spark carries the processing of Big Data to the masses. Try it - you will not regret!
Source: https://habr.com/ru/post/276675/
All Articles