FT Clustering - everRun by Stratus Technologies
Recently, I met a new manufacturer of server hardware and virtualization software called Stratus Technologies. And although this market has long been divided among well-known manufacturers, their solutions still found their niche, as they decided not to reinvent the wheel, but to offer highly specialized products to the market, which have practically no analogues.
Currently, the Stratus Technologies product portfolio consists of 2 solutions:
1. A hardware solution that replaces a cluster of 2 servers, called ftServer.
2. Software product - the hypervisor everRun.
It is much easier to get a software distribution for tests than a two-node piece of hardware, so first of all I was able to evaluate the hypervisor everRun. Below you can see the results.

In the current difficult times in many companies there is a shortage of budgeting IT projects, especially in the foreign currency indicator. However, the requirements for reliability and fault tolerance of critical systems have not been canceled. And before many, the question arises: how to ensure redundancy of systems?
Consider a possible scenario: you need to provide a temperature control system in one particular storage of raw materials. Let it be ... a cistern of milk. In terms of performance, one node is enough for us, let's say even a desktop instead of a full-fledged server. However, the reliability of such a system must be at a high level, which no stand-alone node will ever provide for us.
Yes, you can always raise such a system on a server virtualization cluster, but what should companies do that have server virtualization not implemented, or there are no free resources? Still, expanding the VMWare cluster is quite expensive, both in terms of hardware and in terms of software and licensing.
')
It is here that a rather logical and, at first glance, obvious idea arises: take 2 identical nodes from the “unnecessary zoo” (desktop, decommissioned server, etc.), connect them and cluster them. Such a system should have several distinctive features:
1. The ability to mirror local disk nodes for the possibility of system migration between nodes;
2. The possibility of mirroring the RAM and processor cache to ensure the function of the FT;
3. This solution must have a reasonable cost.
And at first glance, Stratus everRun has all the listed features.
Let us consider in more detail what our “hero” can do.
The solution is based on the Checkpointing technology, which makes it possible to synchronize cluster nodes in such a way that the failure of one of them does not result in the downtime of our application for a split second.
The main idea behind the technology: replicating the state of the guest virtual machine between two independent nodes with the help of checkpoints - state checkpoints that include absolutely everything: processor registers, dirty pages, etc. At the time of the creation of checkpoint, the guest VM is frozen and thawed only after confirmation (ACK) of receipt of the checkpoint by the second system. The checkpoint is created from 50 to 500 times per second, depending on the current VM load. The speed is determined directly by the algorithm and is not subject to manual adjustment. Thus, the virtual machine lives on two servers at the same time. In the event of a failure of the primary node - the VM starts up on the backup from the last received checkpoint, without losing data and any downtime.
Stratus everRun is a bare-metal hypervisor based on the KVM product. This legacy adds a few nuances to its functionality, but more on that later.
For the operation of this product, we need 2 identical nodes that will be interconnected via an Ethernet channel.
The requirements for these nodes are quite democratic:
• From 1 to 2 sockets.
• From 8 GB RAM.
• At least 2 hard drives per node (to maintain fault tolerance at the 1st node level).
• At least 2 ports 1 GE per node. The first port is reserved for interconnect between the nodes (called A-link). The second - under the control network and data network. At the same time, these networks can be separated into different ports if available. A mandatory requirement for the interconnect channel is a delay of not more than 2 ms (for the implementation of the FT function).
Licensing is made according to the usual scheme - 1 license for 2 pairs of processors. This means that for clustering 2x nodes, we only need 1 license. Clustering of more than two nodes and more than two processors on a node is currently not supported.
There are different license levels: Express and Enterprise.
Express has limited functionality and allows for VM fault tolerance at the HA level. This means that there is no mirroring at the processor cache level, the checkpointing technology described above is not used. Only disk replication and network-level fault tolerance. Failure of one of the nodes will stop the VM from running until it restarts on the second node.
Enterprise license has full functionality, and provides protection at the FT level. Failure of one of the nodes will not lead to VM downtime. However, this imposes an additional load on A-link, and therefore to ensure FT without affecting VM performance, it is recommended to use channel 10 GE as an A-link.
We now turn to practice - testing.
To test this product, I was allocated 2 budget SuperMicro servers in the following configuration:
Not the best iron, but not the desktop.
Having mounted them in one rack directly one above the other and having switched through the switch, I proceeded to install the software.
Already at this stage we are waiting for interesting nuances:
• Currently there are not some common blade solutions in the compatibility sheet. What is the reason of incompatibility with the blades is unknown. I tried to install this software on the IBM FlexSystem in my lab and crashed completely.
• The distribution must be recorded on the physical DVD media. No ISO mount via IPMI console, no USB boot. Only DVD, only hardcore. Fortunately, I had an external DVD drive.
