Cross-platform Open Source Time Tracker
In this article I want to talk about why I needed a time tracker, how I searched for it, why I did not find it and what all this turned out to be in the end.
Select tracker
Almost all my career I work as a freelancer. The specificity of the activity is such that all contracts with payment are not hourly, but for work done within the prescribed period. In such conditions you get used to work when there is a mood - the main thing is to meet the deadline. That is, not to touch the project all day, and the next day, 16 hours to continuously plow like a slave in the galleys is a common thing. Customers, as a rule, do not care. While working in this mode, you don’t think about the time tracker.
In early 2015, I was offered an interesting remote project and suddenly with payment not for the work done, but with a fixed salary every month.
A couple of months after the start of work, it became obvious that my usual approach did not work well. When you have a deadline in front of you, and the fact of payment is tied to the delivery of work - additional motivation is not needed, especially since the violation of the terms can result in a solid penalty. In the case of a fixed payment, the situation is different. Realizing this, I realized that I work inefficiently and my employer is unlikely to be satisfied if I continue to work at the same pace.
')
At the end of March, an article entitled “ Warden for a freelancer” was published on Habré : choosing a time tracking system This article ideally coincided with my reflections on improving efficiency. It is mainly devoted to web tools and does not fit my tasks, but the basic idea with regard to time seemed to me to be a silver bullet that would allow for the proper distribution of working time and not let the employer down.
To my luck, in the comments to the article, readers shared their experiences using various trackers, and Alexey2005 posted a link to a comparative table of trackers .
The further I plunged into the study of various trackers, the more obvious it became that none of them fit me.
A list of requirements for the tracker was formed:
- No manual timers. In a world where the user constantly switches between different tasks, moves away to "smoke", meets the ICQ mistress, the accuracy of the manual timers tends to 0.
- Open Source only. Consider me paranoid, but I do not want the closed software to give information about my activity on another server. A couple of years ago, I would not even think about it and calmly set myself a proprietary tracker. But the latest trends in the world of surveillance taught me two things:
- If a company has data, it will use it.
- Data will be leaked or will be provided upon request
I really do not want one day to “come” to me with accusations of using any prohibited bitcoin . - Cross platform As a game developer, I mostly work on Windows, but Linux and Mac OS X also accompany a lot of my activity. A time tracker that will track activity in only one of the operating systems will not provide a complete picture.
Automatic cross-platform trackers, there are two and a half pieces. Open Source among them, I have not found one.
Write your
What to do? The choice is obvious - we will write your tracker.
The basic algorithm of operation is simple - the program hangs in the background and, when changing the active window, remembers which application the user switched to. If for some time the user did not press any buttons, did not move the mouse, and the windows did not switch, go to sleep mode, adjusting the last entry accordingly (we take away the time that the user was inactive).
It would be logical to attach to the transition of the PC to the power saving mode (turning off the monitors), but for many this mode is turned off completely or the pause is too large, so you cannot rely on it.
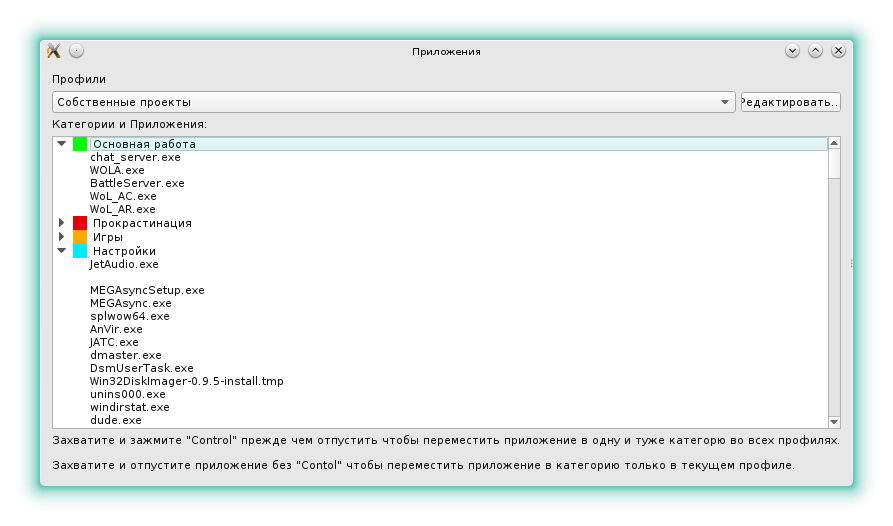
In addition, it is obvious that profiles are needed for time accuracy. Depending on the type of current activity, different applications may fall into different categories. For example, I use notepad ++ both in freelance projects and in my own.
