Own search engine in the distributions of The Pirate Bay
Recently, it has become popular in Habré to do their own search engines for RuTracker. It seemed to me a great reason to move away from the boring enterprise development and try something new.
So, the task: to implement a search engine on the base of The Pirate Bay on the local site and simultaneously try what the frontend development is and what it eats with. The task is complicated by the fact that TPB does not publish its dumps, unlike RuTracker, and it is required to parse their site to get the dumps. As a result of googling and understanding the problem, I decided to use Elasticsearch as a search engine, for which I would write client-side only frontend on AngularJS . To get the data, I decided to write my own TPB site parser and a separate dumper into the index, both on Go. The fact that neither the Elasticsearch, nor the AngularJS I had ever touched before, and that testing them was my real goal, gave a piquancy to the choice.
A brief inspection of the TPB website showed that each torrent has its own page at the address "/ torrent / {id}". Where id is firstly numeric, secondly it is increasing, thirdly, the last id can be viewed on the "/ recent" page and then try all id less than the last. Practice has shown that id does not increase monotonously, and not every id has a valid page with a torrent, which required additional verification and id skipping.
')
Since the parser involves working with the network in several threads, the choice of Go was obvious. To parse the HTML, I used the goquery module.

The parser is quite simple: at the beginning, the "/ recent" is requested and the maximum id is obtained from it:
Then we simply run through all the id values from maximum to zero and feed the resulting numbers to the channel:
As can be seen from the code, on the other side of the channel, a number of gorutins were launched, receiving the torrent id, downloading the corresponding page and processing it:
After processing, the result is sent to the OutputModule, which already saves it in one format or another. I wrote two output modules, in csv and in “almost” json.
Csv format:
Json friendly format is not exactly Json: each line is a separate json object with the same fields as in csv, plus a description of the torrent.
The full dump contains 3828894 torrents and took almost 30 hours to load.
Before you upload data to Elasticsearch, you must configure it.
Since I would like to get a full-text search by the names and descriptions of torrents that are written in several languages, first of all we will create a Unicode friendly analyzer:
Before creating the analyzer, you need to put the ICU plugin , and after creating the analyzer, you need to associate it with the fields in the torrent description:
And now the most important thing is data loading. I also wrote the loader on Go to see how to work with Elasticsearch from Go.
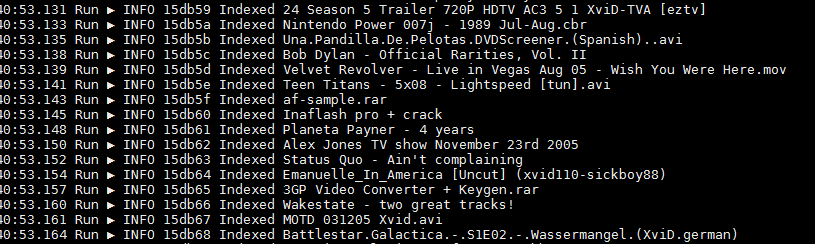
The loader itself is even simpler than the parser: we read the file line by line, translate each line from json to the structure, send the structure to Elastisearch. It would be better to do bulk indexing, but I, frankly, was too lazy. By the way, the most difficult part of writing a bootloader was the search for a screenshot of a fairly long piece of log without porn.
The index itself took the same ~ 6GB and was built in about 2 hours.