The wizard is based on CentOS and has a fairly familiar interface.
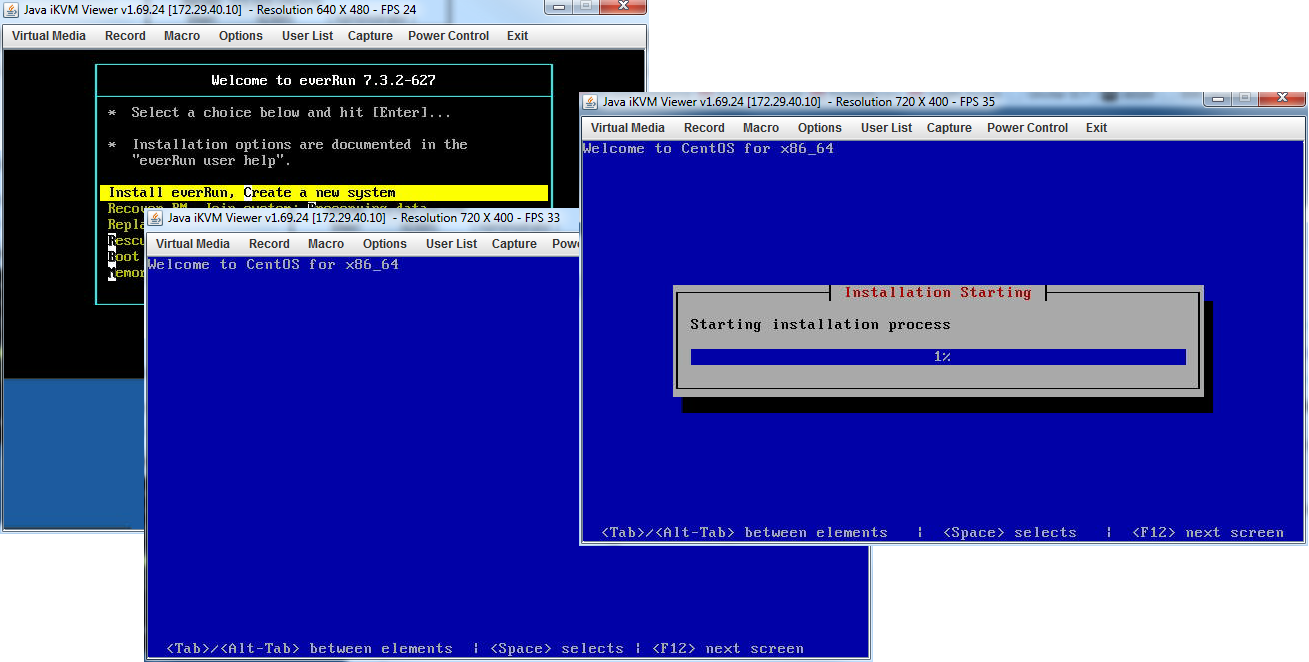
The installation process itself is quite simple:
• Install the software on the first node. During the installation process, you need to select a partition, select ports for the A-link and control networks, and prescribe the necessary IP addresses and root-password.
• Install the software on the second node. In this case, we choose only the installation section and ports. He copies all other information from the main (first) node during the installation process.
After the software is installed on the nodes, you need to connect to the main node by the IP address of the control port. Before us will open the interface for setting up access to the web-interface and license activation.