Profiles allow you to assign an application to different categories. Accordingly, if the “own projects” profile is active, then the use time of notepad ++ will be recorded in one category, and if the “freelance” profile is active in another.
External trackers
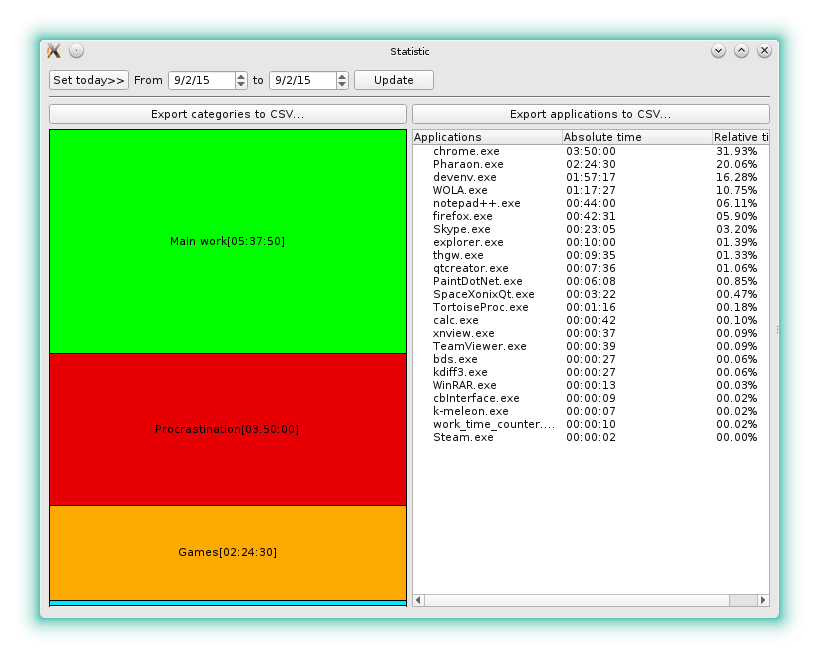
And the first version of the tracker is written and launched. After several days of active testing, it turns out that current automation is not enough. The screenshot in the title shows that Chrome ate 3 hours and 50 minutes and, at the same time, the Procrastination category also took 3 hours and 50 minutes. But in fact, Chrome is also used to access the bugtracker, documentation, stackoverflow. But the first version of the tracker did not know how to distinguish these actions and wrote everything down into one category. One of the temporary solutions is to use Chrome for reading habr / mail / vk, etc., and to conduct all working activity in Frirefox. But the habit was too strong and anyway in the end part of the work was done out of habit in Chrome.
The problem intensified when working in a virtual machine. The tracker, of course, is not able to see by itself: what is going on inside VBox and sees only the activity of VirtualBox.exe. Of course, under virtual machines, only one type of activity was conducted at a time, and the problem could be solved by switching profiles. But initially I really wanted to get away from manual control.
As a result, the solution was born in the form of external trackers.
An external tracker is a program that runs inside an environment inaccessible to the time tracker and transfers information from there. For example, in the case of a virtual machine, this tracker behaves identical to the time tracker, but does not remember what applications are running, and reports the main tracker to the 25855 port via the udp channel.
The message format is pretty simple:
5 char - fixed title. Tytet
1 int - protocol version number. Now 1.
utf8 string (1 int string length and further char array) is the current state of the system.