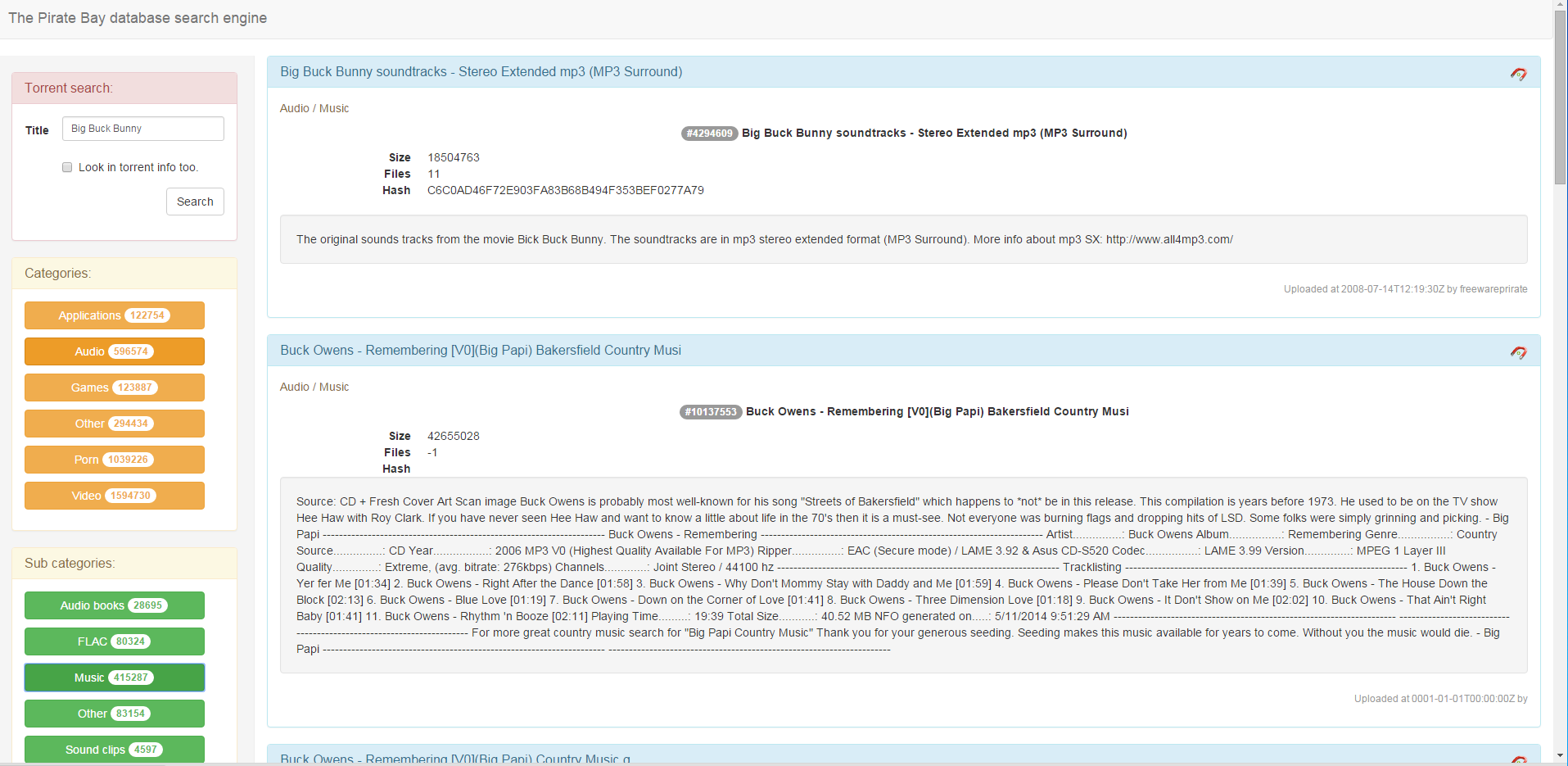
The most interesting part for me. I would like to see all torrents in the database and filter them by categories / subcategories and by name / description of the torrent. Thus, the left filters, right torrents.
I took Bootstrap as the basis for the layout. For most, this seems dupe, but I'm new.
So, on my left hand I have a filter for titles and contents:
Under it, filters by categories and subcategories:
The list of categories is automatically filled when the application is loaded. Using the TermsAggregation request allows you to immediately get a list of categories and the number of torrents in these categories. More strictly speaking - a list of unique values for the Category field and the number of documents for each such value.
When you click on one or more categories, they are selected and loaded a list of their subcategories:
Subcategories can also be selected. When changing the selection of categories / subcategories or filling out a search form, an Elasticsearch query is formed that takes into account everything selected and is sent to Elasticsearch.
Results are displayed on the right:
That's all. Now I have my own search engine on The Pirate Bay, and I learned that you can make a modern website in a couple of hours.
So, the task: to implement a search engine on the base of The Pirate Bay on the local site and simultaneously try what the frontend development is and what it eats with. The task is complicated by the fact that TPB does not publish its dumps, unlike RuTracker, and it is required to parse their site to get the dumps. As a result of googling and understanding the problem, I decided to use Elasticsearch as a search engine, for which I would write client-side only frontend on AngularJS . To get the data, I decided to write my own TPB site parser and a separate dumper into the index, both on Go. The fact that neither the Elasticsearch, nor the AngularJS I had ever touched before, and that testing them was my real goal, gave a piquancy to the choice.
