Use Apache Spark as SQL Engine

Hi, Habr! We, Wrike , are daily confronted with a stream of data from hundreds of thousands of users. All this information is necessary to preserve, process and extract value from them. Apache Spark helps us to cope with this enormous amount of data.
We will not give an introduction to Spark or describe its positive and negative aspects. You can read about it here , here or in official documentation . In this article, we focus on the Spark SQL library and its practical application for analyzing big data.
')
SQL? I did not think?
Historically, the analytics department of almost any IT company was built on the basis of experts who are well versed in both the subtleties of business and SQL. The work of BI or the analytical department almost never does without ETL . It, in turn, most often works with data sources that are most easily accessed using SQL.
Wrike is no exception. For a long time, the main source of data for us was the shards of our database, combined with ETL and Google Analytics , until we were faced with the task of analyzing user behavior based on server logs.
One solution to this problem may be hiring programmers who will write Map-Reduce for Hadoop and provide data decision making in the company. Why do this if we already have a whole group of qualified specialists who are fluent in SQL and understand the intricacies of the business? The alternative solution is to store everything in a relational database. In this case, your main headache will be to support the schema of both your tables and input logs. About the performance of the DBMS with tables of several hundred million records, we think you can not even speak.
The solution for us was Spark SQL.
Ok, what next?
The main abstraction Spark SQL, unlike Spark RDD , is the DataFrame.
DataFrame is a distributed collection of data organized in the form of named columns. DataFrame is conceptually similar to a table in a database, a data frame in R or Python Pandas , but, of course, optimized for distributed computing.
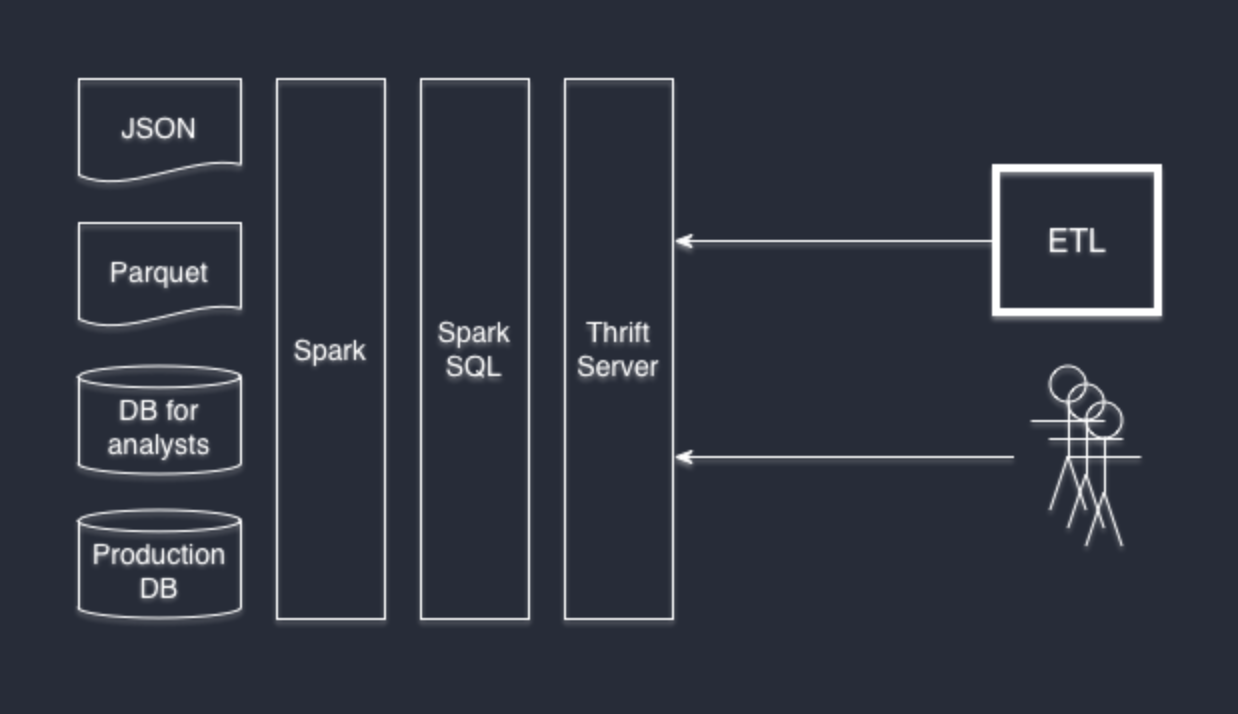
DataFrame can be initialized on the basis of a variety of data sources: structured or weakly structured files, such as JSON and Parquet, regular databases via JDBC / ODBC, and many other methods through third-party connectors (for example, Cassandra ).
DataFrame APIs are available from Scala, Java, Python, and R. From the point of view of SQL, they can be accessed as ordinary SQL tables with full support for all features of the Hive dialect . Spark SQL implements the Hive interface, so you can replace your Hive with Spark SQL without rewriting the system. If you haven’t previously worked with Hive but are familiar with SQL, then you probably don’t need to learn anything further.
Can I connect to Spark SQL with% my-favorite-software%?
If your favorite software supports the use of arbitrary JDBC connectors, then the answer is yes. We like DBeaver , and our developers like IntelliJ IDEA . And they both connect perfectly to Thrift Server.
Thrift Server is part of the standard Spark SQL installation, which turns Spark into a data provider. Raising it is very simple:
./sbin/start-thriftserver.sh Thrift JDBC / ODBC server is fully compatible with HiveServer2 and can transparently replace it with itself.
So, for example, looks like a window connecting DBeaver to SparkSQL:

I want different data providers in one request
Easy. Spark SQL partially expands the Hive dialect so that you can form data sources directly with SQL.
Let's create a "table" based on the logs in json-format:
CREATE TEMPORARY TABLE table_form_json USING org.apache.spark.sql.json OPTIONS (path '/mnt/ssd1/logs/2015/09/*/*-client.json.log.gz') Please note that we use not just a single file, but by the mask we get the data available in a month.
Let's do the same thing, but with our PostgreSQL database. As data, we take not the entire table, but only the result of a specific query:
CREATE TEMPORARY TABLE table_from_jdbc USING org.apache.spark.sql.jdbc OPTIONS ( url "jdbc:postgresql://localhost/mydb?user=[username]&password=[password]&ssl=true", dbtable "(SELECT * FROM profiles where profile_id = 5) tmp" ) Now completely free we can execute a query with JOIN, and the Spark SQL Engine will do the rest of the work for us:
SELECT * FROM table_form_json tjson JOIN table_from_jdbc tjdbc ON tjson.userid = tjdbc.user_id; It is possible to combine data sources in any order. We use PostgreSQL databases, json-logs and parquet-files in Wrike.
Anything else?
If you, like us, are interested in not only using Spark, but also understanding how it works under the hood, we recommend paying attention to the following publications:
- Spark SQL: Relational Data Processing in Spark. Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsi, Matei Zaharia. SIGMOD 2015. June 2015
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. NSDI 2012. April 2012. Best Paper Award
- Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010. June 2010
Source: https://habr.com/ru/post/275567/
All Articles