Universal Memcomputing Machines as an alternative to Turing Machine
This article can be considered a free translation (although rather an attempt to understand) of this article . And yes, it is written more for mathematicians than for a wide audience.
A small spoiler: in the beginning it seemed to me some kind of magic, but then I understood the catch ...
Nowadays, the Turing machine (hereinafter MT) is the universal definition of the concept of an algorithm, and hence the universal definition of a “problem solver”. There are many other models of the algorithm - lambda calculus, Markov algorithms, etc., but all of them are mathematically equivalent to MT, so even though they are interesting, they do not significantly change anything in the theoretical world.
')
Generally speaking, there are other models - Nondeterministic Turing Machine, Quantum Turing Machines. However, they are (for the time being) only abstract models that cannot be implemented in practice.
Six months ago, an interesting article was published in Science Advances with a computational model that differs significantly from MT and which it is quite possible to put into practice (the article itself was about how they counted the SSP task on real hardware).
And yes. The most interesting thing about this model is that, according to the authors, it is possible to solve (some) tasks from the NP class of complete problems in the time and memory polynomial.
Probably you should immediately stipulate that this result does not mean a solution to the problem. . After all, the statement of this problem does not “solve the
. After all, the statement of this problem does not “solve the  behind
behind  time ”, and is it possible to simulate a non-deterministic Turing machine on a regular Turing machine in the time polynomial. Since there is a completely different model of calculations, it is impossible to speak about classical classes of complexity.
time ”, and is it possible to simulate a non-deterministic Turing machine on a regular Turing machine in the time polynomial. Since there is a completely different model of calculations, it is impossible to speak about classical classes of complexity.
I myself am skeptical at the moment about the possibility of building this machine in the gland (why I will tell below), but the model itself seemed to me quite interesting for analysis and, quite possibly, it will find application in other areas of science.
What is a computer (more precisely, the most popular implementation of MT - Arch. Von Neumann) today? Some kind of I / O interface, memory and CPU, which is physically separated from them. In the CPU, there are both the module that controls the progress of the calculations and the blocks that perform these calculations.
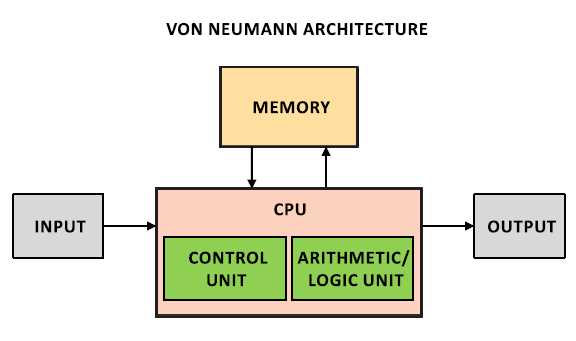
The physical separation of the CPU means that we have to spend a lot of time transferring data. Actually for this purpose various levels of cash memory were invented. However, cache memory, of course, makes life easier, but does not solve all data transfer problems.
The proposed data model was inspired by the work of the brain (the phrase is rather trite, but it is quite suitable here). Its essence is that the calculations take place not in a separate device, where you need to transfer data, but directly in memory. The order of calculations is controlled by an external device (Control Unit).
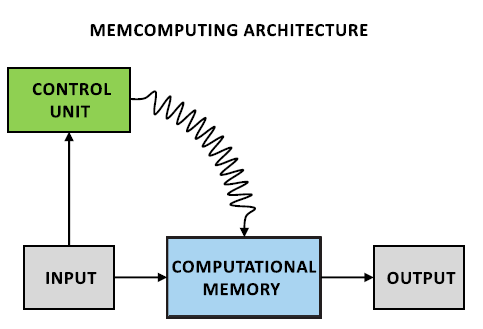
This model of computing, called Universal Memcomputing Machines (I did not begin to translate this term. Then I will use the abbreviation UMM).
In this article, we first recall how MT is formally defined, then we will look at the definition of UMM, look at an example of how to set an algorithm for solving a problem on a UMM, consider several properties, including the most important information overhead.
