Search for a variety of regular expressions using the Hyperscan library
In this article, I would like to tell you about my own experience in optimizing the execution of many regular expressions using the hyperscan system. It turned out that when developing my rspamd spam filter , I was faced with the need to port a large amount of old rules written for spamassassin over several years of work. My first decision was to write a plugin that would read these rules and build a syntax tree of them. Then various optimizations were performed on this tree in order to reduce the overall execution time (I even made a small presentation about this).
Unfortunately, during the operation, it turned out that pcre is still a bottleneck, and on large letters this set of rules is too slow. It turned out, for example, that in a megabyte-sized letter, pcre checks around a gigabyte (!) Of text. Various tricks, such as limiting the amount of text for regular expressions, had a negative effect on the triggering of the rules, and optimizing pcre by using jit fast path through pcre_jit_exec was too dangerous - some old expressions were frankly incorrect and combined with incorrect input text, for example, “Broken” UTF8 characters led to reproducible bugs with program stack corruption. However, at the highload conference we talked with Vyacheslav Olkhovchenkov, and he advised me to look at the hyperscan. Next, I'll get to the point and tell you what came out of it.
')
Hyperscan is a project with a rather long history, and it was created to sell deep packets introspection (DPI) solutions. But last October, Intel decided to open its source code, and even under the BSD license. The project is written in C ++ with a rather intensive use of boost, which causes certain problems when porting (but more on that later). Inside, hyperscan is a non-backtracking regular expression engine based on a non-deterministic finite state machine (NFA). In principle, all modern performance-oriented regular expression engines are written using the same theory and discarding backtracking completely (which, of course, is quite rational if you want to ensure a linear search speed). The most important hyperscan feature for me was the ability to simultaneously perform many regular expressions on some text. A naive approach to do the same in pcre is to try to combine several expressions with the operator | in such a "sausage":
Hyperscan consists of two parts: the compiler and, in fact, the engine. A compiler is a very large part of a library that can take a stack of expressions, compose NFA for it and convert this NFA into assembly code using, for example, vector instructions, in particular AVX2. This task is difficult and resource intensive, so the compiler also allows you to serialize the resulting code for later use. The search engine is a smaller library, and it is actually designed to run NFA on a specific text. For applications that use only precompiled expression sets, you can use the separate library libhs_runtime , which is much smaller than the combined library compiler + engine libhs . For a start, I tried to build hyperscan, which turned out to be quite an easy task if there was a fresh boost for the system (minimum version 1.57). The only remark, perhaps, is that when building with debugging symbols, the library turns out to be just gigantic - about 200Mb on my macbook. And since only the static library is built by default, when connected, its size of binaries is also obtained in the region of 200Mb. If debugging symbols are not needed, it is better to assemble hyperscan without them, specifying
Then I tried to compare hyperscan and pcre, writing a very rough prototype, which you can look under the spoiler (I warn you, this is the code of the prototype, which is written in a hurry without any special claims to quality).
The result was quite impressive: on a megabyte spam letter and a set of ~ 1000 regular expressions, I got the following results:
One of the most impressive features of hyperscan is the ability to work as a pre-filter. This mode is useful when there are unsupported constructions in the expression, for example, the same backtracking. In this mode, the hyperscan creates an expression that is a guaranteed superset of the given unsupported expression. That is, the new expression is guaranteed to be guaranteed in all cases of the initial one, but it can also work in other cases, giving false positive operations. Therefore, the result should be checked on the traditional regular expression engine, for example, pcre (although in this case it is not necessary to chase the entire text, but it is necessary to check it from the beginning to the point of occurrence of the expression). This is graphically shown in the following diagram:
Unfortunately, it turned out, and two unpleasant moments. The first of these is compile time — it just takes an unrealistic long time compared to pcre. The second point is related to the fact that some expressions simply compile during pre-filter compilation. The simplest “lofty” expression was, for example, the following:
As a result, I made sure that before compiling the expressions, all the pre-filter expressions are first checked in a separate process fork. And if the expression is compiled too long, then this process is nailed, and the expression is marked as hopeless, that is, pcre is always used for it. There were about ten such expressions from 4 thousand. All of them came from my beloved spamassassin and are quite characteristic products of the disease called “perl brain”. After some communication with Intel engineers, they fixed the infinite compilation, but the above regexp still compiles about a minute, which is unacceptable for practical purposes.
