Exchange Sorting Network with Batcher Merge
Sorting is one of the basic operations in data processing, which is used in the widest range of tasks. This article will discuss the exchange sorting network with Batcher merge for parallel sorting of an array of arbitrary size.
Sorting networks are a type of sorting algorithms in which the order of execution of comparison operations and their number does not depend on the value of the elements of the array being sorted. They allow you to create scalable parallel algorithms for sorting large amounts of data.
')
In sorting networks, each element of the array is sequentially processed by comparators , which compare two elements and, if necessary, swap them.
Sorting networks are usually depicted as follows. Sorted array elements are indicated by horizontal data lines, and comparators are indicated by vertical lines that connect only two lines. Figure 1 below shows the sorting network for three elements and an example of ordering an array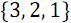 . The value on each data line changes as the corresponding comparator triggers.
. The value on each data line changes as the corresponding comparator triggers.
Figure 1. Network sorting array of 3 elements.
At the moment, the method of building networks with the minimum time for an arbitrary number of inputs is unknown, so consider one of the fastest scalable sorting networks.
Batcher networks are the fastest of scalable networks. To build a network, we will use the following recursive algorithm.
When sorting an array of items with numbers
items with numbers 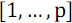 it should be divided into two parts: in the first leave
it should be divided into two parts: in the first leave 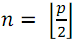 items with numbers
items with numbers  and in the second
and in the second 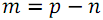 items with numbers
items with numbers 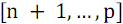 . Next, you should sort each of the parts (function B ) and combine the results of the sort (function S ).
. Next, you should sort each of the parts (function B ) and combine the results of the sort (function S ).
Consider these functions in more detail.
B ( array ) - function of recursive construction of the network of sorting a group of lines Recursively divides an array into two subarrays up and down from and
and 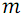 elements, respectively, and then calls the merge function S for these subarrays.
elements, respectively, and then calls the merge function S for these subarrays.
S ( up , down ) - the function of recursive merging of two groups of lines. The network of odd-even merge separately combines elements of arrays with odd numbers and separately with even ones, after which pairs of neighboring elements with numbers are processed with the help of the final group of comparators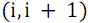 where
where 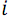 - natural numbers from
- natural numbers from  before
before  . These pairs are written into the comparators array of comparators for further use.
. These pairs are written into the comparators array of comparators for further use.
We give examples.
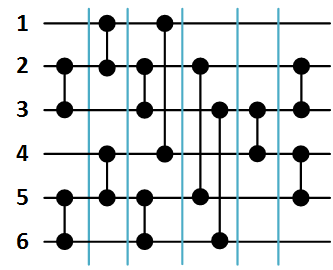
Figure 2 below shows the network of sorting an array of 6 elements, formed as a result of a call to function B (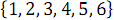 ).
).
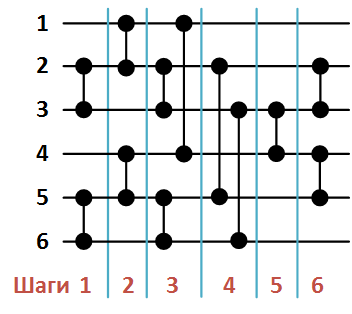
Figure 2. Batcher's network of sorting an array of 6 elements.
The list of comparators in the order of their formation by the function S will be as follows:
Consider an example of combining two ordered arrays: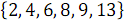 and
and 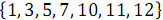 . In Figure 3 below, vertical blocks denote merge networks that process odd and even rows of arrays.
. In Figure 3 below, vertical blocks denote merge networks that process odd and even rows of arrays.
As a result of combining elements with odd numbers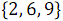 and
and 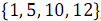 received ordered array
received ordered array 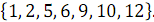 .
.
As a result of combining elements with even numbers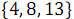 and
and  received ordered array
received ordered array 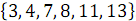 .
.
As a result of the execution of the last group of comparators, a completely sorted array is obtained: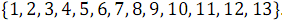 .
.