I think you all remember what a Turing machine is (otherwise there is no point in reading this article). Tape, carriage, all things. Let's just remember how it is defined formally.
Turing machine is a tuple
%2C%0A)
Where - many possible states,
- many possible states,
 - many possible ribbon symbols
- many possible ribbon symbols
 - empty character
- empty character
 - many incoming characters
- many incoming characters
 - initial state
- initial state
 - a set of final states
- a set of final states
 where
where  accordingly, the shift to the left, without offset, offset to the right. I.e
accordingly, the shift to the left, without offset, offset to the right. I.e  - our transition table.
- our transition table.
To begin with, let's define our UMM memory cell - memeprocessor.
The memprocessor is defined as a 4-tuple.) where
where  - the state of the memory processor,
- the state of the memory processor,  - vector of internal variables.
- vector of internal variables.  - vector of "external" variables, that is, variables, connecting different meprocessors. In other words, if
- vector of "external" variables, that is, variables, connecting different meprocessors. In other words, if  and
and  - vectors of external variables of two memprocessors, then two memprocessors are connected
- vectors of external variables of two memprocessors, then two memprocessors are connected 
 . Also, if the memprocessor is not connected to anyone, then
. Also, if the memprocessor is not connected to anyone, then ) , that is, determined only by the internal state.
, that is, determined only by the internal state.
And finally![\ sigma [x, y, z] = (x ', y')](http://tex.s2cms.ru/svg/%5Csigma%5Bx%2Cy%2Cz%5D%20%3D%20(x'%2C%20y')) , i.e
, i.e  - the operator of the new state.
- the operator of the new state.
I want to remind you that the memory processor is not the processor that we usually imagine in our head. It is rather a memory cell that has the function of obtaining a new state (programmable).
Now we introduce the formal definition of UMM. UMM is a model of a computer formed of interconnected meprocessors (which, generally speaking, can be both digital and analog).
%2C%0A)
Where - many possible states of the meprocessor
- many possible states of the meprocessor
 - A set of pointers to the memprocessor (used in to select the desired memory processors)
- A set of pointers to the memprocessor (used in to select the desired memory processors)
 - many indexes
- many indexes  (number of function used )
(number of function used )
- the initial state of the memprocessor
 - initial set of pointers
- initial set of pointers
 - initial operator index ($ \ alpha $)
- initial operator index ($ \ alpha $)
 - a set of final states
- a set of final states

Where - the number of memprocessors used as input by the function
- the number of memprocessors used as input by the function  ,
,  - the number of memory processors used as an exit function .
- the number of memory processors used as an exit function .
By analogy with the Turing machine, as you might have guessed, - transition functions, an analogue of the state table. If you look at an example, then let  - pointers to memprocessors,
- pointers to memprocessors,  ,
, ) - the state vector of these memprocessors, and
- the state vector of these memprocessors, and  - the index of the next command, then
- the index of the next command, then
![\ delta _ {\ alpha} [x (p _ {\ alpha})] = (x '({p'} _ {\ alpha}), \ beta, p _ {\ beta})](http://tex.s2cms.ru/svg/%20%5Cdelta_%7B%5Calpha%7D%20%5Bx(p_%7B%5Calpha%7D)%5D%20%3D%20(x'(%7Bp'%7D_%7B%5Calpha%7D)%2C%20%5Cbeta%2C%20p_%7B%5Cbeta%7D)%20)
Generally speaking, discarding formalism, the main difference between UMM and MT is that in UMM, affecting a single memory cell (that is, a memory processor), you automatically influence its environment, without additional calls from the Control Unit.
Note 2 properties of the UMM, directly arising from its definition.
