Recommendations on stream
Hello!
Today we will talk about how using streaming data processing you can increase the quality of recommendations and reduce the response time of the entire recommender system by 5 times. It will be about one of our clients - the Rutube video streaming service.

First, a few words about Rutube itself and why it needs recommendations. First, at the time of this writing, our recommendation system stores data on 51.76 million users and 1.26 million items, that is, video. Obviously, no user will be able to view all videos in the foreseeable future. He comes to the aid of a recommender system. Secondly, Rutube earns on display of advertising. One of the key business indicators of the company is the time spent by the user on the site. Rutube maximizes this figure. The recommendation system helps to do this. And, thirdly, already a feature of the Rutube itself. Part of the content is commercial video copyright holders. For example, TNT has its own channel, on which they regularly post releases of their programs. When a new release of “House-2” or “Dances” is released, people rush to watch them. The video has a “viral” character. The recommendation system helps other users to track and show such videos.
')
We made the first version of the recommendation system for Rutube in E-Contenta in May 2015. It represented the following: item-based collaborative filtration with recalculation of recommendations every n times, where n is a number from the Fibonacci series . That is, viewing each video was an event and, if the sequence number of this event was in the Fibonacci series, we recalculated the measures of proximity of this video with other videos. It was implemented using the following stack: Tornado + Celery (where the broker is RabbitMQ ) + MongoDB . That is, the data went to Tornado, from there through Celery publisher to RabbitMQ, and from there through Celery consumer - were processed and sent to MongoDB. We must respond to the request for recommendations for the user within 1 second (SLA).
At first, the system worked well: we accepted the flow of events, processed them, and calculated recommendations. However, the following problems appeared quite soon.
First, the technical problem. Recalculation of recommendations for popular videos “put” the entire system. A huge number of events from Mongo scored all the RAM, and the processing of all these events “scored” all the cores. At such moments, we could neither give already calculated recommendations, nor recalculate new ones, breaking the SLA.
Secondly, the business problem. Recounting the recommendations only every i-th time, where i belongs to the Fibonacci series, we could not immediately track the viral video. When we finally reached it, each time we had to do a full recount, which took too much time and resources, while the number of events continued to grow.
Third, an algorithmic problem called the implicit feedback problem. Any recommendation system is based on ratings, or ratings. We collected only video views, that is, in fact, we had a binary rating system: 1 - watched the video, 0 - did not watch.
As a solution, the transition to full real-time was suggested, but for this, an efficient algorithm, which was inexpensive in terms of resources, was needed. The main inspiration was the article published by Tencent. We took the algorithm described by them as the basis for our new recommendation engine.
The new algorithm was the classic item based CF, where the cosine of the angle was used as a measure of proximity:
%20%3D%20%5Cfrac%7B%5Cvec%7Bi_p%7D%5Ccdot%5Cvec%7Bi_q%7D%7D%7B%7C%5Cvec%7Bi_p%7D%7C%5Ccdot%7C%5Cvec%7Bi_q%7D%7C%7D%20%3D%20%5Cfrac%7B%5Csum_%7Bu%5Cin%7BU%7D%7Dr_%7Bu%2Cp%7Dr_%7Bu%2Cq%7D%7D%7B%5Csqrt%7B%5Csum%7Br%5E2_%7Bu%2Cp%7D%7D%7D%5Csqrt%7B%5Csum%7Br%5E2_%7Bu%2Cq%7D%7D%7D%7D)
If you look closely at the formula, you can see that it consists of three sums: the sum of the joint ratings in the numerator and two sums of squares of the ratings in the denominator. Replacing them with simpler concepts, we get the following:
%20%3D%20%5Csum%7Br_%7Bu%2Cp%7D%7D)
%20%3D%20%5Csum_%7Bu%5Cin%7BU%7D%7D%5Ctextit%7Bco-rating%7D(i_p%2Ci_q))
%20%3D%20%5Cfrac%7BpairCount(i_p%2Ci_q)%7D%7B%5Csqrt%7BitemCount(i_p)%7D%5Csqrt%7BitemCount(i_q)%7D%7D)
And now let's think about what happens when recommendations are recalculated when a new event (new assessment) is received? Right! We only increase our amounts by the resulting value. Thus, a new measure of proximity can be represented as follows:
%20%3D%20%5Cfrac%7BpairCount'(i_p%2Ci_q)%7D%7B%5Csqrt%7BitemCount'(i_p)%7D%5Csqrt%7BitemCount'(i_q)%7D%7D%20%3D%20%5Cfrac%7BpairCount(i_p%2Ci_q)%20%2B%20%5Ctriangle%5Ctextit%7Bco-rating%7D(i_p%2Ci_q)%7D%7B%5Csqrt%7BitemCount(i_p)%20%2B%20%5Ctriangle%7B%7Dr_%7Bu_p%7D%7D%5Csqrt%7BitemCount(i_q)%20%2B%20%5Ctriangle%7B%7Dr_%7Bu_q%7D%7D%7D)
From here follows a very important conclusion. We do not need to recalculate all amounts each time. It is enough to store them and increase each new value. This principle is called incremental update. Thanks to him, the load is significantly reduced when recalculating recommendations, and it becomes possible to use such an algorithm in real-time processing.
