Service Monitoring with Prometheus

In previous publications, we have already touched on issues of monitoring and collecting metrics. In today's article we would like to return to this topic and tell you about an interesting tool called Prometheus . It was created in 2012 as an internal monitoring system for the notorious SoundCloud project, but later became more widespread.
Prometheus is a completely new tool (the first public release took place in early 2015), and there are almost no publications about it in Russian (a few months ago an article was published in Hacker magazine , but it is available only to subscribers).
')
SoundCloud developers note (see the detailed report here ) that they needed a new monitoring tool in connection with the transition to the microservice architecture. Growing interest in microservices is one of the characteristic trends of the past few years.
From the point of view of the microservice approach, the application is understood not as a monolith, but as a set of services. Each of these services works in its process and interacts with the environment using a simple mechanism (usually via the HTTP protocol).
Monitoring microservices is not an easy task: in real time, you need to monitor both the state of individual components and the state of the system as a whole. The task is complicated if, in addition to technical ones, it is necessary to check also business-significant indicators. As the Prometheus developers themselves note in numerous articles and reports, it is difficult to solve it using the existing monitoring systems. Therefore, they created their own tool.
Prometheus is a comprehensive solution, which includes a monitoring framework and its own temporal database. In some reviews, it is even called the " new generation monitoring system ."
We were interested in the publications about Prometheus, and we decided to get acquainted with this tool more closely.
Prometheus Architecture
Prometheus contains the following components:
- a server that reads the metrics and stores them in a time series database;
- client libraries for various programming languages (Go, Java, Python, Ruby; the community also created libraries for Bash, Node.js, Haskell, .NET / C #);
- Pushgateway - component for receiving short-term process metrics;
- PROMDASH - dashboards for metrics;
- tools for exporting data from third-party applications (Statsd, Ganglia, HAProxy, and others);
- Notification Manager AlertManager (currently in beta testing);
- command line client for querying data .
Most of them are written in Go, and a very small part in Ruby and Java.
All Prometheus components communicate via HTTP:
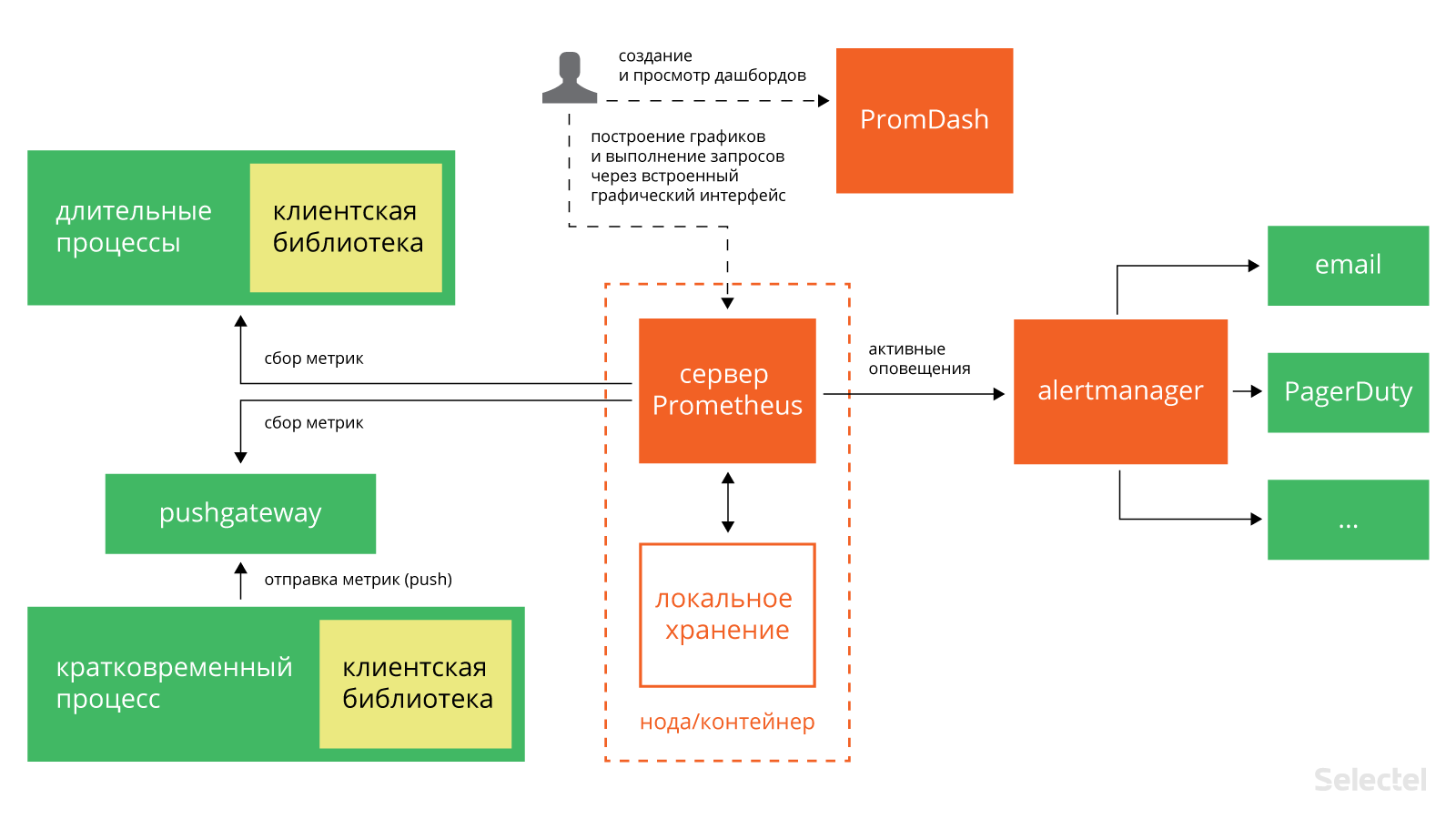
The main component of the entire system is the Prometheus server. It works offline and stores all data in a local database. The discovery of services occurs automatically. This simplifies the deployment procedure: to monitor one service, you do not need to deploy a distributed monitoring system; it is enough to install only the server and the necessary components for collecting and exporting metrics. There are already quite a few such components “honed” for specific services: for Haproxy, MySQL, PostrgreSQL and others (see the full list here , as well as on GitHub ).