For hyperscan to work, it also turned out to be necessary to break sets of expressions into so-called “classes” - this is the type of input text that is checked through regular expressions from the set, for example, the letter header with a specific name or the full body of the letter, or only text parts. Such classes are shown in the following diagram:
To compile, I used the following approach:
This approach made it possible to start checking email immediately after starting (using pcre), rather than wait for hyperscan’s expensive and long compilation, and upon completion of the compilation, immediately switch from pcre to hyperscan (which is called, without departing from the cash register). And the use of sets of bits for checked and triggered regular expressions also makes it possible not to disturb when switching the work of letters already running in the check.
In the course of rspamd + hyperscan, I got something like this:
It was:
It became:
More regexps matched in the hyperscan version are caused by syntax tree optimizations that are done for pcre, but are useless in the hyperscan case (because all expressions are checked at the same time).
The Hyperscan version is already in production, and is included in the new version of rspamd . I can confidently recommend hyperscan for performance-critical projects for checking regular expressions (DPI, proxy, etc.), as well as for applications to search for static strings in the text.
For the last task, I did a hyperscan comparison with the aho-corasick algorithm traditionally used for such purposes. I compared the fastest Mischa Sandberg implementation to me.
Comparison results for 10 thousand static lines on a megabyte letter with a large number of such lines (that is, the worst possible conditions for aho-corasic, having complexity O (M + N), where M is the number of found lines):
Unfortunately, it also turned out that the number of hits did not converge due to an error in the ac-trie code, while the hyperscan was never mistaken.
Also the materials of this article are available in the presentation . The code can be viewed in the rspamd project on the githab
Unfortunately, during the operation, it turned out that pcre is still a bottleneck, and on large letters this set of rules is too slow. It turned out, for example, that in a megabyte-sized letter, pcre checks around a gigabyte (!) Of text. Various tricks, such as limiting the amount of text for regular expressions, had a negative effect on the triggering of the rules, and optimizing pcre by using jit fast path through pcre_jit_exec was too dangerous - some old expressions were frankly incorrect and combined with incorrect input text, for example, “Broken” UTF8 characters led to reproducible bugs with program stack corruption. However, at the highload conference we talked with Vyacheslav Olkhovchenkov, and he advised me to look at the hyperscan. Next, I'll get to the point and tell you what came out of it.