In the same article , a solution was proposed for the implicit feedback problem: to evaluate each specific user action when watching a video. For example, separately evaluate the beginning of viewing, viewing to the middle or to the end, pause, rewind, etc. Here is how we set the weights now:
With multiple user actions with one video, the maximum rating is taken.
Also now we take into account the popular (trending) video. Each video has a counter that is incremented by 1 when an event is received that is associated with it. The most popular videos are in the top 20. When each new event arrives, we check if the video is in the top 20, its counter increases, if not, all videos in the top 20 counter decrease by 1. Thus, a rather dynamic list is obtained, with which it is easy to track the viral video . We keep this list for each region. That is, we recommend different popular videos to users from different regions.
When requesting recommendations for the user, issuance consists of 85% of personal recommendations and 15% of popular videos.
We have decided on the algorithm, now we need to choose the technologies with which it can be implemented. To summarize all the cases we found in stream processing, the stack of technologies used looks like this:
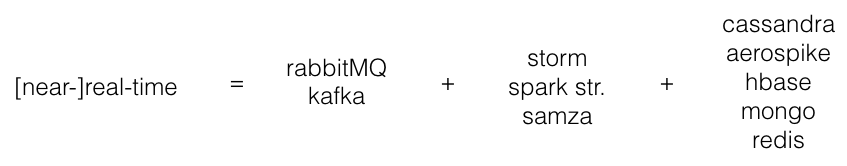
That is, we pound all the events in message broker, then process them in parallel in the stream processing engine and add the results to the key-value database, from where we read them when we receive the request. It remains to choose a specific option for each item.
We already had RabbitMQ, and we were quite pleased with it. However, most streaming engines support Kafka from the box. We were not against the transition at all, especially lately Kafka gained serious momentum, proved itself well and is generally considered to be quite a versatile and reliable tool, having mastered that, you can still use it a lot.
As a streaming engine considered all 3 options. However, they immediately introduced one restriction - all code should be written only in Python. All members of our team know him well, plus Python has all the libraries we need, and those that weren't there, we wrote ourselves. Therefore, Samza disappeared immediately, as it only supports Java. At first they wanted to try Storm, but after digging into the documentation, we found out that some of the code (topology) would be written in Java, and only the code for the processing nodes (bolts) could be written in Python. Later, we discovered an excellent Python wrapper for Storm called streamparse . Who needs Storm completely in Python, we recommend! As a result, the choice was Spark. First, we already knew him. And secondly, it fully supported Python. And thirdly, it is really impressive how rapidly they are developing .
The choice of database was made immediately. Despite the fact that we have experience with each of them, we have a pet. This is Aerospike. Aerospike reveals its full potential on servers with SSD drives. It bypasses the Linux file system and writes directly to the SSD in separate blocks. Due to this, a performance of 1 million TPS per node is achieved, and the response time of 99% of requests is <1 ms. We have used it more than once and are pretty good at preparing it (although there is not much to cook there too :).
As a result, our stack looks like this:

Just a couple of words about the choice between the Storm and Spark, all of a sudden someone will come in handy.
Spark streaming is not really a real-time engine, it’s rather near real-time, as it uses mini-batching. That is, the data stream is divided into mini-batches, the size of the specified number of seconds and processed in parallel. For those familiar with concepts in Spark, a mini-batch is nothing but RDD . Storm is real real-time. Received events are processed immediately (although Storm can also be configured to mini-batching using Trident). In summary, the Storm is lower latency, and Spark is higher throughput. If you have a hard limit on latency, then you should choose Storm. For example, for security applications. Otherwise Spark will be more than enough. We have been using it for more than a month in production, with proper cluster tuning, it works like a clock. There is another opinion that Spark is more fault tolerant. However, in our opinion, it should be supplemented, Spark is more fault tolerant out of the box. With due desire and skill, and Storm can be brought to this level.
