5 common mistakes with working with Amazon Web Services

We at Latera are creating billing for telecom operators . In a blog on Habré, we not only talk about the features of our system and the details of its development (for example, ensuring fault tolerance ), but also publish materials about working with the infrastructure as a whole. The developer and system architect Michael Wittig (Michael Wittig) wrote in the blog Cloudonout interesting material about the most common mistakes when working with AWS (Amazon Web Services). We present to your attention the main points of this note.
Wittig works as an AWS consultant and has seen many software deployment options, regardless of size - for the most part, these are standard web applications. The engineer has compiled a list of the 5 most common user mistakes that should be avoided.
')
What does a typical web application look like?
A standard web application consists of:
- load balancer;
- scalable server part (web backend);
- repositories.
On the diagram, it looks like this:

This is a common scheme. There are good reasons for using some other way of constructing an application.
Error 1. Managing infrastructure manually
If installations in AWS were made using clicks on the console, then the infrastructure is managed manually. The main problem with this type of control is that these settings cannot be reproduced, they are not registered anywhere. As a result, a lot of errors are likely. Fortunately, there is AWS CloudFormation , with which you can solve this problem for free.
Instead of creating resources (EC2 instances, security groups, subnets), you can manually describe them in a template, create your own or use ready-made ones. CloudFormation will take care of how to integrate them into the current stack. The service will create resources in the correct order, as shown in the picture:
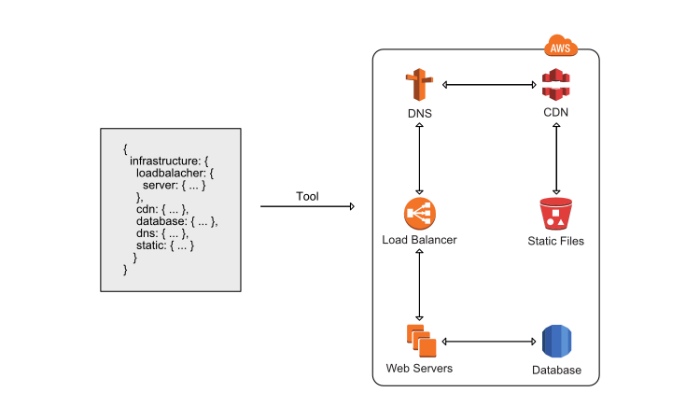
The template can be updated. See an example of a standard template for a web application here . Wittig is convinced that managing the infrastructure manually is unprofessional — too many problems can bring this way of working.
Error 2. Failure to use Auto Scaling Groups
Some naively believe that they can scale resources on their own, without resorting to the help of a special function. Each EC2 instance must be running in the Auto Scaling Group. Even if it is a separate instance. Auto Scaling Group controls the launch of the required number of instances. In essence, it behaves like a logical group of virtual machines. The function can be used for free.
In a standard web application, servers run on virtual machines inside the Auto Scaling Group. It is possible to vary the amount of computing resources, based on the load, focusing on the increase or decrease in demand. The administrator can set the conditions under which the automatic scaling will be launched. This may be the threshold of the CPU performance of a logical group or the number of requests in load balancing.
Error 3. Disregard of Amazon Cloud Watch analytics
Interesting data on the work of AWS services can be obtained through Cloud Watch . Virtual machines announce CPU, network, and disk usage. Stores provide information on memory usage and number of I / O operations. You just have to correctly use these statistics. Let's look at the CPU work schedule for the day:

See peak downloads? Wittig is convinced that this jump occurred every day at the same time:
Looks like a trick of a task scheduler. The way it is. Note that a web server has been started from this machine. This means that every day the waiting time increased due to the scheduler. Run it on a separate virtual machine, and the problem will be solved. Without Cloud Watch, finding it would be difficult.
As soon as the data is analyzed, you should put alert markers of limit values. Not the other way around!
Error 4. Ignoring Trusted Advisor
The Trusted Advisor tool checks the AWS environment for compliance with best practices for working with the service. Checked parameters:
- cost optimization;
- performance;
- security;
- resistance to failure.
If the Trusted Advisor Management Console looks like this:
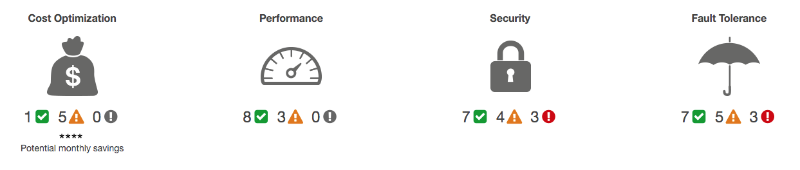
We can safely begin to optimize the processes in the environment right now, says Wittig.
I would advise, first of all, to pay attention to safety. You can try the weekly feedback feature, and Trusted Advisor will report all current and resolved issues. You can activate the free version of the program. Paid support will open additional options for verification.
Error 5. Underestimating the capabilities of virtual machines
It makes no sense not to reduce the size of the instance (the number of machines or the category from c3.xlarge to c3.large) if it turns out that the existing EC2 instances are underutilized. You can learn about this by checking with the data from Cloud Watch. If the project uses Auto Scaling Groups, its administrators need to reconfigure the parameters of automatic scaling, scale resources in favor of increasing later, and in the direction of decreasing earlier.
Other interesting articles on the Latera blog:
- How to improve resiliency of billing: The experience of "Hydra"
- Corporate GitHub: how Azure increased the number of employees on GitHub to two thousand
- Open source application architecture: How nginx works
- LinkedIn's brief history of scaling
- Large-scale migration of records in the database: how it does Stripe
Source: https://habr.com/ru/post/276049/
All Articles