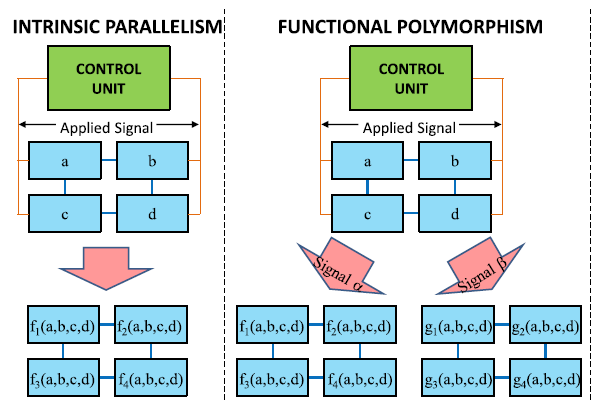
Generally speaking, it is not so difficult to modify the Turing machine so that it also has these properties, but the authors insist.
And a few more comments on the definition. The UMM, unlike the Turing machine, can have an infinite state space with a finite number of meprocessors (due to the fact that they can be analog).
By the way, UMM can be considered as a generalization of neural networks.
Evidence.
In other words, we need to show that the Turing machine is a special case of the UMM. (whether the opposite is true is not proven, and if the authors of the article are right, then this will be equivalent to proving )
Let in the definition of UMM, . We will designate one of the memory processors as
. We will designate one of the memory processors as  , the rest (possibly infinite qty) as
, the rest (possibly infinite qty) as  . Next we define the pointer
. Next we define the pointer  . we will use as a designation of the state
. we will use as a designation of the state  , as a ribbon symbol ( ).
, as a ribbon symbol ( ).
 we will consist of a single function
we will consist of a single function ![\ delta [x (p)] = (x '(p), p')](http://tex.s2cms.ru/svg/%5Cdelta%20%5B%20x(p)%20%5D%20%3D%20(x'(p)%2C%20p')) (omit
(omit  , since there is only one function). New condition
, since there is only one function). New condition  determined by the transition table MT,
determined by the transition table MT, ) - there will be a new state,
- there will be a new state, ) - new ribbon symbol. New pointer
- new ribbon symbol. New pointer  ,
,  if there is no carriage transition,
if there is no carriage transition,  if we move the carriage to the right,
if we move the carriage to the right,  if left. As a result, when writing to initial state and the starting character from , with
if left. As a result, when writing to initial state and the starting character from , with  UTM simulates a universal Turing machine.
UTM simulates a universal Turing machine.
The theorem is proved.
Let's look at an example of how to solve problems on the UMM (for now just to get acquainted with the model). Take the subset sum problem ( SSP ) problem.
Let there be many and given a number
and given a number  . Is there a subset
. Is there a subset  whose sum of elements is equal .
whose sum of elements is equal .
Let the memprocessors in our UMM be arranged in a matrix form (see the figure). We define three operations.
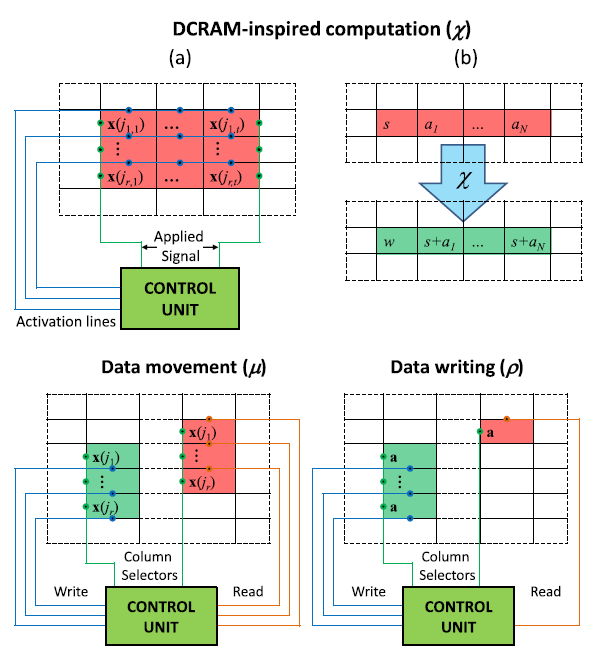
By combining these three operations, we can get the transition function .
.