And the most important thing. Did it all make sense? Had Let's start with the quality of recommendations. We use the online quality metric, which we measure, whether the video actually viewed by the user was included in the list recommended by us and where it was located there. The distribution is as follows.
For personal recommendations only (item-item CF):

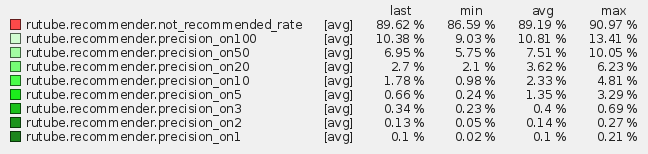
For only popular items (trending):
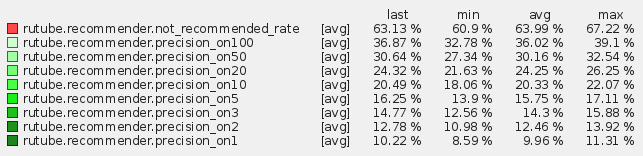
For hybrid recommendations (85% item-item CF and 15% trending):
This is the last option we use in production, since the metrics on it are maximal. That is, about 10% of the videos viewed by users, we recommend it in the first place! About 36% are in the top 100. If these numbers do not tell you anything, you can look at the distribution of popular videos. If we recommend only popular videos to the user, we will guess only 0.1% of all the videos he watched. Which, in turn, is also not bad when compared with the random distribution, where the probability of guessing any video will be equal to 1 / (1.26 million).
For greater clarity, below is a graph of our metrics:
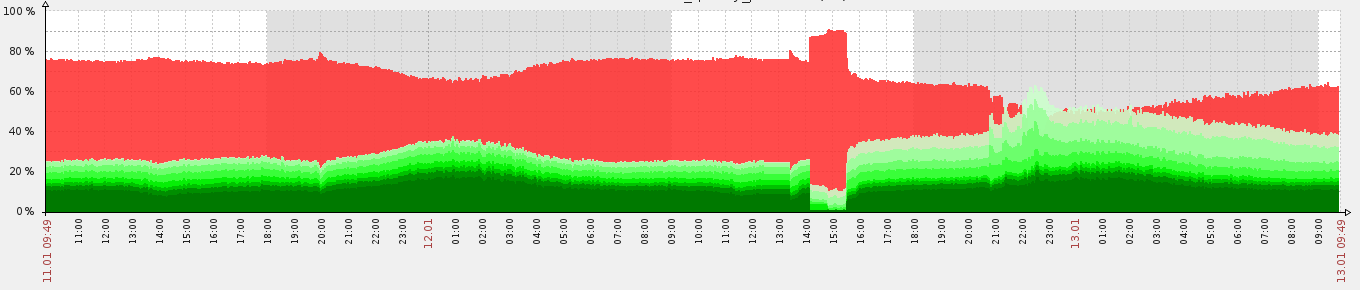
Piece 12.02 from 14:00 to 15:30, where the most unsolved (red) is just testing recommendations with only trending items. Before that - item-item CF, and after - a hybrid model. As you can see, thanks to “realtime”, our recommendation system quickly adapts to the new configuration. By the way when you start the system from scratch, it goes to the above figures for half an hour.