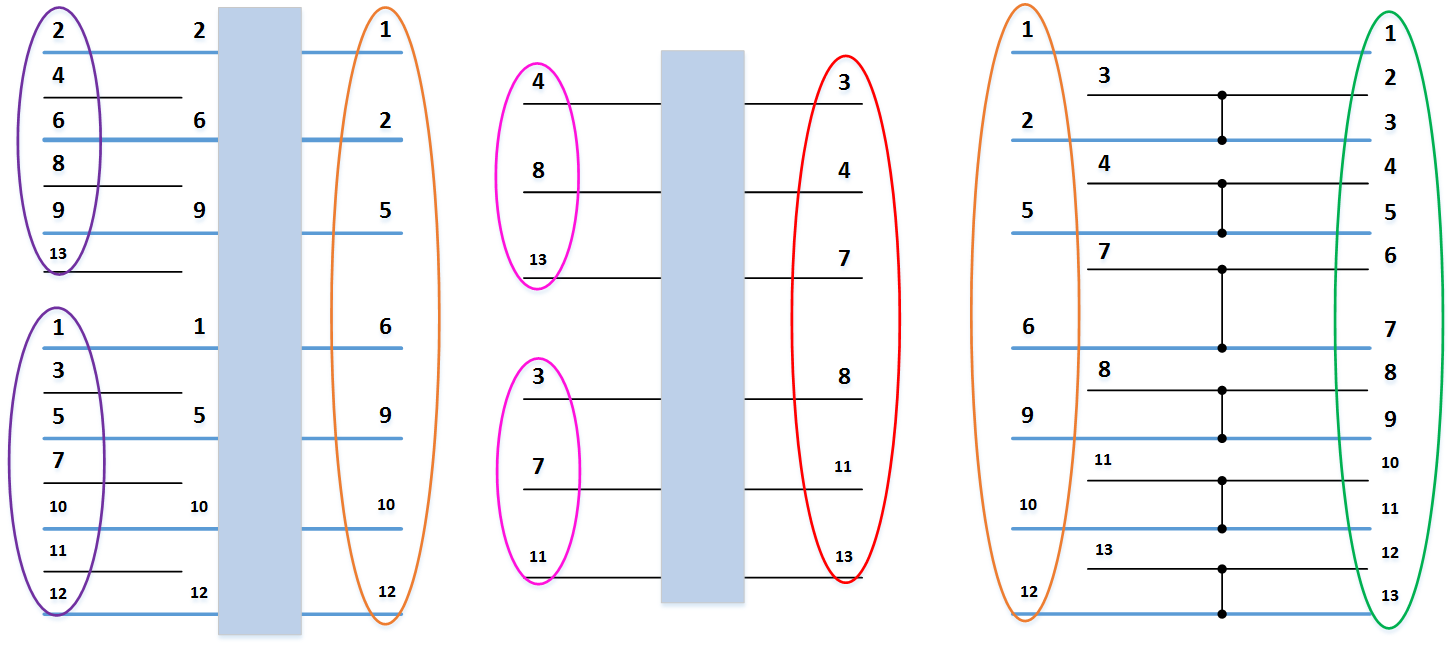
Figure 3. The Batcher odd-even merge network.
In case the size of the array exceeds the number of processors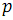 , on each processor we will store by
, on each processor we will store by  array elements. Sorting will be done in two stages.
array elements. Sorting will be done in two stages.
Consider the second stage in more detail. In Figure 4 below, each data line corresponds to one processor , and each comparator corresponds to a merge comparator .
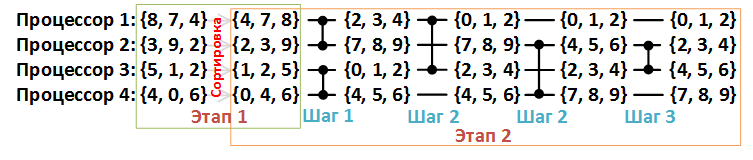
Figure 4. Example of array sorting {8, 7, 4, 3, 9, 2, 5, 1, 2, 4, 0, 6}, n = 12, p = 4.
The merge comparator takes as input two arrays of the same length and redistributes the elements into two new arrays so that the first one contains the elements with smaller values and the second one with the larger ones.
In case of using distributed memory, the stage of data transfer between processors is added:
If necessary, we will supplement the array with fictitious zero elements so that the length of the sorted processor is a multiple of the number of processors.
Thus, the first stage can be written as:
And second:
For the input, we will use the function MPI_File_read_ordered () , which sequentially reads from the file equal fragments of the array for each processor. If there is not enough data from the file, it will not overwrite the dummy zeros with which the array is initialized.
For output, we will use the similar function MPI_File_write_ordered () , but for each processor it is necessary to calculate how many elements it should write to the file. Such a need arises if the length of the array being sorted was not a multiple of the number of processors.
Consider more.
Files with random unsigned integers for a different number of elements were generated, after which the result of the program was compared with a reference response obtained using the standard qsort () function.
The table below compares the speed of the sequential algorithm with the sort of Batcher on a different number of processors.