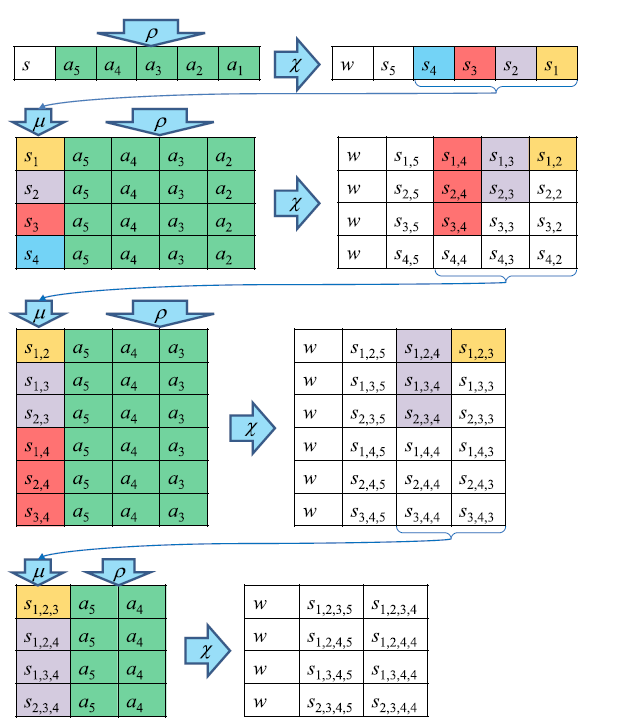
In the first step of the algorithm, we get the sum of all subsets of length on the second step of the subsets
on the second step of the subsets  and so on. As soon as we found the desired number (it will be in the left column), we found the answer. Each step is performed in one function call. therefore the algorithm works steps.
and so on. As soon as we found the desired number (it will be in the left column), we found the answer. Each step is performed in one function call. therefore the algorithm works steps.
Now let's calculate how many processors we need to perform these operations. At iteration k we need) meprotsessorov. Estimation for this expression using Stirling formula -
meprotsessorov. Estimation for this expression using Stirling formula - %5E%7B1%2F2%7D%202%5E%7Bn-1%7D) . The number of nodes grows exponentially.
. The number of nodes grows exponentially.
I think now it has become more or less clear what kind of object it is. We now turn to the most delicious that the UMM offers us, namely to the third property - the information overhead .
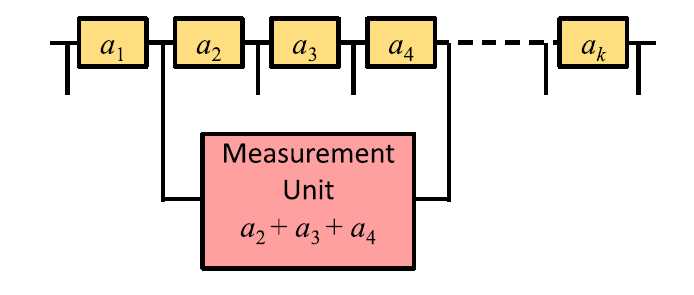
Suppose we have n memprocessors, let us designate the state of the selected memprocessors as%20%3D%20(x(j_1)%2C%20%5Cdots%2C%20x(j_n))) . The status of a separate memprocessor
. The status of a separate memprocessor %20%3D%20u_j) contained in internal variables
contained in internal variables  .
.  - vector. Also for each memprocessor, we divide external variables into 2 groups - “in” and “out” (out of one memprocessor is connected to in another). In the picture the empty circle is a component
- vector. Also for each memprocessor, we divide external variables into 2 groups - “in” and “out” (out of one memprocessor is connected to in another). In the picture the empty circle is a component _h%20%3D%200) . Suppose also that we have a device that, when connected to the desired meprocessor, can be considered at once .
. Suppose also that we have a device that, when connected to the desired meprocessor, can be considered at once .

