Setting the problem of computer vision

For the last eight years, I have been actively engaged in tasks related to image recognition, computer vision, and machine learning. It turned out to accumulate a large enough baggage of experience and projects (something of their own, something in the rank of full-time programmer, something to order). In addition, since I wrote a couple of articles on Habré, readers often contact me, asking for help with their task, to advise something. So quite often I come across completely unpredictable applications of CV algorithms.
But, damn it, in 90% of cases I see the same system error. Every now and again. Over the past 5 years I have already explained it to dozens of people. Yes that there, periodically and I make it myself ...
In 99% of the tasks of computer vision, the idea of the problem that you formulated in your head, and especially the solution that you set out, has nothing to do with reality. There will always be situations about which you could not even think. The only way to formulate a task is to collect a database of examples and work with it, taking into account both the ideal and the worst situations. The wider the base, the more accurate the task. Without a base to talk about the task impossible.
Trivial thought. But everyone is mistaken. Everything. In the article I will give several examples of such situations. When the task is set poorly when good. And what pitfalls await you in the formation of TK for computer vision systems.
')
First examples
The bad
One of the most frequent ideas that people ask me about (even offered to take up) is label recognition in stores: “ Good afternoon! I came up with a cool startup: a person comes to the store, removes the price tag, we find the product, the price, and look at which store the cheapest! I have already done everything, but only the recognition module remains! ". Over the past two years, I have been written about five times with similar offers ...
And really! In the mind of a person who rarely encounters recognition tasks, there is a clear picture: “Recognizing a line of text on a label is to spit it out!”. After all, there are ABBYY , which recognize the text by pages, there is Smart Engines ( 1 , 2 ), which have cards with a bunch of numbers recognized, and even labels! The problem has long been solved! What is the difference, Ikea or Auchan? All labels are similar, a single module will cope.
Usually after such a thing you want to say to a person: “ Go to three different networks, take ten frames and look at them .” What you can usually get the answer: " What I did not see there! Yesterday I was at the Crossroads and looked at them! ".
We'll see?








These are not the worst examples (photos are clickable). In all the examples here a person can read / think out the information. And the car?
• Photos are often blurred, the text is blurred and merged. Often the letters are written so close to each other that segmentation is almost impossible.
• There are a lot of artifacts along the edges of the price tags, often the letters are cut off, or there is a strip along them.
• If shooting with a flash - there will be highlights, often completely overlapping text.
• On the same price list there are often 2-3 prices written in different fonts (and often price tags can be fixed to each other).
• The font varies even within the same distribution network.
• The format of price tags varies even within the same distribution network.
Some particularly hard-nosed ones continue to insist: “You have invented everything! There is a post at Smart Engines, where everything works and price tags are recognized! ”
And really! A remarkable example of a correctly set task: a rectangle of a given size is searched for, on a red background, the font is the same. Having defined the boundaries of the rectangle, you can roughly segment the code. Heuristics are, but minimal: link three blocks in the picture, arranged in a known order.
Yes: there will be overshoots, there will be highlights, corners can be bent, someone draws his autograph on the price tag, and someone always gives the camera unsharp frames. But when you know the position of each digit, everything else is not so important. And in most cases, everything will work fine.
NB I do not say that the problem of recognizing price tags is not solvable in the general case. Solved. And today's progress makes this decision closer and closer. Google already recognizes house numbers. And ABBYY is customized for any predefined text format. But the solution of such a problem is on the border of modern technologies, the solution will be imperfect, or it will require a lot of time and money for development. Of course, you can make price recognition on price tags (without text) and such a system will work well on some price tags. And sometimes you can read the barcode (from the above price tags open format barcode written on one). Often there are ways to cut corners and simplify problem statement.
Distract from the labels
You will say that these are examples from the air and that this does not happen? .. I will give an example which has even been published on Habré: habrahabr.ru/post/265209 .
Before reading further, try to understand why the method will not work.
- For those who are too lazy to read. The author suggests to put a stamp on a tree from three points. And believes that the intersection of lines between points with annual rings will uniquely mark and classify the log from the camera.
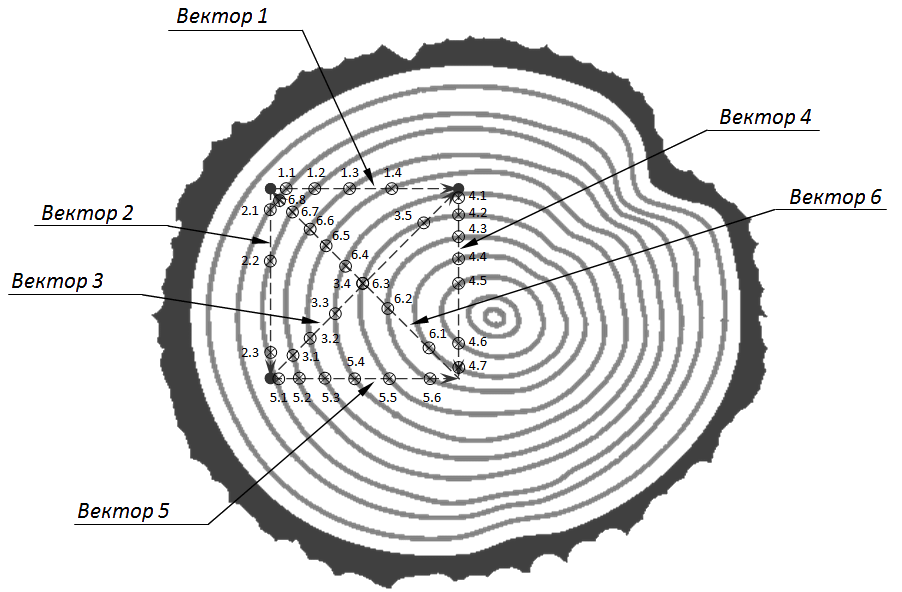
Here is a beautiful picture, he leads. The method is immediately clear and understandable. Is not it?
- The author himself appealed to me about a week before publication with the question whether it would all work. I said that I most likely would not, cited several examples, and also said how to modify the algorithm to make it work. But he wrote an article in the key that this is a working method. And no one in the top ten comments objected. Only two dislayka ... (Hell, I confess, one of them is me).
Let's try to figure it out. First, what does the “annual ring” look like? Let’s ask Yandex to give us a log:

