Data Driven Realtime Rule Engine in Wargaming: data analysis. Part 2
In the first part of the article, we explained why DDRRE is needed, as well as how and with what tools the data is collected. The second part of the article will be devoted to using the data stream obtained at the first stage.
Recall the general scheme of the system:
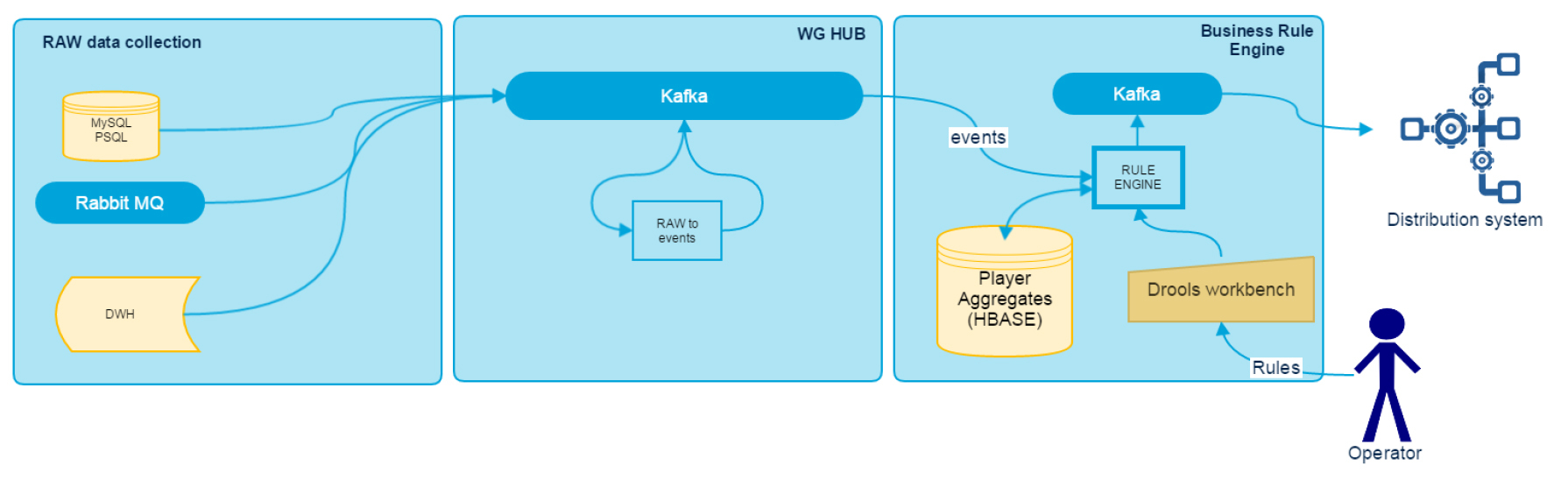
The RAW Data Collection block is described in the first article and is a set of standalone adapters.
The following two are based on parallel stream processing. Spark Streaming is used as a framework. Why precisely he? It was decided that it would be worthwhile to use a single Hadoop distribution - Cloudera, which out of the box includes Spark, HBase and Kafka. In addition, the company at that time already had expertise on Spark.
At the input of the WG Hub subsystem, we get a lot of information from various data sources, but not all of it is ready for direct use and requires some transformation. To convert raw data, the RDT (Raw Data Transformer) module is used, which collects all business logic for integrating data sources. At the output, we receive a standardized message, which is a certain named event with a set of attributes. It is written to Kafka as a serialized Java object. At the entrance, RDT processes the number of topics equal to the number of data sources, while at the output we get one topic with a stream of various events partitioned by player ID. This ensures that during subsequent processing, the data of a specific player are processed only by one executor assigned to the partition (when using Spark Streaming directStream).
The main drawback of this module is the need to edit the code and redeploy in case of a change in the structure of the input data. Now we are working on the use cases in the transformations of a certain metalanguage in order to make the module more flexible and make changes to the logic without the need to write code.