Prometheus collects metrics using a pull mechanism. There is also the possibility of collecting metrics using the push mechanism (for this, a special component pushgateway is used , which is installed separately). This may be necessary in situations where the collection of metrics with the help of pull for one reason or another is impossible: for example, when observing services protected by a firewall. Also, the push mechanism can be useful when monitoring services that connect to the network periodically and for a short time.
Prometheus is well suited for collecting and analyzing data presented in the form of time series (time series). It stores all metrics in its own temporal database (see its comparison with OpenTSDB and InfluxDB here ); LevelDB is used to store indexes.
Data model
Prometheus stores data in the form of time series, a set of values associated with a timestamp.
An element of a time series (dimension) consists of the name of a metric, a time stamp, and a key-value pair. Time stamps are accurate to milliseconds, values are presented with 64-bit accuracy.
The name of the metric indicates a system parameter about which data is being collected. For example, a metric with information about the number of HTTP requests to a certain API name might look like this: api_http_requests_total. A time series in such a metric can store information about all GET requests to the address / api / tracks that were answered with the code 200. This time series can be represented as the following notation:
api_http_requests_total{method="GET", endpoint="/api/tracks", status="200"} The data model used in Prometheus resembles the one used in OpenTSDB. All metrics have a name, but it can be the same for several rows.
In addition, each time series must be marked with at least one tag. Measurements for one tag are stored sequentially, which provides fast data aggregation.
The following types of metrics are supported:
- counter (counter) - stores values that increase over time (for example, the number of requests to the server);
- scale (gauge) - stores values that over time can either increase or decrease (for example, the amount of RAM used or the number of I / O operations);
- histogram (histogram) - stores information about a certain parameter change during a certain period (for example, the total number of requests to the server from 11 to 12 hours and the number of requests to the same servers from 11.30 to 11.40);
- summary of results (summary) - like a histogram, it stores information about changes in the value of a certain parameter over a time interval, but also allows calculating quantiles for sliding time intervals.
Installation
Consider now the practical aspects of using Prometheus. Let's start with a description of the installation procedure.
More recently, Prometheus has been included in the official repositories of Debian 8 and Ubuntu 15.10.