This device, connected to several memprocessors, can consider the state of both, and therefore their global state, defined as where
where  - commutative, associative operation,
- commutative, associative operation, ) . This operation is defined as
. This operation is defined as
_%7Bh%20%5Cstar%20k%7D%20%3D%20(u_%7Bj_1%7D)_h%20%20%5Cast%20(u_%7Bj_2%7D)_k%2C%0A)
Where and
and  - commutative and associative operations with
- commutative and associative operations with  and
and  . Moreover, if for
. Moreover, if for  performed
performed  then
then
_%7Bh%20%5Cstar%20k%7D%20%3D%20(u_%7Bj_1%7D%20%5Cdiamond%20u_%7Bj_2%7D)_%7Bh%20%5Cstar%20k%7D%20%5Coplus%20(u_%7Bj_1%7D%20%5Cdiamond%20u_%7Bj_2%7D)_%7Bh'%20%5Cstar%20k'%7D%2C%0A)
Where - commutative, associative operation, for which
- commutative, associative operation, for which  .
.
Now having a lot integers, we define the message
integers, we define the message %20%5Ccup%20(a_%7B%5Csigma_1%7D%20%2C%20%5Cdots%20%2C%20a_%7B%5Csigma_k%7D)) where
where ) - indexes taken from various subsets
- indexes taken from various subsets  . Thus many messages consists of
. Thus many messages consists of  equally likely messages
equally likely messages  The amount of information on Shannon is equal to
The amount of information on Shannon is equal to %20%3D%20-%5Clog_2(2%5E%7B-n%7D)%20%3D%20n)
Now, taking n memprocessors, we expose nonzero components where
where  . So we coded all the elements.
. So we coded all the elements.  on the memory processors. On the other hand, by connecting to the necessary meprocessors and reading their global state (according to the formulas, the sum of the elements is obtained there), we can consider any possible state m. In other words, n memprocessors can encode (compress information if you wish) about
on the memory processors. On the other hand, by connecting to the necessary meprocessors and reading their global state (according to the formulas, the sum of the elements is obtained there), we can consider any possible state m. In other words, n memprocessors can encode (compress information if you wish) about  messages at the same time.
messages at the same time.
Here I have to say that I could not understand the details of this algorithm (it turned out that I am not so good at electrical engineering and signal processing, and the authors apparently decided not to paint everything for such ignoramuses), but the general idea is .
For starters, they offer a look at the function
%20%3D%20-1%20%2B%20%5Cprod_%7Bj%3D1%7D%5En%20(1%20%2B%20e%5E%7Bi%202%20%5Cpi%20a_j%20x%7D)%0A)
If we open the brackets, then we will have works on various sets of indices (denote such a set as  ), and they are equal
), and they are equal
%0A)
In other words, our function contains information about the sums of all subsets . Now, if we consider the function g as a signal source, then each exponent contributes to the resulting signal, with the contribution with frequency
contains information about the sums of all subsets . Now, if we consider the function g as a signal source, then each exponent contributes to the resulting signal, with the contribution with frequency  .
.
Now, all we need is to apply a Fourier transform to this signal and see what frequencies we have in the signal. If we have a component with a frequency then the subset with sum exists.
If we solve this problem on a regular computer, now we could apply a fast Fourier transform. Let us estimate the asymptotics.
To do this, we estimate the number of points that need to be taken from the signal. By the Kotelnikov theorem, these points need where
where  - Evaluation of the maximum possible value of frequency. In the article, the authors introduced an additional variable.
- Evaluation of the maximum possible value of frequency. In the article, the authors introduced an additional variable.  which is proportional
which is proportional  and considered the asymptotics through it.
and considered the asymptotics through it.
Thus, using FFT we can solve the problem for)) . Here it should be noted that, as in the backpack problem (and SSP is a special case of the backpack problem), $ p $ grows exponentially. For our problem, you can also use the Görtsel algorithm, which will give us
. Here it should be noted that, as in the backpack problem (and SSP is a special case of the backpack problem), $ p $ grows exponentially. For our problem, you can also use the Görtsel algorithm, which will give us ) . The proposed method allows the authors to get rid of asymptotic, which will give us linear time.
. The proposed method allows the authors to get rid of asymptotic, which will give us linear time.
Now, in your own words (for more detailed consideration, refer to the original articles), how they achieved this.