Perfect. Beautiful rings! Just like in the picture above. Wait ... And what is this?

Also rings ... And what if we have a camera a little bit missed with sharpness?

Pancake. Half the rings are gone. And if we evening and rose ISO?

Again…
Well, maybe not so bad? We will come up with a criterion to select only sufficiently large annual bands, we will generate several variants for each tree. OK?


No, there are still cracks that can change the geometry and situations where there are almost no bands at all. And these are the first 20 perfect pictures from the issue of Yandex. The conclusion suggests itself in five minutes. But there is a cool idea! Why look at pictures from the search? ..
The task itself, in my opinion, is more likely solved. If you take the mark as anchor points and compare the same methods that compare eyes . But, again, until you test the database for at least a couple of hundred examples, you will never know if the work can be successfully completed. But for some reason the author of the article did not like this sentence ... It's a pity!
These are the two most meaningful and representative, in my opinion, examples. By them you can understand why you need to abstract from the idea and watch real shots.
A few more examples that I met, but in a nutshell. In all these examples, people did not have a single photo at the time when they started asking about the feasibility of the task:
1) Recognition of numbers by marathoners on T-shirts by video stream (picture from Yandyks)

Chy . While preparing the article came across this . A very good example that shows all potential problems. These are different fonts, this is an unstable background with shadows, these are blur and jammed corners. And the most important thing. The customer offers an idealized base . Shot on a good camera on a sunny day. Try to see the numbers of athletes on T-shirts by searching in the search for yandyks.
Khy.Hy A couple of hours before publication, the order author suddenly came to me with a proposal to take up work, which I refused :) Still, this is karma, add it to the article.
2) Recognize text on phone screen photos
3) And, my favorite example. Mail to:
" we need a program in the commercial sector to recognize images.
The algorithm works. The program operator sets images of the object (s) from several angles, etc.
then when this or as close as possible image of the object appears, the program performs the required / specified action.
Of course I can not yet tell the details. "(spelling, punctuation preserved)
Good ones
But it is not all that bad! The situation when the task is put ideally, meets often. My favorite: “You need software to automatically count the moose in the photo.
An example of a photo with moose send. "