In Ubuntu 14.04, it can also be installed using the standard package manager. Naturally, for this you need to connect the corresponding repository:
$ echo 'deb http://deb.robustperception.io/ precise nightly' > /etc/apt/sources.list $ wget https://s3-eu-west-1.amazonaws.com/deb.robustperception.io/41EFC99D.gpg $ sudo apt-key add 41EFC99D.gpg $ sudo apt-get update $ sudo apt-get install prometheus node-exporter alertmanager Using the above commands, we installed the Prometheus server, as well as additional components - node_exporter and alertmanager. Node_exporter collects data on the server status, and the alertmanager (we'll talk about it in more detail below) sends out notifications if the specified conditions are met or not met.
The installation is complete, but there is one more small touch: you need to make sure that the node_exporter constantly collects metrics in the background. To do this, first create a symbolic link in / usr / bin:
$ sudo ln -s ~/Prometheus/node_exporter/node_exporter /usr/bin Then create the /etc/init/node_exporter.conf file and add the following lines to it:
# Run node_exporter start on startup script /usr/bin/node_exporter end script Save the changes and execute the command:
$ sudo service node_exporter start In distributions that have switched to systemd (for example, in Ubuntu 15.10), to run node_exporter in the background, you need to create the /etc/systemd/system/node_exporter.service file and add the following lines to it:
[Unit] Description=Node Exporter [Service] ExecStart=/usr/sbin/node_exporter Restart=Always [Install] WantedBy=default.target After saving the changes, you need to run the following commands:
$ sudo systemctl enable node_exporter.service $ sudo systemctl start node_exporter Configuration
The default settings of Prometheus are enough to keep track of everything happening on the local machine. Additional settings, if necessary, can always be written in the configuration file /etc/prometheus/prometheus.yml. Consider its structure in more detail. It begins with the globals section:
global: scrape_interval: 15s evaluation_interval: 15s rule_files: It includes the following parameters:
- scrape_interval - metrics collection interval (15 seconds by default);
- evaluation_interval - matching interval with rules (15 seconds by default);
- rule_files - rule files (discussed below).
The following is the scrape_configs section with basic metrics collection settings on the server:
scrape_configs: - job_name: "prometheus" - scrape_interval: "15s" target_groups: - targets: - "localhost:9090" It includes the following required parameters:
- job_name - the name of the task;
- scrape_interval — metrics collection interval (in the example shown, every 15 seconds);
- target_groups - services and service groups for which you need to collect metrics.
In the same section, you can register additional settings:
- scrape_timeout - data waiting time;
- metrics_path - HTTP resource to which metrics will be transmitted;
- scheme - the protocol that will be used to transfer metrics;
- basic_auth - login details for authorization on the server from which metrics will be collected (username :, password :).
Above, we have already mentioned that in the configuration file you can refer to the rule files. The rules help to pre-calculate the most frequently used or resource-consuming parameters and save them as new time series. It is much easier to search for pre-calculated parameters than to re-calculate their values for each query. This can be useful, for example, when working with dashboards that request parameter values during each update.
In general, the syntax of the rules can be represented as follows:
< >{} = < > Let's give more specific and clear examples:
job:http_inprogress_requests:sum = sum(http_inprogress_requests) by (job) new_time_series{label_to_change="new_value",label_to_drop=""} = old_time_series Prometheus is reconciled with the rules at certain intervals specified in the configuration file in the parameter evaluation_). After each reconciliation, Prometheus recalculates the value of the parameter and saves it under a new name with the current timestamp.