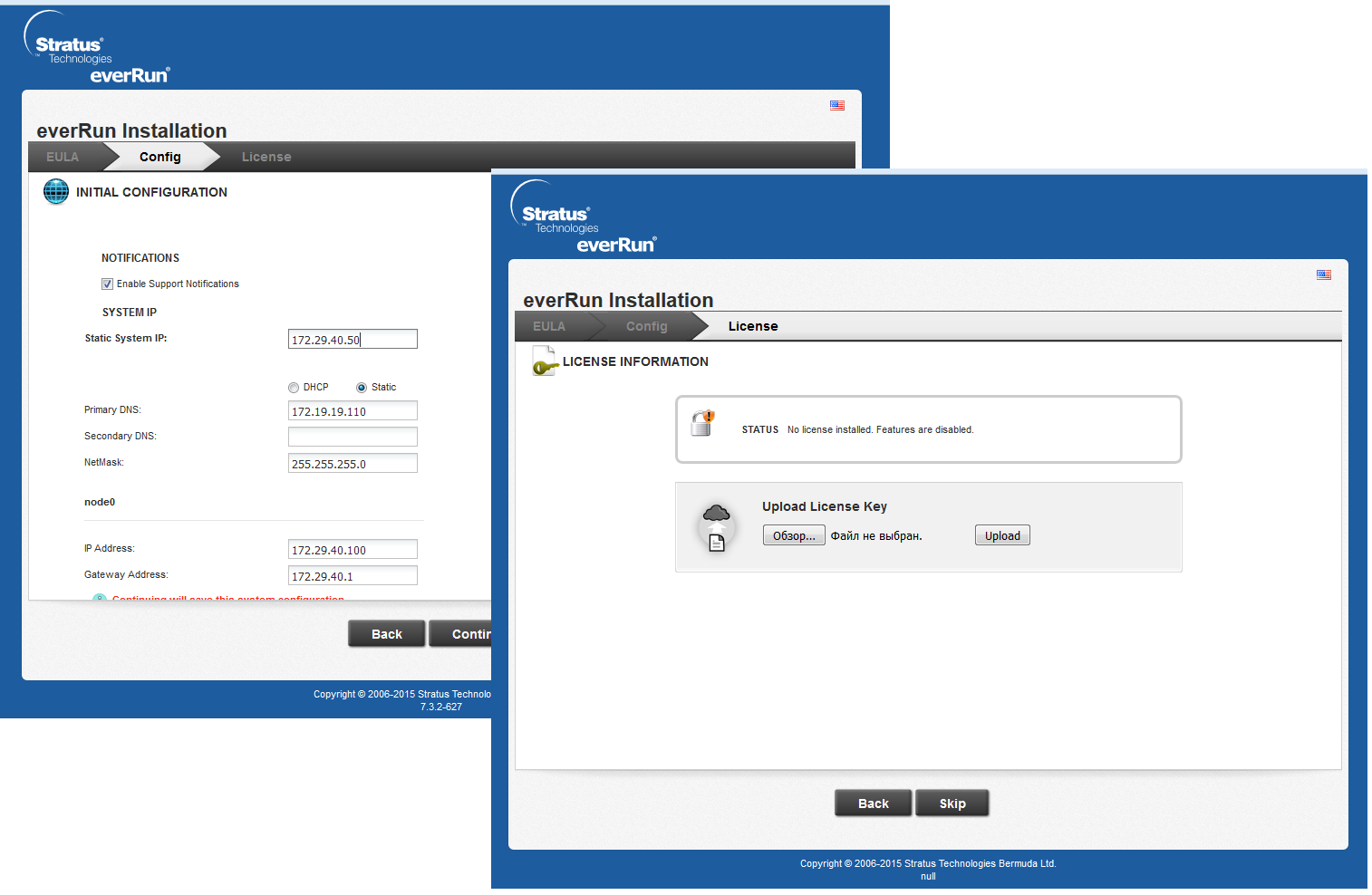
Thus, we have a pool of 5 addresses: 2 addresses of the IPMI ports of the node, 2 addresses of the control ports of the nodes, and 1 address of the web interface.
The interface for everRun is quite simple and pretty.

As you can see in the screenshot of the Dashboard, after installation, the second node remained in maintenance mode. What is the reason for this, I did not understand, maybe some inaccuracies in the installation on my part. The problem was solved by transferring the node to normal mode by hand through the appropriate menu section.
As we can see in the System section, everRun “eats” 2 cores of processor capacity for its own needs. At the same time, we allow overprovisioning.
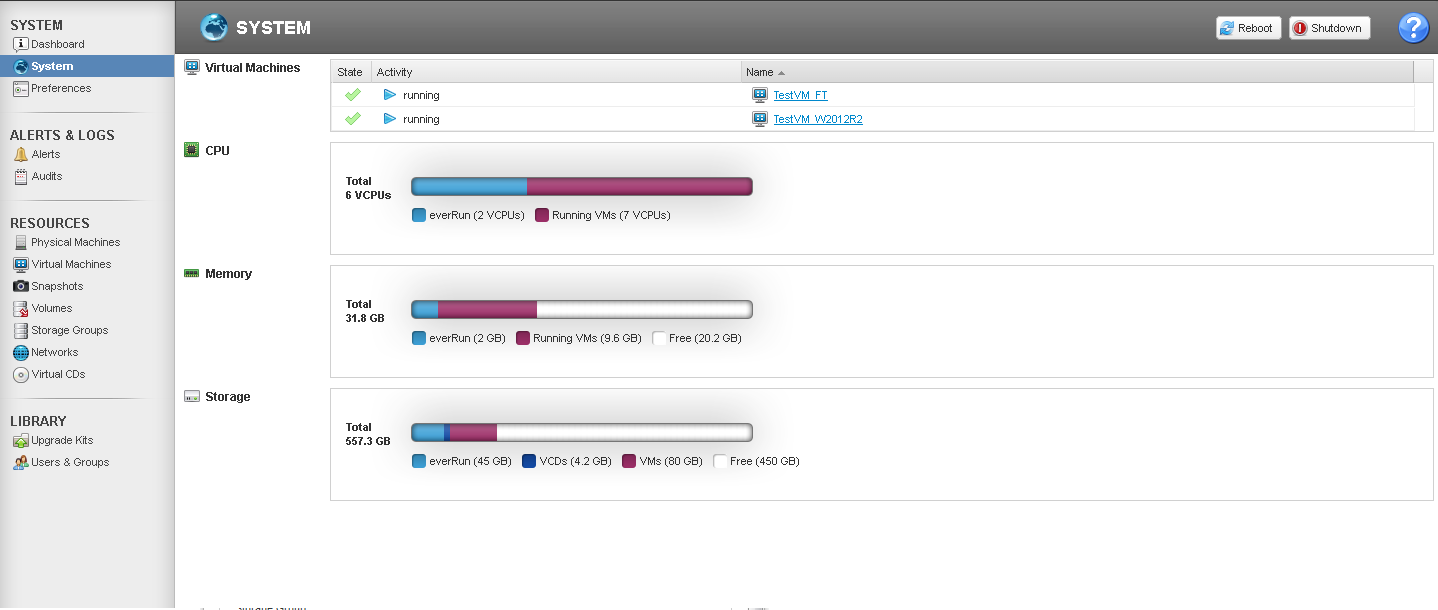
In addition, there are overhead costs for the cores, depending on the level of protection. In the case of HA, n + 1 cluster cores will go to a VM with n cores, and in the case of FT, n + 2 will go away. Thus, 5 cores of the cluster will be allocated to HA VM 4 vCPU, and all 8 cores will go to FT VM 6 vCPU (in the case of multi-user installations, n + 2 will be added per user).