Both photos are clickable.
I still regret that I didn’t grow up with this task. At first he defended his candidate’s and was busy, and then the customer somehow lost his enthusiasm (or found other performers).
In the formulation there is not the slightest interpretation of the decision. Only two things: “what to do”, “input data”. Lots of input. Everything.
Thought - conclusion
The only way to set a task is to build a base and determine the methodology for working on this base. What do you want to get? What are the limits of applicability of the algorithm? Without this, you will not only be unable to approach the task, you will not be able to pass it. Without a database, the customer will always be able to say “Such a case does not work for you. But this is a critical situation! Without him, I will not accept work. ”
How to form a base
Probably all this was a prequel to the article. This article starts here. The idea that in any task CV and ML need a base for testing is obvious. But how to get such a base? In my memory, three or four times the first dialed base went down into the toilet. Sometimes the second. Because it was unrepresentative. What is the difficulty?
It is necessary to understand that "collecting the base" = "problem statement". The assembled base should:
1. To reflect the problematic of the problem;
2. Reflect the conditions in which the task will be solved;
3. Formulate the task as such;
4. To lead the customer and the performer to a consensus on what has been done.
Season
A couple of years ago, my friend and I decided to make a system that could work on cell phones and recognize car numbers. Something even happened, and we wrote a series of articles about it (http://habrahabr.ru/company/recognitor/). At that time, we were very sophisticated in CV systems. They knew that it was necessary to assemble such a base so that it was bad. To look at her and immediately understand all the problems. We have collected such a database:




They made an algorithm, and it even worked well. Gave 80-85% recognition of the selected numbers.
Well, yes ... Only in summer, when all the rooms became clean and the system’s good accuracy slipped by 5 percent ...
Biometrics
Quite a lot in our lives, we worked with biometrics ( 1 , 2 , 3 ). And, it seems, they attacked all possible rakes while collecting biometric bases.
• The base must be assembled in different rooms. When the device to collect the database is only from the developers - sooner or later it will become clear that it is tied to the next lamp.
• In biometric databases you need to have 5-10 pictures for each person. And these 5-10 shots should be taken on different days, at different times of the day. Approaching a biometric scanner several times in a row, a person is scanned in the same way. Approaching on different days - in different ways. Some biometric characteristics may vary slightly during the day.
• The base collected from developers is unrepresentative. They are subconsciously read so that everything works ...
• Do you have a new scanner model? Are you sure that it works with the old base?
Here are the eyes collected from different scanners. Different fields of work, different highlights, different shadows, different spatial resolutions, etc.

