C calls in Go: principle of operation and performance
The Go language has recently been repeatedly discussed in the Habré — it was both criticized and praised . We at Intel love Go and participate in the open-source development of this project. If you use Go too, you are interested in its internal structure and questions of the most effective programming in this wonderful language, then welcome under cat. The article will be about how the external call mechanism is implemented in Go and how fast it works.
The main principle guided by the creators of Go when designing a language is the maximum simplicity of the organization of this project. The creators deliberately avoid the "overload" and unnecessary functionality available "by default", so all the additional functionality is made into utilities that users of the language can install at will. Thus, Go is not just a platform, it is also a set of useful standard utilities. Go itself includes only the minimum necessary for them, but a great many additional useful tools are always available, provided by the creators of the language or created by the community. For example, among the standard utilities there is go vet , which helps to catch suspicious constructs in the code (and in addition you can put go lint , errcheck , structcheck, and others). The test utility automates the testing of packages, fix - will help in the transition to the new version of Go and the modified API and will make the necessary changes in the already existing code. The creators of Go took care of the convenience and ease of use of these tools, and writing code makes them easy and enjoyable.
Among other things, the creators also provide for the possibility of using C-libraries in Go-programs. This is very important, because at the moment Go-shny packages exist far from all occasions, while in C almost everything is implemented. To use all this wealth of C-libraries in Go, the cgo utility is created. It analyzes the Go code and when compiling the Go program, if necessary, calls the C compiler for the connected C code with the specified flags, and also forms one package from the C and Go files. With its help, C-code is very easy to integrate into Go (see, for example, here )
But inevitably the question arises, how will Go code that actively use C calls work? In order to understand this, you need to learn a little more about the internal mechanism of work environment Go. Looking ahead, I will say that we need this knowledge, because they will allow us to doubt the effectiveness of the work of C-challenges, and to do further analysis ... But let's get everything in order.
')
How the runtime environment works
In Go, there are go-routines - these are the “user-level” execution threads - go-routines are switched within one system thread, each of them has its own stack. It should be noted that the organization of the multithreading model in Go is under a strict theory, namely, the theory of interacting Hoare consecutive processes ( CSP ), used for the formal description of the functioning of parallel systems.
Go is known for its ability to create a huge amount (tens and hundreds of thousands) of go-routines. This is possible due to the fact that initially all go-routines require quite a few resources for their creation - namely, all of them are created with a small stack size (2K stack versus 2M in the case of a standard flow on Linux / x86-32), and in the process their stack relocates as needed. The means of interaction go-rutin is the channel .
Here the question arises: how will the C-calls fit into this system? Will the stack increase for the needs of the C function in the same way as it does for a go-routine? How will the go-routine be planned when making an outside call? At first, all this is quite obvious.
Let's first understand the general mechanism of go-rutin, without external calls. To understand how everything works, consider the internal entities Go, which are usually denoted by the letters g , m and p . Someone is probably familiar with them under the article about the go-scheduler device, the translation of which is also available .
g - structure go-routine descriptor. It contains all the information specific to one go-routine, including data on the current boundaries of its stack, the program counter, and a pointer to the handle of the current system thread in which this go-run is executed (it is indicated by m , and about it just below) . Go-routines are put to execution by the scheduler, which is called at the right moment for this — for example, when the executed go-routine makes a system call or an I / O operation.
Each system thread created by the Go runtime is in turn described by the structure m . M contains internal stream data: its identifier, the go-routine currently running in it, there are state description fields (spinning, blocked, dying) and other Go-specific fields. But among other things there are data that will interest us further - these are the boundaries of the stack allocated to the flow, as well as a pointer to something called the “execution context”.
The execution context of p is also a special structure. The context is needed by the system thread m in order to perform go-routines. Inside itself, p stores a local queue of go-routines, ready for execution. As soon as m has acquired some context p , he can execute go-routines from the local queue belonging to this context. If the local queue is empty, then work-stealing will occur from the queues of other p . There is also a global queue, which all p check periodically.
It is important to understand that there are usually many system threads m at the same time, often more than contexts. But only those threads that have context can do the go-rutin. The number of contexts can be set by the GOMAXPROCS environment variable, and by default it is equal to the number of processor cores. Due to the fact that the number of contexts is fixed, the whole set of go-routines is multiplexed to a given number of OS threads.