Parser
A brief inspection of the TPB website showed that each torrent has its own page at the address "/ torrent / {id}". Where id is firstly numeric, secondly it is increasing, thirdly, the last id can be viewed on the "/ recent" page and then try all id less than the last. Practice has shown that id does not increase monotonously, and not every id has a valid page with a torrent, which required additional verification and id skipping.
')
Since the parser involves working with the network in several threads, the choice of Go was obvious. To parse the HTML, I used the goquery module.
The parser is quite simple: at the beginning, the "/ recent" is requested and the maximum id is obtained from it:
Get the last id
func getRecentId(topUrl string) int { var url bytes.Buffer url.WriteString(topUrl) url.WriteString("/recent") log.Info("Processing recent torrents page at: %s", url.String()) doc, err := goquery.NewDocument(url.String()) if err != nil { log.Critical("Can't download recent torrents page from TPB: %v", err) return 0 } topTorrent := doc.Find("#searchResult .detName a").First() t, pT := topTorrent.Attr("title") u, pU := topTorrent.Attr("href") if pT && pU { rx, _ := regexp.Compile(`\/torrent\/(\d+)\/.*`) if rx.MatchString(u) { id, err := strconv.Atoi(rx.FindStringSubmatch(u)[1]) if err != nil { log.Critical("Can't retrieve latest torrent id") return 0 } log.Info("The most recent torrent is %s and it's id is %d", t, id) return id } } return 0 } Then we simply run through all the id values from maximum to zero and feed the resulting numbers to the channel:
Boring cycle and a bit of sync.
func (d *Downloader) run() { d.wg.Add(streams) for w := 0; w <= streams; w++ { go d.processPage() } for w := d.initialId; w >= 0; w-- { d.pageId <- w } close(d.pageId) log.Info("Processing complete, waiting for goroutines to finish") d.wg.Wait() d.output.Done() } As can be seen from the code, on the other side of the channel, a number of gorutins were launched, receiving the torrent id, downloading the corresponding page and processing it:
Torrent page handler
func (d *Downloader) processPage() { for id := range d.pageId { var url bytes.Buffer url.WriteString(d.topUrl) url.WriteString("/torrent/") url.WriteString(strconv.Itoa(id)) log.Info("Parsing torrent page at: %s", url.String()) doc, err := goquery.NewDocument(url.String()) if err != nil { log.Warning("Can't download torrent page %s from TPB: %v", url, err) continue } torrentData := doc.Find("#detailsframe") if torrentData.Length() < 1 { log.Warning("Erroneous torrent %d: \"%s\"", id, url.String()) continue } torrent := TorrentEntry{Id: id} torrent.processTitle(torrentData) torrent.processFirstColumn(torrentData) torrent.processSecondColumn(torrentData) torrent.processHash(torrentData) torrent.processMagnet(torrentData) torrent.processInfo(torrentData) d.output.Put(&torrent) log.Info("Processed torrent %d: \"%s\"", id, torrent.Title) } d.wg.Done() } After processing, the result is sent to the OutputModule, which already saves it in one format or another. I wrote two output modules, in csv and in “almost” json.
Csv format:
id , , , , , , , , ,
Json friendly format is not exactly Json: each line is a separate json object with the same fields as in csv, plus a description of the torrent.
The full dump contains 3828894 torrents and took almost 30 hours to load.
Index
Before you upload data to Elasticsearch, you must configure it.
Since I would like to get a full-text search by the names and descriptions of torrents that are written in several languages, first of all we will create a Unicode friendly analyzer:
Unicode analyzer with normalization and other conversions.