So, we have reviewed the structure and syntax of the configuration file. In order for the specified settings to take effect, you need to run the following command (instead of path / to / prometheus.yml specify the path to the configuration file):
$ prometheus -config.file “path/to/prometheus.yml” Web interface
The Prometheus web interface will be available in a browser at: http: // [IP address of the server]: 9090:
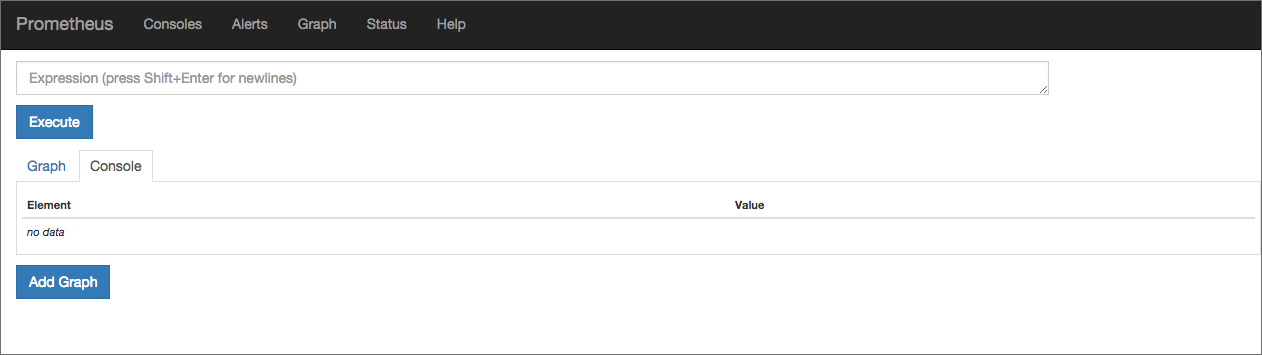
In the Expression field, you can select the metric for which the graph will be displayed. Let's try to track, for example, the amount of active memory on the server. Select the node_memory_active metric and click on the Execute button:

Above the chart there are buttons with which you can select a period for displaying statistics.
Console templates
The main Prometheus console we just reviewed. To view more specialized charts used custom console.
On the server, they are stored in the / etc / prometheus / consoles directory. Custom consoles display general server statistics (node.html), CPU statistics (node-cpu.html), server I / O statistics (cpu-disk.html), and others. In the browser, they are available at http: // [server IP address]: 9090 / consoles / <console name> .html.
This is, for example, the node.html console:
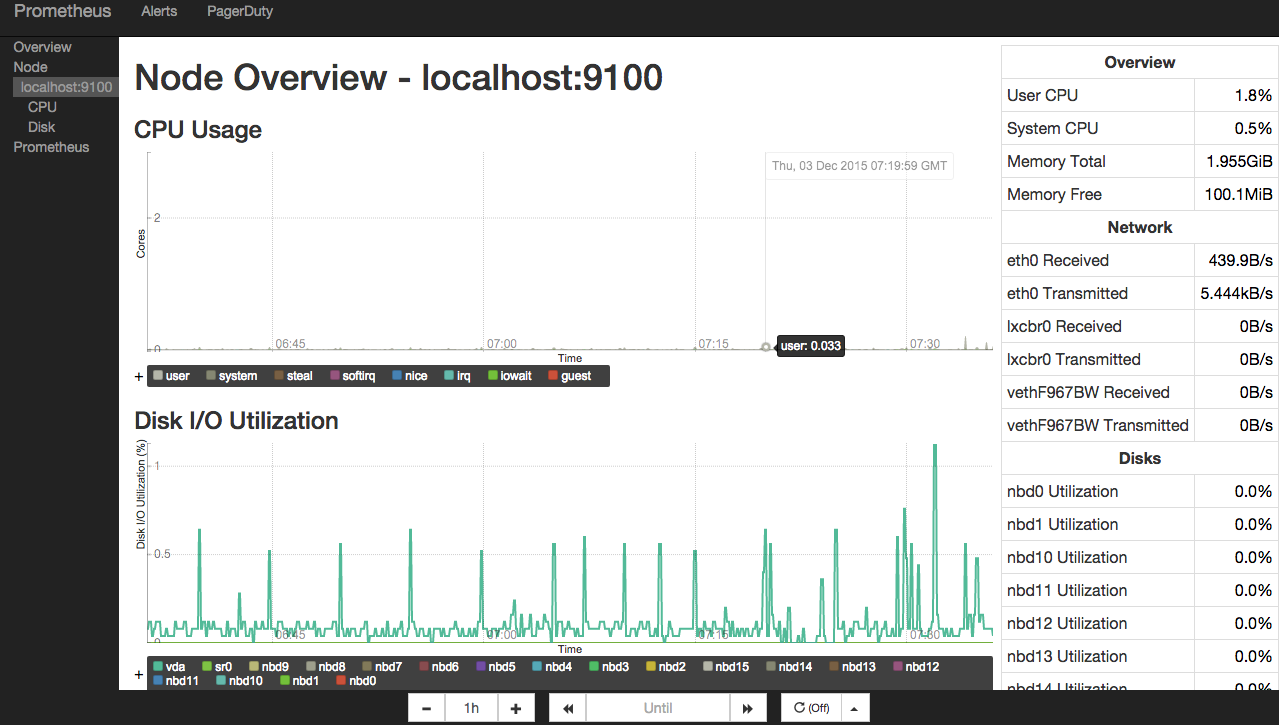
If none of the available consoles are suitable for you, you can create your own console that will display the statistics you need. For writing consoles in Prometheus, the HTML go template is used. Detailed instructions for creating custom consoles are given in the official documentation .