Hyperscan in brief
')
Hyperscan is a project with a rather long history, and it was created to sell deep packets introspection (DPI) solutions. But last October, Intel decided to open its source code, and even under the BSD license. The project is written in C ++ with a rather intensive use of boost, which causes certain problems when porting (but more on that later). Inside, hyperscan is a non-backtracking regular expression engine based on a non-deterministic finite state machine (NFA). In principle, all modern performance-oriented regular expression engines are written using the same theory and discarding backtracking completely (which, of course, is quite rational if you want to ensure a linear search speed). The most important hyperscan feature for me was the ability to simultaneously perform many regular expressions on some text. A naive approach to do the same in pcre is to try to combine several expressions with the operator | in such a "sausage":
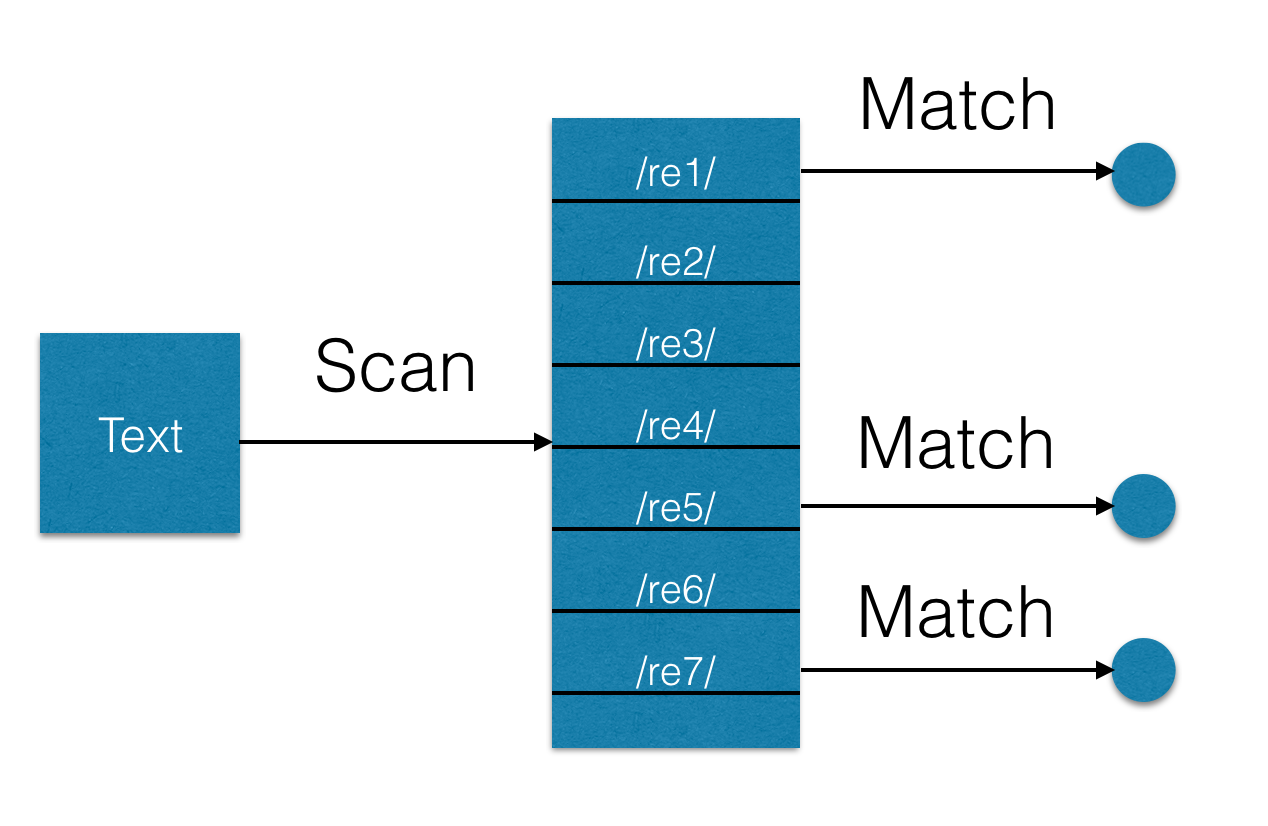
(?: re1) | (?: re2) | ... | (?: reN). Unfortunately, this approach does not work - after all, the task is to find all occurrences from a given set of expressions, and not just those that worked before. Hyperscan does not work the same way - for each expression found, it calls a callback function with a position in the text (but only the last character of the entry), which can be demonstrated in the following diagram:
Hyperscan architecture
Hyperscan consists of two parts: the compiler and, in fact, the engine. A compiler is a very large part of a library that can take a stack of expressions, compose NFA for it and convert this NFA into assembly code using, for example, vector instructions, in particular AVX2. This task is difficult and resource intensive, so the compiler also allows you to serialize the resulting code for later use. The search engine is a smaller library, and it is actually designed to run NFA on a specific text. For applications that use only precompiled expression sets, you can use the separate library libhs_runtime , which is much smaller than the combined library compiler + engine libhs . For a start, I tried to build hyperscan, which turned out to be quite an easy task if there was a fresh boost for the system (minimum version 1.57). The only remark, perhaps, is that when building with debugging symbols, the library turns out to be just gigantic - about 200Mb on my macbook. And since only the static library is built by default, when connected, its size of binaries is also obtained in the region of 200Mb. If debugging symbols are not needed, it is better to assemble hyperscan without them, specifying
-DCMAKE_BUILD_TYPE = MinSizeRelat a configuration stage through cmake.