The main task of this module is to provide the end user with the ability to create rules in the system that, in response to events on the data bus and having at their disposal some accumulated historical data about the player, will issue notifications to the final system based on the logic specified by the user. The basis for the Rule Engine was chosen long enough, until we stopped at Drools. Why is he:
')
HBase is used as a repository of historical information on the player. NoSQL storage is great here, because all processing is done by player ID, and HBase does a good job with load balancing and data sharding between regions. The best response we get is if almost all the data fit in the blockCache.
Schematically, the BRE work is as follows:

Drools distributes the rules as a compiled JAR file, so at the first stage we installed a local Maven and set up the project in Workbench on the replay in the repository through the distributionManagement section in pom.xml.
When you start a Spark application in each executor, a separate Drools KieScanner process is launched, which periodically checks the artifact with rules in Maven. The version for checking the artifact is installed in LATEST, which allows in the case of new rules to load them into the currently running code.
When new events arrive at Kafka, BRE accepts a package for processing and reads a block of historical data from HBase for each player. Further events along with the player's data are transmitted to the Drools StatelessKieSession, where they are checked for compliance with the currently loaded rules. As a result, the list of triggered rules is recorded in Kafka. It is on its basis that hints and suggestions are formed to the user in the game client.
Serialization of historical data for storage in HBase. In the early stages of implementation, we used Jackson JSON, with the result that the same POJO was used in two places (in the workbench when writing the rules and in Jackson). This greatly limited us in optimizing the storage format and forced us to use overly complex Jackson annotations. Then we decided to separate the business description of the object from the storage object. The latter is a class generated by the protobuf scheme. As a result, the POJO used in the workbench has a human-readable structure, clear names and is a proxy to the protobuf object.
Query optimization in HBase. During the test operation of the service, it was noticed that, due to the nature of the game, several events from the same account often get into the processing stack. Since the appeal to HBase is the most resource-intensive operation, we decided to pre-group accounts in a bundle by identifier and read historical data once for the whole group. This optimization allowed to reduce requests to HBase by 3-5 times.
Optimize Data Locality. In our cluster, the machines combine Kafka, HBase and Spark simultaneously. Since the processing begins with reading Kafka, then locality is conducted according to the leader of the readable partition. However, if we consider the entire processing process, it becomes clear that the amount of data read from HBase is much higher than the amount of incoming event data. Consequently, sending this data over the network takes more resources. To optimize the process after reading the data from Kafka, we added an additional shuffle, which regroup data by HBase region and exposes locality by it. As a result, we received a significant reduction in network traffic, as well as a performance gain, due to the fact that each individual Spark task addresses only one specific HBase region, and not all, as it was before.
Optimize resources used by Spark. In the fight for processing time, we also reduced spark.locality.wait, since with a larger number of partitions being processed and a smaller number of executor, the expectation of locality was much longer than the processing time.
In the current version, the module copes with its tasks, but there is still a lot of room for optimization.
The plans for the expansion of DDRRE create a Rule as a service - a special system with which it will be possible to trigger the triggering of the rules not by an in-game event, but by a request from an external service via the API. This will allow you to respond to requests of the form: “What rating does this player have?”, “Which segment does he belong to?”, “Which product is better suited for him?”, Etc.
Recall the general scheme of the system:
The RAW Data Collection block is described in the first article and is a set of standalone adapters.
The following two are based on parallel stream processing. Spark Streaming is used as a framework. Why precisely he? It was decided that it would be worthwhile to use a single Hadoop distribution - Cloudera, which out of the box includes Spark, HBase and Kafka. In addition, the company at that time already had expertise on Spark.
Raw Data Transformer
At the input of the WG Hub subsystem, we get a lot of information from various data sources, but not all of it is ready for direct use and requires some transformation. To convert raw data, the RDT (Raw Data Transformer) module is used, which collects all business logic for integrating data sources. At the output, we receive a standardized message, which is a certain named event with a set of attributes. It is written to Kafka as a serialized Java object. At the entrance, RDT processes the number of topics equal to the number of data sources, while at the output we get one topic with a stream of various events partitioned by player ID. This ensures that during subsequent processing, the data of a specific player are processed only by one executor assigned to the partition (when using Spark Streaming directStream).