It is noteworthy that the maximum number of vCPU supported in FT VM is 8, which is quite an interesting indicator. For comparison, the vCenter Server (ver 6.x) allows you to create FT VMs only up to 4 vCPUs (and in versions 5.x - up to 1 vCPUs), which significantly reduces the scope of use of this function.
Creating a VM also has a number of nuances, while quite unpleasant. To create a new VM, we need an ISO image of the OS distribution. It must be located on the local cluster volume. You can download it there only via the web interface by clicking on the corresponding menu button.
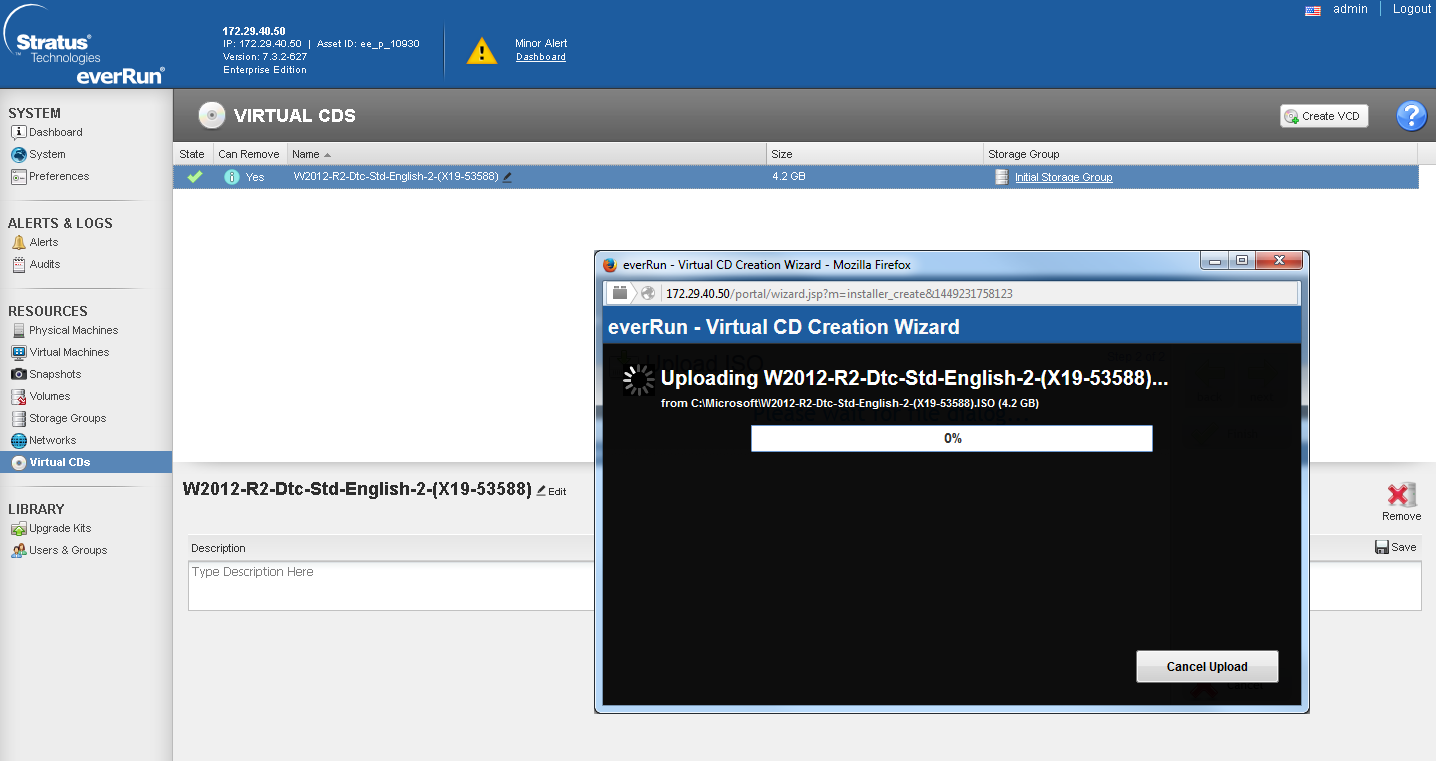
This leads to the fact that you have to download an ISO image from a remote PC over the network. This will either score the entire channel, or it will continue indecently for a long time. For example, the image of Win 2012 R2, weighing 4.2 GB, I poured ~ 4 hours. This also implies the second unpleasant feature: everRun does not allow USB media and PCE-E devices to be forwarded into virtualoks. Those. all possible USB tokens or GPUs cannot be used. In defense of the solution, it can be noted that forwarding USB drives directly to the cluster node significantly reduces the system fault tolerance (since when the node fails, you