Test code
Then I tried to compare hyperscan and pcre, writing a very rough prototype, which you can look under the spoiler (I warn you, this is the code of the prototype, which is written in a hurry without any special claims to quality).
Comparison code pcre and hyperscan
#include <iostream> #include <string> #include <fstream> #include <vector> #include <stdexcept> #include <algorithm> #include <set> #include "pcre.h" #include "hs.h" #include <time.h> #ifdef __APPLE__ #include <mach/mach_time.h> #endif using namespace std; double get_ticks(void) { double res; #if defined(__APPLE__) res = mach_absolute_time() / 1000000000.; #else struct timespec ts; clock_gettime(CLOCK_MONOTONIC, &ts); res = (double)ts.tv_sec + ts.tv_nsec / 1000000000.; #endif return res; } struct pcre_regexp { pcre* re; pcre_extra* extra; pcre_regexp(const string& pattern) { const char* err; int err_off; re = pcre_compile(pattern.c_str(), PCRE_NEWLINE_ANYCRLF, &err, &err_off, NULL); if (re == NULL) { throw invalid_argument(string("cannot compile: '") + pattern + "' error: " + err + " at offset: " + to_string(err_off)); } extra = pcre_study(re, PCRE_STUDY_JIT_COMPILE, &err); if (extra == NULL) { throw invalid_argument(string("cannot study: '") + pattern + "' error: " + err + " at offset: " + to_string(err_off)); } } }; struct cb_context { set<int> approx_re; vector<pcre_regexp> pcre_vec; }; struct cb_data { struct cb_context* ctx; vector<int> matched; const std::string* str; }; bool remove_uncompileable(const string& s, int id, struct cb_context* ctx) { hs_compile_error_t* hs_errors; hs_database_t* hs_db; if (hs_compile(s.c_str(), HS_FLAG_ALLOWEMPTY, HS_MODE_BLOCK, NULL, &hs_db, &hs_errors) != HS_SUCCESS) { cout << "pattern: '" << s << "', error: " << hs_errors->message << endl; if (hs_compile(s.c_str(), HS_FLAG_ALLOWEMPTY | HS_FLAG_PREFILTER, HS_MODE_BLOCK, NULL, &hs_db, &hs_errors) != HS_SUCCESS) { cout << "completely bad pattern: '" << s << "', error: " << hs_errors->message << endl; return true; } else { ctx->approx_re.insert(id); } } else { hs_free_database(hs_db); } return false; } int match_cb(unsigned int id, unsigned long long from, unsigned long long to, unsigned int flags, void* context) { auto cbdata = (struct cb_data*)context; auto& matched = cbdata->matched; if (cbdata->ctx->approx_re.find(id) != cbdata->ctx->approx_re.end()) { int ovec[3]; auto re = cbdata->ctx->pcre_vec[id]; auto* begin = cbdata->str->data(); auto* p = begin; auto sz = cbdata->str->size(); while (pcre_exec(re.re, re.extra, p, sz - (p - begin), 0, 0, ovec, 3) > 0) { p = p + ovec[1]; matched[id]++; } } else { matched[id]++; } return 0; } int main(int argc, char** argv) { ifstream refile(argv[1]); vector<string> re_vec; double t1, t2, total_ticks = 0; struct cb_context ctx; int ls; pcre_config(PCRE_CONFIG_LINK_SIZE, &ls); cout << ls << endl; for (std::string line; std::getline(refile, line);) { re_vec.push_back(line); } string re_pipe; const char** pats = new const char*[re_vec.size()]; unsigned int i = 0, *ids = new unsigned int[re_vec.size()]; //re_vec.erase(remove_if(re_vec.begin(), re_vec.end(), remove_uncompileable), re_vec.end()); for (i = 0; i < re_vec.size(); i++) { const auto& r = re_vec[i]; remove_uncompileable(r, i, &ctx); pats[i] = r.c_str(); ids[i] = i; re_pipe = re_pipe + string("(") + r + string(")|"); } // Last | re_pipe.erase(re_pipe.size() - 1); total_ticks = 0; for (const auto& r : re_vec) { t1 = get_ticks(); ctx.pcre_vec.emplace_back(r); t2 = get_ticks(); total_ticks += t2 - t1; } cout << "PCRE compile time: " << total_ticks << endl; ifstream input(argv[2]); std::string in_str((std::istreambuf_iterator<char>(input)), std::istreambuf_iterator<char>()); hs_compile_error_t* hs_errors; hs_database_t* hs_db; hs_platform_info_t plt; hs_populate_platform(&plt); unsigned int* flags = new unsigned int[re_vec.size()]; for (i = 0; i < re_vec.size(); i++) { if (ctx.approx_re.find(i) != ctx.approx_re.end()) { flags[i] = HS_FLAG_PREFILTER; } else { flags[i] = 0; } } t1 = get_ticks(); if (hs_compile_multi(pats, flags, ids, re_vec.size(), HS_MODE_BLOCK, &plt, &hs_db, &hs_errors) != HS_SUCCESS) { cout << "BAD pattern: '" << re_vec[hs_errors->expression] << "', error: " << hs_errors->message << endl; return -101; } t2 = get_ticks(); cout << "Hyperscan compile time: " << (t2 - t1) << "; approx re: " << ctx.approx_re.size() << "; total re: " << re_vec.size() << endl; char* bytes = NULL; size_t bytes_len; t1 = get_ticks(); if (hs_serialize_database(hs_db, &bytes, &bytes_len) != HS_SUCCESS) { cout << "BAD" << endl; return -101; } t2 = get_ticks(); cout << "Hyperscan serialize time: " << (t2 - t1) << "; size: " << bytes_len << " bytes" << endl; hs_database_t* hs_db1 = NULL; t1 = get_ticks(); if (hs_deserialize_database(bytes, bytes_len, &hs_db1) != HS_SUCCESS) { cout << "BAD1" << endl; return -101; } t2 = get_ticks(); cout << "Hyperscan deserialize time: " << (t2 - t1) << "; size: " << bytes_len << " bytes" << endl; auto matches = 0; total_ticks = 0; for (const auto& re : ctx.pcre_vec) { int ovec[3]; auto* begin = in_str.data(); auto* p = begin; auto sz = in_str.size(); t1 = get_ticks(); while (pcre_exec(re.re, re.extra, p, sz - (p - begin), 0, 0, ovec, 3) > 0) { p = p + ovec[1]; matches++; } t2 = get_ticks(); total_ticks += t2 - t1; } //cout << re_pipe << endl; cout << "Time for individual re: " << total_ticks << "; matches: " << matches << endl; //cout << "Time for piped re: " << (t2 - t1) << endl; hs_scratch_t* scratch = NULL; int rc; if ((rc = hs_alloc_scratch(hs_db1, &scratch)) != HS_SUCCESS) { cout << "bad scratch: " << rc << endl; return -102; } struct cb_data cbdata; cbdata.ctx = &ctx; cbdata.matched = vector<int>(re_vec.size(), 0); cbdata.str = &in_str; t1 = get_ticks(); if ((rc = hs_scan(hs_db1, in_str.data(), in_str.size(), 0, scratch, match_cb, &cbdata)) != HS_SUCCESS) { cout << "bad scan: " << rc << endl; return -103; } t2 = get_ticks(); matches = 0; for_each(cbdata.matched.begin(), cbdata.matched.end(), [&matches](int elt) { matches += elt; }); cout << "Time for hyperscan re: " << (t2 - t1) << "; matches: " << matches << endl; return 0; } The result was quite impressive: on a megabyte spam letter and a set of ~ 1000 regular expressions, I got the following results:
PCRE compile time: 0.0138553 Hyperscan compile time: 4.94309; approx re: 191; total re: 971 Hyperscan serialize time: 0.00312218; size: 5242956 bytes Hyperscan deserialize time: 0.00359501; size: 5242956 bytes Time for individual re: 0.440707; matches: 7 Time for hyperscan re: 0.0770988; matches: 7
Prefilter
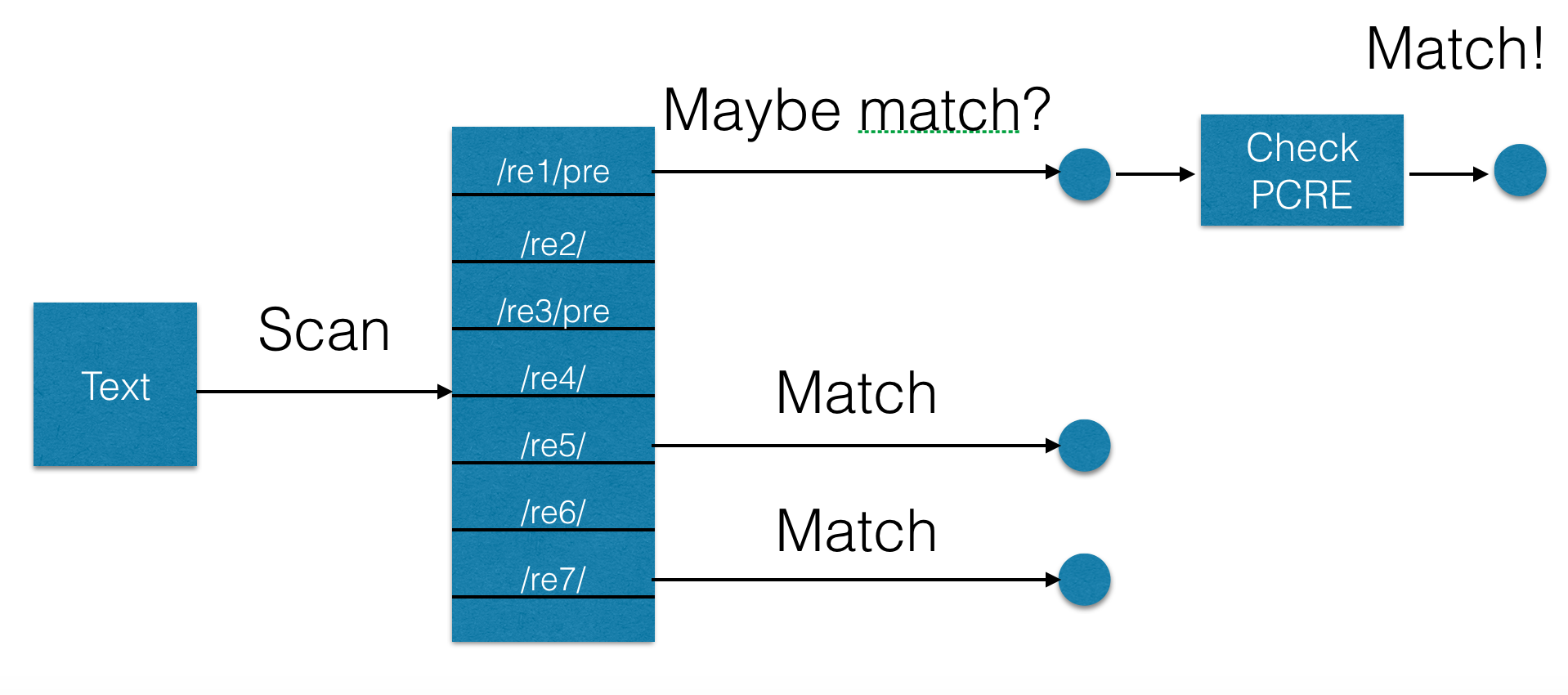
One of the most impressive features of hyperscan is the ability to work as a pre-filter. This mode is useful when there are unsupported constructions in the expression, for example, the same backtracking. In this mode, the hyperscan creates an expression that is a guaranteed superset of the given unsupported expression. That is, the new expression is guaranteed to be guaranteed in all cases of the initial one, but it can also work in other cases, giving false positive operations. Therefore, the result should be checked on the traditional regular expression engine, for example, pcre (although in this case it is not necessary to chase the entire text, but it is necessary to check it from the beginning to the point of occurrence of the expression). This is graphically shown in the following diagram:
Compilation issues
Unfortunately, it turned out, and two unpleasant moments. The first of these is compile time — it just takes an unrealistic long time compared to pcre. The second point is related to the fact that some expressions simply compile during pre-filter compilation. The simplest “lofty” expression was, for example, the following:
<a \ s [^>] {0.2048} \ bhref = (?: 3D)?.? (https?: [^> "'\ #] {8.29} [^>"' \ #: \ /? & =]) [^>] {0.2048}> (?: [^ <] {0.1024} <(?! \ / A) [^>] {1.1024}>) {0, 99} \ s {0.10} (?! \ 1) https? [^ \ W <] {1,3} [^ <] {5}
As a result, I made sure that before compiling the expressions, all the pre-filter expressions are first checked in a separate process fork. And if the expression is compiled too long, then this process is nailed, and the expression is marked as hopeless, that is, pcre is always used for it. There were about ten such expressions from 4 thousand. All of them came from my beloved spamassassin and are quite characteristic products of the disease called “perl brain”. After some communication with Intel engineers, they fixed the infinite compilation, but the above regexp still compiles about a minute, which is unacceptable for practical purposes.
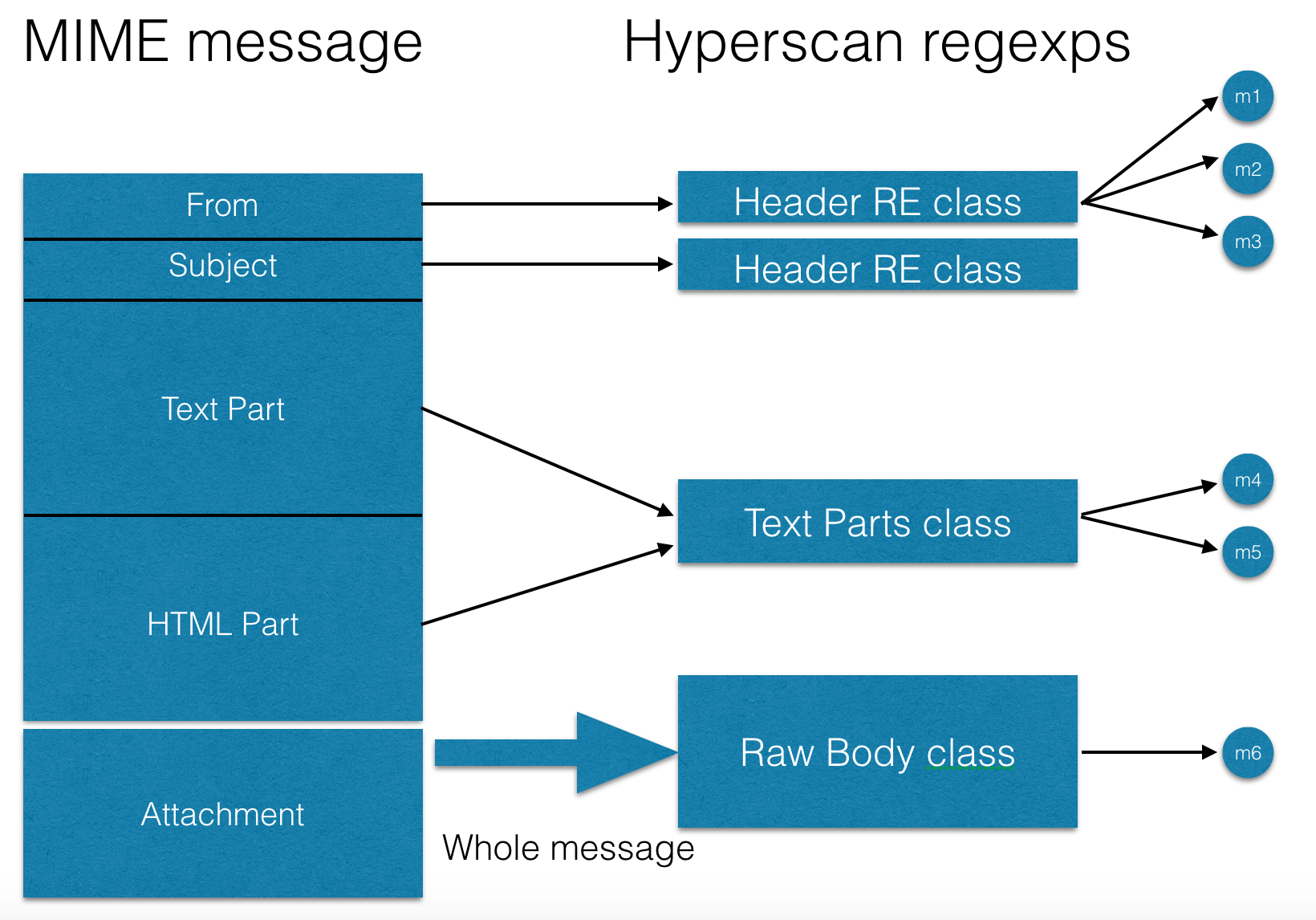
For hyperscan to work, it also turned out to be necessary to break sets of expressions into so-called “classes” - this is the type of input text that is checked through regular expressions from the set, for example, the letter header with a specific name or the full body of the letter, or only text parts. Such classes are shown in the following diagram:
To compile, I used the following approach:
- In a separate process, start checking the expression classes, and for each class, look for whether there is already a compiled and valid file for it.
- If there is no such file or it contains an incorrect set of expressions (checked by the hash from the expression pattern), then compile it by checking the compile time of the preliminary filters.
- When all expressions are compiled in the cache, then send a message to all processes for the scanners to get the scanners to load the cached expressions and switch from pcre to hyperscan.