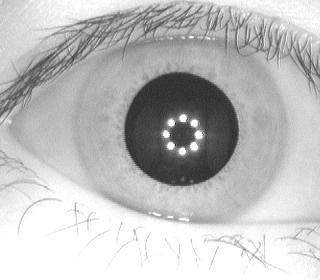
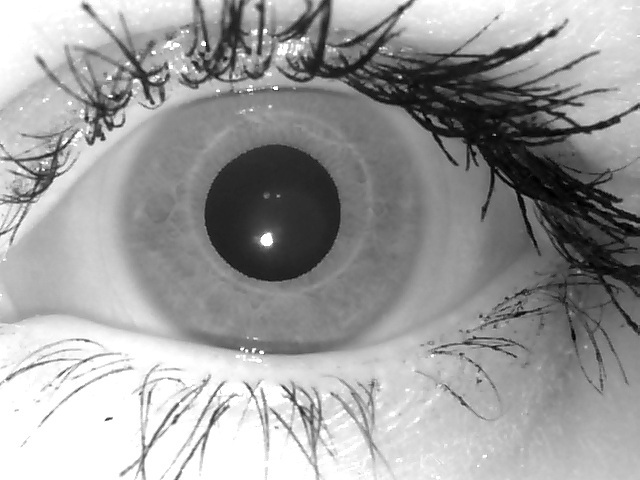
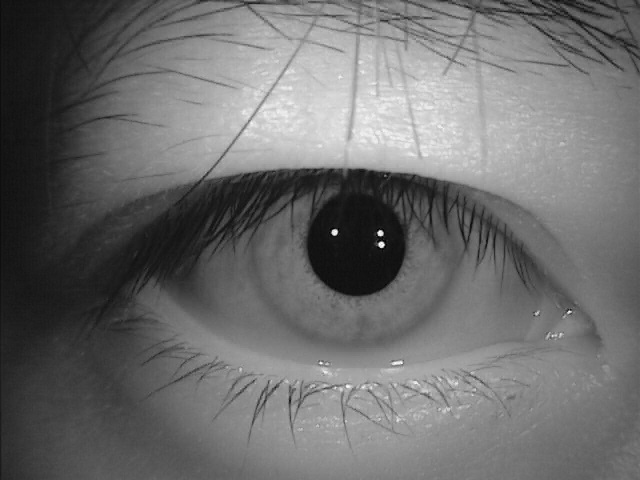
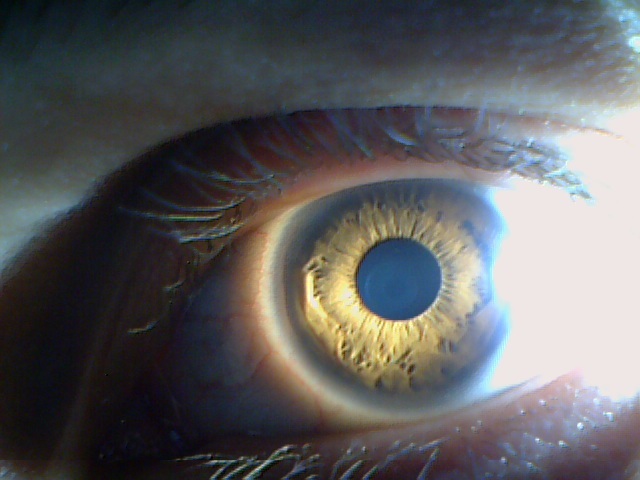
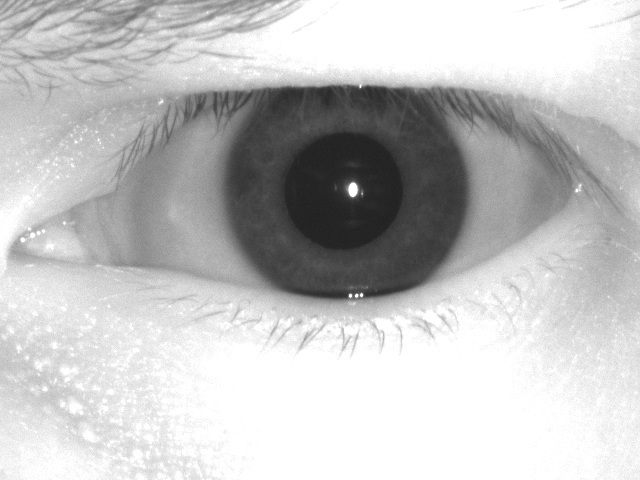
Base for neural networks and learning algorithms
If you use some kind of learning algorithm in your code, write to them. You need to form a base for learning with his account. Suppose there are two very different fonts in your recognition task. The first occurs in 90% of cases, the second in 10%. If you cut these two fonts in this proportion and learn to use them as a single classifier, then the letters of the first font will be recognized with a high probability, and the letters of the second will not. For the neural network / SVM will find a local minimum not where 97% of the first font and 97% of the second is recognized, and where 99% of the first font and 0% of the second are recognized. Your database should have enough examples of each font, so that training does not go to another minimum.
How to create a base when working with a real customer
One of the non-trivial problems when collecting the base is who should do this. The customer or performer. First, I will give a few sad examples from life.
I hire you to solve my problem!
That is the phrase I heard once. And damn, you can not argue. But only the base would have to be assembled at the factory, where no one would let us go. And even more so, would not let us mount equipment. Those data that the customer gave were useless: an object a few pixels in size, a very noisy camera with impulse noise, which periodically twitches, from the strength of twenty test images. On proposals to put a better camera, choose a better angle for shooting, make a base of at least a couple of hundred examples, the customer answered with a phrase from the title.
We do not have time to do it!
One day, the director of a very large company (about 100 people + offices in many countries of the world) offered to talk. In the product produced by this company, part of the functionality was implemented with very old and very simple algorithms. The director told us that he had long dreamed of modifying this functionality in modern algorithms. Even hired two different development teams. But did not grow together. One team, according to him, too theorized, and the second did not know any theory and did trivialism. We decided to try.
The next day we were given access to a huge array of raw information. Much more than I could see in a year. After spending a couple of days analyzing information, we were wary and asked: “What exactly do you need from new algorithms?”. We were called a dozen two situations when the current algorithms do not work. But for a couple of days, I saw only one or two of these situations. After reviewing another packet of data I could find another one. To the question: “What situations worry your customers in the first place?”, Neither the director nor his chief engineers could give an answer. They did not have such statistics.
We investigated the question and proposed a solution algorithm that could automatically collect all possible situations. But we needed to help with two things. First, to deploy information processing on the servers of the company itself (we did not have enough computing power or a sufficient channel to the place where the raw data was stored). This would have left the week of the work of the company's administrator. And secondly, the representative of the company had to classify the collected information by importance and by how it needs to be processed (this is three more days). By this time, we have already spent two or three weeks of our time to analyze the data, study articles on the subject, and write programs for collecting information (there was no agreement signed at this time, everything was done on a voluntary basis).
To which we were told: “We cannot divert anyone to this task. Understand yourself. On what we have bowed and retired.
The customer gives the base
There was another case. This time the customer is smaller. And the system, which deals with the customer scattered throughout the country. But the customer understands that we will not assemble a base. And she tries with all her might to assemble a base. Collects. Very large and diverse. And even assures that the base is representative. Getting started. Almost finish the algorithm. Before delivery, it turns out that the algorithm works on the assembled base. And we satisfy the conditions of the contract. But the base was unrepresentative. There are no 2/3 situations in it. And those situations that are - are represented disproportionately. And on real data, the system works much worse.
So it turns out. We tried our best. All that was promised was done, although the task turned out to be much more complicated than planned. The customer tried. Spent a lot of time collecting base.
But the final result is bad. I had to invent something on the go, at least somehow plug holes ...
So who should form the base?