will need to manually reconnect these media), and forwarding the GPU and further replicating the load on the GPU in FT mode is extremely expensive from the point of view of the system. But still, this fact dramatically narrows the scope of this solution.
After the distribution kit has been loaded on the cluster storage, we proceed to the creation of a VM.
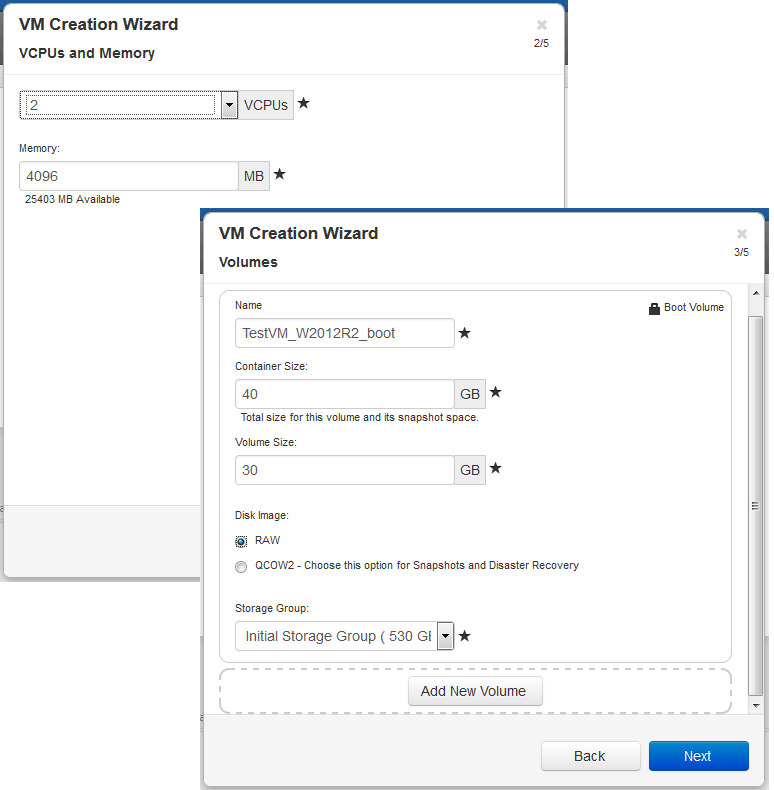
As can be seen from the VM creation wizard, one of the inherited KVM features was 2 types of created partitions: QCOW 2 and RAW. The main difference is that RAW-type volumes do not support the creation of snapshots and DisasterRecovery.
When creating a VM, we need to specify not only the size of the partition, but also the size of the “container”. A container is a volume that contains both the partition itself and its snapshots. Thus, according to the sizing manual, the size of the container is recommended to be made from 2.5 to 3.6 sizes of the VM section, depending on the intensity of the data change:
VolContSize = 2 * VolSize + [(# SnapshotsRetained + 1) * SnapshotSize]
To create consistent snapshots, it is proposed to use separately downloadable clients for Windows and Linux environments.