The main drawback of this module is the need to edit the code and redeploy in case of a change in the structure of the input data. Now we are working on the use cases in the transformations of a certain metalanguage in order to make the module more flexible and make changes to the logic without the need to write code.
Rule engine
The main task of this module is to provide the end user with the ability to create rules in the system that, in response to events on the data bus and having at their disposal some accumulated historical data about the player, will issue notifications to the final system based on the logic specified by the user. The basis for the Rule Engine was chosen long enough, until we stopped at Drools. Why is he:
')
- This is Java, which means less integration problems.
- included is not the most convenient, but still the GUI to create rules
- KieScanner component that allows you to update the rules without restarting the application
- the ability to use Drools as a library without the need to install additional services
- large enough community
HBase is used as a repository of historical information on the player. NoSQL storage is great here, because all processing is done by player ID, and HBase does a good job with load balancing and data sharding between regions. The best response we get is if almost all the data fit in the blockCache.
Schematically, the BRE work is as follows:
Drools distributes the rules as a compiled JAR file, so at the first stage we installed a local Maven and set up the project in Workbench on the replay in the repository through the distributionManagement section in pom.xml.
When you start a Spark application in each executor, a separate Drools KieScanner process is launched, which periodically checks the artifact with rules in Maven. The version for checking the artifact is installed in LATEST, which allows in the case of new rules to load them into the currently running code.
When new events arrive at Kafka, BRE accepts a package for processing and reads a block of historical data from HBase for each player. Further events along with the player's data are transmitted to the Drools StatelessKieSession, where they are checked for compliance with the currently loaded rules. As a result, the list of triggered rules is recorded in Kafka. It is on its basis that hints and suggestions are formed to the user in the game client.
DDRRE: optimizing and improving
Serialization of historical data for storage in HBase. In the early stages of implementation, we used Jackson JSON, with the result that the same POJO was used in two places (in the workbench when writing the rules and in Jackson). This greatly limited us in optimizing the storage format and forced us to use overly complex Jackson annotations. Then we decided to separate the business description of the object from the storage object. The latter is a class generated by the protobuf scheme. As a result, the POJO used in the workbench has a human-readable structure, clear names and is a proxy to the protobuf object.
Query optimization in HBase. During the test operation of the service, it was noticed that, due to the nature of the game, several events from the same account often get into the processing stack. Since the appeal to HBase is the most resource-intensive operation, we decided to pre-group accounts in a bundle by identifier and read historical data once for the whole group. This optimization allowed to reduce requests to HBase by 3-5 times.
Optimize Data Locality. In our cluster, the machines combine Kafka, HBase and Spark simultaneously. Since the processing begins with reading Kafka, then locality is conducted according to the leader of the readable partition. However, if we consider the entire processing process, it becomes clear that the amount of data read from HBase is much higher than the amount of incoming event data. Consequently, sending this data over the network takes more resources. To optimize the process after reading the data from Kafka, we added an additional shuffle, which regroup data by HBase region and exposes locality by it. As a result, we received a significant reduction in network traffic, as well as a performance gain, due to the fact that each individual Spark task addresses only one specific HBase region, and not all, as it was before.
Optimize resources used by Spark. In the fight for processing time, we also reduced spark.locality.wait, since with a larger number of partitions being processed and a smaller number of executor, the expectation of locality was much longer than the processing time.
In the current version, the module copes with its tasks, but there is still a lot of room for optimization.
The plans for the expansion of DDRRE create a Rule as a service - a special system with which it will be possible to trigger the triggering of the rules not by an in-game event, but by a request from an external service via the API. This will allow you to respond to requests of the form: “What rating does this player have?”, “Which segment does he belong to?”, “Which product is better suited for him?”, Etc.
Source: https://habr.com/ru/post/275705/
All Articles