A little bit about software architectures

There is no doubt that lately the world has only strengthened its dependence on software. Applications must have high availability, perform the required functions properly and have adequate cost. These characteristics, to one degree or another, are determined by the software architecture.
The IEEE 1471 standard defines the following: “Architecture is the basic organization of a system that describes the connections between the components of this system (and the external environment), and also defines the principles of its design and development.” However, many other architectural definitions recognize not only structural elements, but also their compositions, as well as interfaces and other connecting links.
')
So far, we do not have a generally accepted classification of architectural paradigms, but still we can easily identify several basic and widespread architectural patterns or styles. Take a look at some of them.
Pipes and Filters
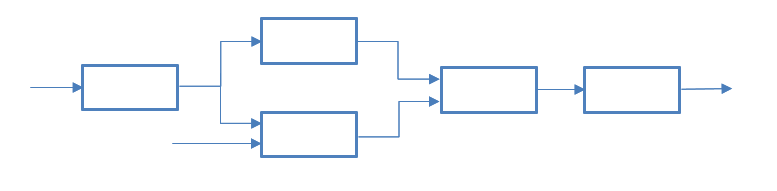
Figure 1 - Pipes and Filters
This kind of architecture is suitable if the process of the application is divided into several steps that can be performed by separate handlers. The main components are “filter” (filter) and “pipe” (pipe). Sometimes, an additional "data source" (data source) and "data consumer" (data sink) are distinguished.
Each data processing flow is a series of alternating filters and channels, starting with a data source and ending with their consumer. Channels provide data transfer and synchronization. The filter also accepts data as input and processes it, transforming it into some other representation, and then passes it on.
For example, one of the filters can implement a Caesar cipher — a substitution cipher, in which each character in the text is replaced with a character that is located at some constant number of positions to the left or to the right in the alphabet. One variation of the Caesar code is ROT13, which has a pitch of 13.
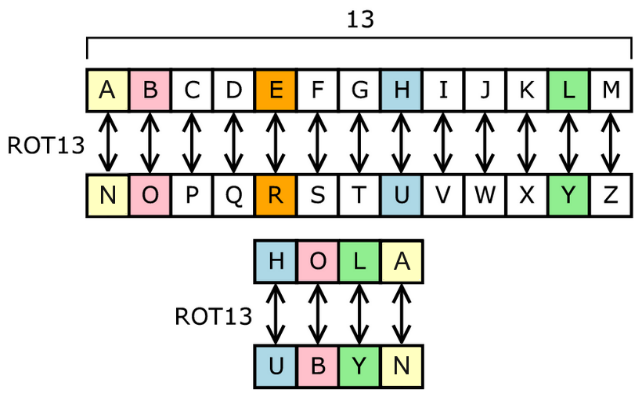
Figure 2 - ROT13 Principle
It is quite simple to implement it using the standard terminal utility Unix tr :
$ # Map upper case AZ to N-ZA-M and lower case az to n-za-m $ echo "The Quick Brown Fox Jumps Over The Lazy Dog" | tr 'A-Za-z' 'N-ZA-Mn-za-m' Gur Dhvpx Oebja Sbk Whzcf Bire Gur Ynml Qbt $ tr 'A-Za-z' 'N-ZA-Mn-za-m' <<<"The Quick Brown Fox Jumps Over The Lazy Dog" Gur Dhvpx Oebja Sbk Whzcf Bire Gur Ynml Qbt And here's the Python code:
def rot13(text): rot13ed = '' for letter in text: byte = ord(letter) capital = (byte & 32) byte &= ~capital if ord('A') <= byte <= ord('Z'): byte -= ord('A') byte += 13 byte %= 26 byte += ord('A') byte |= capital rot13ed += chr(byte) return rot13ed Filters can be easily replaced, reused, swapped, which makes it possible to implement many functions based on a limited set of components. Moreover, active filters can work in parallel, which leads to a significant increase in performance on multiprocessor systems. However, there are drawbacks, for example, filters often spend more time converting input data than processing it.
An example of using this architecture is the UNIX Shell , one of whose designers was Douglas McIlroy. Another example would be the architecture of the compiler, if we consider it as a sequence of filters: lexer, parser, semantic analyzer and code generator.
Additional information on this type of architecture can be found here and here .
Layered architecture
It is one of the most famous architectures in which each layer performs a specific function. Depending on your needs, you can realize any number of levels, but too many of them will lead to excessive complication of the system. Often there are three main levels: presentation level, logic level and data level.
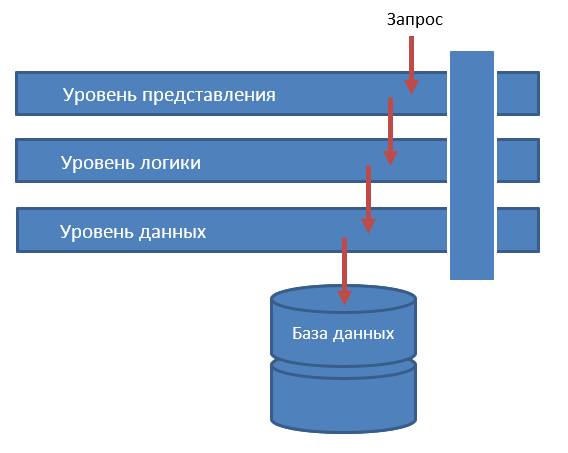
Figure 2 - Layered Architecture
A layer does not need to know what its neighbors are doing. This manifests such a property as the division of responsibility. If all three layers are closed, then the user's request to the top level initiates a chain of calls from the top level to the bottom level. In this case, the presentation layer is responsible for the user interface and data mapping for the user and does not know anything about the existence of a physical data store. The level of logic does not know anything about the existence of the database - only the rules of business logic "worry" it. Access to the database is only through the data management level.