In a test snapshot creation of a newly created VM with a 30 GB partition, the system ate 8.1 GB. What this space has left for me remains a mystery.
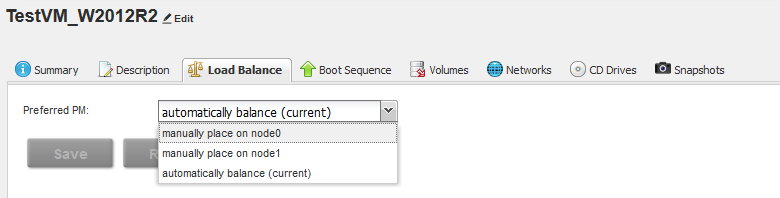
After creating the VM, the Load Balancing function is available to us. The whole point of balancing is that it evenly distributes all VMs across both nodes of the cluster, or in the manual mode it “binds” to a specific node.
As part of the stress test, I created 2 virtual machines: one in HA mode, the second - FT, after which I forcibly extinguished one of the nodes.
HA VM went into reboot, after which it automatically went up to the second node.
FT VM continued normal operation, while the system resource monitor notes an increase in the load on the disk and network subsystems.

Testing this solution, I thought about the areas of its application. Since the product is quite specific, with a lot of nuances, it’s good to be able to show itself only in highly specialized projects.
One of the most obvious will be industrial use. Often, during production there are certain objects that cannot be connected to the existing IT infrastructure, but which have their own requirements for availability and fault tolerance. In this case, the cluster based on everRun will be quite profitable to look at against the background of other commercial clustering systems due to the ratio of the solution's efficiency and functionality.
The second type of projects arising from the features of the first one will be video surveillance, especially when it is necessary to set up a video surveillance system at remote or isolated sites, for example, at railway junctions, oil and gas points, etc. The isolation of these objects from the company's basic infrastructures does not allow them to be included in the existing clusters, and the use of stand-alone video surveillance servers increases the risk of their failure and the resulting maintenance costs.
Pricing Stratus Technologies implies a single price recommended for the end customer for everRun licenses worldwide. Delivery is carried out in the usual way - the license is sold under a non-exclusive right agreement, it goes to a service subscription for a period of at least 1 year, implying the entire amount of technical support in the 5x8 or 24x7 mode, including upgrading to any current version during the subscription period.
Summarizing, we can note the narrow focus of this product. Possessing a number of advantages, it cannot be used everywhere because of the above limitations. But if all these restrictions suit you, then I strongly recommend that you study this solution, since a vendor can easily provide a trial license for a period of 30-60 days.
And for those who are interested in personal testing, but do not have the ability to independently deploy Stratus everRun on local sites, we can always offer remote testing based on our demo stand.
Currently, the Stratus Technologies product portfolio consists of 2 solutions:
1. A hardware solution that replaces a cluster of 2 servers, called ftServer.
2. Software product - the hypervisor everRun.
It is much easier to get a software distribution for tests than a two-node piece of hardware, so first of all I was able to evaluate the hypervisor everRun. Below you can see the results.
In the current difficult times in many companies there is a shortage of budgeting IT projects, especially in the foreign currency indicator. However, the requirements for reliability and fault tolerance of critical systems have not been canceled. And before many, the question arises: how to ensure redundancy of systems?
Consider a possible scenario: you need to provide a temperature control system in one particular storage of raw materials. Let it be ... a cistern of milk. In terms of performance, one node is enough for us, let's say even a desktop instead of a full-fledged server. However, the reliability of such a system must be at a high level, which no stand-alone node will ever provide for us.
Yes, you can always raise such a system on a server virtualization cluster, but what should companies do that have server virtualization not implemented, or there are no free resources? Still, expanding the VMWare cluster is quite expensive, both in terms of hardware and in terms of software and licensing.
')
It is here that a rather logical and, at first glance, obvious idea arises: take 2 identical nodes from the “unnecessary zoo” (desktop, decommissioned server, etc.), connect them and cluster them. Such a system should have several distinctive features:
1. The ability to mirror local disk nodes for the possibility of system migration between nodes;
2. The possibility of mirroring the RAM and processor cache to ensure the function of the FT;
3. This solution must have a reasonable cost.
And at first glance, Stratus everRun has all the listed features.
Let us consider in more detail what our “hero” can do.
Description
The solution is based on the Checkpointing technology, which makes it possible to synchronize cluster nodes in such a way that the failure of one of them does not result in the downtime of our application for a split second.