On a stationary machine (Intel Core i7-3770 (4 cores, 8 threads), 8 GB RAM):
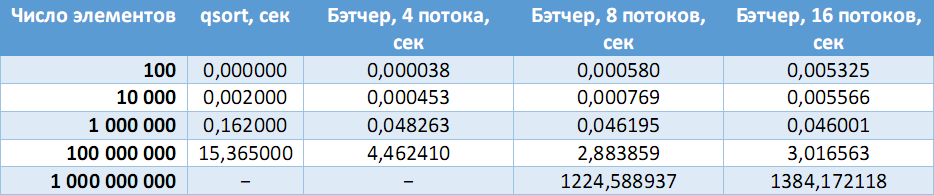
(Dashes - errors in allocating the required amount of memory).
The source code for this sorting is available on GitHub at the following link: https://github.com/zodinyac/batcher-sort . You can also find a test generator and other auxiliary utilities described in README.md .
Introduction
Sorting networks are a type of sorting algorithms in which the order of execution of comparison operations and their number does not depend on the value of the elements of the array being sorted. They allow you to create scalable parallel algorithms for sorting large amounts of data.
')
In sorting networks, each element of the array is sequentially processed by comparators , which compare two elements and, if necessary, swap them.
Sorting networks are usually depicted as follows. Sorted array elements are indicated by horizontal data lines, and comparators are indicated by vertical lines that connect only two lines. Figure 1 below shows the sorting network for three elements and an example of ordering an array
. The value on each data line changes as the corresponding comparator triggers.Figure 1. Network sorting array of 3 elements.
At the moment, the method of building networks with the minimum time for an arbitrary number of inputs is unknown, so consider one of the fastest scalable sorting networks.
Exchange Sorting Network with Batcher Merge
Batcher networks are the fastest of scalable networks. To build a network, we will use the following recursive algorithm.
When sorting an array of
items with numbers it should be divided into two parts: in the first leave items with numbers and in the second items with numbers . Next, you should sort each of the parts (function B ) and combine the results of the sort (function S ).Consider these functions in more detail.
B ( array ) - function of recursive construction of the network of sorting a group of lines Recursively divides an array into two subarrays up and down from
and elements, respectively, and then calls the merge function S for these subarrays.S ( up , down ) - the function of recursive merging of two groups of lines. The network of odd-even merge separately combines elements of arrays with odd numbers and separately with even ones, after which pairs of neighboring elements with numbers are processed with the help of the final group of comparators
where - natural numbers from before . These pairs are written into the comparators array of comparators for further use.Source code of functions B and S
Hereinafter we will give C code examples with the following conventions.
Code of functions with normal syntax highlighting on github .
- Arrays of type T are denoted as array (T).
- We assume that all the functions of working with arrays are defined in some array.h and do exactly what is written in the title.
- In addition to the array_push () function: for vectors, it adds the transferred value to the end of the array, allocating memory if necessary; for ordinary arrays, it writes the transferred value after the last one written, starting with zero.
void S(array(int) procs_up, array(int) procs_down) { int proc_count = array_size(procs_up) + array_size(procs_down); if (proc_count == 1) { return; } else if (proc_count == 2) { array_push(&comparators, ((pair_t){ procs_up[0], procs_down[0] })); return; } array(int) procs_up_odd = array_new(array_size(procs_up) / 2 + array_size(procs_up) % 2, int); array(int) procs_down_odd = array_new(array_size(procs_down) / 2 + array_size(procs_down) % 2, int); array(int) procs_up_even = array_new(array_size(procs_up) / 2, int); array(int) procs_down_even = array_new(array_size(procs_down) / 2, int); array(int) procs_result = array_new(array_size(procs_up) + array_size(procs_down), int); for (int i = 0; i < array_size(procs_up); i++) { if (i % 2) { array_push(&procs_up_even, procs_up[i]); } else { array_push(&procs_up_odd, procs_up[i]); } } for (int i = 0; i < array_size(procs_down); i++) { if (i % 2) { array_push(&procs_down_even, procs_down[i]); } else { array_push(&procs_down_odd, procs_down[i]); } } S(procs_up_odd, procs_down_odd); S(procs_up_even, procs_down_even); array_concatenate(&procs_result, procs_up, procs_down); for (int i = 1; i + 1 < array_size(procs_result); i += 2) { array_push(&comparators, ((pair_t){ procs_result[i], procs_result[i + 1] })); } array_delete(&procs_up_odd); array_delete(&procs_down_odd); array_delete(&procs_up_even); array_delete(&procs_down_even); array_delete(&procs_result); } void B(array(int) procs) { if (array_size(procs) == 1) { return; } array(int) procs_up = array_new(array_size(procs) / 2, int); array(int) procs_down = array_new(array_size(procs) / 2 + array_size(procs) % 2, int); array_copy(procs_up, procs, 0, array_size(procs_up)); array_copy(procs_down, procs, array_size(procs_up), array_size(procs_down)); B(procs_up); B(procs_down); S(procs_up, procs_down); array_delete(&procs_up); array_delete(&procs_down); } Code of functions with normal syntax highlighting on github .