The problem is that very often computer vision tasks occur in complex systems. Systems that have been made for decades by many people. And to understand such a system is often much longer than solving the problem itself. And the customer wants to start the development tomorrow. And naturally, the proposal to pay for the preparation of TZ and the base amount is 2 times the cost of the task, increase the time by 3 times, give admission to their systems and algorithms, select an employee who will show and tell everything, causes him bewilderment.
In my opinion, the solution of any computer vision problem requires a constant dialogue between the customer and the performer, as well as the customer’s desire to formulate the task. The contractor does not see all the nuances of the customer's business, does not know the system from the inside. I have never seen an approach: “here is money for you, make me a decision tomorrow” worked. The decision was something. But did it work as it should?
I myself as a fire trying to shy away from such contracts. Whether I work myself, or in some company that took the order for development.
In general, the situation can be represented as follows: suppose you want to arrange your wedding. You can:
• Design and organize everything yourself from beginning to end. In essence, this option is “solve the problem yourself”.
• Think everything from start to finish. Write all the scripts. And hire performers for each role. Tamada in order for guests not to be bored, a restaurant, so that everyone would cook and cook. Write the main canvas for the toastmaster, the menu for the restaurant. This option is a dialogue. Provide the performer with data, paint everything that is required.
• You can think in large blocks without going into details. Hire a toastmaster, let him do what he does. Do not agree on the restaurant menu. Order a fashion designer selection of dresses, hairstyles, image. The headache is at least, but when the strip competitions begin, you can understand that something was done wrong. It’s far from the fact that by formulating a task in the “recognize me character” style, the performer and the customer will understand the same thing.
• And you can order everything to a wedding agency. It's expensive to think at all. But no one knows what happens. Option - "make me well." Most likely, the quality will depend on the cost. But not necessarily
Are there any tasks where the base is not needed
There is. First, in tasks where the base is too difficult. For example, the development of a robot that analyzes video, and makes decisions on it. We need some kind of test bench. You can make the base for some separate functions. But to make a base for a full cycle of actions is often impossible. Secondly, when there is research work. For example, there is a development not only of algorithms, but also devices with which the base will be gathered. Every day a new device, new options. When the algorithm changes three times a day. In such conditions, the base is useless. You can create some local database, changing every day. But something global is meaningless.
Thirdly, these are tasks where a model can be made. Modeling is generally a very big and complex topic. If you can make a good model cheap, then of course you need to do it. You want to recognize the text, where there is only one font - the easiest way to create a simulation algorithm ( an example of such a task ).
Scientific approach
But what about scientists? Do they collect a separate base for each job?
Usually not. On the Internet you can find a lot of open databases. Usually universal, for some classic examples. For example, there are several sites with databases for biometrics (the most famous ). There are sites with databases for testing various learning algorithms ( 1 2 3 ).
The problem of all these bases is often that they are of little use and unrepresentative. Take, for example, the legendary MNIST — a database of handwritten numbers of numbers:

All machine recognition algorithms are tested on it. Everything would be fine, but ... Top algorithms long ago have accuracy of the form of 99.5%, 99.6%, 99.6351%, etc. 30-40 pictures that are well known to everyone are not recognized. Half of them, even a person can not be recognized. With tricky settings you can slightly improve the accuracy and make + 0.1%. But it is clear that it doesn’t have anything to do with the actual data, and there’s nothing more to a qualitative assessment of the algorithm.
Often it turns out that the algorithm written in such databases will work only in those conditions and with the parameters for which the entire base is assembled.
Give your examples!
On Habré there are a lot of people who are engaged in image processing and probably have a lot of experience in this (I read some of them while still a student): SmartEngines sergeypid BelBES mephistopheies rocknrollnerd YUVladimir Nordavind BigObfuscator Vasyutka
(Forgive me if anyone mentioned the wrong case, but most of the noted ones wrote cool articles on CV and ML). Surely you have your own thoughts on how to make the formulation of the problem perfect and build a cool base. Share it? Or can you criticize what is written as a heresy from beginning to end? :)
Source: https://habr.com/ru/post/274725/
All Articles