The point of introducing a context is that it can be transferred between different OS threads, and the usual go-routines from the local context queue will not notice the difference. When can this be needed? Then when you need to release the current thread for some kind of blocking task. Let's pretend that passing context is impossible. Then if any one go-routine makes a system call, then for those remaining in the local queue it will mean idle. And since the system call can be blocking, the go-routines can remain blocked indefinitely, and this should not be allowed. The transfer of context solves this problem and allows go-routines from the queue to continue to run even in such cases. That is why, before making a system call, the context is transferred to some other free system thread m , and the queue will continue to work freely on this new thread. The system call will be made on the source thread, but without the execution context.
So, we looked at the basic g, m, p entities and slightly touched on system calls. Now we come to the question of external calls in Go.
How external calls are made
As you can see, in Go, the execution model is not at all peculiar to C functions. Therefore, external calls must be handled in a special way, outside the go-rutin mechanism. But we have already started talking about handling system calls in Go — and what if the system calls are also inside the C function? Since this cannot be known knowingly, from the point of view of Go, any arbitrary C-function should be processed so that the system calls inside it work correctly. Consequently, there should be common points in handling Go C-calls and system calls. Let's take a closer look at them, but along the way we will note the differences.
Both syscall and arbitrary C-call are executed in a separate system thread.
We cannot know in advance how long it will take to make a C-call. In the same way as a system call, it can be blocking, and other go-routines should not suffer from this. Therefore, the C-call, like the system call, is always executed in a separate thread, first passing the context to another m . If at the moment of calling free m in the pool was not, then m is created on the go. Important note: since both C functions and system calls are executed without context, they are not subject to the GOMAXPROCS restriction, which means that they will be executed in a separate thread even with GOMAXPROCS = 1. This way it is guaranteed that the execution of the go-rutin cannot be blocked by anyone.
We also emphasize that the created system threads remain alive after the completion of a system call or C function and can be reused, and new m will always be created only in the absence of free ones.
Both are required to "switch" the stack.
As you might guess, the go-routine stack and the OS thread stack are not the same thing. This is already clear from those considerations that the go-routine is many times larger than threads, plus the entire stack size of each go-routine changes dynamically during the program.
Indeed, the go-rutin stacks are heaped and maintained by the runtime, regardless of the OS thread stacks. Initially, all go-routines start with a small 2K stack, then the stack can grow and shrink. While system stacks are the most common stacks of system threads m. In order to store the borders of the system stack, there is a special go-routine g0 in the structure m : it is special because the limits of the system stack are stored as its stack. From here and the accepted designation for a system stack in Go: m-> g0 stack .
System calls and C functions work on the m-> g0 stack. That is why, before launching them, a "stack switch" is required. In the case of the C function, this will be done inside the runtime.asmcgocall () function. There is literally the following:
- The current SP go-routine is saved in spec. m field of structure.
- SP go-routine: = SP of this system thread.
In the case of a system call, the difference lies in the fact that, for the sake of optimization, not all of them will be performed on the system stack, but only some internal functions for which this is explicitly spelled out (and the switching is done inside the systemstack () function).
In both cases, you need the binding of the calling go-routine to the current thread m
So, in order for the C functions to execute correctly, they need to be run on the system
stack But there is one more thing: before the control is transferred to the C-code, you need to inform the execution environment that the stream becomes "sish", and it cannot be used to plan new go-routines. This is done using the runtime.LockOSThread () function. Thus, it is guaranteed that no other go-routine will be assigned to this m until the current one is completed, or until the current go-routine does not call runtime.UnlockOSThread () .
There is some delay when returning from a system call or from a C function.
After the completion of the C function or the system call, the go-routine may not always immediately continue to be executed. Remember, before executing the C function itself, the context p was passed to another thread m ? Now we are again returning to the execution of the Go code, which means that in order to continue execution we need to get the context again (the same or different).
In the current implementation of the go-routine scheduler, it first tries to get the same execution context p that was given by it. If this succeeds (for example, if p is not used by anyone and is in the idle state), then the work continues (and the delay is minimal).
If it is impossible to get p at once, and all other p are also busy, then the go-routine is blocked. The reason for this is the existing GOMAXPROCS restriction: no more than $ GOMAXPROCS go-rutin can run simultaneously (that is, no more than there are contexts), and a new go-rut is set to be executed only when one of the executables is ready to “give up” i.e. will do some kind of blocking operation. It turns out that, returning from the C-call, the go-routine will have to wait until someone “gives up” the context at will. If external calls occur frequently, then waiting for the release of p upon returning from the C-call can spoil everything.