We give examples.
First example.
Figure 2 below shows the network of sorting an array of 6 elements, formed as a result of a call to function B (
).Figure 2. Batcher's network of sorting an array of 6 elements.
The list of comparators in the order of their formation by the function S will be as follows:
- (2, 3)
- (12),
- (2, 3)
- (5, 6),
- (4, 5)
- (5, 6),
- (14),
- (3, 6),
- (3, 4),
- (2, 5)
- (2, 3)
- (4, 5).
The second example.
Consider an example of combining two ordered arrays:
and . In Figure 3 below, vertical blocks denote merge networks that process odd and even rows of arrays.As a result of combining elements with odd numbers
and received ordered array .As a result of combining elements with even numbers
and received ordered array .As a result of the execution of the last group of comparators, a completely sorted array is obtained:
.Figure 3. The Batcher odd-even merge network.
Sort large arrays
In case the size of the array exceeds the number of processors
, on each processor we will store by array elements. Sorting will be done in two stages.- Sort on each processor array length
 . Each processor, independently of the others, performs the process of ordering the elements of the array. Sorting is performed by the best available sequential algorithms.
. Each processor, independently of the others, performs the process of ordering the elements of the array. Sorting is performed by the best available sequential algorithms. - Merging each sorted array according to the schedule specified by the sorting network used elements, that is, at this stage, global sorting is performed.
Consider the second stage in more detail. In Figure 4 below, each data line corresponds to one processor , and each comparator corresponds to a merge comparator .
Figure 4. Example of array sorting {8, 7, 4, 3, 9, 2, 5, 1, 2, 4, 0, 6}, n = 12, p = 4.
The merge comparator takes as input two arrays of the same length and redistributes the elements into two new arrays so that the first one contains the elements with smaller values and the second one with the larger ones.
In case of using distributed memory, the stage of data transfer between processors is added:
- each of the processors sends its own fragment of the array to the processor connected to another input of the comparator,
- a processor with a lower number selects from two fragments
 the smallest elements, and the processor with a large number - largest items.
the smallest elements, and the processor with a large number - largest items.
If necessary, we will supplement the array with fictitious zero elements so that the length of the sorted processor is a multiple of the number of processors.
Thus, the first stage can be written as:
Source code of the first stage
For simplicity, we will use the built-in sort function qsort () . The size of the sorted array on each processor is defined as:
Then the first stage consists of just one line of code:
On the githaba.
int proc_count; // int elems_count; // int elems_count_new = elems_count + (elems_count % proc_count ? proc_count - elems_count % proc_count : 0); int elems_per_proc_count = elems_count_new / proc_count; Then the first stage consists of just one line of code:
qsort(elems_result, elems_per_proc_count, array_item_size(elems_result), compare_uint32); On the githaba.
And second:
Source code of the second stage
As already mentioned, this stage consists in the sequential processing of each comparator from the comparators array. The processor from the first input of the comparator sends its array to the second input, the other processor arrives similarly, with the result that each processor has two arrays: its own ( elems_result ) and another processor ( elems_current ).
Then on each processor a third array is formed ( elems_temp ), consisting of the smallest elements (for the first processor) or the largest (for the second processor).
After that, the elems_temp array is written in place of the elems_result array.
On the githaba.
Then on each processor a third array is formed ( elems_temp ), consisting of the smallest elements (for the first processor) or the largest (for the second processor).
After that, the elems_temp array is written in place of the elems_result array.
for (int i = 0; i < array_size(comparators); i++) { pair_t comparator = comparators[i]; if (rank == comparator.a) { MPI_Send(elems_result, elems_per_proc_count, MPI_UNSIGNED, comparator.b, 0, MPI_COMM_WORLD); MPI_Recv(elems_current, elems_per_proc_count, MPI_UNSIGNED, comparator.b, 0, MPI_COMM_WORLD, &status); for (int res_index = 0, cur_index = 0, tmp_index = 0; tmp_index < elems_per_proc_count; tmp_index++) { uint32_t result = elems_result[res_index]; uint32_t current = elems_current[cur_index]; if (result < current) { elems_temp[tmp_index] = result; res_index++; } else { elems_temp[tmp_index] = current; cur_index++; } } swap_ptr(&elems_result, &elems_temp); } else if (rank == comparator.b) { MPI_Recv(elems_current, elems_per_proc_count, MPI_UNSIGNED, comparator.a, 0, MPI_COMM_WORLD, &status); MPI_Send(elems_result, elems_per_proc_count, MPI_UNSIGNED, comparator.a, 0, MPI_COMM_WORLD); int start = elems_per_proc_count - 1; for (int res_index = start, cur_index = start, tmp_index = start; tmp_index >= 0; tmp_index--) { uint32_t result = elems_result[res_index]; uint32_t current = elems_current[cur_index]; if (result > current) { elems_temp[tmp_index] = result; res_index--; } else { elems_temp[tmp_index] = current; cur_index--; } } swap_ptr(&elems_result, &elems_temp); } } On the githaba.
