Algorithmic Trading: Finding an Efficient Data Processing Method Using FPGA
A group of researchers from the University of Toronto has published a paper on the use of FPGA to increase the efficiency of event processing in algorithmic trading on the exchange. We present to you the highlights of this document.
Introduction
Currently, high-frequency trading dominates the financial markets (according to various sources, the proportion of transactions made using algorithms is now about 70%). Accordingly, the importance of optimizing the processes of order execution and processing of transactions and events occurring in the market is constantly growing - the competition is so strong that microseconds decide everything.
Successful strategies can bring profits to their creators, playing even on microscopic differences in the prices of related assets on different stock exchanges - for example, if a certain company shares are traded on the New York Stock Exchange at $ 40.05, and in Toronto - at $ 40.04 , the algorithm has to buy into a stock in Canada and sell it in the USA. Every millisecond won here can result in millions of profits on the horizon of the year.
')
Algorithmic trading can be modeled as an event processing platform in which financial news and market data are treated as events, such as [stock = ABX, TSXask = 40.04, NYSEask = 40.05], and investment strategies are formulated by financial institutions or investors in the form of subscriptions: [ stock = ABX, TSXask 6 = NYSEask] or [stock = ABX, TSXask ≤ 40.04].
Thus, a scalable event processing platform must be able to efficiently find all investment strategies (subscriptions) that correspond to incoming events — and there may be millions of such events per second.
Why use FPGA
The most resource-intensive aspect of the event handling process is matching. The algorithm accepts an input event (a flow of quotations, market events) and a set of subscriptions (that is, investment strategies) and returns subscriptions for which matches are found with market events.
Dealing with data processing efficiency requirements in networks with ever-increasing throughput is not a trivial task. Simultaneously with the increase in throughput, the volumes of processed data are growing. At the same time, building not too expensive systems to work in such a situation is also not easy due to the fact that the existing technologies for creating processors are approaching their limit and their performance is not growing as fast as it was before.
Popular servers often fail to handle market data at the right speed. As a result, traders and financial institutions are faced with the need to improve the performance of their infrastructure. You can speed up the work of algorithms not only by purchasing additional servers, but also using FPGA.
Soft-processing approach
The hardware reconfiguration capability allows FPGAs to use soft microprocessors , which have several important advantages. They are easier to program (this means that you can use C instead of Verilog, which requires specialized knowledge), they can be ported to different FPGAs, they can be customized, in addition, they can be used to interact with other parts of the system.
In the current example, the FPGA is located on the NetFPGA network card and communicates with the host machine via DMA on the PCI interface. The FPGA has programmable pins that provide a direct connection to the memory and network interfaces — in a normal server, you can interact with them only through the interface of the network card.
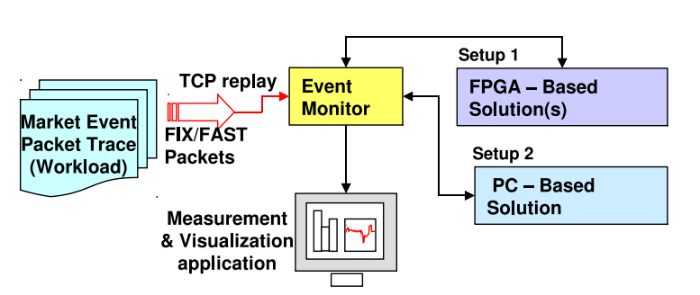
For the experiments, a solution was created based on Soft-microprocessors, working on NetFPGA, as well as the basic version for working with PCs - both implementations used the same match strategy.
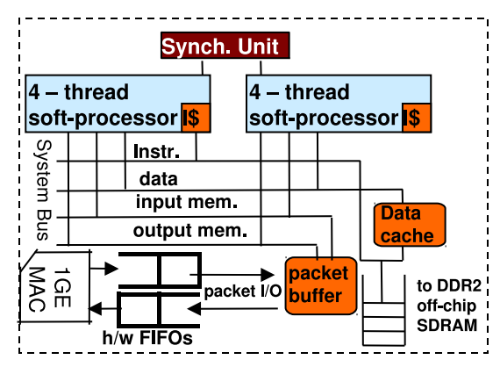
Soft microprocessor implementation
To increase the bandwidth of the event-handling application, NetThreads was selected, which has two single-task, five-step, multi-threaded processors.