It is not difficult to see if you write the following code:
package main import ( "fmt" "sync" "runtime" ) func main() { runtime.GOMAXPROCS(5) var wg sync.WaitGroup wg.Add(1) go func() { defer wg.Done() work() }() for i := 0; i < 10; i++ { go spinlock() } wg.Wait() } func spinlock() { for { } } func work() { fmt.Println("I am working!") } Here, with the given constraint GOMAXPROCS = 5, 10 go-routines are created, which work in infinite cycles, and then another go-routine that displays something on the screen. After all of them are created, some 5 of them receive contexts and are executed. If you run this example several times, you can catch the situation when work has time to get the context at the beginning and work out. But if it turns out that 5 “endless” go-routines have started to be executed, then they will not give up the context, and work () will never be able to be executed.
C function call
Let's follow the course of events occurring during the C-call. Let some C-function f () be called. This unfolds into the next sequence of calls shown in the figure. The solid arrow indicates the function call, the dotted line is the return of control.

Let's see what will happen at each step:
Step 1. Fixing the Go-routine for the current m (call lockOSThread ())
Step 2. Choosing m from the pool of system threads (if there are no free m - creating a new thread) and passing the context to the selected m
Step 3. Switching the stack of the go-routine to m-> g0 operating system thread stack
Step 4. Preparing the C-function call f and directly calling the function itself. By preparation is meant a casting to the calling agreement corresponding to a specific architecture (for example, on x86_64, the function arguments will be put in the corresponding registers). Returning the value of the C-function also occurs by agreement, so if necessary, a reverse cast will be done (on x86_64, the return value from the register will be moved to the stack)
Step 5. Reverse switching from the OS stack stack to the stack of the current go-routine ( m-> curg stack)
Step 6. Exitsyscall () - the function is blocked inside it until it is possible to execute the Go code without violating the $ GOMAXPROCS restriction
Step 7. As soon as execution is possible - detach the go-routine from m (unlockOSThread ())
Here it should be noted that the creators of Go also provides the ability to make callback-and. A callback happens like this: from a Go-code, a call is made to some C-function, which is passed as an argument to a pointer to some Go-function. In the course of its work, this C-function calls the Go-function according to the pointer passed to it.
At a minimum, the case discussed in the previous part suggests that delays in waiting p will significantly affect the effectiveness of callback. Let's take a closer look at why this is so. We dealt with what is happening in the C-call, but in order to execute the internal Go-code from C, the following actions will be performed:
- A new go-routine will be created.
- Then a reverse stack switch will be performed (from the system one to the stack of the new go-routine)
- New go-routine for execution is needed p . Therefore, it will be blocked and just as when returning from an external call, it will wait until some p is released .
Thus, in the case of callback, in addition to the delay of return from the C-call already considered (due to the expectation of a free p), there is one more delay of the same nature. We obtain that the waiting time p makes a double contribution to the overhead.
How well it works. Overhead
So, let us once again denote the nature of the costs arising from external calls from the go-routine:
Situation 1. A go-routine is waiting for p to be released after returning from the C function.
In this situation, it would seem, there is nothing terrible. But let us imagine that we have a lot of go-rutin and C-calls from them occur quite often (for example, even if we wrote a wrapper to our favorite library and use it according to all Go canons, through a lot of go-rutin). With multiple C-calls, these delays will be, firstly, more likely, and secondly, more prolonged.
Situation 2. At the next external call, there was not enough free flow to execute the remaining go-routines.
In this case, a forced creation of a new thread will occur and the execution context will be transferred to it. Because of this, even the simplest C-function will be executed with a significant delay equal to the overhead of creating an OS-stream. This kind of delay cannot be predicted in the course of the program, since the threads, as we found out, are created out of necessity.
To estimate these costs, you can measure the time spent on the call to an empty C-function from the go-routine in two possible situations:
1) In a situation where a new thread is created.
2) In case the existing stream is reused.
This was done by us. Below is a simple program with which data was obtained.
package main // Run program as ./program pb=<int> // where pb means P_blocked - number of Ps to be in a spinlock. // Program prints to console time (in nanoseconds) elapsed by one C call that is done in goroutine import "fmt" import "time" import "flag" import "sync" // int empty_c_foo() {} // import "C" func spin_lock() { for { } } func main() { var wg sync.WaitGroup wg.Add(1) pb_ptr := flag.Int("pb", 3, "number of Ps that will be in spinlock") flag.Parse() P_blocked := *pb_ptr for i := 0; i < P_blocked; i++ { // «» go spin_lock() } go func() { // C.empty_c_foo() // 2 defer wg.Done() time1 := time.Now() C.empty_c_foo() time2 := time.Now() fmt.Println(int64(time2.Sub(time1))) }() wg.Wait() } In paragraph 1, it is enough to measure the time for one empty C-function called first - since this will be the very first external call, then at the moment it occurs, there is guaranteed no free m in the pool, which means that we will create the thread that we need. In case 2, the program is similar, but measurements are already being made for a repeated C-call, it is expected that the costs will be significantly lower, since m will already be created on the first call.