The main idea behind the technology: replicating the state of the guest virtual machine between two independent nodes with the help of checkpoints - state checkpoints that include absolutely everything: processor registers, dirty pages, etc. At the time of the creation of checkpoint, the guest VM is frozen and thawed only after confirmation (ACK) of receipt of the checkpoint by the second system. The checkpoint is created from 50 to 500 times per second, depending on the current VM load. The speed is determined directly by the algorithm and is not subject to manual adjustment. Thus, the virtual machine lives on two servers at the same time. In the event of a failure of the primary node - the VM starts up on the backup from the last received checkpoint, without losing data and any downtime.
Stratus everRun is a bare-metal hypervisor based on the KVM product. This legacy adds a few nuances to its functionality, but more on that later.
For the operation of this product, we need 2 identical nodes that will be interconnected via an Ethernet channel.
The requirements for these nodes are quite democratic:
• From 1 to 2 sockets.
• From 8 GB RAM.
• At least 2 hard drives per node (to maintain fault tolerance at the 1st node level).
• At least 2 ports 1 GE per node. The first port is reserved for interconnect between the nodes (called A-link). The second - under the control network and data network. At the same time, these networks can be separated into different ports if available. A mandatory requirement for the interconnect channel is a delay of not more than 2 ms (for the implementation of the FT function).
Licensing is made according to the usual scheme - 1 license for 2 pairs of processors. This means that for clustering 2x nodes, we only need 1 license. Clustering of more than two nodes and more than two processors on a node is currently not supported.
There are different license levels: Express and Enterprise.
Express has limited functionality and allows for VM fault tolerance at the HA level. This means that there is no mirroring at the processor cache level, the checkpointing technology described above is not used. Only disk replication and network-level fault tolerance. Failure of one of the nodes will stop the VM from running until it restarts on the second node.
Enterprise license has full functionality, and provides protection at the FT level. Failure of one of the nodes will not lead to VM downtime. However, this imposes an additional load on A-link, and therefore to ensure FT without affecting VM performance, it is recommended to use channel 10 GE as an A-link.
We now turn to practice - testing.
Deployment
To test this product, I was allocated 2 budget SuperMicro servers in the following configuration:
| PN | Description | qty |
|---|---|---|
| SYS-5018R-M | Supermicro SuperServer 1U 5018R-M no CPU (1) / no memory (8) / on board C612 RAID 0/1/10 / no HDD (4) LFF / 2xGE / 1xFH / 1noRx350W Gold / Backplane 4xSATA / SAS | 2 |
| SR1YC | CPU Intel Xeon E5-2609 V3 (1.90Ghz / 15Mb) FCLGA2011-3 OEM | 2 |
| LSI00419 | LSI MegaRAID SAS9341-4I (PCI-E 3.0 x8, LP) SGL SAS 12G, RAID 0,1,10,5, 4port (1 * intSFF8643) | 2 |
| KVR21R15D4 / 16 | Kingston DDR4 16GB (PC4-17000) 2133MHz ECC Reg Dual Rank, x4, 1.2V, w / TS | four |
| ST3300657SS | HDD SAS Seagate 300Gb, ST3300657SS, Cheetah 15K.7, 15000 rpm, 16Mb buffer | four |
Not the best iron, but not the desktop.
Having mounted them in one rack directly one above the other and having switched through the switch, I proceeded to install the software.
Already at this stage we are waiting for interesting nuances:
• Currently there are not some common blade solutions in the compatibility sheet. What is the reason of incompatibility with the blades is unknown. I tried to install this software on the IBM FlexSystem in my lab and crashed completely.
• The distribution must be recorded on the physical DVD media. No ISO mount via IPMI console, no USB boot. Only DVD, only hardcore. Fortunately, I had an external DVD drive.
The wizard is based on CentOS and has a fairly familiar interface.
The installation process itself is quite simple:
• Install the software on the first node. During the installation process, you need to select a partition, select ports for the A-link and control networks, and prescribe the necessary IP addresses and root-password.
• Install the software on the second node. In this case, we choose only the installation section and ports. He copies all other information from the main (first) node during the installation process.
After the software is installed on the nodes, you need to connect to the main node by the IP address of the control port. Before us will open the interface for setting up access to the web-interface and license activation.
Thus, we have a pool of 5 addresses: 2 addresses of the IPMI ports of the node, 2 addresses of the control ports of the nodes, and 1 address of the web interface.
Interface
The interface for everRun is quite simple and pretty.
As you can see in the screenshot of the Dashboard, after installation, the second node remained in maintenance mode. What is the reason for this, I did not understand, maybe some inaccuracies in the installation on my part. The problem was solved by transferring the node to normal mode by hand through the appropriate menu section.