This approach made it possible to start checking email immediately after starting (using pcre), rather than wait for hyperscan’s expensive and long compilation, and upon completion of the compilation, immediately switch from pcre to hyperscan (which is called, without departing from the cash register). And the use of sets of bits for checked and triggered regular expressions also makes it possible not to disturb when switching the work of letters already running in the check.
findings
In the course of rspamd + hyperscan, I got something like this:
It was:
len: 610591, time: 2492.457ms real, 882.251ms virtual regexp statistics: 4095 pcre regexps scanned, 18 regexps matched, 694M bytes scanned using pcre
It became:
len: 610591, time: 654.596ms real, 309.785ms virtual regexp statistics: 34 pcre regexps scanned, 41 regexps matched, 8.41M bytes scanned using pcre, 9.56M bytes scanned total
More regexps matched in the hyperscan version are caused by syntax tree optimizations that are done for pcre, but are useless in the hyperscan case (because all expressions are checked at the same time).
The Hyperscan version is already in production, and is included in the new version of rspamd . I can confidently recommend hyperscan for performance-critical projects for checking regular expressions (DPI, proxy, etc.), as well as for applications to search for static strings in the text.
For the last task, I did a hyperscan comparison with the aho-corasick algorithm traditionally used for such purposes. I compared the fastest Mischa Sandberg implementation to me.
Comparison results for 10 thousand static lines on a megabyte letter with a large number of such lines (that is, the worst possible conditions for aho-corasic, having complexity O (M + N), where M is the number of found lines):
actrie compile time: 0.0743811 Hyperscan compile time: 0.1547; approx re: 0; total re: 7400 Hyperscan serialize time: 0.000178297; size: 1250856 bytes Hyperscan deserialize time: 0.000312379; size: 1250856 bytes Time for hyperscan re: 0.117938; matches: 3001024 Time for actrie: 0.100427; matches: 3000144
Unfortunately, it also turned out that the number of hits did not converge due to an error in the ac-trie code, while the hyperscan was never mistaken.
Also the materials of this article are available in the presentation . The code can be viewed in the rspamd project on the githab
Source: https://habr.com/ru/post/275507/
All Articles