Due to the transition from MongoDB to Aerospike, the average response time to a request for recommendation has fallen. Below is the moment of switching from the old engine to the new one:
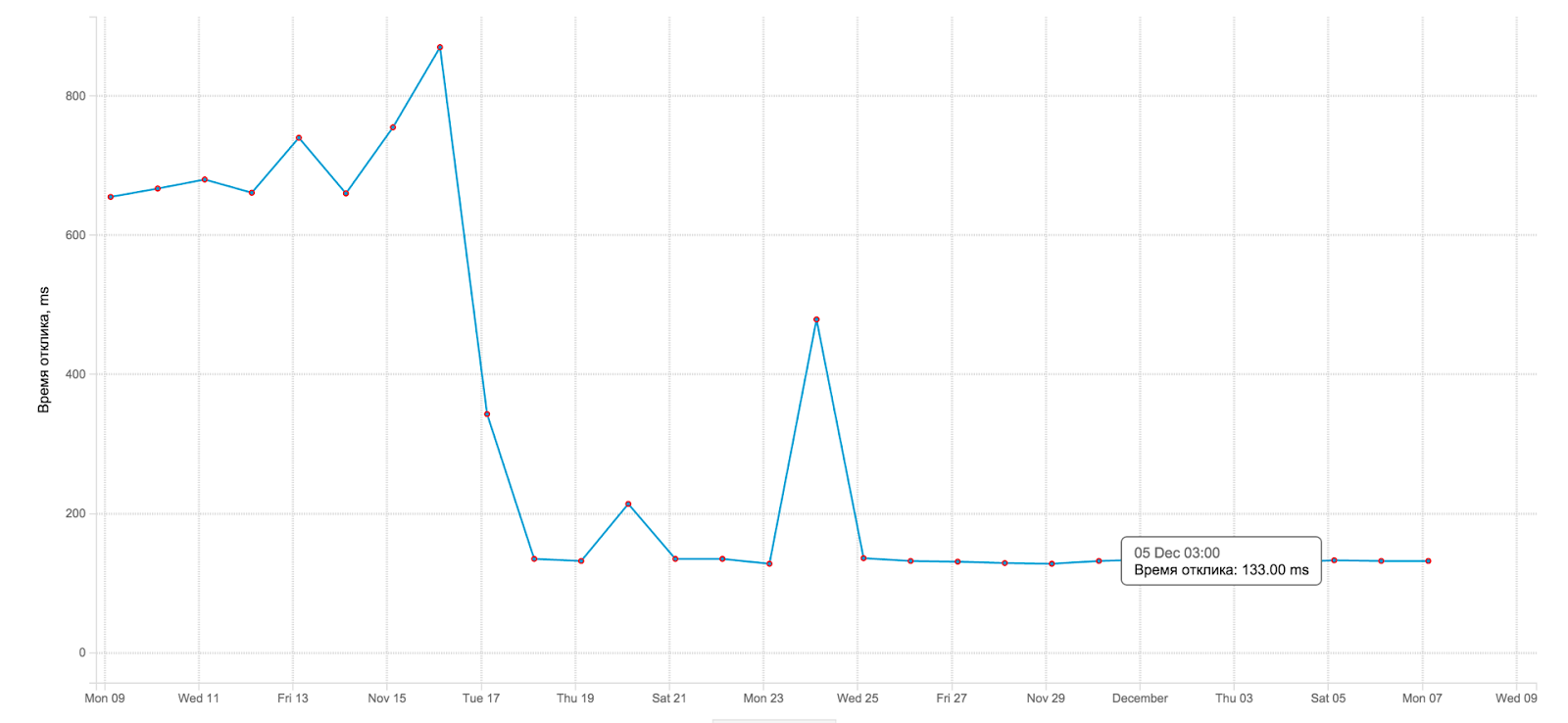
As you can see, the response time fell about 5 times. Which is also pleasant, both for us and for the Rutube itself, because we don’t worry anymore about SLA :)
As for iron, we launched a new cluster (Cloudera) on 3 machines. While we have enough of this. The whole system is fault tolerant, therefore uptime is 99.9%. In addition to this comes the scalability: at any moment we can “plug in” new machines with a significant increase in the load on the cluster.
Now we are interested in 2 points: the weight of events (the beginning of viewing, viewing to the middle, pause, etc.) and the share of popular videos in issuing recommendations. Both those and other indicators were set up by an expert method, that is, “by eye” :) I would still like to determine the most effective indicators in both cases. Most likely, we will use the Metric Optimization Engine (MOE) . This is a framework for determining system parameters based on A / B testing. As soon as we get some interesting results, we will definitely write.
If you have any questions about the case and stream processing in general, ask in the comments, we will try to answer all.
Today we will talk about how using streaming data processing you can increase the quality of recommendations and reduce the response time of the entire recommender system by 5 times. It will be about one of our clients - the Rutube video streaming service.
First, a few words about Rutube itself and why it needs recommendations. First, at the time of this writing, our recommendation system stores data on 51.76 million users and 1.26 million items, that is, video. Obviously, no user will be able to view all videos in the foreseeable future. He comes to the aid of a recommender system. Secondly, Rutube earns on display of advertising. One of the key business indicators of the company is the time spent by the user on the site. Rutube maximizes this figure. The recommendation system helps to do this. And, thirdly, already a feature of the Rutube itself. Part of the content is commercial video copyright holders. For example, TNT has its own channel, on which they regularly post releases of their programs. When a new release of “House-2” or “Dances” is released, people rush to watch them. The video has a “viral” character. The recommendation system helps other users to track and show such videos.