The advantages of such an architecture are the simplicity of development (mainly due to the fact that this type of architecture is familiar to everyone) and the simplicity of testing. Among the shortcomings, one can single out possible difficulties with performance and scaling - it is all due to the need to pass requests and data across all levels (again, if all layers are closed ).
One of the most famous examples of this pattern is the OSI network model. You can read more about multi-tier architecture, for example, in the blogs of these three programmers and developers:
- Scott Hanselman's blog,
- Hendry Luk's blog ,
- Johannes Brodwall's blog.
Event Driven Architecture (EDA)
This is a popular adaptive pattern that is widely used to create scalable systems. To get acquainted with the principles of event-oriented architecture, you can watch this video from Complexity Academy :

Figure 3 - Event-oriented architecture
If we talk about software, then in this scheme there are two variants of events: an initiating event and an event to which handlers respond. Handlers are isolated independent components that are (ideally) responsible for any one task, and contain the business logic necessary for work.
The mediator can be implemented in several ways. The easiest way is to use the framework for integrating Apache Camel, Spring Integration, or Mule ESB. For larger applications that require more sophisticated management functions, you can implement an intermediary using the concept of business process management (for example, the jBPL engine).
An event-driven architecture is a relatively complex pattern. The reason for this is its distributed and asynchronous nature. You will have to solve network fragmentation problems, handle event queue errors, and so on. The advantages of this architecture can serve as high performance, ease of development and amazing scalability. However, the complexity of the system testing process is possible.
More information about event-oriented architecture can be found here .
Micronuclear architecture
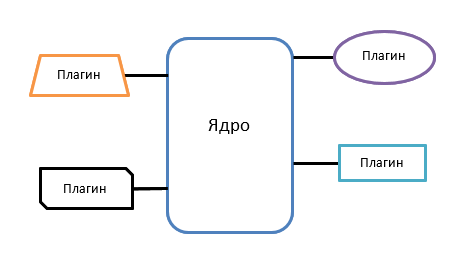
The pattern consists of two components: the main system (core) and plug-ins. The kernel contains a minimum of business logic, but manages the loading, unloading and launching of the necessary plug-ins. Thus, the plugins are unrelated to each other.
Since plug-ins can be developed independently of each other, such systems have very high flexibility and, as a result, are easily tested. The performance of an application built on the basis of such an architecture directly depends on the number of connected and active modules.
Perhaps the best example of a micronuclear architecture is the Eclipse IDE. Downloading Eclipse without add-ons, you get a completely empty editor. However, with the addition of plugins, an empty editor will begin to turn into a useful and easily customizable product. Another good example is the browser: additional plugins allow you to extend its functionality.
Learn more about micronuclear architecture here and here .
Microservice architecture
This type of architecture allows applications to be scaled along the Y axis of the Scale Cube , described in Martin L. Abbott and Michael T. Fisher’s The Art of Scalability book . In this case, the application is divided into many small services, called microservices. Each microservice includes business logic and is a completely independent component. Services of one system can be written in various programming languages and communicate with each other using different protocols.
Since each microservice is a separate project, you can distribute work on them among development teams, that is, several dozens of programmers can work on the system at the same time. Microservice architecture allows you to easily scale the application - if you need to implement a new function (you can deploy each microservice separately), just write a new service, and if no one uses a function, disable the service.
An obvious disadvantage of this pattern is the need to transfer a large amount of data between microservices. If the overhead of messaging is too high, you need to either optimize the protocol or combine microservices. Testing such systems is not all that simple either. For example, if you write a class on Spring Boot, which should test all the REST API of the service, then it should run the microservice being checked and microservices associated with it. This is not nuclear physics, but you should not underestimate the complexity of the process.
You can read more about microservice architectures in the following sources: here , here and here .
Additional materials
In this article, we looked at several types of software architectures. Of course, many other patterns were not touched here. As additional materials on the topic you can see the following resources:
- O'Reilly : a series of articles on software architectures;
- SE : the best books on software architecture;
- Fromdev : five best books on software architecture that everyone should read;
- All Things Distributed : Werner Vogels' blog (Werner Vogels), Amazon's technical manager, on building scalable and reliable distributed systems;
- Quora : the best books, articles and blogs for software architects.
Our blog covers a variety of issues ranging from file system development to industry events , from data center reliability to virtualization, and our own case studies of how to transfer Russian business to the cloud.
In addition, we talk about the work of the cloud support service provider and the topic of performance optimization , which we plan to return to in one of the following materials.
Source: https://habr.com/ru/post/276297/
All Articles