In a single core, instructions from the four “iron” threads are processed in a manner similar to round-robin — this allows you to perform calculations even if you need to wait for memory. Such a system is well suited for handling events: Soft-processors do not suffer from overloads of the operating system, which ordinary computers are subject to, they can receive and process packets in parallel, with minimal resources, and they have access to a higher resolution timer (much larger than on a PC) for processing timeouts and scheduling operations.
Due to the absence of the operating system in NetThreads, the packets are considered as memory buffers of characters and are available immediately after their full receipt by the processor (skipping step with copying to the application in user space).
Only "iron"
The second approach used meant the creation of an exclusively hardware solution: all the necessary steps are carried out by “custom” iron components, including they are used to parse market events and match them with the appropriate strategies. This method allows you to achieve the greatest performance, but it is also the most difficult.
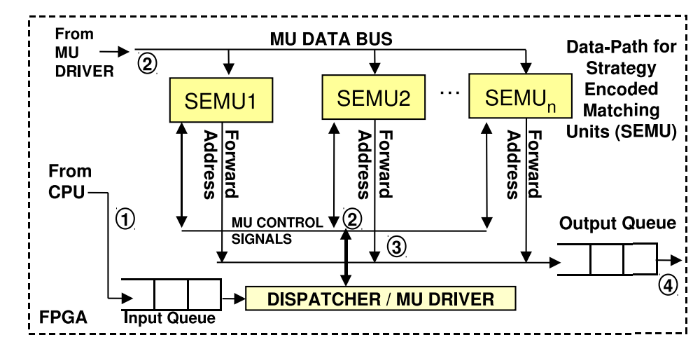
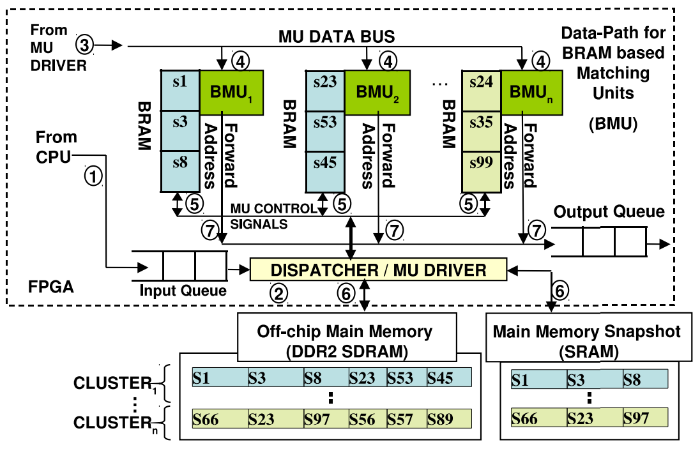
Hybrid approach
Due to the complexity of using only hardware to support dynamic strategies and event formats, a hybrid approach can be used, combining the advantages of the two schemes described above. Since FPGAs are usually programmed in low-level languages, it is rather difficult to maintain the work of the communication protocols created in this way.
This problem can be avoided by running a soft microprocessor to implement packet processing using software. After parsing incoming packets with market data, a soft microprocessor transfers them to the hardware.
Conclusion
As a result of various approaches - using the PC as a base case, a soft approach, only hardware and a hybrid method - researchers were able to collect data on the effectiveness of each of the presented methods for handling market events.
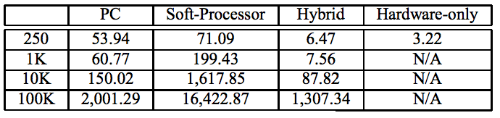
The load during the experiments changed from 250 to 100 thousand analyzed investment strategies. As a result, the use of a hybrid approach made it possible to overtake other methods by two or more orders of magnitude (the results are presented in the table above).
Source: https://habr.com/ru/post/275169/
All Articles