Some areas of file system development

The history of data management systems dates back to the advent of magnetic tapes, but they acquired a modern look with the advent of magnetic disks. Today we decided to look at the direction of the further development of file systems.
In traditional data storage systems, actions are performed both on small blocks of information of a certain size and on metadata. Today, object storage systems are being developed, where, instead of data blocks, they operate on objects with different parameters. Object storage systems are based on the T-10 Object Storage Devices (OSD) standard.
')
The fundamental difference between block and object storage systems is that in the first case you create objects from sets of blocks containing data and metadata, and in the second case you operate on objects and the corresponding metadata directly.
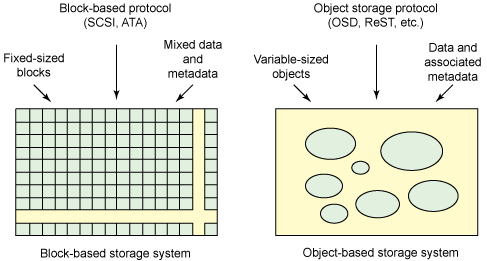
Figure 1 - Block and object storage systems
One example of file systems built on an object storage system is exofs (Extended Object File System).
The exofs scheme can be represented as follows:
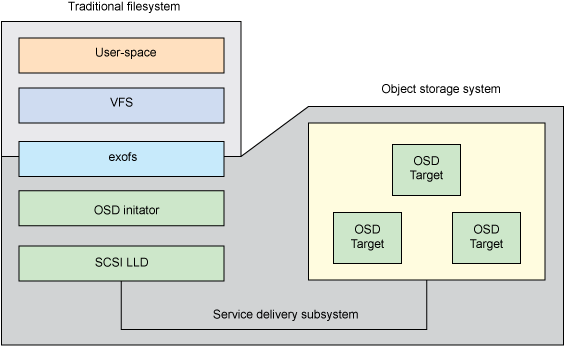
Figure 2 - Scheme exofs
The VFS (Virtual File System Switch) virtual file system switch provides access to exofs, and exofs already interacts with the object storage system via the local OSD initiator.
While storing objects is an interesting idea, Ravi Tandon, a graduate of the computer science department, believes that the future is in log-structured file systems. “This is my opinion, since flash and SSD technologies will play an important role in the further development of storage systems,” says Ravi. Log-structured file systems are ideal for solid-state drives, since in this case, write operations are distributed evenly across the entire device, which leads to a decrease in the number of data erasure cycles - this can significantly extend the lifespan of SSD.
The idea of a log-structured file system was proposed in 1988 by John Ousterhout and Fred Douglis, and implemented in 1992 in the Sprite operating system. The point here is as follows: the file system is represented as a circular log, where new data and metadata are written, and free space is always taken from the end. This means that there may be many copies of one file in the journal, but the most current one will always be considered active. This interesting feature allows you to get several advantages.
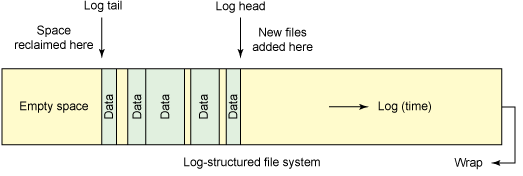
Figure 3 - Log-structured file system
This approach to data storage leads to a reduction in recording overhead - recording is done sequentially, data is faster on the disk, because the file system is faster. Ravi Tandon also writes that log-structured systems support features such as version control and data recovery, effectively allowing you to “travel through time.”
An example of a log-structured file system is NILFS2 . NILFS2 can really create snapshots of the state of the file system. This is very convenient if you need to restore previously deleted or lost files. However, you have to pay for everything, the log-structured file system is also not without drawbacks - here you have to use the garbage collector to remove old data and metadata. At these times, there may be a significant decrease in performance.
The two types of file systems considered are certainly good (although they are not without flaws), but there are other worthwhile ideas. In particular, Jeff Darcy (Jeff Darcy), a programmer and blogger, believes that within a few years there will be a division into local and distributed file systems, where the latter will be built on the basis of the former. As for the first case, recently ZFS and Btrfs file systems have become increasingly popular.
ZFS (Zettabyte File System) is a 128-bit file system that supports files that are ridiculously huge (16 exabytes) and can handle disk volumes of up to 256 zettabytes. ZFS project leader Jeff Bonwick said that “filling 128-bit file systems will exceed quantum data storage on Earth.” “You cannot fill and store 128-bit volume without boiling the oceans, ” Bonvik said .
An example of how big these numbers are: if you create a thousand files every second, then it will take about 9000 years to reach the limit on the number of files in ZFS. In general, the ZFS file system is designed in such a way that it is not possible to face any restrictions in the foreseeable future.
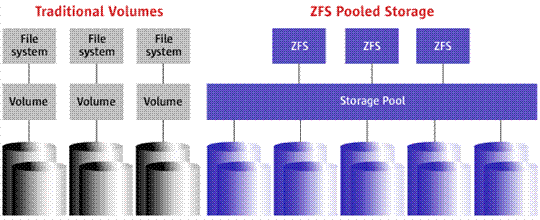
Figure 4 - Traditional File Systems and ZFS
ZFS is built on top of virtual data pools (zpool). It turns out that all the connected drives are part of one giant partition. Moreover, disks can communicate with each other in virtual RAID-arrays, which have the ability to "self-healing". Also, this file system allows you to take snapshots to recover data in case of damage. Learn more about ZFS here .
The Btrfs file system is a direct competitor to ZFS and has almost the same functions. As a couple of examples of comparative analysis, you can see these two articles: 1 and 2 .
www.diva-portal.org/smash/get/diva2 : 822493 / FULLTEXT01.pdf
As for distributed file systems, then, according to Jeff Darcy, who is developing GlusterFS , the future lies with them. However, in this case it is necessary to pay much attention to reliability. In general, a distributed file system is a cluster of independent computers that look to the user as a single, integral system.
The concept has several advantages. As an example, it has great potential for scaling. Traditional file systems work like this: when a user sends a file to the server, its contents and metadata are separated and stored in the relevant storage.
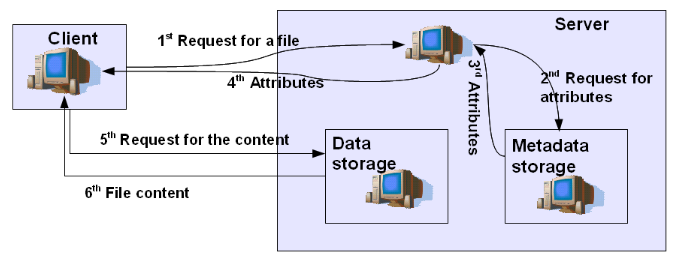
Figure 5 - Upload for DFS
When a user wants to get his file back, he accesses the file system, which retrieves the metadata with the attributes of the file and determines its location in the data store. The file is sent to the client, which in turn sends a receipt message. In principle, such a scheme has both advantages and disadvantages.
The advantages, of course, is that when working on a network, you can save disk space. But, on the other hand, you have to work with remote files, which is much slower than working with local files. In addition, the actual ability to access a remote file is critically dependent on the server and network performance.
By the way, recently we talked about how to check the reliability of the data center ( here and here ). In addition, we gave examples of our cases and prepared a calendar of events for 2016 on the subject of IT infrastructure, information security and telecom.
Source: https://habr.com/ru/post/276295/
All Articles