I / O Features
For the input, we will use the function MPI_File_read_ordered () , which sequentially reads from the file equal fragments of the array for each processor. If there is not enough data from the file, it will not overwrite the dummy zeros with which the array is initialized.
For output, we will use the similar function MPI_File_write_ordered () , but for each processor it is necessary to calculate how many elements it should write to the file. Such a need arises if the length of the array being sorted was not a multiple of the number of processors.
Consider more.
Source code output
The idea is as follows. Suppose we have an array of 15 elements, 3 elements per processor (variable elems_per_proc_count ) (Figure 5 below). You must skip the first 5 items ( skip variable).

Figure 5. An example of the distribution of an array of processors. It is necessary to display the circled blue elements.
For each processor, we will calculate the offset (variable print_offset ) relative to the beginning of the array from which to start output, as well as the number of output elements (variable print_count ).
Three cases are possible.
Consider the calculation of the displacement. Obviously, the offset is always zero, except for the processor, which ends the number of elements to be skipped. The number of such a processor is calculated as the ratio of skip to elems_per_proc_count with a drop of the fractional part, and the number of elements that do not need to be output to this processor, as the remainder of the division in the specified ratio.
Thus, after grouping all the conditions, we get an expression for print_offset .
Using the code below, it is easy to understand the formula for calculating the number of elements.
On the githaba.
Figure 5. An example of the distribution of an array of processors. It is necessary to display the circled blue elements.
For each processor, we will calculate the offset (variable print_offset ) relative to the beginning of the array from which to start output, as well as the number of output elements (variable print_count ).
Three cases are possible.
- The processor does not output anything, that is, the offset is zero, the number of outputs is zero.
- The processor outputs some of its elements, that is, the offset is the number of elements to be skipped, the number of output is the difference elems_per_proc_count and the offset.
- The processor outputs all its elements of the array, i.e., the offset is zero, the number of output is elems_per_proc_count .
Consider the calculation of the displacement. Obviously, the offset is always zero, except for the processor, which ends the number of elements to be skipped. The number of such a processor is calculated as the ratio of skip to elems_per_proc_count with a drop of the fractional part, and the number of elements that do not need to be output to this processor, as the remainder of the division in the specified ratio.
Thus, after grouping all the conditions, we get an expression for print_offset .
Using the code below, it is easy to understand the formula for calculating the number of elements.
// , . int skip = elems_count_new - elems_count; // , . int print_offset = (skip / elems_per_proc_count == rank) * (skip % elems_per_proc_count); // . int print_count = (skip / elems_per_proc_count <= rank) * elems_per_proc_count - print_offset; // 0. MPI_File_write_ordered(output, &elems_count, rank == 0, MPI_UNSIGNED, &status); // . MPI_File_write_ordered(output, (unsigned char *)elems_result + print_offset * array_item_size(elems_result), print_count, MPI_UNSIGNED, &status); On the githaba.
Testing a 32-bit application
Files with random unsigned integers for a different number of elements were generated, after which the result of the program was compared with a reference response obtained using the standard qsort () function.
The table below compares the speed of the sequential algorithm with the sort of Batcher on a different number of processors.
On a stationary machine (Intel Core i7-3770 (4 cores, 8 threads), 8 GB RAM):
(Dashes - errors in allocating the required amount of memory).
Source
The source code for this sorting is available on GitHub at the following link: https://github.com/zodinyac/batcher-sort . You can also find a test generator and other auxiliary utilities described in README.md .
References
- Yakobovskiy M.V. Parallel Algorithms for Sorting Large Volumes of Data.
- Yakobovskiy MV Introduction to parallel methods for solving problems.
- Tyutlyaeva EO. Integration of the Batcher parallel sorting algorithm and the active data storage system.
Source: https://habr.com/ru/post/275889/
All Articles