To simulate the “loaded” execution environment, a number of go-routines were created that were occupied in infinite cycles: their number is indicated by P_spinlocked = 5, 10, 15, ..., 35, and for each such value 100,000 program and measurement launches were made. The program was launched on Intel® Xeon® CPU E5-2697 v2 @ 2.70GHz. By car 48 cores, the parameter GOMAXPROCS = 40, the machine was in exclusive use.
Experimental results for C-call when a new thread is created
| Number P_spinlocked = | five | ten | 15 | 20 | 25 | thirty | 35 |
|---|---|---|---|---|---|---|---|
| % emissions> average + 3 degree of deviation | 0.28% | 0.36% | 0.31% | 0.31% | 0.30% | 0.27% | 0.28% |
| The average | 2537 | 2438 | 2518 | 2534 | 2626 | 2686 | 2719 |
| Standard deviation | 201 | 470 | 200 | 224 | 346 | 369 | 393 |
| Median | 2512 | 2523 | 2493 | 2500 | 2540 | 2590 | 2613 |
| Maximum | 58182 | 65798 | 59543 | 58243 | 55700 | 66620 | 59600 |
| Minimum | 972 | 870 | 1011 | 909 | 1005 | 975 | 937 |
The results of experiments for C-call in the case where the thread has already been created
| Number P_spinlocked = | five | ten | 15 | 20 | 25 | thirty | 35 |
|---|---|---|---|---|---|---|---|
| % emissions> average + 3 degree of deviation | 0.06% | 0.09% | 0.10% | 0.12% | 0.13% | 0.15% | 0.16% |
| The average | 1123 | 1126 | 1137 | 1172 | 1250 | 1283 | 1313 |
| Standard deviation | 183 | 212 | 226 | 300 | 433 | 456 | 492 |
| Median | 1086 | 1076 | 1080 | 1086 | 1099 | 1117 | 1123 |
| Maximum | 68461 | 73383 | 53756 | 49751 | 50581 | 47844 | 86258 |
| Minimum | 391 | 354 | 364 | 348 | 313 | 340 | 351 |
To begin with, let's compare the distribution of C-call durations in cases 1 and 2 (with the same runtime load P_spinlocked = 35). Here we see the expected result - in the case of creating a new stream, the time is longer. The mean values differ approximately by 2 times and are ~ 2600 ns and ~ 1200 ns, respectively, for the 1 and 2 cases.

In the figures below, for each case, the distribution of durations with a low load (P_spinlocked = 5) and with a high load (P_spinlocked = 35) (without emissions) is presented separately.
A gradual increase in the runtime load allowed us to see how the costs related to the performance of the execution environment itself are growing - with increasing load, a smooth shift in the average value is observed. This is also clearly seen from the histograms below: for a loaded runtime (P_spinlocked = 35), the histogram is “blurred” towards larger values compared to an unloaded one (P_spinlocked = 5), which means that the complexity of the execution environment is not constant with respect to to the number of go-rutin.