{ "index": { "analysis": { "analyzer": { "customHTMLSnowball": { "type": "custom", "char_filter": [ "html_strip" ], "tokenizer": "icu_tokenizer", "filter": [ "icu_normalizer", "icu_folding", "lowercase", "stop", "snowball" ] } } } } } curl -XPUT http://127.0.0.1:9200/tpb -d @tpb-settings.json Before creating the analyzer, you need to put the ICU plugin , and after creating the analyzer, you need to associate it with the fields in the torrent description:
Description of the type of torrent
{ "properties" : { "Id" : { "type" : "long", "index" : "no" }, "Title" : { "type" : "string", "index" : "analyzed", "analyzer" : "customHTMLSnowball" }, "Size" : { "type" : "long", "index" : "no" }, "Files" : { "type" : "long", "index" : "no" }, "Category" : { "type" : "string", "index" : "not_analyzed" }, "Subcategory" : { "type" : "string", "index" : "not_analyzed" }, "By" : { "type" : "string", "index" : "no" }, "Hash" : { "type" : "string", "index" : "not_analyzed" }, "Uploaded" : { "type" : "date", "index" : "no" }, "Magnet" : { "type" : "string", "index" : "no" }, "Info" : { "type" : "string", "index" : "analyzed", "analyzer" : "customHTMLSnowball" } } } curl -XPUT http://127.0.0.1:9200/tpb/_mappings/torrent -d @tpb-mapping.json And now the most important thing is data loading. I also wrote the loader on Go to see how to work with Elasticsearch from Go.
The loader itself is even simpler than the parser: we read the file line by line, translate each line from json to the structure, send the structure to Elastisearch. It would be better to do bulk indexing, but I, frankly, was too lazy. By the way, the most difficult part of writing a bootloader was the search for a screenshot of a fairly long piece of log without porn.
Loader in Elasticsearch
func (i *Indexer) Run() { for i.scaner.Scan() { var t TorrentEntry err := json.Unmarshal(i.scaner.Bytes(), &t) if err != nil { log.Warning("Failed to parse entry %s", i.scaner.Text()) continue } _, err = i.es.Index().Index(i.index).Type("torrent").BodyJson(t).Do() if err != nil { log.Warning("Failed to index torrent entry %s with id %d", t.Title, t.Id) continue } log.Info("Indexed %s", t.Title) } i.file.Close() } The index itself took the same ~ 6GB and was built in about 2 hours.
Frontend
The most interesting part for me. I would like to see all torrents in the database and filter them by categories / subcategories and by name / description of the torrent. Thus, the left filters, right torrents.
I took Bootstrap as the basis for the layout. For most, this seems dupe, but I'm new.
So, on my left hand I have a filter for titles and contents:
Filter by title
<form class="form-horizontal"> <div class="form-group"> <label for="queryInput" class="col-sm-2 control-label">Title</label> <div class="col-sm-10"> <input type="text" class="form-control input-sm" id="queryInput" placeholder="Big Buck Bunny" ng-model="query"> </div> </div> <div class="form-group"> <div class="col-sm-offset-2 col-sm-10"> <div class="checkbox"> <label> <input type="checkbox" ng-model="useInfo"> Look in torrent info too. </label> </div> </div> </div> <div class="form-group text-right"> <div class="col-sm-offset-2 col-sm-10"> <button type="submit" class="btn btn-default" ng-click="searchClick()">Search</button> </div> </div> </form> Under it, filters by categories and subcategories:
Filter by category
<div class="panel panel-warning" ng-cloak ng-show="categories.length >0"> <div class="panel-heading"> <h3 class="panel-title">Categories:</h3> </div> <div class="panel-body"> <div ng-repeat="cat in categories | orderBy: 'key'"> <p class="text-justify"> <button class="btn btn-warning wide_button" ng-class="{'active': cat.active}" ng-click="categoryClick(cat)">{{cat.key}} <span class="badge">{{cat.doc_count}}</span></button> </p> </div> </div> </div> <div class="panel panel-warning" ng-cloak ng-show="SubCategories.length >0 && filterCategories.length >0"> <div class="panel-heading"> <h3 class="panel-title">Sub categories:</h3> </div> <div class="panel-body"> <div ng-repeat="cat in SubCategories | orderBy: 'key'"> <p class="text-justify"> <button class="btn btn-success wide_button" ng-class="{'active': cat.active}" ng-click="subCategoryClick(cat)">{{cat.key}} <span class="badge">{{cat.doc_count}}</span></button> </p> </div> </div> </div> The list of categories is automatically filled when the application is loaded. Using the TermsAggregation request allows you to immediately get a list of categories and the number of torrents in these categories. More strictly speaking - a list of unique values for the Category field and the number of documents for each such value.