And if for some reason or other you are not satisfied with the available consoles, you can integrate Prometheus with the popular Grafana tool .
The developers of Prometheus created their own dashboard tool called Promdash (see also the repository on GitHub ), which resembles Grafana. In our opinion, it is still in a somewhat "raw" state, and it is too early to recommend it for use.
Alertmanager: setting up notifications
No monitoring tool is unthinkable without a component for sending notifications. Prometheus uses alertmanager for this purpose. Notification settings are stored in the alertmanager.conf configuration file.
Consider the following snippet:
notification_config { name: "alertmanager_test" email_config { email: "test@example.org" } aggregation_rule { notification_config_name: "alertmanager_test" } Its syntax is quite understandable: we indicated that notifications should be sent by e-mail to test@example.org upon the occurrence of a certain condition.
Links to rule files can be added to the configuration file (in fact, they are no different from the rule files used to collect the metrics described above). The rules state the conditions under which you want to send notifications.
In general, the syntax of the rule looks like this:
ALERT < > IF < > FOR < > WITH < >> SUMMARY "< >" DESCRIPTION "< >" Consider the functions of the rules with more specific examples.
Example1:
ALERT InstanceDown IF up == 0 FOR 5m WITH { severity="page" } SUMMARY "Instance {{$labels.instance}} down" DESCRIPTION "{{$labels.instance}} of job {{$labels.job}} has been down for more than 5 minutes." This rule indicates that a notification should be sent in case some instance is unavailable for 5 minutes or more.
Example2:
ALERT ApiHighRequestLatency IF api_http_request_latencies_ms{quantile="0.5"} > 1000 FOR 1m SUMMARY "High request latency on {{$labels.instance}}" DESCRIPTION "{{$labels.instance}} has a median request latency above 1s (current value: {{$value}})" According to this rule, notifications should be sent as soon as the average response time for requests to API exceeds 1 ms.
For the settings specified in the configuration file to take effect, you need to save it and execute the command:
$ alertmanager -config.file alertmanager.conf You can create several configuration files and register notification settings for them in various cases.
Prometheus sends notifications in JSON format. They look like this:
{ "version": "1", "status": "firing", "alert": [ { "summary": "summary", "description": "description", "labels": { "alertname": "TestAlert" }, "payload": { "activeSince": "2015-06-01T12:55:47.356+01:00", "alertingRule": "ALERT TestAlert IF absent(metric_name) FOR 0y WITH ", "generatorURL": "http://localhost:9090/graph#%5B%7B%22expr%22%3A%22absent%28metric_name%29%22%2C%22tab%22%3A0%7D%5D", "value": "1" } } ] } Sending notifications is carried out by e-mail, via a web hook, as well as using specialized services: PagerDuty , HipChat, and others.
Prometheus developers note that so far the alertmanager is in a “raw” state and warn of possible errors. However, we did not notice any anomalies in the operation of this component.
Conclusion
Prometheus is a rather interesting and promising tool, and you should pay attention to it. Among its advantages, one should first of all highlight:
- ease of deployment;
- extensive integration with third-party applications and services;
- convenient graphical interface for working with metrics.
If you already have practical experience using Prometheus, share your impressions. We will be grateful for any useful comments and additions.
For those who want to learn more, here are some useful links:
- https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud - an article about Prometheus from the SoundCloud blog;
- http://www.robustperception.io/blog/ - the blog of one of the Prometheus developers Brian Brazil with interesting practical examples;
- http://agiletesting.blogspot.ru/2015/11/initial-experiences-with-prometheus.html - a curious report on experiments with Prometheus;
- https://www.digitalocean.com/community/tutorials/how-to-install-prometheus-using-docker-on-centos-7 - instructions for installing Prometheus in Docker
- https://github.com/William-Yeh/ansible-prometheus - Ansible role for installing Prometheus.
If for one reason or another you cannot leave comments here - we invite you to our blog .
Source: https://habr.com/ru/post/275803/
All Articles