As we can see in the System section, everRun “eats” 2 cores of processor capacity for its own needs. At the same time, we allow overprovisioning.
In addition, there are overhead costs for the cores, depending on the level of protection. In the case of HA, n + 1 cluster cores will go to a VM with n cores, and in the case of FT, n + 2 will go away. Thus, 5 cores of the cluster will be allocated to HA VM 4 vCPU, and all 8 cores will go to FT VM 6 vCPU (in the case of multi-user installations, n + 2 will be added per user).
It is noteworthy that the maximum number of vCPU supported in FT VM is 8, which is quite an interesting indicator. For comparison, the vCenter Server (ver 6.x) allows you to create FT VMs only up to 4 vCPUs (and in versions 5.x - up to 1 vCPUs), which significantly reduces the scope of use of this function.
Creating a VM also has a number of nuances, while quite unpleasant. To create a new VM, we need an ISO image of the OS distribution. It must be located on the local cluster volume. You can download it there only via the web interface by clicking on the corresponding menu button.
This leads to the fact that you have to download an ISO image from a remote PC over the network. This will either score the entire channel, or it will continue indecently for a long time. For example, the image of Win 2012 R2, weighing 4.2 GB, I poured ~ 4 hours. This also implies the second unpleasant feature: everRun does not allow USB media and PCE-E devices to be forwarded into virtualoks. Those. all possible USB tokens or GPUs cannot be used. In defense of the solution, it can be noted that forwarding USB drives directly to the cluster node significantly reduces the system fault tolerance (since when the node fails, you will need to manually reconnect these media), and forwarding the GPU and further replicating the load on the GPU in FT mode is extremely expensive from the point of view of the system. But still, this fact dramatically narrows the scope of this solution.
After the distribution kit has been loaded on the cluster storage, we proceed to the creation of a VM.
As can be seen from the VM creation wizard, one of the inherited KVM features was 2 types of created partitions: QCOW 2 and RAW. The main difference is that RAW-type volumes do not support the creation of snapshots and DisasterRecovery.
When creating a VM, we need to specify not only the size of the partition, but also the size of the “container”. A container is a volume that contains both the partition itself and its snapshots. Thus, according to the sizing manual, the size of the container is recommended to be made from 2.5 to 3.6 sizes of the VM section, depending on the intensity of the data change:
VolContSize = 2 * VolSize + [(# SnapshotsRetained + 1) * SnapshotSize]
To create consistent snapshots, it is proposed to use separately downloadable clients for Windows and Linux environments.
In a test snapshot creation of a newly created VM with a 30 GB partition, the system ate 8.1 GB. What this space has left for me remains a mystery.
After creating the VM, the Load Balancing function is available to us. The whole point of balancing is that it evenly distributes all VMs across both nodes of the cluster, or in the manual mode it “binds” to a specific node.
As part of the stress test, I created 2 virtual machines: one in HA mode, the second - FT, after which I forcibly extinguished one of the nodes.
HA VM went into reboot, after which it automatically went up to the second node.
FT VM continued normal operation, while the system resource monitor notes an increase in the load on the disk and network subsystems.
Application
Testing this solution, I thought about the areas of its application. Since the product is quite specific, with a lot of nuances, it’s good to be able to show itself only in highly specialized projects.
One of the most obvious will be industrial use. Often, during production there are certain objects that cannot be connected to the existing IT infrastructure, but which have their own requirements for availability and fault tolerance. In this case, the cluster based on everRun will be quite profitable to look at against the background of other commercial clustering systems due to the ratio of the solution's efficiency and functionality.
The second type of projects arising from the features of the first one will be video surveillance, especially when it is necessary to set up a video surveillance system at remote or isolated sites, for example, at railway junctions, oil and gas points, etc. The isolation of these objects from the company's basic infrastructures does not allow them to be included in the existing clusters, and the use of stand-alone video surveillance servers increases the risk of their failure and the resulting maintenance costs.
Pricing Stratus Technologies implies a single price recommended for the end customer for everRun licenses worldwide. Delivery is carried out in the usual way - the license is sold under a non-exclusive right agreement, it goes to a service subscription for a period of at least 1 year, implying the entire amount of technical support in the 5x8 or 24x7 mode, including upgrading to any current version during the subscription period.
Summarizing, we can note the narrow focus of this product. Possessing a number of advantages, it cannot be used everywhere because of the above limitations. But if all these restrictions suit you, then I strongly recommend that you study this solution, since a vendor can easily provide a trial license for a period of 30-60 days.
And for those who are interested in personal testing, but do not have the ability to independently deploy Stratus everRun on local sites, we can always offer remote testing based on our demo stand.
Source: https://habr.com/ru/post/275687/
All Articles