Loading categories
client.search({ index: 'tpb', type: 'torrent', body: ejs.Request().agg(ejs.TermsAggregation('categories').field('Category')) }).then(function (resp) { $scope.categories = resp.aggregations.categories.buckets; $scope.errorCategories = null; }).catch(function (err) { $scope.categories = null; $scope.errorCategories = err; // if the err is a NoConnections error, then the client was not able to // connect to elasticsearch. In that case, create a more detailed error // message if (err instanceof esFactory.errors.NoConnections) { $scope.errorCategories = new Error('Unable to connect to elasticsearch.'); } }); When you click on one or more categories, they are selected and loaded a list of their subcategories:
Processing subcategories
$scope.categoryClick = function (category) { /* Mark button */ category.active = !category.active; /* Reload sub categories list */ $scope.filterCategories = []; $scope.categories.forEach(function (item) { if (item.active) { $scope.filterCategories.push(item.key); } }); if ($scope.filterCategories.length > 0) { $scope.loading = true; client.search({ index: 'tpb', type: 'torrent', body: ejs.Request().agg(ejs.FilterAggregation('SubCategoryFilter').filter(ejs.TermsFilter('Category', $scope.filterCategories)).agg(ejs.TermsAggregation('categories').field('Subcategory').size(50))) }).then(function (resp) { $scope.SubCategories = resp.aggregations.SubCategoryFilter.categories.buckets; $scope.errorSubCategories = null; //Restore selection $scope.SubCategories.forEach(function (item) { if ($scope.selectedSubCategories[item.key]) { item.active = true; } }); } ).catch(function (err) { $scope.SubCategories = null; $scope.errorSubCategories = err; // if the err is a NoConnections error, then the client was not able to // connect to elasticsearch. In that case, create a more detailed error // message if (err instanceof esFactory.errors.NoConnections) { $scope.errorSubCategories = new Error('Unable to connect to elasticsearch.'); } }); } else { $scope.selectedSubCategories = {}; $scope.filterSubCategories = []; } $scope.searchClick(); }; Subcategories can also be selected. When changing the selection of categories / subcategories or filling out a search form, an Elasticsearch query is formed that takes into account everything selected and is sent to Elasticsearch.
We form a request to Elasticsearch, depending on the choice on the left.
$scope.buildQuery = function () { var match = null; if ($scope.query) { if ($scope.useInfo) { match = ejs.MultiMatchQuery(['Title', 'Info'], $scope.query); } else { match = ejs.MatchQuery('Title', $scope.query); } } else { match = ejs.MatchAllQuery(); } var filter = null; if ($scope.filterSubCategories.length > 0) { filter = ejs.TermsFilter('Subcategory', $scope.filterSubCategories); } if ($scope.filterCategories.length > 0) { var categoriesFilter = ejs.TermsFilter('Category', $scope.filterCategories); if (filter !== null) { filter = ejs.AndFilter([categoriesFilter, filter]); } else { filter = categoriesFilter; } } var request = ejs.Request(); if (filter !== null) { request = request.query(ejs.FilteredQuery(match, filter)); } else { request = request.query(match); } request = request.from($scope.pageNo*10); return request; }; Results are displayed on the right:
Result template
<div class="panel panel-info" ng-repeat="doc in searchResults"> <div class="panel-heading"> <h3 class="panel-title"> <a href="{{doc._source.Magnet}}">{{doc._source.Title}}</a> <!-- build:[src] img/ --> <a href="{{doc._source.Magnet}}"><img class="magnet_icon" src="assets/dist/img/magnet_link.png"></a> <!-- /build --> </h3> </div> <div class="panel-body"> <p class="text-left text-warning"> {{doc._source.Category}} / {{doc._source.Subcategory}}</p> <p class="text-center"><span class="badge">#{{doc._source.Id}}</span> <b>{{doc._source.Title}}</b> </p> <dl class="dl-horizontal"> <dt>Size</dt> <dd>{{doc._source.Size}}</dd> <dt>Files</dt> <dd>{{doc._source.Files}}</dd> <dt>Hash</dt> <dd>{{doc._source.Hash}}</dd> </dl> <div class="well" ng-bind-html="doc._source.Info"></div> <p class="text-right text-muted"> <small>Uploaded at {{doc._source.Uploaded}} by {{doc._source.By}}</small> </p> </div> </div> That's all. Now I have my own search engine on The Pirate Bay, and I learned that you can make a modern website in a couple of hours.
- tpb-parser - The source code for The Pirate Bay parser
- estorrent - Source code of frontend and indexer
- TPB dump for those who want to make something new based on it (~ 1.2GB archive)
- Virtual machine image with Elasticsearch and web application (~ 6GB)
Source: https://habr.com/ru/post/275339/
All Articles