')
What we had
We made the first version of the recommendation system for Rutube in E-Contenta in May 2015. It represented the following: item-based collaborative filtration with recalculation of recommendations every n times, where n is a number from the Fibonacci series . That is, viewing each video was an event and, if the sequence number of this event was in the Fibonacci series, we recalculated the measures of proximity of this video with other videos. It was implemented using the following stack: Tornado + Celery (where the broker is RabbitMQ ) + MongoDB . That is, the data went to Tornado, from there through Celery publisher to RabbitMQ, and from there through Celery consumer - were processed and sent to MongoDB. We must respond to the request for recommendations for the user within 1 second (SLA).
Problems
At first, the system worked well: we accepted the flow of events, processed them, and calculated recommendations. However, the following problems appeared quite soon.
First, the technical problem. Recalculation of recommendations for popular videos “put” the entire system. A huge number of events from Mongo scored all the RAM, and the processing of all these events “scored” all the cores. At such moments, we could neither give already calculated recommendations, nor recalculate new ones, breaking the SLA.
Secondly, the business problem. Recounting the recommendations only every i-th time, where i belongs to the Fibonacci series, we could not immediately track the viral video. When we finally reached it, each time we had to do a full recount, which took too much time and resources, while the number of events continued to grow.
Third, an algorithmic problem called the implicit feedback problem. Any recommendation system is based on ratings, or ratings. We collected only video views, that is, in fact, we had a binary rating system: 1 - watched the video, 0 - did not watch.
Decision
As a solution, the transition to full real-time was suggested, but for this, an efficient algorithm, which was inexpensive in terms of resources, was needed. The main inspiration was the article published by Tencent. We took the algorithm described by them as the basis for our new recommendation engine.
Algorithm: personal recommendations
The new algorithm was the classic item based CF, where the cosine of the angle was used as a measure of proximity:
If you look closely at the formula, you can see that it consists of three sums: the sum of the joint ratings in the numerator and two sums of squares of the ratings in the denominator. Replacing them with simpler concepts, we get the following:
And now let's think about what happens when recommendations are recalculated when a new event (new assessment) is received? Right! We only increase our amounts by the resulting value. Thus, a new measure of proximity can be represented as follows:
From here follows a very important conclusion. We do not need to recalculate all amounts each time. It is enough to store them and increase each new value. This principle is called incremental update. Thanks to him, the load is significantly reduced when recalculating recommendations, and it becomes possible to use such an algorithm in real-time processing.
In the same article , a solution was proposed for the implicit feedback problem: to evaluate each specific user action when watching a video. For example, separately evaluate the beginning of viewing, viewing to the middle or to the end, pause, rewind, etc. Here is how we set the weights now:
ACTION_WEIGHTS = { "thirdQuartile": 0.75, "complete": 1.0, "firstQuartile": 0.25, "exitFullscreen": 0.1, "fullscreen": 0.1, "midpoint": 0.5, "resume": 0.2, "rewind": 0.2, "pause": 0.05, "start": 0.2 } With multiple user actions with one video, the maximum rating is taken.
Algorithm: Popular Videos
Also now we take into account the popular (trending) video. Each video has a counter that is incremented by 1 when an event is received that is associated with it. The most popular videos are in the top 20. When each new event arrives, we check if the video is in the top 20, its counter increases, if not, all videos in the top 20 counter decrease by 1. Thus, a rather dynamic list is obtained, with which it is easy to track the viral video . We keep this list for each region. That is, we recommend different popular videos to users from different regions.
When requesting recommendations for the user, issuance consists of 85% of personal recommendations and 15% of popular videos.
Technology
We have decided on the algorithm, now we need to choose the technologies with which it can be implemented. To summarize all the cases we found in stream processing, the stack of technologies used looks like this:
That is, we pound all the events in message broker, then process them in parallel in the stream processing engine and add the results to the key-value database, from where we read them when we receive the request. It remains to choose a specific option for each item.