For example, the virtual machine simply renders the current application as chrome.exe, qtcreator.exe, explorer.exe. It is a bit more complicated with the browser, since the sites are the sea, and the main sites with which the user interacts are given as a state: habrahabr.ru, geektimes.ru, vk.com, gmail.com, google.com, etc. The remaining sites go under the general status: undefined. That is, the main sites are defined in the appropriate categories at the time tracker level, and undefined go into a separate category. For example, I have undefined written in Procrastination, since it is much easier to determine the set of working sites than the millions of garbage that you get when reading another garbage.
1 int - the number of applications to overlap
utf8 - an array of strings with the name of each application overlapped
Overlapped applications are a list of applications that will be replaced if there is fresh (less than 10 seconds) information from the tracker. For example, Chrome tracker covers two applications:
chrome.exe and google-chrome-stable.
Accordingly, if the current status of habrahabr.ru comes from it, then the time tracker during activity in chrome.exe under Windows and Google-chrome-stable in Linux will write to the database not Chrome, but habrahabr.ru.
1 unsigned char - checksum. The checksum is considered to be a simple addition of all the bytes in the packet.
Time tracker in combination with external trackers allows you to get the most correct information about the time spent behind a PC.
In principle, nothing prevents the external tracker from being truly external, for example, an android phone. This will allow for activity outside the PC. But I do not need such functionality, so I did not implement it.
Work with tracker
From the user's point of view, the application is a tray icon, which has a context menu that calls up the necessary windows:

Minor features:
Settings allow you to determine the general details of the application.
Profiles allow you to switch between active profiles without opening the application windows.
And the most important:
Applications - allow you to categorize applications (applications are automatically added to the list during operation) and edit profiles:
Statistics - allows you to tear out the information for the specified date from the database and draw a graph and a table.
On the one hand, the display of statistics is an important part of the time tracker. But I think that the tracker application itself should be just a simple, superficial tool for analyzing data. The main thing is the collection. And you can draw beautiful LibreCalc charts based on exported CSV data.
We should also discuss working with the database.
At first I was afraid that it would grow very quickly and would have to programmatically break it apart.
But the testing process of the first version showed that in half a year of work in three operating systems with a hundred database applications, it would take only 1 megabyte. 20 megabytes in 10 years. Not the size to worry about. But the application code is simplified if you keep the database in one piece.
Since it is meaningless to keep a separate file for each OS from a statistical point of view, for myself I made an exFAT partition of 100 megabytes, where I put the database and now Windows / Linux / Mac OS X work as one of these files. The result - general statistics, available in one place.
Go to Open Source
About 10 months have passed since the first version of the application was written. For myself, I rated the application as very useful. By luck, an article was published in January. Why and why should I write open source code? . And I thought - and not to publish a time tracker on github, because the task of counting time is very relevant, and Open Source solutions are not so many.
And here, acquaintance to github, rewriting of the application taking into account all nuances which are saved up for almost a year of use and the first assembly lies, ready to downloading and creation of fork'ov.
Let me speak
Suddenly, the most difficult thing when publishing an Open Source-project was a poor knowledge of English. At that moment, when it became clear that the project does not make sense without at least minimal documentation and comments - there was a desire not to publish, so as not to shame ... Because my English allows me to watch movies with subtitles, read documentation, understand simple conversational speech ... But writing meaningful, grammatically and orthographically clean sentences - this is too tough for me ...
And there was a choice:
- Nothing to publish at all.
- Limit monosyllabic comments. Perhaps they will not guess that I do not know English.
- Write as much as I consider necessary in bad English.
The first option seemed unacceptable. The project seems to be useful and its publication is important. I think there are a few dozen users for him, so it's a pity to leave unpublished.
The second option does not allow you to fully paint the important points on working with the sources and the application itself. And what is the probability that I will be able to paint everything correctly in short sentences?
As a result, stopped at the third option. In the end, this is not an English exam or a book, but software. Perhaps serious shoals will be corrected by more educated comrades, or maybe the application can function with my crooked comments.
Sources are available here:
github.com/Allexin/TrackYourTime
Source: https://habr.com/ru/post/275447/
All Articles