It should also be noted that in both cases there is a fraction of a percent of significant emissions (~ 50,000 ns or more). (This is strange. It would seem that in the second case there is already a flow and there should be no significant delays, but there are nevertheless emissions of the same order as the first case. Apparently, the reason lies in the operating system features not related to the creation of threads)
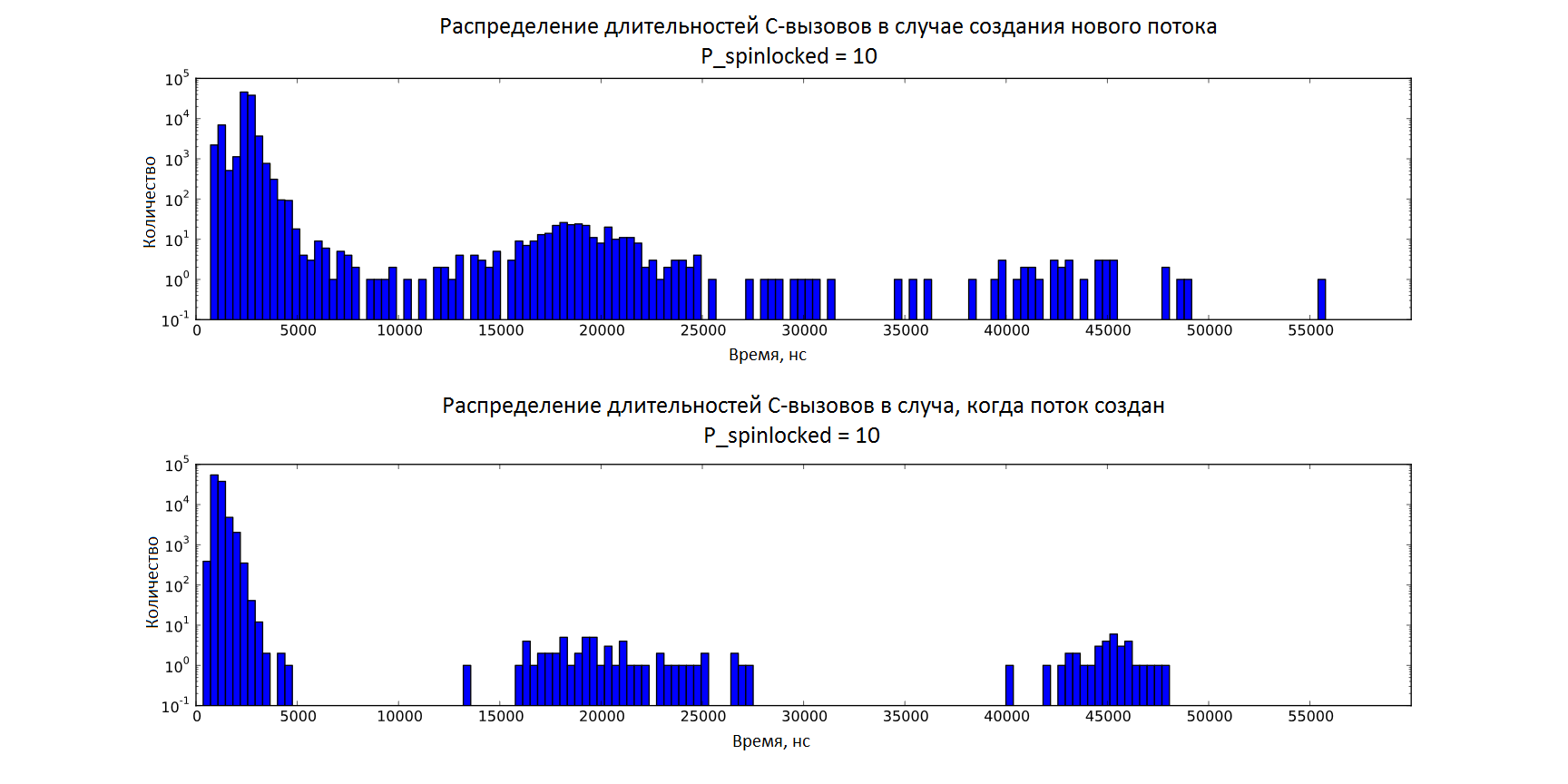
The histogram below (on a logarithmic scale along the y axis) shows all points, including outliers, for both cases with an equal runtime of P_spinlocked = 10. Here you can estimate the share of outliers among all the obtained values.
Outside the experiment remains the contribution of the garbage collector. For our experiment, it was forcibly turned off. In reality, he contributes a share of non-determinism, periodically completely stopping the execution of the program (the so-called Stop-the-world stage). Go developers pay great attention to improving its work and minimizing the pauses associated with it in the work of programs. In Go 1.5, the work of the collector is significantly optimized - it is guaranteed that the stop time does not exceed 10 ms, which is very good.
Conclusion
External calls are very costly. In addition, the runtime itself can cause significant unexpected delays in the execution of external calls, even in our artificial situation when the garbage collector is turned off, go-routines that create a “load” do not work with memory, and therefore do not provoke stack additions, as well as these "Load" go-routines do not do any expensive operations that could cause a call to the scheduler - which means they are not rescheduled. In reality, with these loaded go-routines, the spread of values will seriously increase in a big way.
The delay due to the creation of threads can be avoided, for example, by organizing the creation of some of their number at the start of the program. But the waiting time for a free context will still remain unpredictable, and with frequent external calls it will only increase, so you have to admit the sad fact is that the active use of cgo from go-routines will have a negative effect on the overall effectiveness of the program and resort to it only from time to time. The likelihood of large delays is, of course, very small, but their possibility calls into question the use of external calls in Go, even for soft real-time systems.
Source: https://habr.com/ru/post/275709/
All Articles