Take analog memory processors, the internal value of which will be the value of a certain number of . As operators
analog memory processors, the internal value of which will be the value of a certain number of . As operators  and
and  taken, respectively, addition and multiplication.
taken, respectively, addition and multiplication.
But it is in our model. In iron, it turns out that each memprocessor is a signal generator with its own frequency (corresponding to the number of ), the general state of the memory processors is simply the addition of a signal. It turns out that these memory processors simulate the function .
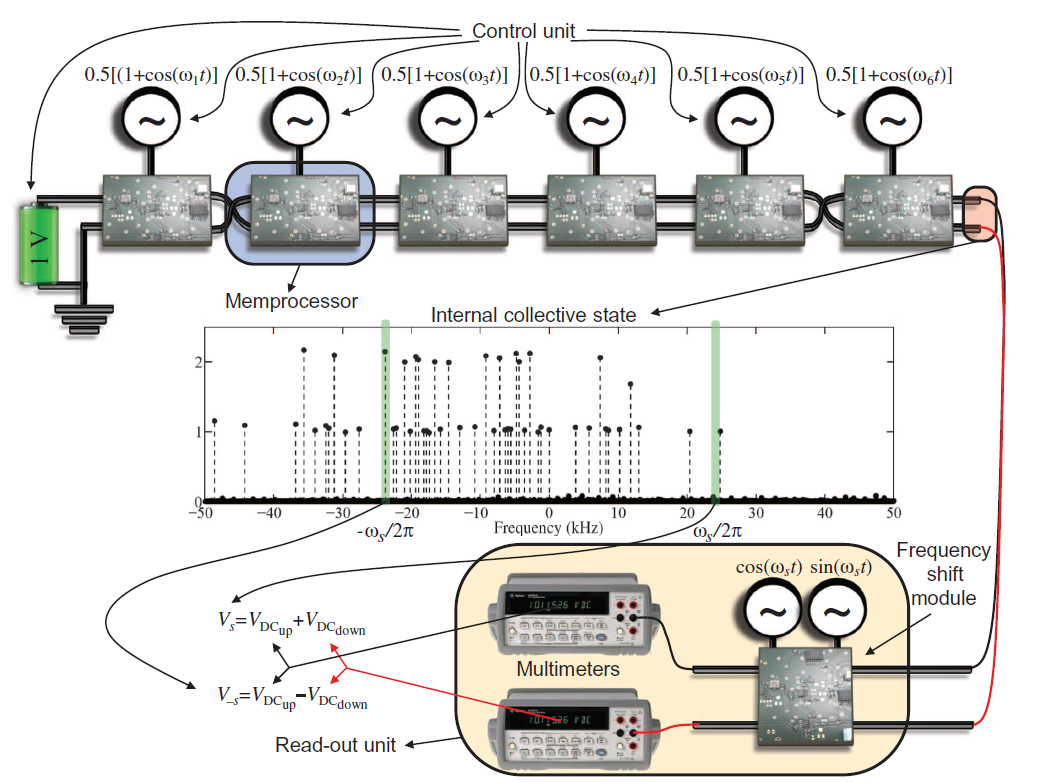
Well, now, in order to read the result, you need to check if there is a given frequency in the signal. Instead of implementing FFT, they made a piece of hardware that only skips a given frequency (I didn’t quite understand how, but my knowledge in electronics is to blame), which is already working for a constant time.
Total time asymptotics in general amounted to) , asymptotics for the memprocessor was
, asymptotics for the memprocessor was ) . Let us fireworks? Do not hurry.
. Let us fireworks? Do not hurry.
In fact, the authors slyly shifted the “complicated” part of the task, which gives us the exhibitor, from the program part to the technical part. In an earlier article about this in general, not a word, in July they admit it, but only a few lines.
It's all about signal coding (I found a clear explanation here ). Due to the fact that we encode analog signals, and use discrete signal generators, we now need exponential accuracy in determining the signal level (in the piece of hardware that isolates the desired frequency), which may require the time exponent.