We already had RabbitMQ, and we were quite pleased with it. However, most streaming engines support Kafka from the box. We were not against the transition at all, especially lately Kafka gained serious momentum, proved itself well and is generally considered to be quite a versatile and reliable tool, having mastered that, you can still use it a lot.
As a streaming engine considered all 3 options. However, they immediately introduced one restriction - all code should be written only in Python. All members of our team know him well, plus Python has all the libraries we need, and those that weren't there, we wrote ourselves. Therefore, Samza disappeared immediately, as it only supports Java. At first they wanted to try Storm, but after digging into the documentation, we found out that some of the code (topology) would be written in Java, and only the code for the processing nodes (bolts) could be written in Python. Later, we discovered an excellent Python wrapper for Storm called streamparse . Who needs Storm completely in Python, we recommend! As a result, the choice was Spark. First, we already knew him. And secondly, it fully supported Python. And thirdly, it is really impressive how rapidly they are developing .
The choice of database was made immediately. Despite the fact that we have experience with each of them, we have a pet. This is Aerospike. Aerospike reveals its full potential on servers with SSD drives. It bypasses the Linux file system and writes directly to the SSD in separate blocks. Due to this, a performance of 1 million TPS per node is achieved, and the response time of 99% of requests is <1 ms. We have used it more than once and are pretty good at preparing it (although there is not much to cook there too :).
As a result, our stack looks like this:
Just a couple of words about the choice between the Storm and Spark, all of a sudden someone will come in handy.
Spark streaming is not really a real-time engine, it’s rather near real-time, as it uses mini-batching. That is, the data stream is divided into mini-batches, the size of the specified number of seconds and processed in parallel. For those familiar with concepts in Spark, a mini-batch is nothing but RDD . Storm is real real-time. Received events are processed immediately (although Storm can also be configured to mini-batching using Trident). In summary, the Storm is lower latency, and Spark is higher throughput. If you have a hard limit on latency, then you should choose Storm. For example, for security applications. Otherwise Spark will be more than enough. We have been using it for more than a month in production, with proper cluster tuning, it works like a clock. There is another opinion that Spark is more fault tolerant. However, in our opinion, it should be supplemented, Spark is more fault tolerant out of the box. With due desire and skill, and Storm can be brought to this level.
results
And the most important thing. Did it all make sense? Had Let's start with the quality of recommendations. We use the online quality metric, which we measure, whether the video actually viewed by the user was included in the list recommended by us and where it was located there. The distribution is as follows.
For personal recommendations only (item-item CF):
For only popular items (trending):
For hybrid recommendations (85% item-item CF and 15% trending):
This is the last option we use in production, since the metrics on it are maximal. That is, about 10% of the videos viewed by users, we recommend it in the first place! About 36% are in the top 100. If these numbers do not tell you anything, you can look at the distribution of popular videos. If we recommend only popular videos to the user, we will guess only 0.1% of all the videos he watched. Which, in turn, is also not bad when compared with the random distribution, where the probability of guessing any video will be equal to 1 / (1.26 million).
For greater clarity, below is a graph of our metrics:
Piece 12.02 from 14:00 to 15:30, where the most unsolved (red) is just testing recommendations with only trending items. Before that - item-item CF, and after - a hybrid model. As you can see, thanks to “realtime”, our recommendation system quickly adapts to the new configuration. By the way when you start the system from scratch, it goes to the above figures for half an hour.
Due to the transition from MongoDB to Aerospike, the average response time to a request for recommendation has fallen. Below is the moment of switching from the old engine to the new one:
As you can see, the response time fell about 5 times. Which is also pleasant, both for us and for the Rutube itself, because we don’t worry anymore about SLA :)
As for iron, we launched a new cluster (Cloudera) on 3 machines. While we have enough of this. The whole system is fault tolerant, therefore uptime is 99.9%. In addition to this comes the scalability: at any moment we can “plug in” new machines with a significant increase in the load on the cluster.
What's next
Now we are interested in 2 points: the weight of events (the beginning of viewing, viewing to the middle, pause, etc.) and the share of popular videos in issuing recommendations. Both those and other indicators were set up by an expert method, that is, “by eye” :) I would still like to determine the most effective indicators in both cases. Most likely, we will use the Metric Optimization Engine (MOE) . This is a framework for determining system parameters based on A / B testing. As soon as we get some interesting results, we will definitely write.
If you have any questions about the case and stream processing in general, ask in the comments, we will try to answer all.
Source: https://habr.com/ru/post/276661/
All Articles