Methods of creating images on the example of Docker

The time has come to decompose the information about containers “by the shelves”
In fact, if a developer does not want to change something in the future in a running container that was going to be temporarily or only for testing, there is no need to think over the structure of the images, its layers and size. In the finished product, each excess layer translates into extra megabytes of information that needs to be downloaded, either via a slow connection to the Docker Hub, or transferred to compressed files. And when you have to update the product version, it is more useful to replace some image and one container dependent on it, than the entire system. In this case, there are thoughts about how best to assemble an image for the container, so that it is convenient to use it in production, update the product in a timely manner and make life easier when deployed in a cluster.
First, let's define what the image layer is. If you paint the Dokerfile in as much detail as possible, then each new layer will be an added or modified file (even if it is an environment variable inside the future container). And not to be confused, under the template, I understand the incomplete image of the container.
Now we will present such files as - as a set of elements of the same type Q. Also we define all processes or containers that will exist in our system, make up the set X. Each such process corresponds to an executable file, which in turn depends on other elements of the file system. We will consider such sets A, B, C, D and E as projections of processes (elements of set X) on the set Q.
')

Imagine the dependencies between files (libraries, etc.) in the form of lines above the elements, we get the sets A (a1-a2, a2-a3, a3-a4), B (b1-b2), C (c1-c2, c2- c3, c3-c4, c5-c6, c6-c4), D (d1-d2, d2-d3, d3-d4, d5-d6, d6-d4, d7-d4). The right shows the processes from the set X, to the left the corresponding executable files (a4, b2, c4, d4, e1) and their dependencies. For executable files, we define libraries, environment variables, devices, and reflect them in the form of corresponding elements. Since each process does not have more than one executable file, these elements will be key when creating the container. Additionally, I would like to note that there is no need to describe in detail each file. It is enough to describe the utility if its libraries are not used anywhere else and, for example, to consider the curl utility as one element.
In accordance with the conditions that we identified at the beginning of the article for the final product, we compose all the elements of the set Q into containers and templates. For each reflection, we define common elements (nodes) that are simultaneously present in several sets, mark them with Q (q1) = A (a1) = C (c1) = D (d1), Q (q2) = A (a3) = B ( b1), Q (3) = C (c5) = D (d5), Q (4) = C (c6) = D (d6) and set the appropriate dependencies, neglecting the individual elements.
In the future, we will work with these elements and build container templates on their basis. Since the elements in each set will constantly change (some elements more often, others less often), it is necessary to distinguish them in a special way. To do this, find the longest chain of dependencies among the sets, starting with the element corresponding to the executable file, for example a1-a2-a3-a4. The number of nodes in such a chain will correspond to the maximum degree of updating the elements in the set, that is, it is equal to four. We assume that when the degree is equal to one, this element in the system is not updated or changes very rarely, as a result of which we select it into a separate template. At the maximum degree this element will constantly change, and it should be allocated already in the container.
Since the display of each process is a set of elements depending on each other, this structure must also be indexed. Nodal elements are present in all sets, they are indexed for each set separately. For example: A (a1 = 1, a2 = 2, a3 = 3, a4 = 4), B (b1 = 2, b2 = 3), C (c1 = 1, c2 = 2, c3 = 2, c4 = 3, c5 = 2, c6 = 2), D (d1 = 2, d2 = 2, d3 = 3, d4 = 4, d5 = 2, d6 = 3), E (e1 = 3). The final update rate of the node element will be the maximum index among all sets. We get: q1 = 2, q2 = 3, q3 = 2, q4 = 3.
It should be noted that the nodal elements cannot be formed by two identical templates, since by definition each container is built on only one template. From this it follows that all dependencies of elements with the same degree must be included in one template.

This operation should be repeated several times, as a result of combining new dependencies appear.
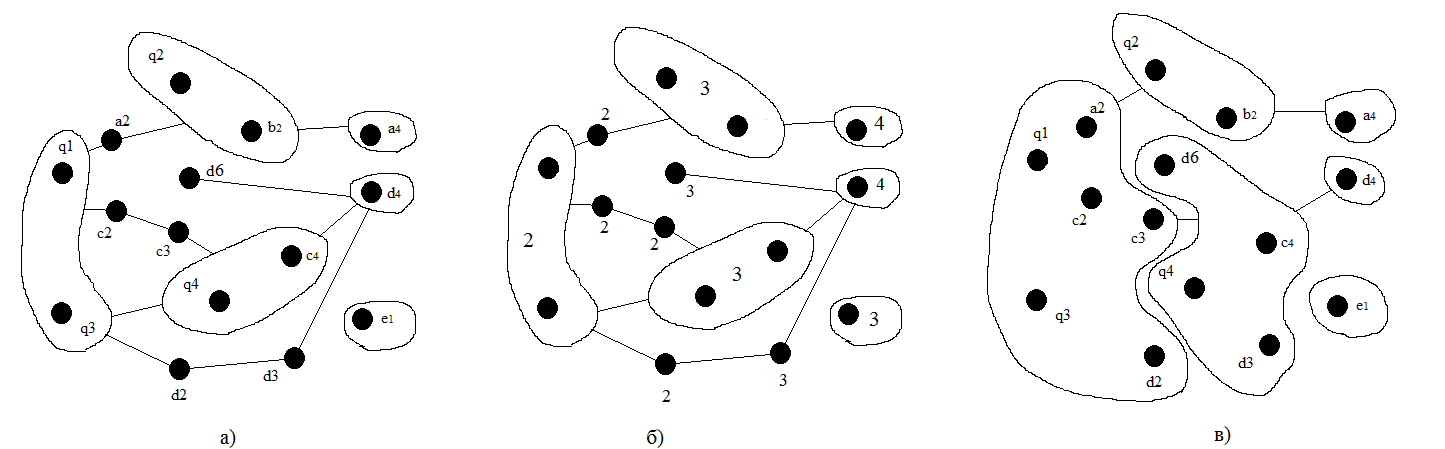
Lastly, it is necessary to select all the elements on which the templates depend, and combine them either into one (if their indices correspond), or with a template that depends on them. The resulting structure reflects the relationship, the formation of which took into account the degree of renewal of elements and their dependencies.
The final structure of the resulting images and containers can be seen in the figure:

The result of this article is an approach to the formation of Docker images, when the entire file system used is broken down into elements. These elements are labeled depending on the frequency of their updates in the final product or at the development stage. And then they are combined into logically complete images, on the basis of which the containers are launched.
PS: I ask you to forgive because of possible errors in the article and a bit of a messy presentation, but I think the meaning of the article can be caught by simply looking at the pictures and reading the conclusion.
Source: https://habr.com/ru/post/276557/
All Articles