The authors argue that this trouble can be circumvented, if instead of discrete signal generators use analog. But I have big doubts that you can use analog circuits for any and at the same time not to drown in the noise (because of them at the time they abandoned analog computers and began to use digital).
Wonderful magic did not happen. NP full problems are still difficult to calculate. So why did I write all this? Mainly because at least the physical implementation is complex, the model itself seems very interesting to me, and their study is necessary. Soon (if not now), such models will be of great importance in many areas of science.
For example, as I mentioned, neural networks are a special case of UMM. It is possible that we will learn a little more about neural networks if we look at them from the other side using a slightly different mate. apparatus.
A small spoiler: in the beginning it seemed to me some kind of magic, but then I understood the catch ...
Nowadays, the Turing machine (hereinafter MT) is the universal definition of the concept of an algorithm, and hence the universal definition of a “problem solver”. There are many other models of the algorithm - lambda calculus, Markov algorithms, etc., but all of them are mathematically equivalent to MT, so even though they are interesting, they do not significantly change anything in the theoretical world.
')
Generally speaking, there are other models - Nondeterministic Turing Machine, Quantum Turing Machines. However, they are (for the time being) only abstract models that cannot be implemented in practice.
Six months ago, an interesting article was published in Science Advances with a computational model that differs significantly from MT and which it is quite possible to put into practice (the article itself was about how they counted the SSP task on real hardware).
And yes. The most interesting thing about this model is that, according to the authors, it is possible to solve (some) tasks from the NP class of complete problems in the time and memory polynomial.
Probably you should immediately stipulate that this result does not mean a solution to the problem.
I myself am skeptical at the moment about the possibility of building this machine in the gland (why I will tell below), but the model itself seemed to me quite interesting for analysis and, quite possibly, it will find application in other areas of science.
Small introduction
What is a computer (more precisely, the most popular implementation of MT - Arch. Von Neumann) today? Some kind of I / O interface, memory and CPU, which is physically separated from them. In the CPU, there are both the module that controls the progress of the calculations and the blocks that perform these calculations.
The physical separation of the CPU means that we have to spend a lot of time transferring data. Actually for this purpose various levels of cash memory were invented. However, cache memory, of course, makes life easier, but does not solve all data transfer problems.
The proposed data model was inspired by the work of the brain (the phrase is rather trite, but it is quite suitable here). Its essence is that the calculations take place not in a separate device, where you need to transfer data, but directly in memory. The order of calculations is controlled by an external device (Control Unit).
This model of computing, called Universal Memcomputing Machines (I did not begin to translate this term. Then I will use the abbreviation UMM).
In this article, we first recall how MT is formally defined, then we will look at the definition of UMM, look at an example of how to set an algorithm for solving a problem on a UMM, consider several properties, including the most important information overhead.
Formal description of the model.
Universal Turing Machine (UTM)
I think you all remember what a Turing machine is (otherwise there is no point in reading this article). Tape, carriage, all things. Let's just remember how it is defined formally.
Turing machine is a tuple
Where
Memprocessor
To begin with, let's define our UMM memory cell - memeprocessor.
The memprocessor is defined as a 4-tuple.
And finally
I want to remind you that the memory processor is not the processor that we usually imagine in our head. It is rather a memory cell that has the function of obtaining a new state (programmable).
Universal Memcomputing Machine (UMM)
Now we introduce the formal definition of UMM. UMM is a model of a computer formed of interconnected meprocessors (which, generally speaking, can be both digital and analog).
Where
Where
By analogy with the Turing machine, as you might have guessed,
Generally speaking, discarding formalism, the main difference between UMM and MT is that in UMM, affecting a single memory cell (that is, a memory processor), you automatically influence its environment, without additional calls from the Control Unit.
Note 2 properties of the UMM, directly arising from its definition.
- Property 1. Intrinsic parallelism (I have not decided how to properly translate this term, so I left it as it is). Any function
- Property 2. Functional polymorphism . It lies in the fact that, unlike the Turing machine, the UMM can have many different operators
Generally speaking, it is not so difficult to modify the Turing machine so that it also has these properties, but the authors insist.
And a few more comments on the definition. The UMM, unlike the Turing machine, can have an infinite state space with a finite number of meprocessors (due to the fact that they can be analog).
By the way, UMM can be considered as a generalization of neural networks.
We prove one theorem.
UMM is a universal machine (that is, a machine that can simulate the operation of any MT).
Evidence.
In other words, we need to show that the Turing machine is a special case of the UMM. (whether the opposite is true is not proven, and if the authors of the article are right, then this will be equivalent to proving
Let in the definition of UMM,
The theorem is proved.
Algorithms
Let's look at an example of how to solve problems on the UMM (for now just to get acquainted with the model). Take the subset sum problem ( SSP ) problem.
Let there be many
Exponential algorithm
Let the memprocessors in our UMM be arranged in a matrix form (see the figure). We define three operations.
- this is directly a calculation. Using activation lines, we can select rows and bounding columns in which calculations are made. The essence of the calculation is in adding the value of the leftmost cell to the entire row.
- this is a data movement operation. The control node selects two columns and the values from the first are copied to the second. The control node does not necessarily perform the copy operation itself; it simply activates the columns with the necessary lines.
By combining these three operations, we can get the transition function
In the first step of the algorithm, we get the sum of all subsets of length
Now let's calculate how many processors we need to perform these operations. At iteration k we need
I think now it has become more or less clear what kind of object it is. We now turn to the most delicious that the UMM offers us, namely to the third property - the information overhead .
Exponential Information Overhead
Suppose we have n memprocessors, let us designate the state of the selected memprocessors as
This device, connected to several memprocessors, can consider the state of both, and therefore their global state, defined as
Where
Where
Now having a lot
Now, taking n memprocessors, we expose nonzero components
SSP solution algorithm using Exponential Information Overhead
Here I have to say that I could not understand the details of this algorithm (it turned out that I am not so good at electrical engineering and signal processing, and the authors apparently decided not to paint everything for such ignoramuses), but the general idea is .
For starters, they offer a look at the function
If we open the brackets, then we will have works on various sets of indices
In other words, our function
Now, all we need is to apply a Fourier transform to this signal and see what frequencies we have in the signal. If we have a component with a frequency
If we solve this problem on a regular computer, now we could apply a fast Fourier transform. Let us estimate the asymptotics.
To do this, we estimate the number of points that need to be taken from the signal. By the Kotelnikov theorem, these points need
Thus, using FFT we can solve the problem for
Now, in your own words (for more detailed consideration, refer to the original articles), how they achieved this.
Take
But it is in our model. In iron, it turns out that each memprocessor is a signal generator with its own frequency (corresponding to the number of
Well, now, in order to read the result, you need to check if there is a given frequency in the signal. Instead of implementing FFT, they made a piece of hardware that only skips a given frequency (I didn’t quite understand how, but my knowledge in electronics is to blame), which is already working for a constant time.
Total time asymptotics in general amounted to
Some problems of the model
In fact, the authors slyly shifted the “complicated” part of the task, which gives us the exhibitor, from the program part to the technical part. In an earlier article about this in general, not a word, in July they admit it, but only a few lines.
It's all about signal coding (I found a clear explanation here ). Due to the fact that we encode analog signals, and use discrete signal generators, we now need exponential accuracy in determining the signal level (in the piece of hardware that isolates the desired frequency), which may require the time exponent.
The authors argue that this trouble can be circumvented, if instead of discrete signal generators use analog. But I have big doubts that you can use analog circuits for any
Total
Wonderful magic did not happen. NP full problems are still difficult to calculate. So why did I write all this? Mainly because at least the physical implementation is complex, the model itself seems very interesting to me, and their study is necessary. Soon (if not now), such models will be of great importance in many areas of science.
For example, as I mentioned, neural networks are a special case of UMM. It is possible that we will learn a little more about neural networks if we look at them from the other side using a slightly different mate. apparatus.
Source: https://habr.com/ru/post/274593/
All Articles